数据结构Notes
来源:数据结构课程总结
2023.9~2024.1@isSeymour
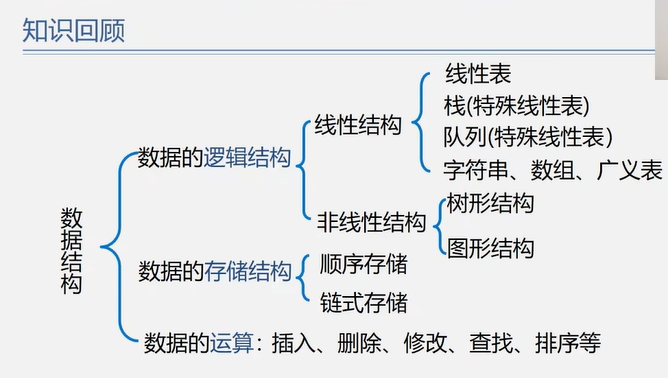
一、线性表
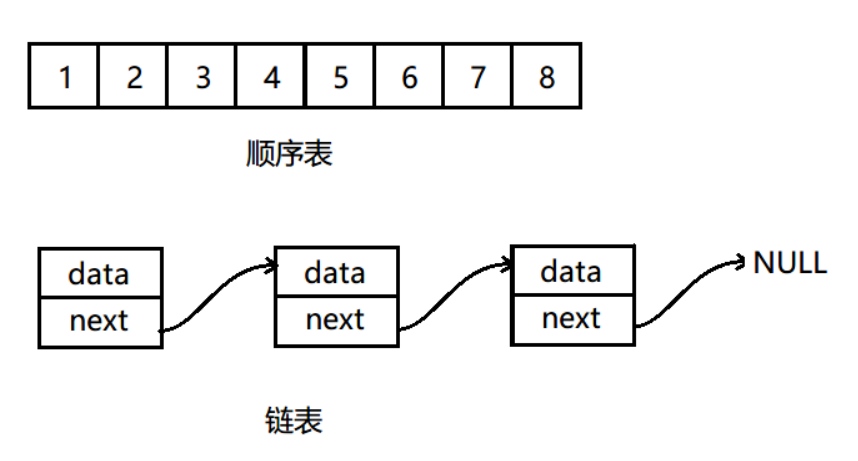
1.1 顺序表
元素位置从1开始作为参数 i 传入(不是从0开始)。
定义、声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <stdio.h> #include <stdlib.h> #define LIST_INIT_SIZE 100 #define LIST_INCREMENT 10 typedef int ElemType; typedef struct { ElemType* elem; int length; int listsize; } sqlist; typedef int Status; #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0 #define INFEASIBLE -1 #define OVERFLOW -2 Status InitList (sqlist* L) ; Status DestroyList (sqlist* L) ; Status ClearList (sqlist* L) ; int ListLength (sqlist L) ;Status GetElem (sqlist L, int i, ElemType* e) ; Status ListInsert (sqlist* L, int i, ElemType e) ; Status ListDelete (sqlist* L, int i, ElemType* e) ; int LocateElem (sqlist L, ElemType e, Status (*compare)(ElemType e1, ElemType e2)) ;Status PriorElem (sqlist L, ElemType cur_e, ElemType* pre_e) ; Status NextElem (sqlist L, ElemType cur_e, ElemType* next_e) ; Status ListTraverse (sqlist L, Status (*visit)(ElemType e)) ;
初始化、销毁、清空
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Status InitList (sqlist* L) { L->elem = (ElemType*)malloc (LIST_INIT_SIZE * sizeof (ElemType)); if (L->elem == NULL ) exit (OVERFLOW); L->length = 0 ; L->listsize = LIST_INIT_SIZE; return OK; } Status DestroyList (sqlist* L) { if (L->elem) free (L->elem); L->length = 0 ; L->listsize = 0 ; return OK; } Status ClearList (sqlist* L) { L->length = 0 ; return OK; }
求长度、取元素
1 2 3 4 5 6 7 8 9 10 11 12 13 int ListLength (sqlist L) { return L.length; } Status GetElem (sqlist L, int i, ElemType* e) { if (i < 1 || i > L.length) return ERROR; *e = L.elem[i - 1 ]; return OK; }
插入、删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 Status ListInsert (sqlist* L, int i, ElemType e) { ElemType *p, *q; if (i < 1 || i > L->length + 1 ) return ERROR; if (L->length >= L->listsize) { ElemType* newbase; newbase = (ElemType*)realloc (L->elem, (L->listsize + LIST_INCREMENT) * sizeof (ElemType)); if (!newbase) return OVERFLOW; L->elem = newbase; L->listsize += LIST_INCREMENT; } q = &(L->elem[i - 1 ]); for (p = &(L->elem[L->length - 1 ]); p >= q; --p) *(p + 1 ) = *p; *q = e; L->length++; return OK; } Status ListDelete (sqlist* L, int i, ElemType* e) { ElemType *p, *q; if (i < 1 || i > L->length) return ERROR; p = &(L->elem[i - 1 ]); *e = *p; q = &(L->elem[L->length - 1 ]); for (++p; p <= q; ++p) *(p - 1 ) = *p; L->length--; return OK; }
更多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 int LocateElem (sqlist L, ElemType e, Status (*compare)(ElemType e1, ElemType e2)) { ElemType* p = L.elem; int i = 1 ; while (i <= L.length && (*compare)(*p++, e) == FALSE) i++; return (i <= L.length) ? i : 0 ; } Status PriorElem (sqlist L, ElemType cur_e, ElemType* pre_e) { ElemType* p = L.elem; int i = 1 ; while (i <= L.length && *p != cur_e) { i++; p++; } if (i == 1 || i > L.length) return ERROR; *pre_e = *--p; return OK; } Status NextElem (sqlist L, ElemType cur_e, ElemType* next_e) { ElemType* p = L.elem; int i = 1 ; while (i < L.length && *p != cur_e) { i++; p++; } if (i >= L.length) return ERROR; *next_e = *++p; return OK; } Status ListTraverse (sqlist L, Status (*visit)(ElemType e)) { ElemType* p = L.elem; int i = 1 ; while (i <= L.length && (*visit)(*p++) == TRUE) i++; if (i <= L.length) return ERROR; printf ("\n" ); return OK; }
main
程序并不完整,这里只是给出在main中使用的一般流程
1 2 3 4 5 6 7 8 9 10 11 int main () { sqlist L; int n, x; InitList(&L); ...... DestroyList(&L); return 0 ; }
1.2 单链表
定义、声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <stdio.h> #include <stdlib.h> typedef struct { int p; int e; } Equation; typedef Equation ElemType; typedef struct LNode { ElemType data; struct LNode *next ; } LNode, *LinkList; typedef int Status; #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0 #define INFEASIBLE -1 #define OVERFLOW -2 Status InitLink (LinkList &L) ; Status DestroyLink (LinkList &L) ; int ListLength (LinkList &L) ; LNode* GetElem (LinkList &L, int i) ; Status ListInsert (LinkList &L, int i, ElemType data) ; Status ListDelete (LinkList &L, int i) ;
初始化、销毁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Status InitLink (LinkList &L) { L = (LNode *)malloc (sizeof (LNode)); L->next = NULL ; return OK; } Status DestroyLink (LinkList &L) { LNode *p = L, *t; while (p!=NULL ) { t = p->next; free (p); p = t; } return OK; }
求表长、查找元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Status ListLength (LinkList &L) { LNode *p = L->next; int count = 0 ; while (p) { count++; p = p->next; } return count; } LNode* GetElem (LinkList &L, int i) { if (i<0 ) { return NULL ; } int j=0 ; LNode *p = L; while (p!=NULL && j<i) { p = p->next; j++; } return p; }
插入、删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Status ListInsert (LinkList &L, int i, ElemType data) { if (i<1 ) { return ERROR; } LNode *newnode = (LNode *)malloc (sizeof (LNode)); newnode->data = data; newnode->next = NULL ; LNode *t = GetElem(L, i-1 ); if (t) { newnode->next = t->next; t->next = newnode; return OK; } return ERROR; } Status LinkDelete (LinkList &L, int i) { LNode *t1 = GetElem(L, i-1 ); LNode *t2 = GetElem(L, i); if (t1 && t2) { t1->next = t2->next; free (t2); return OK; } return ERROR; }
main
程序并不完整,这里只是给出在main中使用的一般流程
1 2 3 4 5 6 7 8 9 10 int main () { LinkList L1, L2, L3, L4; InitLink(L1), InitLink(L2), InitLink(L3), InitLink(L4); ...... DestroyLink(L1), DestroyLink(L2), DestroyLink(L3), DestroyLink(L4); return 0 ; }
二、栈和队列
2.1 栈(顺序栈)
定义、声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #define STACK_INIT_SIZE 100 #define STACK_INCREMENT 10 typedef int Status;#define OK 1 #define ERROR 0 #define OVERFLOW -1 #define TRUE 1 #define FALSE 0 typedef char SElemType;typedef struct { SElemType *top; SElemType *base; int stacksize; } SqStack; Status InitStack (SqStack &S) ; Status DestroyStack (SqStack &S) ; Status ClearStack (SqStack &S) ; Status StackEmpty (SqStack S) ; int StackLength (SqStack S) Status GetTop (SqStack S, SElemType &e) ;Status Push (SqStack &S, SElemType e) ; Status Pop (SqStack &S, SElemType &e) ; Status StackTraverse (SqStack S, Status (* visit)(SElemType *p)) ;
初始化、销毁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Status InitStack (SqStack &S) S.base = (SElemType *)malloc (STACK_INIT_SIZE * sizeof (SElemType)); if (!S.base) exit (OVERFLOW); S.top = S.base; S.stacksize = STACK_INIT_SIZE; return OK; } Status DestroyStack (SqStack &S) if (S.base) { free (S.base); S.base = S.top = NULL ; S.stacksize = 0 ; } return OK; }
清空、查空、长度、顶元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Status ClearStack (SqStack &S) if (S.base) S.top = S.base; return OK; } Status StackEmpty (SqStack S) if (S.top == S.base) return TRUE; else return FALSE; } int StackLength (SqStack S) return S.top - S.base; } Status GetTop (SqStack S, SElemType &e) if (S.top == S.base) return ERROR; e = *(S.top - 1 ); return OK; }
入栈、出栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Status Push (SqStack &S, SElemType e) if (S.top - S.base >= S.stacksize) { S.base = (SElemType *)realloc (S.base, (S.stacksize + STACK_INCREMENT) * sizeof (SElemType)); if (!S.base) exit (OVERFLOW); S.top = S.base + S.stacksize; S.stacksize += STACK_INCREMENT; } *S.top = e; S.top++; return OK; } Status Pop (SqStack &S, SElemType &e) if (S.top == S.base) return ERROR; S.top--; e = *S.top; return OK; }
更多
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Status StackTraverse (SqStack S, Status (* visit)(SElemType *p)) if (S.base == NULL ) return ERROR; SElemType *p1 = S.top; SElemType *p2 = S.base; while (p1 > p2) { visit (p2); p2++; } return OK; }
2.2 队列(链式队列)
定义、声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <stdio.h> #include <stdlib.h> typedef int Status;#define OK 1 #define ERROR 0 #define OVERFLOW -1 #define TRUE 1 #define FALSE 0 typedef int QElemType;typedef struct QNode { QElemType data; struct QNode *next; }QNode, *QueuePtr; typedef struct { QueuePtr front; QueuePtr rear; } LinkQueue; Status InitQueue (LinkQueue &Q) ; Status DestroyQueue (LinkQueue &Q) ; Status ClearQueue (LinkQueue &Q) ; Status QueueEmpty (LinkQueue Q) ; int QueueLength (LinkQueue Q) Status GetHead (LinkQueue Q, QElemType &e) ; Status EnQueue (LinkQueue &Q, QElemType e) ; Status DeQueue (LinkQueue &Q, QElemType &e) ;
初始化、销毁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Status InitQueue (LinkQueue &Q) Q.front = Q.rear = (QueuePtr)malloc (sizeof (QNode)); if (!Q.front) exit (OVERFLOW); Q.front->next = NULL ; return OK; } Status DestroyQueue (LinkQueue &Q) while (Q.front) { Q.rear = Q.front->next; free (Q.front); Q.front = Q.rear; } return OK; }
清空、为空、长度、队头
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 Status ClearQueue (LinkQueue &Q) if (!Q.front) return ERROR; QueuePtr p = Q.front->next, t; while (p) { t = p->next; free (p); p = t; } Q.rear = Q.front; Q.front->next = NULL ; return OK; } Status QueueEmpty (LinkQueue Q) if (Q.front == Q.rear) return TRUE; else return FALSE; } int QueueLength (LinkQueue Q) int len = 0 ; QueuePtr p = Q.front->next; while (p) { p = p->next; len++; } return len; } Status GetHead (LinkQueue Q, QElemType &e) if (!Q.front) return ERROR; if (Q.front == Q.rear) return ERROR; e = Q.front->next->data; return OK; }
队尾排队、队头出队
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Status EnQueue (LinkQueue &Q, QElemType e) QueuePtr p = (QueuePtr)malloc (sizeof (QNode)); if (!p) exit (OVERFLOW); p->data = e; p->next = NULL ; Q.rear->next = p; Q.rear = p; return OK; } Status DeQueue (LinkQueue &Q, QElemType &e) if (!Q.front) return ERROR; if (Q.front == Q.rear) return ERROR; QueuePtr p = Q.front->next; e = p->data; Q.front = p->next; if (Q.rear == p) Q.rear = Q.front; free (p); return OK; }
三、树
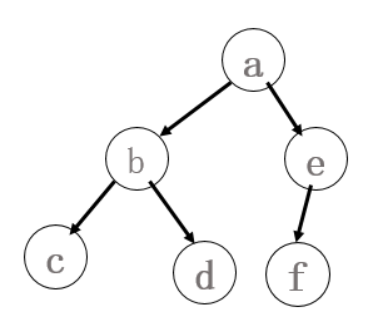
3.1 二叉树
二叉树的性质
非空二叉树上的叶子结点数等于度为 2 的结点数加 1 。
n0 = n2 +1
非空二叉树上第 k 层 上至多有 2^k-1^ 个结点(k>=1)
高度为 h 的二叉树至多有 2^h^ - 1 个结点(k>=1)
对完全二叉树 按从上到下、从左到右的顺序依次编号 1,2,…,n,则有以下关系:
当 i>1 时,结点 i 的双亲编号为 floor(i/2)
i 为偶数,双亲编号为 i/2,它为双亲的左孩子;
i 为奇数,双亲编号为 (i-1)/2,它为双亲的右孩子。
当 2i <= n 时,结点 i 的左孩子 编号为 2i ,否则无左孩子;
当 2i+1 <= n 时,结点 i 的右孩子 编号为 2i+1 ,否则无右孩子。
结点 i 所在层次(深度)为 floor( log~2~ i ) + 1 。
具有 n 个结点 (n>0)的完全二叉树 的高度为 ceiling( log~2~ (n+1) ) 或 floor( log~2~ n ) + 1 。
存储结构若采用顺序存储时,建议下标1开始,否则不满足条件4。
由于顺序存储空间利用率低,因此二叉树一般采用链式存储结构。
定义、声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdlib.h> #include <stack> #include <queue> using namespace std;typedef int Status;#define OK 1 #define ERROR 0 #define OVERFLOW -1 #define TRUE 1 #define FALSE 0 typedef char ElemType;typedef struct BiTNode { ElemType data; struct BiTNode *lchild, *rchild; } BiTNode, *BiTree;
含n个结点的二叉链表中,含有n+1个空链域,后续可作线索链表
构造、销毁、树空、访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 Status InitTree (BiTree &T) T = NULL ; return OK; } Status DestroyTree (BiTree &T) if (T) { DestroyTree (T->lchild); DestroyTree (T->rchild); free (T); } T = NULL ; return OK; } Status CreateBiTree (BiTree &T) char ch; scanf ("%c" , &ch); if (ch == '#' ) T = NULL ; else { if (!(T = (BiTNode*)malloc (sizeof (BiTNode)))) exit (OVERFLOW); T->data = ch; CreateBiTree (T->lchild); CreateBiTree (T->rchild); } return OK; } Status ClearTree (BiTree &T) if (T) { ClearTree (T->lchild); ClearTree (T->rchild); free (T); } T = NULL ; return OK; } Status TreeEmpty (BiTree &T) if (T) return FALSE; else return TRUE; } Status visit (BiTNode* T) printf ("%c " , T->data); return OK; }
递归:先、中、后序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Status PreOrder (BiTree T) if (T) { visit (T); PreOrder (T->lchild); PreOrder (T->rchild); } return OK; } Status InOrder (BiTree T) if (T) { InOrder (T->lchild); visit (T); InOrder (T->rchild); } return OK; } Status PostOrder (BiTree T) if (T) { PostOrder (T->lchild); PostOrder (T->rchild); visit (T); } return OK; }
非递归:先、中、后序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 Status PreOrder2 (BiTree &T) stack<BiTree> S; BiTree p = T; while (p || !S.empty ()) { if (p) { visit (p); S.push (p); p = p->lchild; } else { p = S.top (); S.pop (); p = p->rchild; } } return OK; } Status InOrder2 (BiTree &T) stack<BiTree> S; BiTree p = T; while (p || !S.empty ()) { if (p) { S.push (p); p = p->lchild; } else { p = S.top (); S.pop (); visit (p); p = p->rchild; } } return OK; } Status PostOrder2 (BiTree &T) stack<BiTree> S; BiTree p = T; BiTree r = NULL ; while (p || !S.empty ()) { if (p) { S.push (p); p = p->lchild; } else { p = S.top (); if (p->rchild && p->rchild != r) p = p->rchild; else { p = S.top (); S.pop (); visit (p); r = p; p = NULL ; } } } return OK; }
层次遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Status LevelOrder (BiTree T) queue<BiTree> Q; BiTNode *p = T; Q.push (p); while (!Q.empty ()) { p = Q.front (); Q.pop (); visit (p); if (p->lchild) Q.push (p->lchild); if (p->rchild) Q.push (p->rchild); } return OK; }
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main () BiTree T = NULL ; CreateBiTree (T); LevelOrder (T); DestroyTree (T); return 0 ; }
3.2 线索二叉树
四、图
4.0 知识框架
图的定义
图结构的存储
图的遍历
图的相关应用
最小生成树:Prim 算法、Kruskal 算法
最短路径:Dijkstra 算法、Floyd 算法
拓扑排序:AOV 网
关键路径:AOE 网
4.1 图的基本概念
图
图 G 由顶点集 V 和边集 E 组成,记为 G = (V, E)。
1 2 3 G = (V, E) V = {1, 2, 3} E = {<1,2>, <2,1>, <2,3>}
注:线性表可以是空表,树可以是空树,但图不可以是空图 。
就是说,图中不能一个顶点也没有,图的顶点集 V 一定非空 ,但边集 E 可以为空,此时图中只有顶点而没有边。
基本概念与术语
方向性
有向图
边是顶点的有序对。(弧)
无向图
边是顶点的无序对。(边)
复杂度
简单图
不存在重复边
不存在顶点到自身的边
多重图
注:学习中,只讨论简单图。
完全图(简单完全图)
无向图:任意两个顶点之间都存在边。
有向图:任意两个顶点之间都存在方向相反的弧。
子图与生成子图
1 2 3 4 5 6 7 G = (V, E) G' = (V', E') 子图: V‘ 是 V 的子集,E' 是 E 的子集,则 G’ 是 G 的子图。 生成子图: 且满足 V(G') = V(G)。(即,在子图的那些顶点的边是完全的,并不缺边)
注:并非 V 和 E 的任何子集都能构成 G 的子图。因为可能这样的子集可能不是图。
连通
在无向图中讨论连通性,
在有向图中讨论强连通性。
无向图
有向图
生成树(连通图才有)
连通图的生成树,是包含图中全部顶点的一个极小连通子图。
极大连通子图
要求包含所有边
极小连通子图
既要图连通,又要边数最少。
生成森林(非连通图可以)
非连通图中,连通分量的生成树构成了非连通图的生成森林。
4.2 图的存储及基本操作
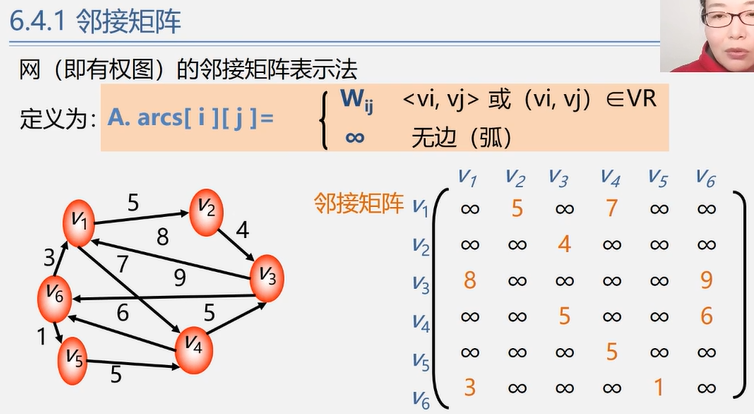
4.2.1 邻接矩阵法(稠密图)
1 2 3 4 5 6 7 8 #define MAX_VERTEX_NUM 100 typedef char VertexType; typedef int EdgeType; typedef struct { VertexType Vex[MAX_VERTEX_NUM]; EdgeType Edge[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; int vexnum, arcnum; } MGraph;
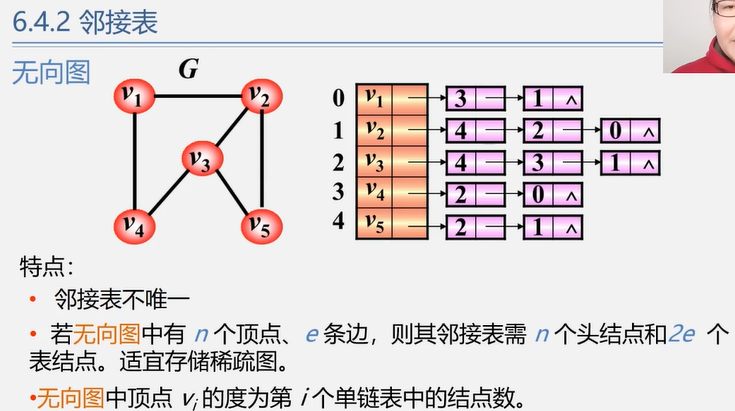
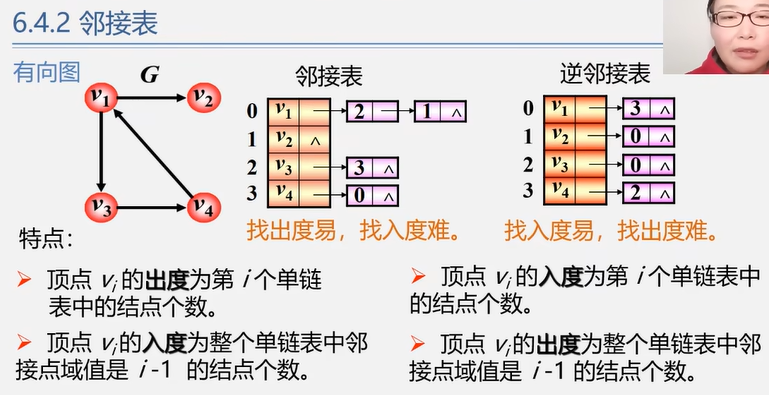
4.2.2 邻接表法(稀疏图)
介绍
对图 G 中的每一个顶点 vi 建立一个单链表。
边表(邻接表):
第 i 个单链表中的结点表示依附于顶点 vi 的边(有向图则是以顶点 vi 为尾的弧),这个单链表就称为顶点 vi 的边表(有向图则是出边表)。
由邻接点域(adjvex)和指向下一条邻接边的指针域(nextarc)构成。
顶点表:
边表的头指针和顶点的数据信息采用顺序存储(称为顶点表)。
由顶点域(data)和指向第一条邻接边的指针(firstarc)构成。
适合:稀疏图
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #define MAX_VERTEX_NUM 100 typedef struct ArcNode { int adjvex; struct ArcNode *next; }ArcNode; typedef struct VNode { VertexType data; ArcNode *first; }VNode, AdjList[MAX_VERTEX_NUM]; typedef struct { AdjList vertices; int vexnum, arcnum; }ALGraph;
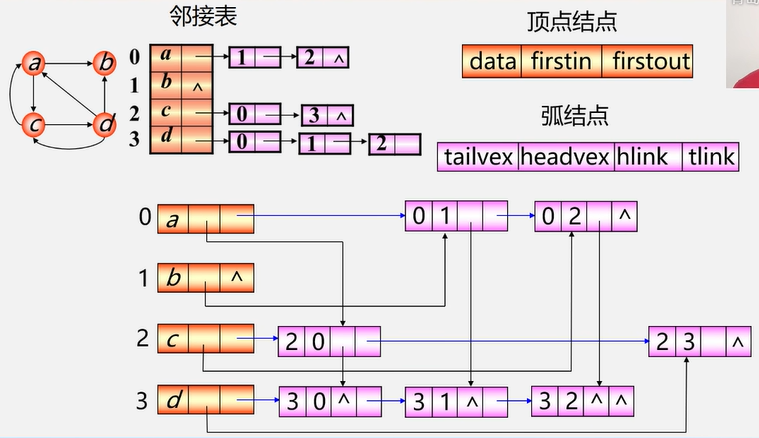
4.2.3 十字链表(有向图)
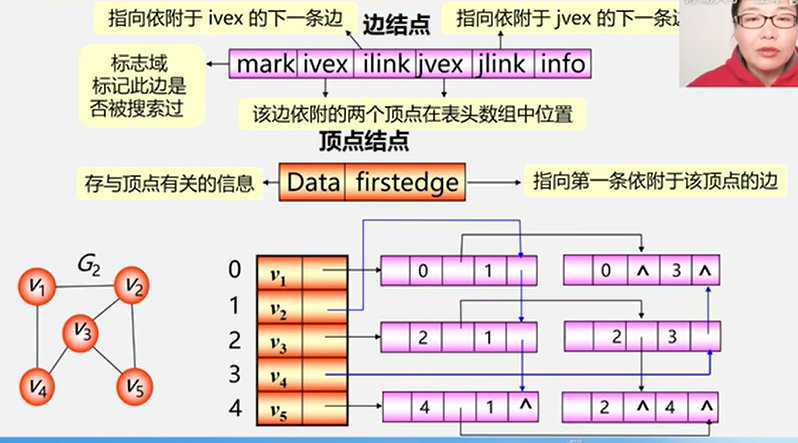
4.2.4 邻接多重链表(无向图)
介绍
邻接多重链表是无向图 的另一种链式 存储结构。
边结点:
ivex 和 jvex 指示该边依附的两个顶点的编号;
ilink 指向下一个依附于顶点 ivex 的边;
jlink 指向下一个依附于顶点 jvex 的边;
info 存放该边的相关信息。
顶点结点:
data 存放该顶点的相关信息;
firstedge 指向第一条依附于该顶点的边。
注:在邻接多重链表中,所有依附于同一顶点的边串联在同一链表中,由于每条边依附于两个顶点,因此每个边结点同时链接在两个链表中。
对于无向图,其邻接多重链表和邻接表的差别仅在于,同一条边在邻接表中用两个结点表示,而在邻接多重链表中只有一个结点。
4.3 图的遍历
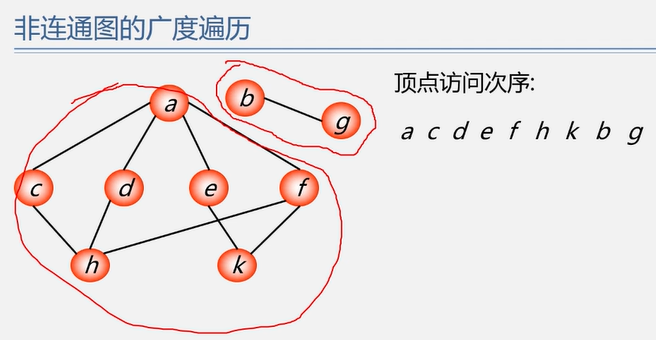
4.3.1 广度优先搜索(BFS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 bool visited[MAX_VERTEX_NUM]; Status BFSTraverse (Graph G) for (int i=0 ; i<G.vexnum; i++) visited[i] = FALSE; InitQueue (Q); for (int i=0 ; i<G.vexnum; i++) if (!visited[i]) BFS (G, i); return OK; } Status BFS (Graph G, int v) visit (v); visited[v] = TRUE; Enqueue (Q, v); while (!isEmpty (Q)) { DeQueue (Q, vh); for (w=FirstNeighbor (G, vh); w>=0 ; w=NextNeighbor (G, vh, w)) { if (!visited[w]) { visit (w); visited[w] = TRUE; EnQueue (Q, w); } } } return OK; }
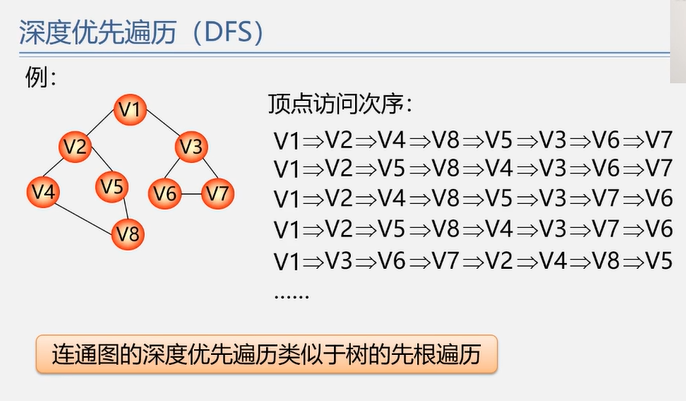
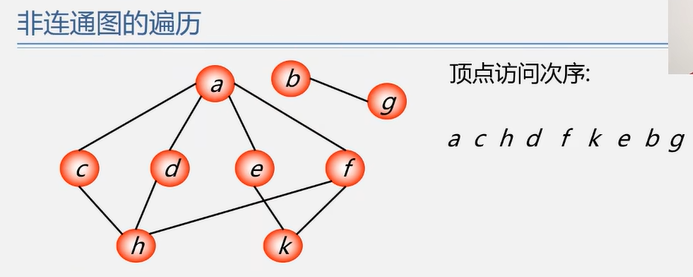
4.3.2 深度优先搜索 DFS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool visited[MAX_VERTEX_NUM]; Status DFSTraverse (Graph G) for (int v=0 ; v<G.vexnum; v++) visited[v] = FALSE; for (int v=0 ; v<G.vexnum; v++) if (!visited[v]) DFS (G, v); return OK; } Status DFS (Graph G, int v) visit (v); visited[v] = TRUE; for (w=FirstNeighbor (G, V); w>=0 ; w=NextNeighbor (G, v, w)) if (!visited[w]) DFS (G, w); return OK; }
4.3.3 遍历与连通性
4.4 图的应用
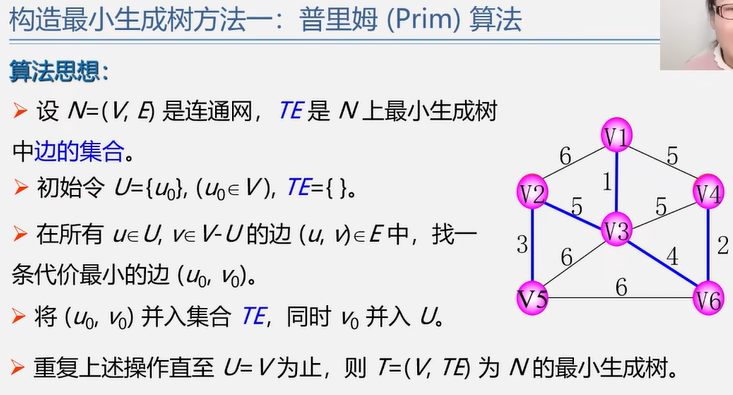
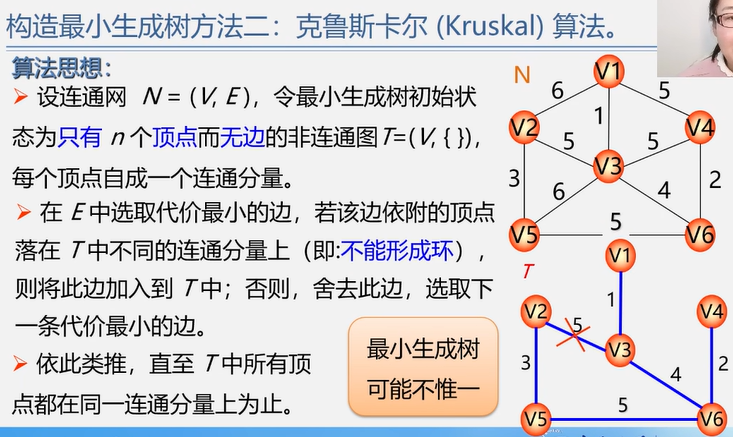
4.4.1 最小生成树
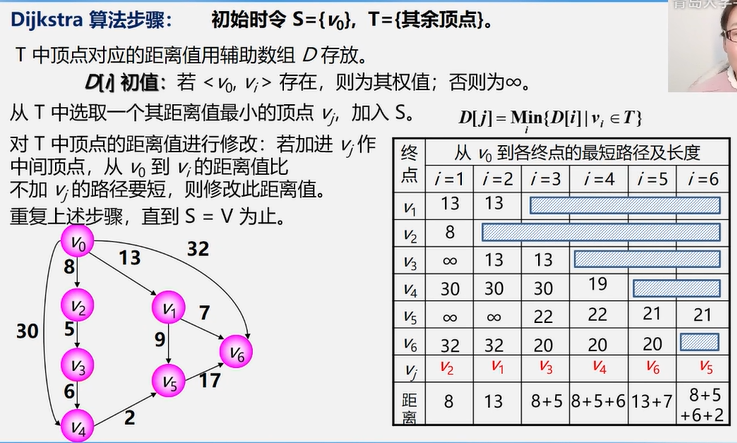
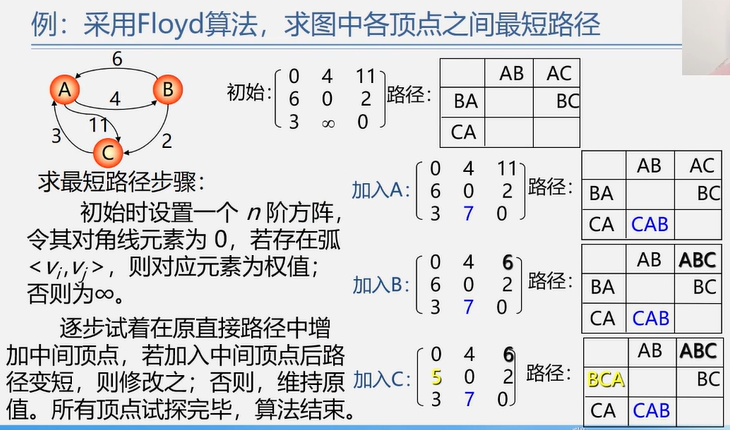
4.4.2 最短路径
单源最短路径——Dijkstra 算法
多源最短路径——Floyd 算法
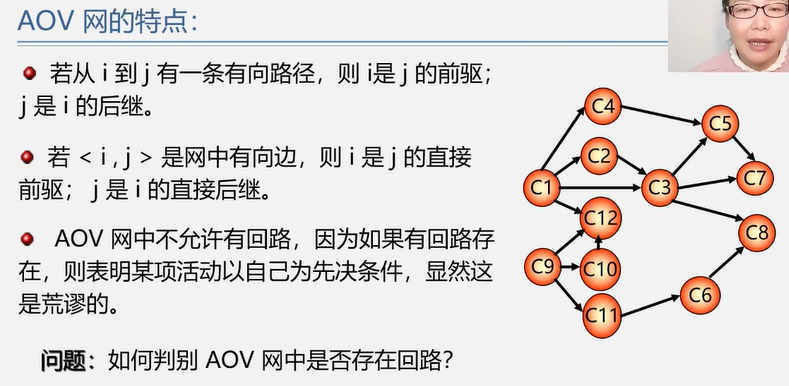
4.4.3 拓扑排序、AOV网
AOV网
若用 有向无环图 DAG图表示一个工程,其顶点表示活动,有向边 <vi, vj> 表示活动 vi 必须先于活动 vj 进行的这样一种关系,则将这种有向图称为 顶点表示活动的网络(Activity On Vertex, AOV网)。
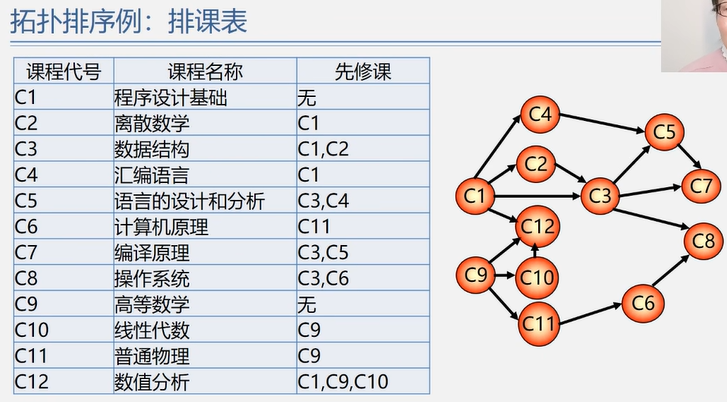
拓扑排序
在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件,称为该图的一个拓扑排序:
每个顶点出现且只出现一次
若顶点 A 在序列中排在顶点 B 的前面,则在图中不存在从顶点 B 到顶点 A 的路径。
每个 AOV 网都有一个或多个拓扑排序。
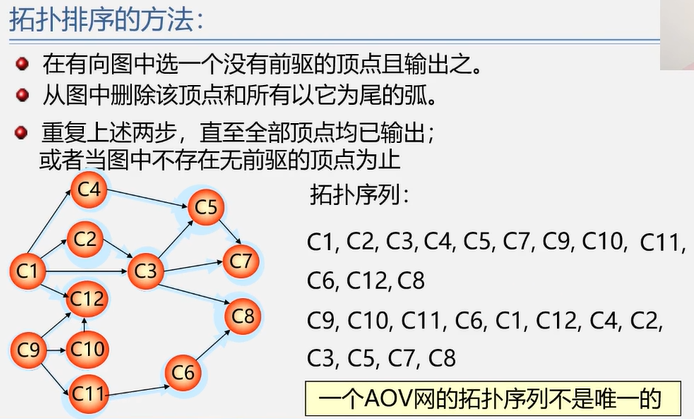
常用算法步骤:
从 AOV 网中选择一个没有前驱的顶点并输出。
从网中删除该顶点和所有以它为起点的有向边。
重复步骤1 和步骤2 直到当前的 AOV 网为空或当前网中不存在无前驱的顶点为止。(后者说明有向图中存在环)
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Status TopologicalSort (Graph G) InitStack (S); for (int i=0 ; i<G.vexnum; i++) if (indegree[i]==0 ) Push (S, i); int count = 0 ; while (!isEmpty (S)) { int h; Pop (S, h); print[count++] = h; for (p=G.vertices[h].firstarc; p; p=p->nextarc) { v = p->adjvex; if (!(--indegree[v])) Push (S, v); } } if (count<G.vexnum) return FALSE; else return TRUE; }
4.4.4 关键路径、AOE网
AOE网
在带权有向图中,以顶点表示事件,以有向边表示活动,以边上的权值表示完成该活动的开销(比如时间),称为 用边表示活动的网络(Activity On Edge, AOE网)。
注:AOV 网和 AOE 网都是有向无环图,不同之处在于它们的边和顶点所代表的含义是不同的,且 AOE 网的边有权值,而 AOV 网的边无权值,仅代表顶点之间的前后关系。
AOE 网的性质
只有在某顶点所代表的事件发生后,从该顶点出发的各有向边所代表的活动才能开始
只有在进入某顶点的各有向边所代表的活动都已经结束时,该顶点代表的事件才能发生
工程
工程开始:在 AOE 网中,仅有一个入度为0的顶点,是开始顶点(源点)。
工程结束:在 AOE 网中,仅有一个出度为0的顶点,是结束顶点(汇点)。
在 AOE 网中,一些活动是可以并行的。
关键路径
从源点到汇点的所有路径中,具有最大路径长度的路径,称为关键路径。
关键活动:在关键路径上的活动
关键路径的长度:完成整个工程的最短时间
概念
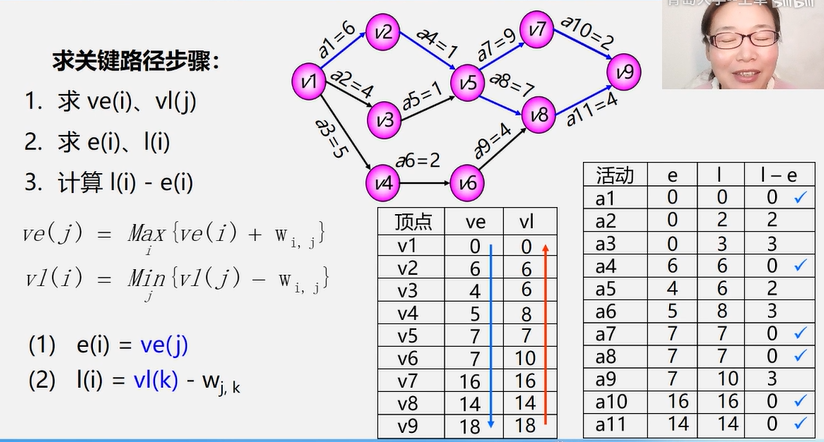
1 2 3 4 5 6 7 8 9 ai 活动:vj->vk ve (k) 事件 vk 的最早发生时间 vl (k) 事件 vk 的最迟发生时间 v (i) 活动 ai 的最早开始时间 l (i) 活动 ai 的最迟开始时间 d (i) l (i) - e (i) 活动 ai 的差额空闲余量 l (i) - e (i) = 0 ,即 l (i) = e (i) 的活动 ai 是 关键活动。
求关键路径的算法
从源点出发,令 ve(源点) = 0 ,按拓扑有序求 其余顶点的最早发生时间 ve()
从汇点出发,令 vl(汇点) = ve(汇点) ,按逆拓扑有序求 其余顶点的最迟发生时间 vl()
根据各顶点的 ve() 值求 所有弧的最早开始时间 e()
根据各顶点的 vl() 值求 所有弧的最迟开始时间 l()
求 AOE 网中所有活动的差额 d()
找出所有 d() = 0 的活动 ,构成关键路径
如何求 ve() ?
从 ve(1) = 0 开始按拓扑有序推进
1 ve (j) = Max i{ ve (i) + Wij}
其中,<i, j> ∈ T, 2<=j<=n,T是所有以 j 为头的弧的集合。
如何求 vl() ?
从 vl(n) = ve(n) 开始按拓扑有序推进
1 vl (i) = Min j{ vl (j) - Wij}
其中,<i, j> ∈ S, 1<=i<=n-1,S是所有以 i 为尾的弧的集合。
注意:
关键路径上的所有活动都是关键活动,因此可以通过加快关键活动来缩短整个工期。
但也不能任意缩短,因为一旦缩短到一定程度,该关键活动就可能变成非关键活动。
网中的关键路径并不唯一,对于有多条关键路径的网,只提高一条关键路径上的关键活动速度并不能缩短整个工程的工期。
五、查找
5.0 知识框架
5.1 线性结构
5.1.1 顺序查找
又称“线性查找”
适用:顺序表、链表
说明:引入“哨兵”
1 2 3 4 5 6 7 8 9 10 11 typedef struct { Element *elem; int TableLen; }SSTable; int Search_Seq (SSTable ST, ElemtType key) ST.elem[0 ] = key; for (int i=ST.TableLen; ST.elem[i]!=key; --i) ; return i; }
若查找前,已知关键字是有序的。
成功情况相同;失败情况可以提早退出循环。
ASL失败 = n/2 + n/n+1
n为结点数目
5.1.2 折半查找
又称“二分查找”
适用:有序的顺序表!!!
基本思想:
将给定值 key 与表中间位置比较
相等,成功
不相等,缩小范围到左半部或右半部,继续查找(若已经出现跨越部分的情况,说明找不到,退出)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int Binary_Search (SSTable L, ElemType key) int low = 0 , high = L.TableLen - 1 , mid; while (low <= high) { mid = (low+high)/2 ; if (L.elem[mid] == key) return mid; else if (L.elem[mid] > key) high = mid - 1 ; else low = mid + 1 ; } return -1 ; }
5.1.3 分块查找
又称“索引顺序查找”
吸收顺序查找和折半查找的优点,既有动态结构,又有快速查找
基本思想:
分块,块内无序,块间有序。
做法:
建立一个索引表,索引表的每个元素含有各块的最大关键字和各块的第一个元素的地址,索引表按关键字有序排序。
查找:
第一步:确定所在块(顺序查找或折半查找均可)
第二步:块内顺序查找
性能分析
长度 n 的查找表均匀分为 b 块,每块有 s 个记录,在等概论情况下。
若在块内和索引表中均采用顺序查找,则
ASL = LI + LS = (b+1)/2 + (s+1)/2 = (s2 + 2s + n)/(2s)
5.2 树形结构
5.2.1 二叉排序树 BST
二叉排序树
要么是一棵空树
要么是一棵满足下列条件的二叉树
若左子树非空,左子树所有结点的值均小于根结点的值
若右子树非空,右子树所有结点的值均大于根结点的值
左右子树也是一棵二叉排序树
效果
左 < 根 < 右
中序遍历,得到递增的有序序列
构造
1 2 3 4 5 6 7 8 9 10 void Creat_BST (BiTree &T, KeyType str[], int n) T = NULL ; int i = 0 ; while (i < n) { BST_Insert (T, str[i]); i++; } }
插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Status BST_Insert (BiTree &T, KeyType k) if (T == NULL ) { T = (BiTree)malloc (sizeof (BSTNode)); T->data = k; T->lchild = T->rchild = NULL ; return OK; } else if (k == T->data) return ERROR; else if (k < T->data) return BST_Insert (T->lchild, k); else return BST_Insert (T->rchild, k); }
查找
1 2 3 4 5 6 7 8 9 10 11 BSNode *BST_Search (BiTree T, ElemType key) while (T != NULL && key != T->data) { if (key < T->data) T = T->lchild; else T = T->rchild; } return T; }
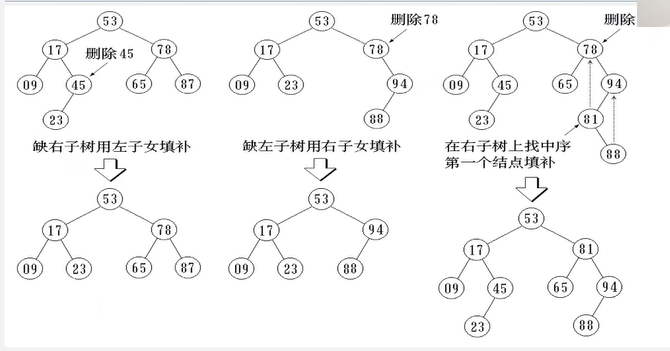
删除
三种情况,被删除结点是结点 Z。
注意:删除时特别注意,可能会把 root 根结点都删除了,要随时更新 root 值(传引用)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Status Remove (BSTree node, BSTree &root) if (node == NULL ) return ERROR; BSTree pt = node->parent; BSTree lc = node->lchild; BSTree rc = node->rchild; int left = (pt && pt->lchild == node)? 1 : 0 ; if (lc == NULL && rc == NULL ) { if (pt) { if (left) pt->lchild = NULL ; else pt->rchild = NULL ; } if (node == root) root = NULL ; delete node; } else if (lc && rc) { BSTNode *front = FindFront (node); node->data = front->data; node->cnt = front->cnt; Remove (front, root); } else { BSTree c = (lc)? lc : rc; if (pt) { if (left) pt->lchild = c; else pt->rchild = c; c->parent = pt; } if (node == root) root = c; delete node; } return OK; }
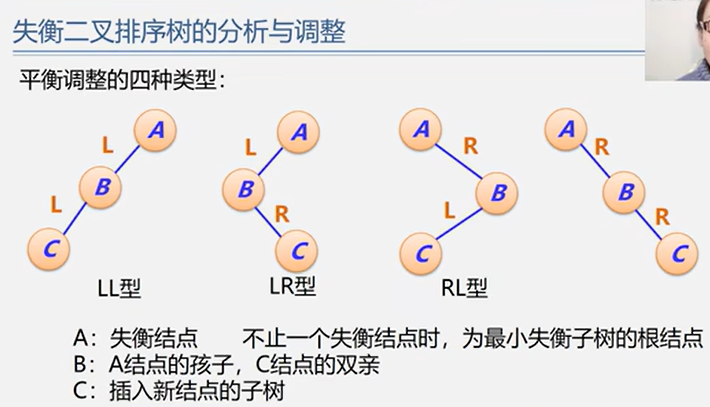
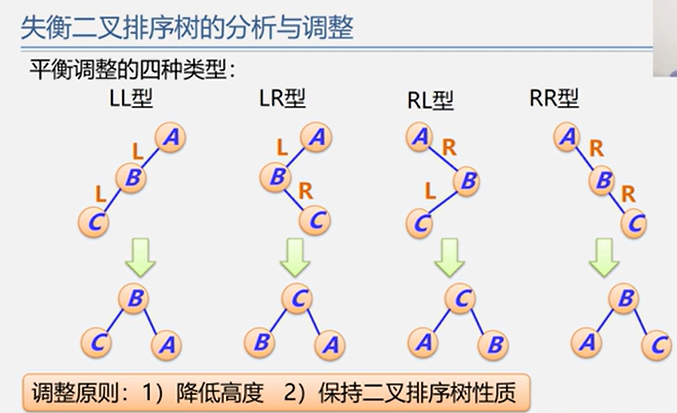
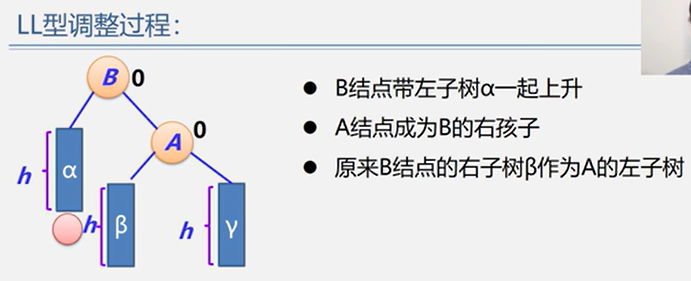
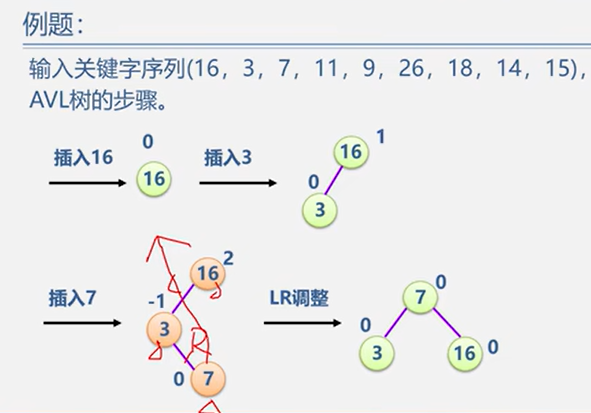
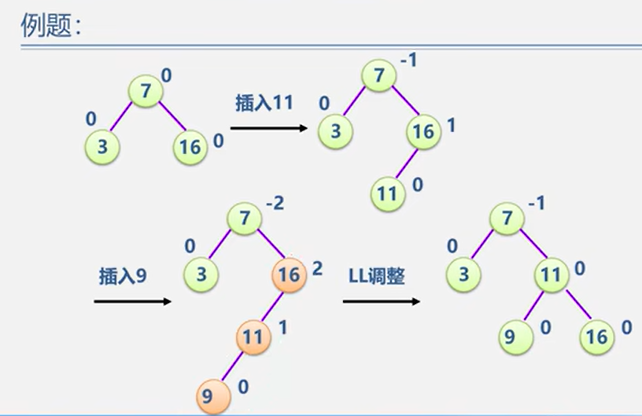
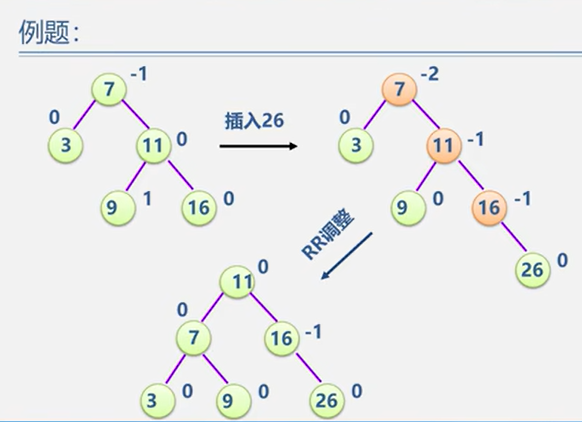
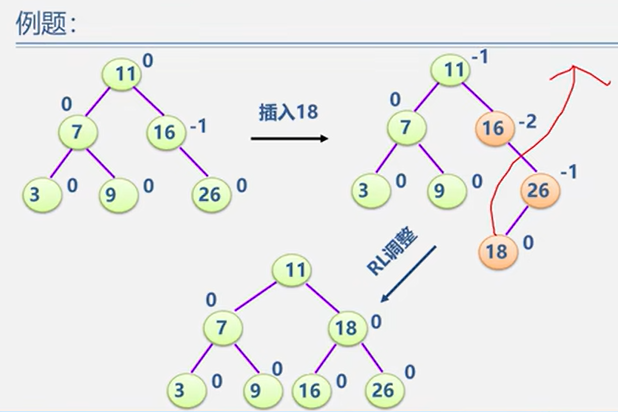
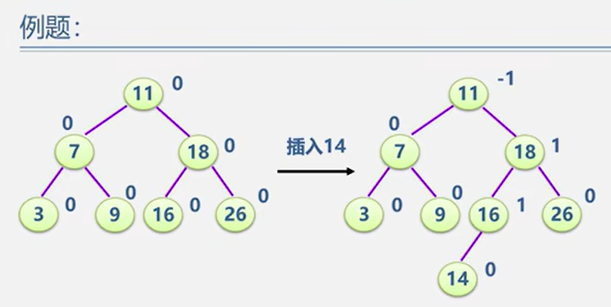
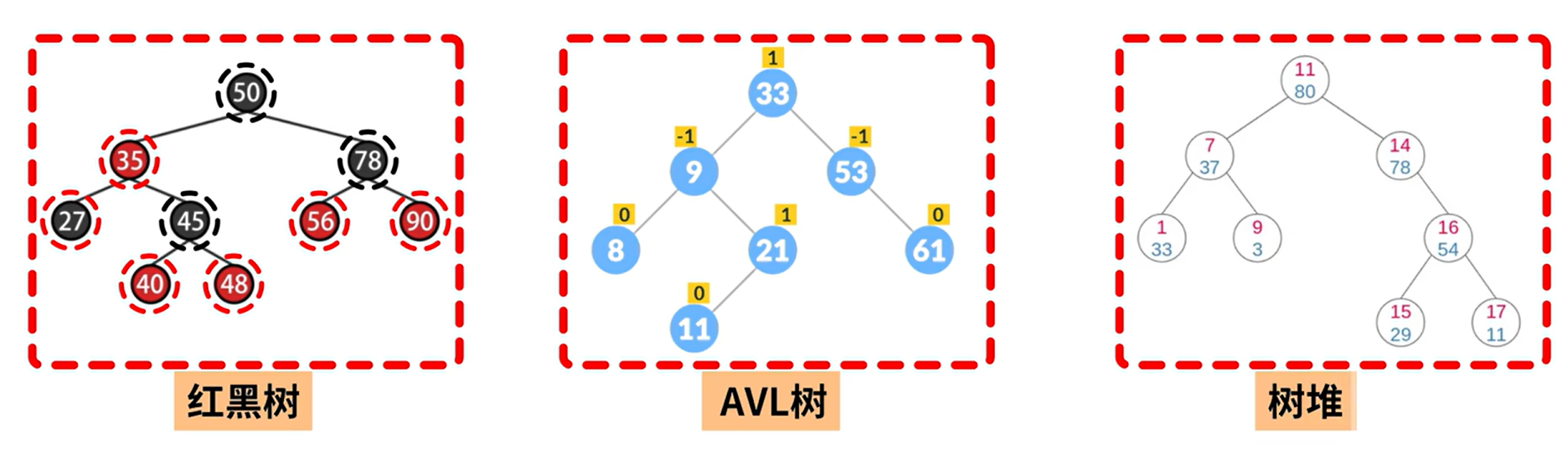
5.2.2 平衡二叉树 BBT / AVL
平衡调整
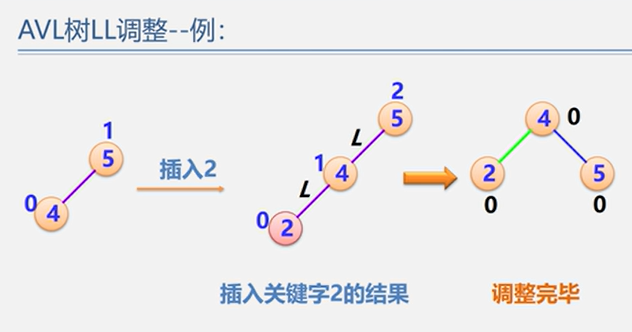
(1)LL型
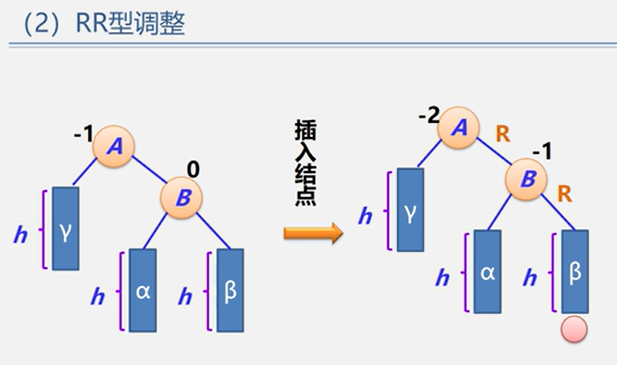
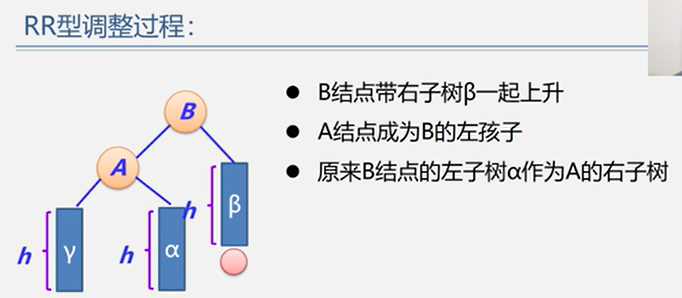
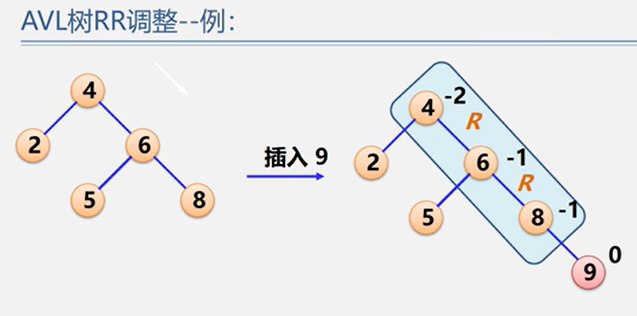
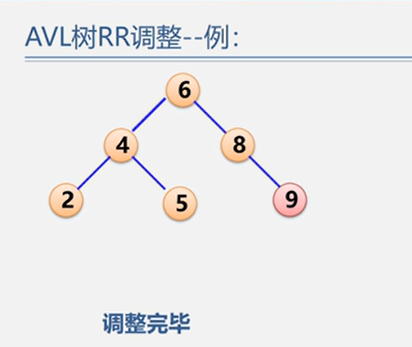
(2)RR型
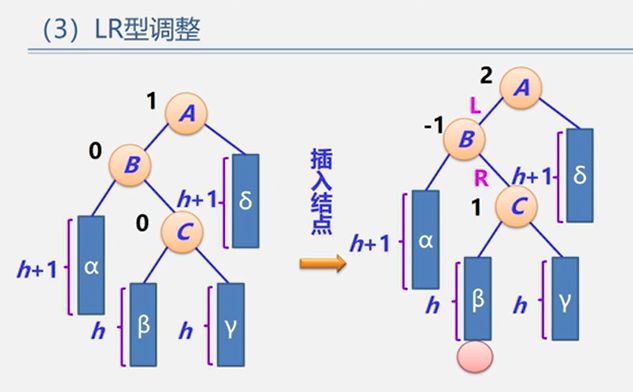
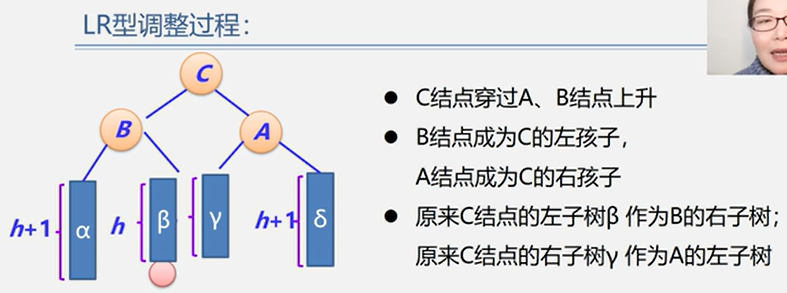
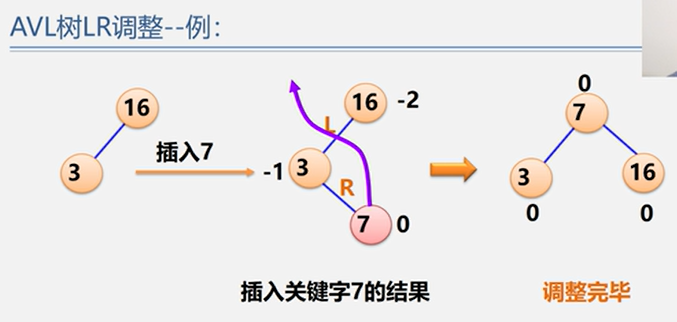
(3)LR型
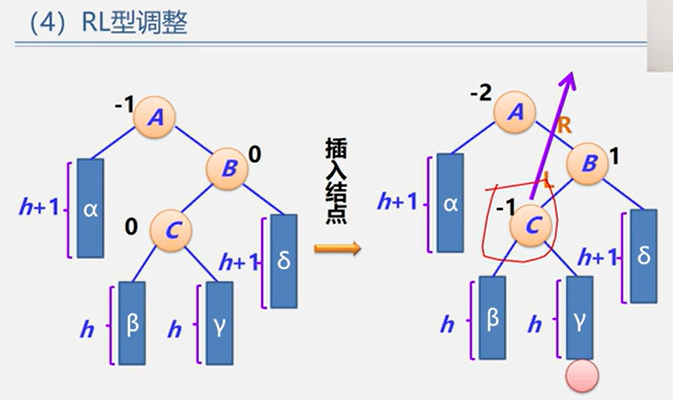
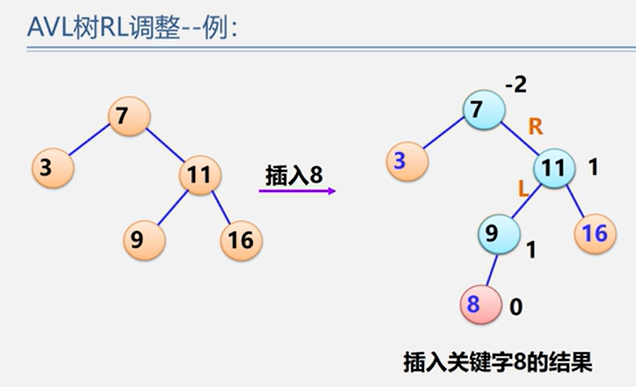
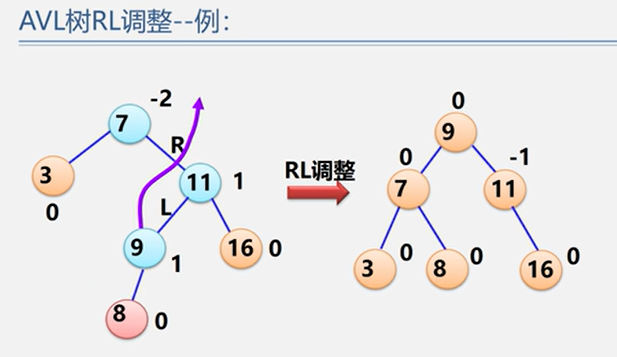
(4)RL型
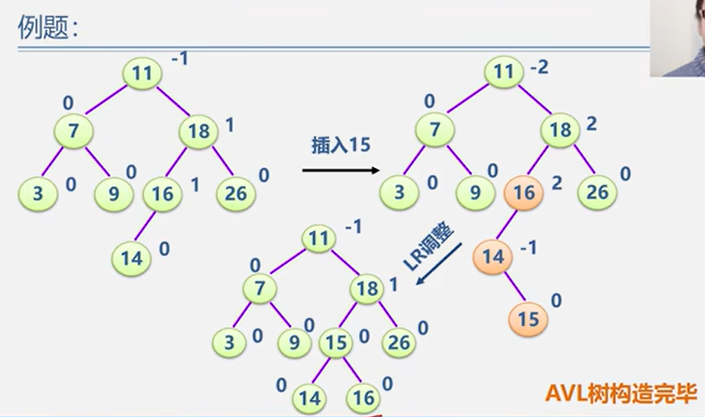
示例
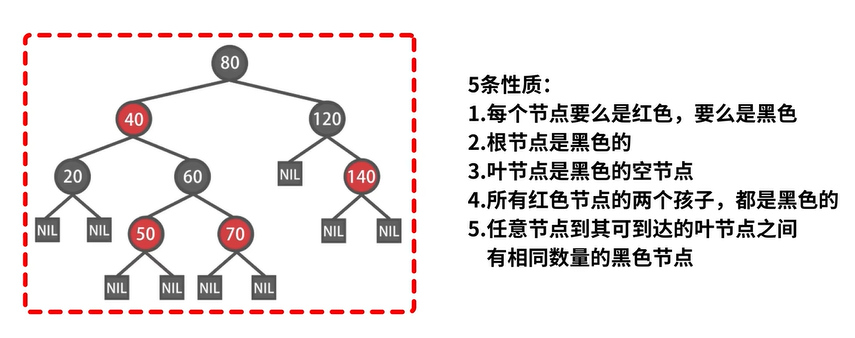
5.2.3 红黑树
辨析
不同的二叉排序树,主要区别在于:维护二叉树平衡的方式不同
定义
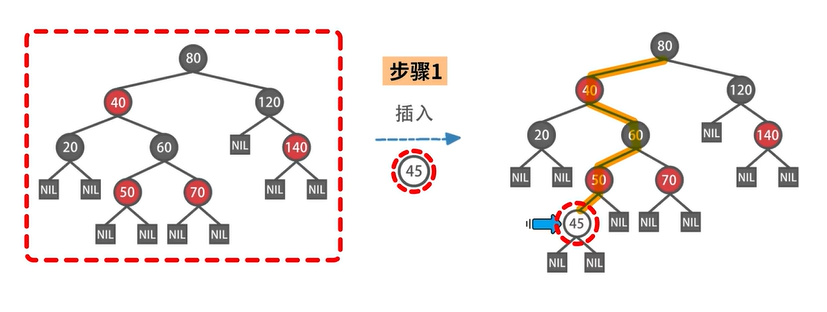
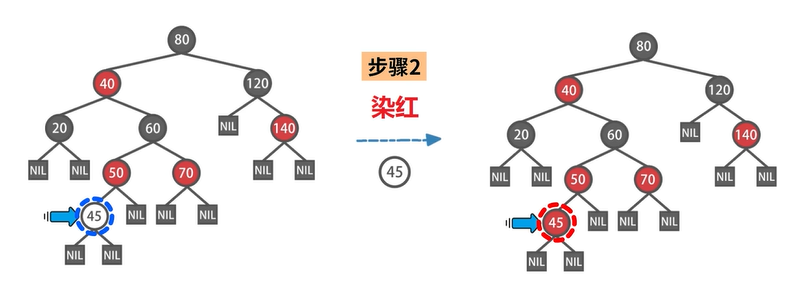
插入数据
疑问:为什么最初是染红,而不是染黑?
答:因为这样做,可以更少地违背红黑树的性质,更容易恢复红黑树应有的性质。
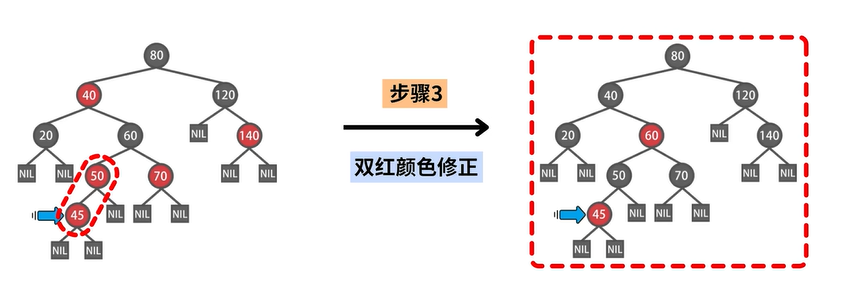
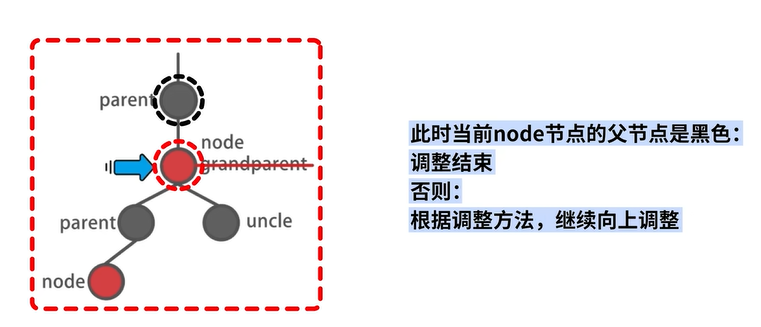
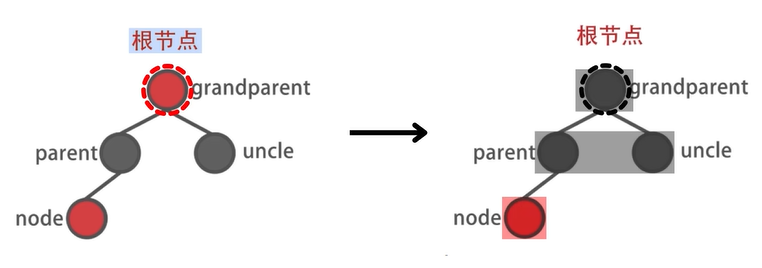
双红修正
包含两种操作
双红修正是一个从底向上的循环过程 。
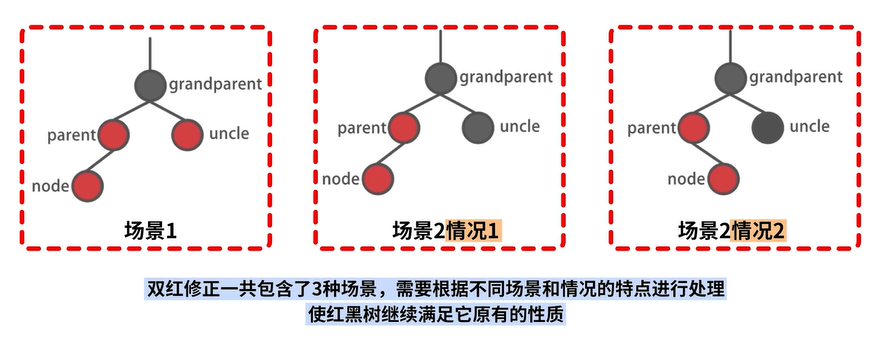
一共包含三种场景 :
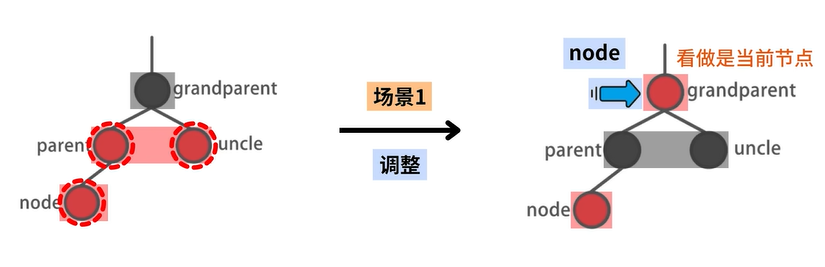
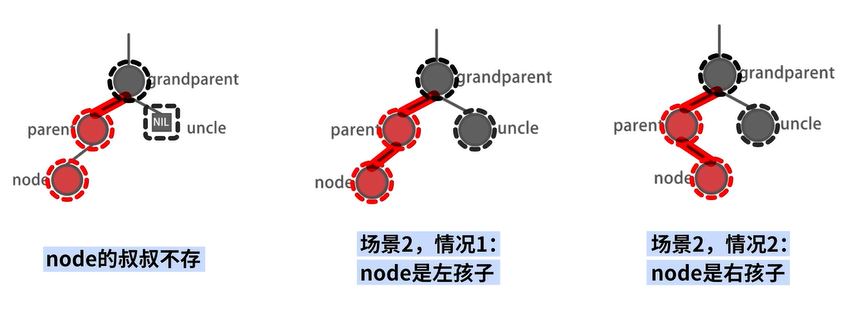
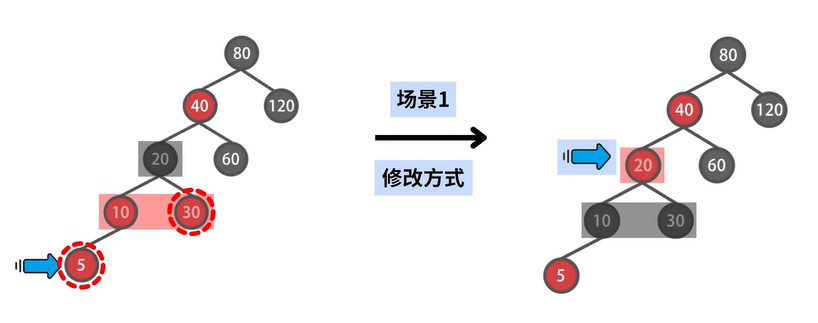
场景1:存在 uncle 结点
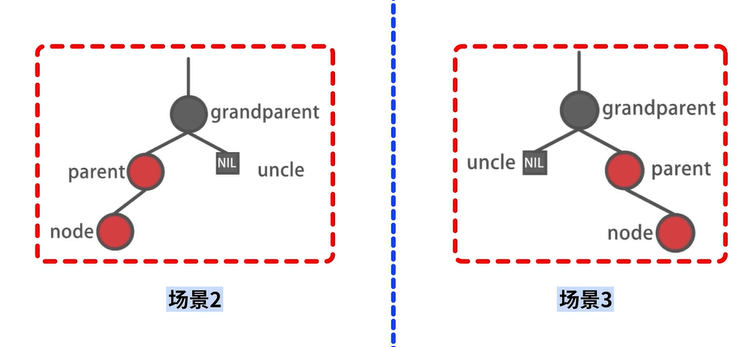
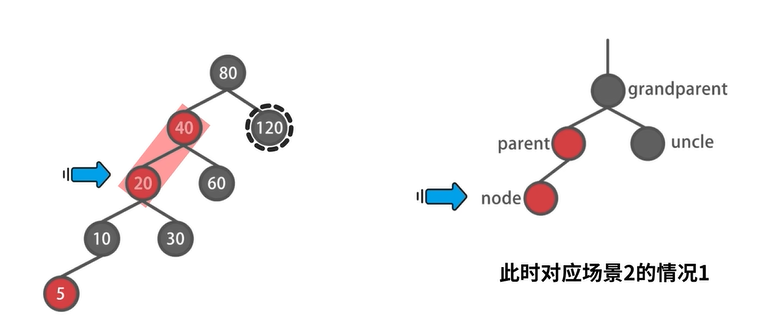
场景2-1:不存在 uncle 结点,自己是左孩子
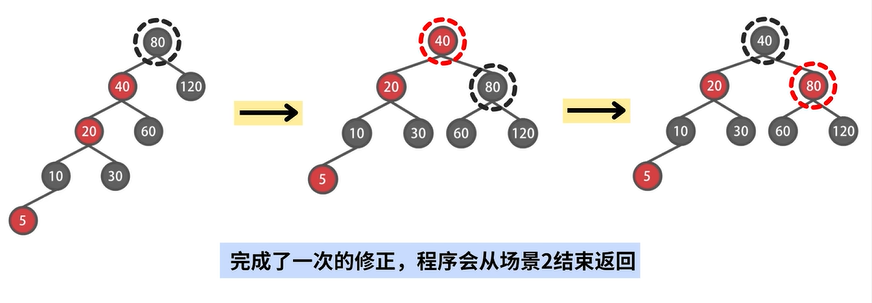
场景2-2:不存在 uncle 结点,自己是右孩子
注:黑色即被认为不存在。
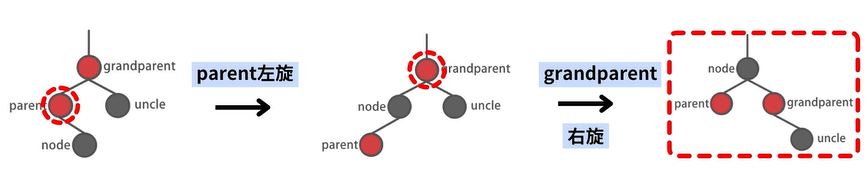
修正场景分析
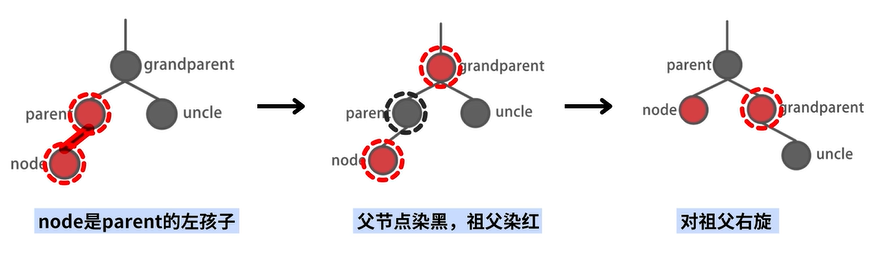
场景2-1:不存在 uncle 结点,自己是左孩子
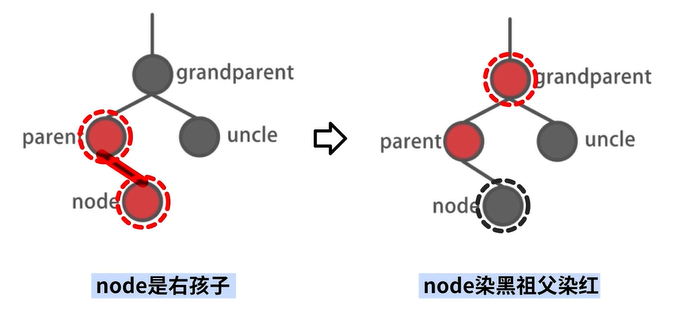
场景2-2:不存在 uncle 结点,自己是右孩子
其中,场景2-1 和场景2-2 的结果对比如下:
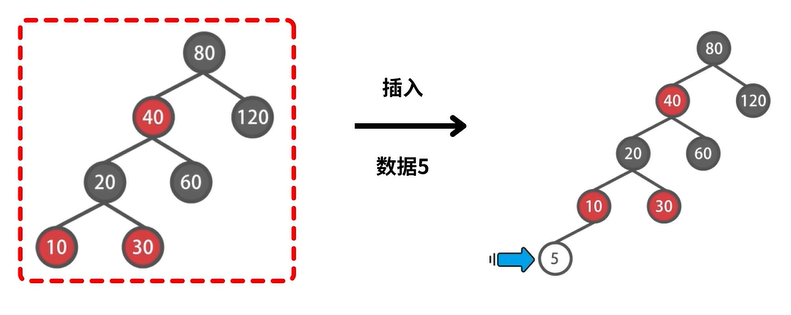
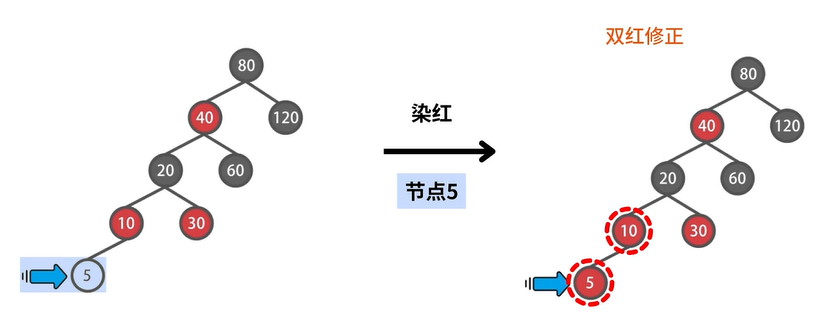
示例
代码:数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdio.h> typedef int Status;#define OK 1 #define ERROR 0 #define BLACK 0 #define RED 1 struct RBNode { int value; int color; RBNode *left; RBNode *right; RBNode *parent; int size; int cnt; RBNode (int _value) { value = _value; color = BLACK; left = NULL ; right = NULL ; parent = NULL ; size = 1 ; cnt = 1 ; } };
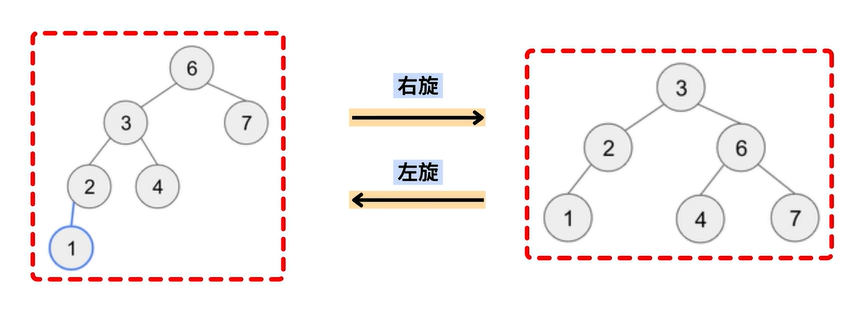
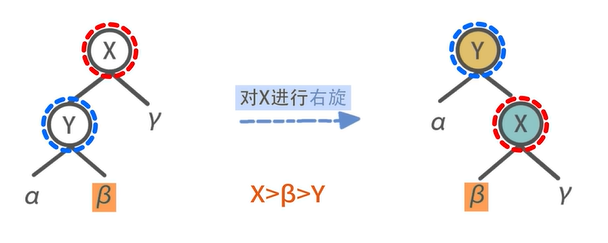
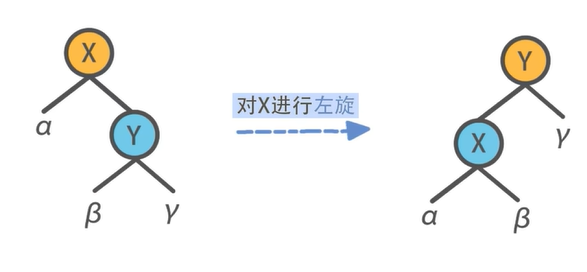
代码:左旋、右旋
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 Status Left_Rotate (RBNode *x, RBNode *&root) RBNode *y = x->right; x->right = y->left; if (y->left) y->left->parent = x; y->parent = x->parent; if (!x->parent) root = y; else { if (x == x->parent->left) x->parent->left = y; else x->parent->right = y; } x->parent = y; y->left = x; update_node_size (x); update_node_size (y); return OK; } Status Right_Rotate (RBNode *x, RBNode *&root) RBNode *y = x->left; x->left = y->right; if (y->right) y->right->parent = x; y->parent = x->parent; if (!x->parent) root = y; else { if (x == x->parent->left) x->parent->left = y; else x->parent->right = y; } x->parent = y; y->right = x; update_node_size (x); update_node_size (y); return OK; } Status update_node_size (RBNode *node) int size = node->cnt; if (node->left) size += node->left->size; if (node->right) size += node->right->size; node->size = size; return OK; } RBNode *uncle_node (RBNode *node) RBNode *parent = node->parent; RBNode *grandparent = parent->parent; if (parent == grandparent->left) return grandparent->right; else return grandparent->left; }
代码:双红修正
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 Status Fix_Double_Red (RBNode *node, RBNode *&root) while (1 ) { if (node == root) { node->color = BLACK; return OK; } RBNode *parent = node->parent; if (parent->color == BLACK) return OK; RBNode *grandparent = node->parent->parent; RBNode *uncle = uncle_node (node); if (uncle && uncle->color == RED) { parent->color = BLACK; uncle->color = BLACK; grandparent->color = RED; node = grandparent; } else { if (parent == grandparent->left) { if (node == parent->left) { parent->color = BLACK; grandparent->color = RED; Right_Rotate (grandparent, root); } else { node->color = BLACK; grandparent->color = RED; Left_Rotate (parent, root); Right_Rotate (grandparent, root); } } else { if (node == parent->right) { parent->color = BLACK; grandparent->color = RED; Left_Rotate (grandparent, root); } else { node->color = BLACK; grandparent->color = RED; Right_Rotate (parent, root); Left_Rotate (grandparent, root); } } return OK; } } return ERROR; }
代码:插入操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Status Node_Insert (RBNode *&root, RBNode *node) RBNode *ptr = root; while (ptr != node) { ptr->size++; if (node->value == ptr->value) { ptr->cnt++; return OK; } else if (node->value < ptr->value) { if (!ptr->left) { ptr->left = node; node->parent = ptr; } ptr = ptr->left; } else if (node->value > ptr->value) { if (!ptr->right) { ptr->right = node; node->parent = ptr; } ptr = ptr->right; } } node->color = RED; Fix_Double_Red (node, root); return OK; }
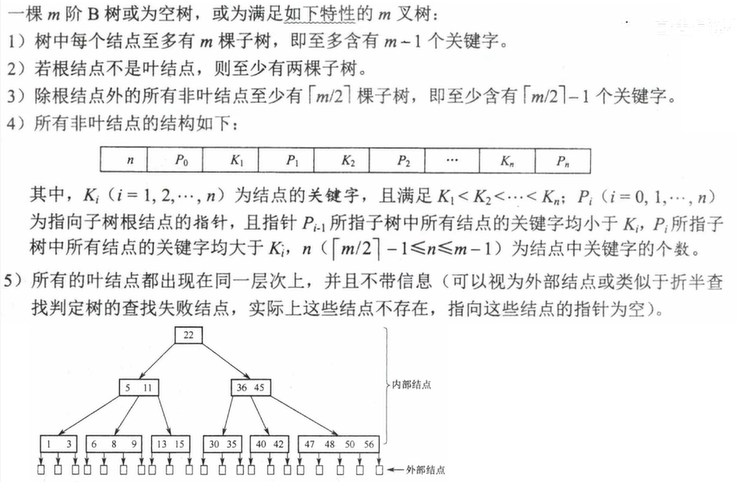
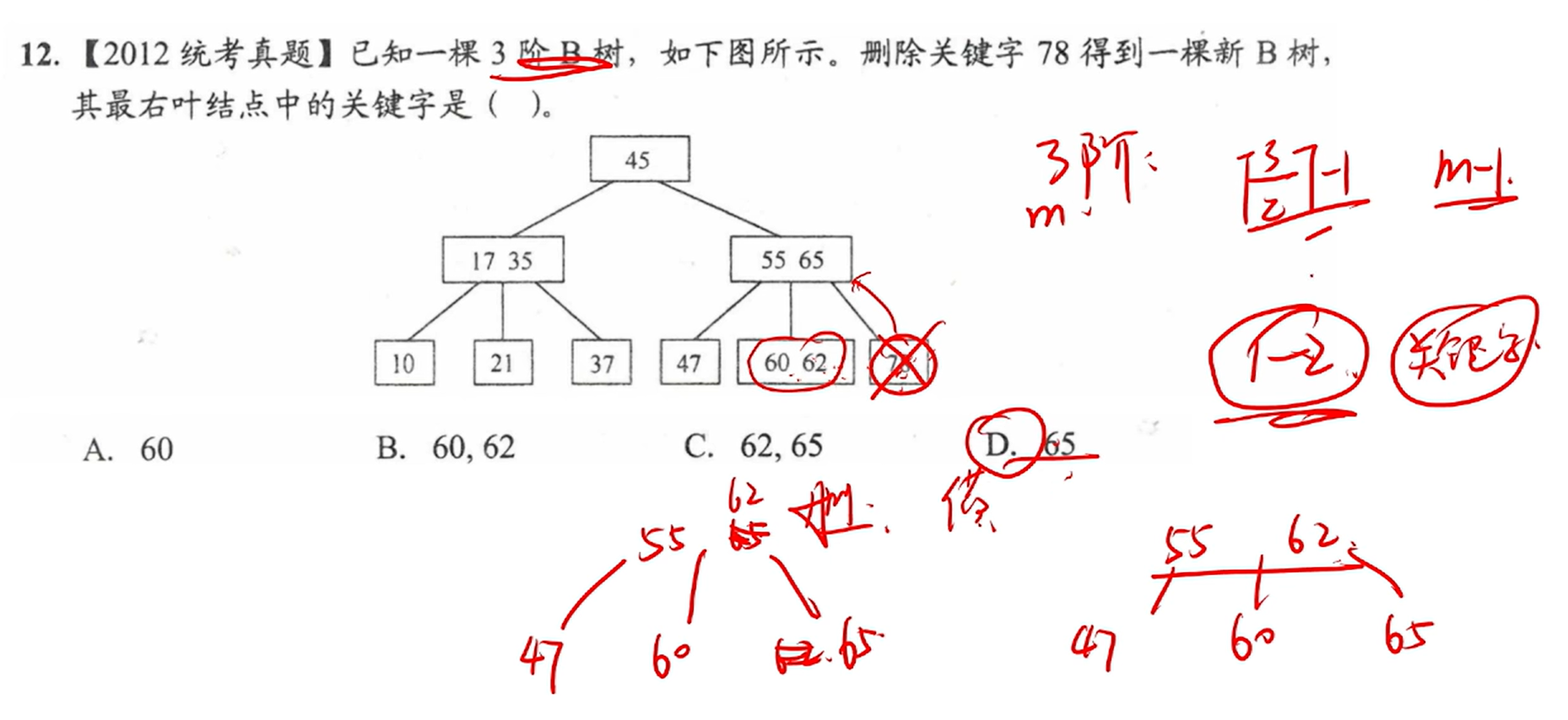
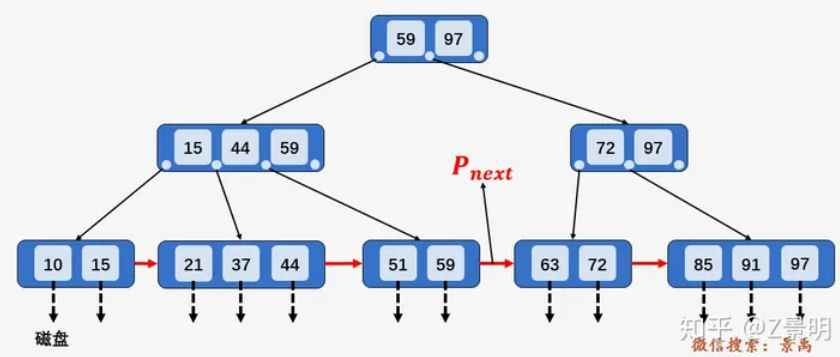
5.2.4 B树、B+树
定义
查找
查找包括两个基本操作
在B树中找结点
在结点内找关键字
插入
将关键字 key 插入 B树的过程:
定位
利用前述的 B树查找算法,找到插入该关键字的最底层的某个非叶结点
插入
在B树中,每个非失败结点的关键字个数都在区间[ m/2向上取整 - 1, m - 1]内。
插入后关键字个数小于 m:可以直接插入
否则:对结点进行分裂(B树高度+1)
删除
三种情况
直接删除关键字(删除后仍然是满足最小关键字个数)
兄弟够借:借、调整
兄弟不够借:合并
B+树
主要差异
在 B+树 中,具有 n 个关键字的结点只含有 n 棵子树,即每个关键字对应一棵子树;
而在B树 中,具有 n 个关键字的结点含有 n+1 棵子树。
在 B+树 中,每个结点(非根内部结点)的关键字个数 n 的范围是 m/2向上取整 <= n <= m
(而根结点是2 <= n <= m)
在 B树 中,每个结点(非根内部结点)的关键字个数 n 的范围是 m/2向上取整 <= n <= m-1
(而根结点是1 <= n <= m-1)
在 B+树 中,叶结点包含了全部关键字,非叶结点中出现的关键字也会出现在叶结点中;
而 B树 中,最外层的终端结点包含的关键字和其他结点包含的关键字是不重复的。
在 B+树 中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
5.3 散列结构
5.3.1 散列表(哈希表)
定义
根据关键字而直接进行访问的数据结构。
散列表建立了关键字和存储地址之间的一种直接映射关系。
时间复杂度
理想情况下,为O(1),即与表中元素个数无关。
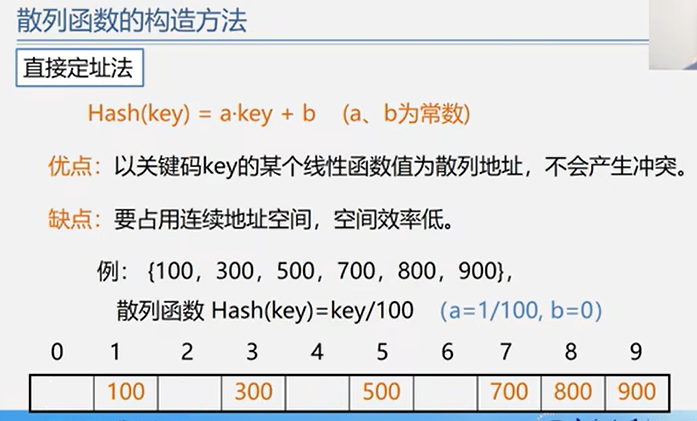
散列函数
一个把查找表中的关键字映射成该关键字对应的地址的函数。
记为 Hash(key) = Addr
冲突
散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称为冲突。
常用散列函数
直接定址法
除留余数法
数字分析法
平方取中法
折叠法
伪随机数法
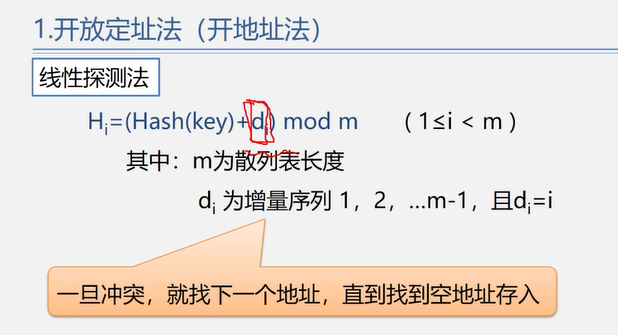
5.3.2 处理冲突
拉链法的优点:
非同义词不会冲突,无“聚集”现象
链表上结点空间动态申请,更适合于表长不确定的情况
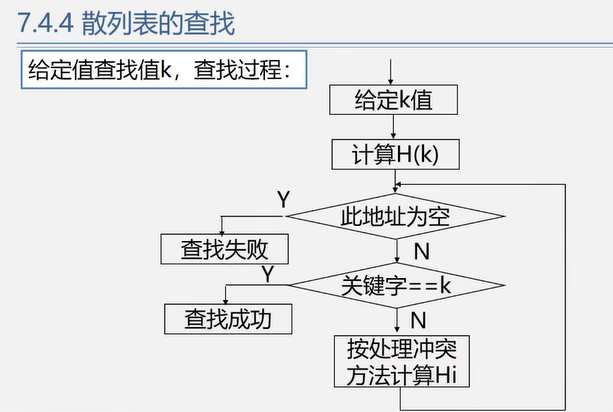
5.3.3 散列表的查找
流程
示例
效率分析
5.3.4 结论
散列表技术具有很好的平均性能 ,优于一些传统的技术链地址法 优于 开地址法除留余数法 作散列函数 优于 其他类型函数
六、排序
6.0 知识框架
6.1 插入排序
6.1.1 直接插入排序
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定
适用:顺序存储、链式存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Status InsertSort (ElemType A[], int n) int i, j; for (i=2 ; i<=n; i++) { if (A[i] < A[i-1 ]) { A[0 ] = A[i]; for (j=i-1 ; A[0 ]<A[j]; j--) A[j+1 ] = A[j]; A[j+1 ] = A[0 ]; } } return OK; }
6.1.2 折半插入排序
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定
适用:仅 顺序存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Status InsertSort (ElemType A[], int n) int i, j, low, high, mid; for (i=2 ; i<=n; i++) { A[0 ] = A[i]; low = 1 , high = i-1 ; while (low <= high) { mid = (low+high)/2 ; if (A[mid] > A[0 ]) high = mid-1 ; else low = mid + 1 ; } for (j=i-1 ; j>=high+1 ; j--) A[j+1 ] = A[j]; A[high+1 ] = A[0 ]; } return OK; }
6.1.3 希尔排序
又称“缩小增量排序”
基本思想:先将待排序表按间隔取记录,分割成若干[i, i+d, i+2d, i+3d, ...]的特殊子表,对各个子表分别进行直接插入排序,此时,就会总体呈现“基本有序”,再对全体记录(也相当于d=1)进行直接插入排序。
时间复杂度:O(n^1.3)
空间复杂度:O(1)
稳定性:不稳定
适用:仅 顺序存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Status ShellSort (ElemType A[], int n) int dk, i, j; for (dk=n/2 ; dk>=1 ; dk=dk/2 ) { for (i=dk+1 ; i<=n; ++i) { if (A[i] < A[i-dk]) { A[0 ] = A[i]; for (j=i-dk; j>0 && A[0 ]<A[j]; j-=dk) A[j+dk] = A[j]; A[j+dk] = A[0 ]; } } } return OK; }
6.2 交换排序
6.2.1 冒泡排序
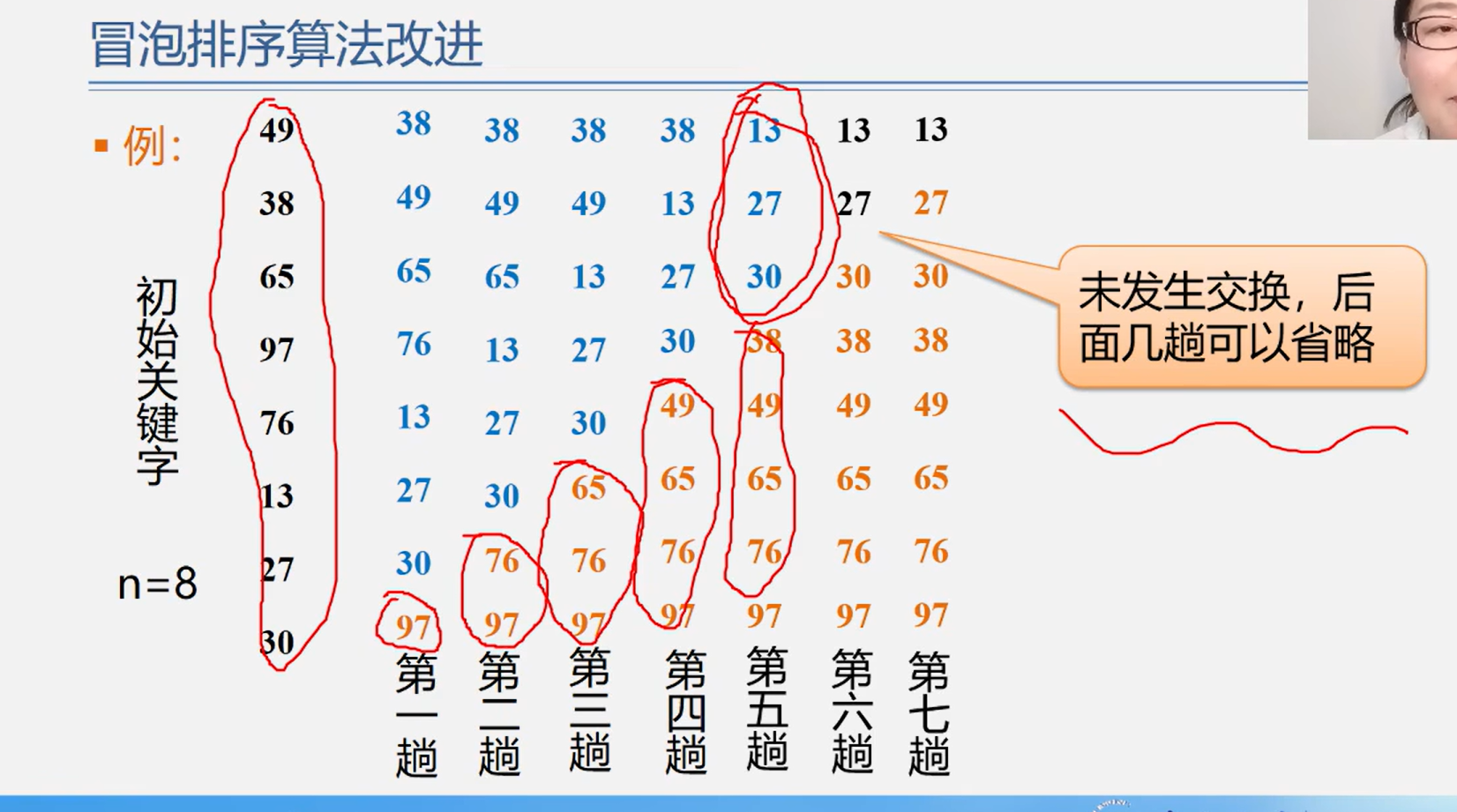
基本思想:
从后往前,两两比较相邻元素,若是逆序则交换位置,此次结果会把最小的换到第一个位置。而后第一个元素不动,继续…
每一趟冒泡的结果是把序列中最小元素放到了序列的最终位置。下一趟冒泡时,前一趟已经确定的元素不再参与。如此最多做n-1趟就能把所有元素排好序。
优化:
若在某一趟中,没有发生任何交换,说明已经排序好了,可以提前结束。
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定
1 2 3 4 5 6 7 8 9 10 11 Status BubbleSort (ElemType A[], int n) bool flag = true ; for (int i=0 ; i<n-1 && flag; i++) { flag = false ; for (int j=n-1 ; j>i; j--) if (A[j-1 ] > A[j]) swap (A[j-1 ], A[j]), flag = true ; } }
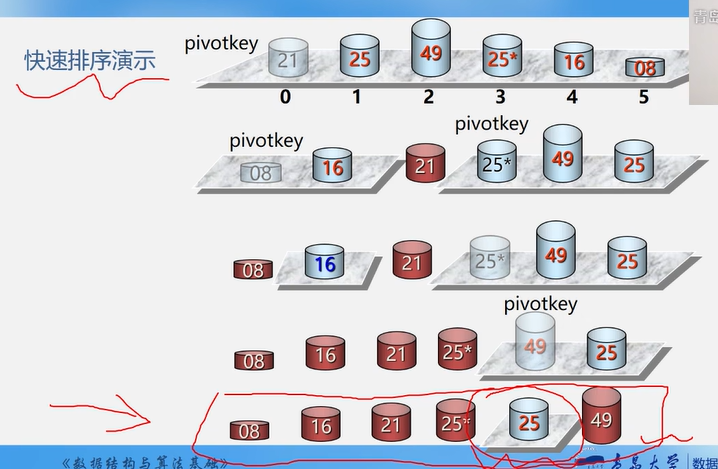
6.2.2 快速排序
快速排序不是自然排序(自然排序:最初序列越有序,则排序越快)
快速排序在最初序列有序时,反而是更慢!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Status QuickSort (ElemType A[], int low, int high) if (low < high) { int pivotpos = Partition (A, low, high); QuickSort (A, low, pivotpos-1 ); QuickSort (A, pivotpos+1 , high); } return OK; } int Partition (ElemType A[], int low, int high) ElemType pivot = A[low]; while (low < high) { while (low < high && A[high] >= pivot) high--; A[low] = A[high]; while (low < high && A[low] <= pivot) low++; A[high] = A[low]; } A[low] = pivot; return low; }
6.3 选择排序
基本思想:
每一趟(如第 i 趟)在后面 n-i+1( i =1,2,3,…,n-1)个排序元素中选取关键字最小的元素,作为有序子序列的第 i 个元素,直到第 n-1 趟做完,待排序元素只剩下 1 个,就排序完成了。
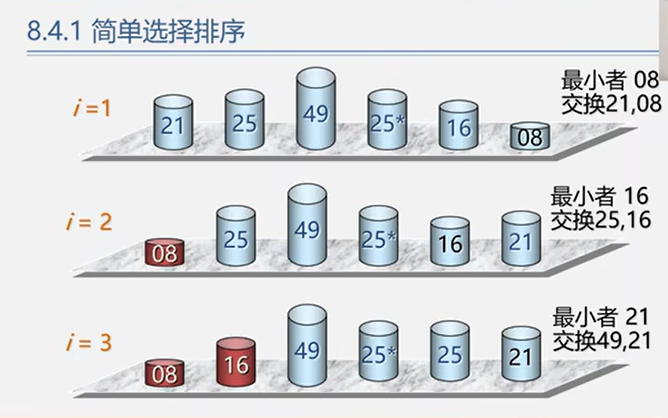
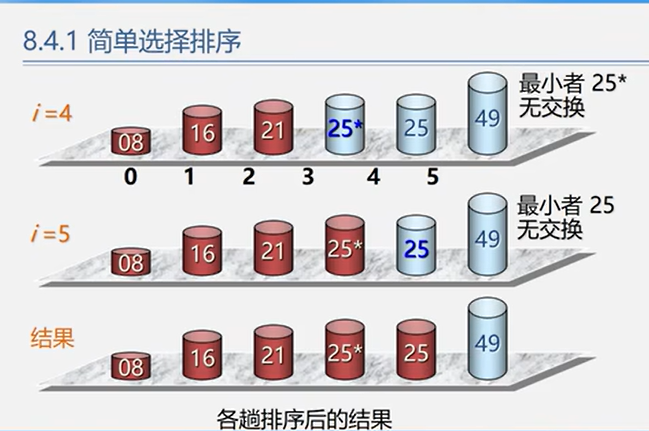
6.3.1 简单选择排序
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:不稳定
1 2 3 4 5 6 7 8 9 10 11 12 13 Status SelectSort (ElemType A[], int n) for (int i=0 ; i<n-1 ; i++) { int min = i; for (int j=i+1 ; j<n; j++) if (A[j] < A[min]) min = j; if (min != i) swap (A[i], A[min]); } return OK; }
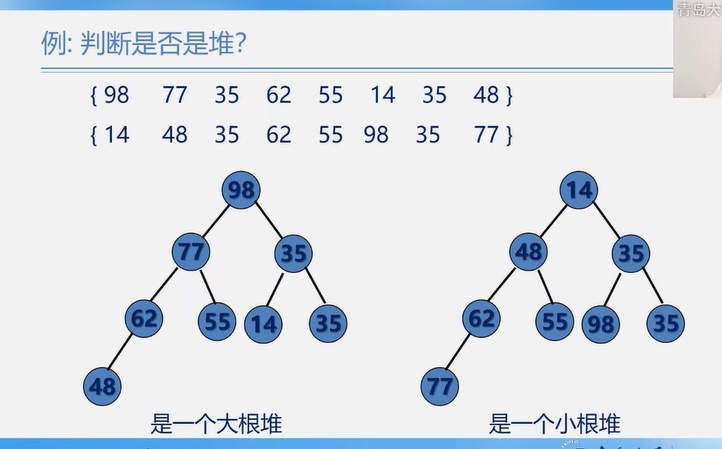
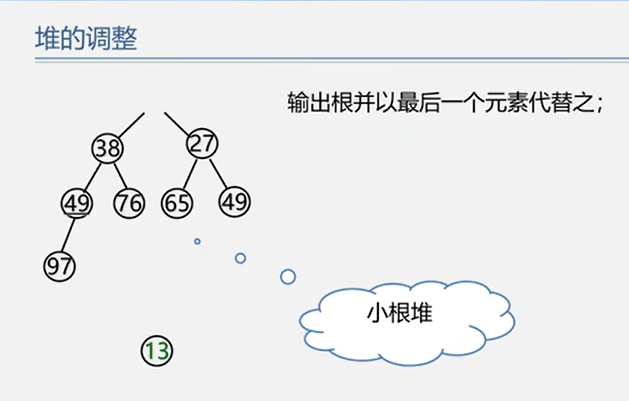
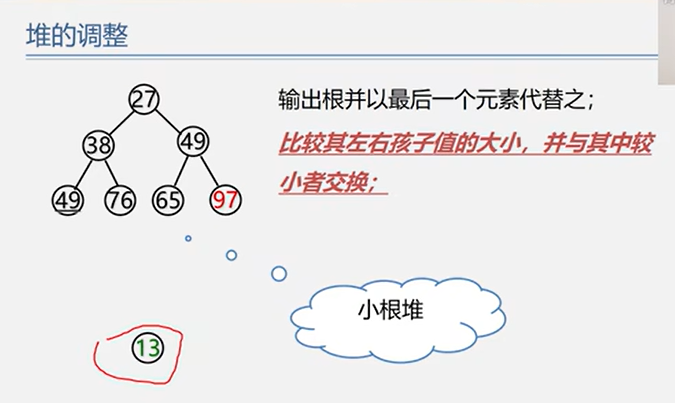
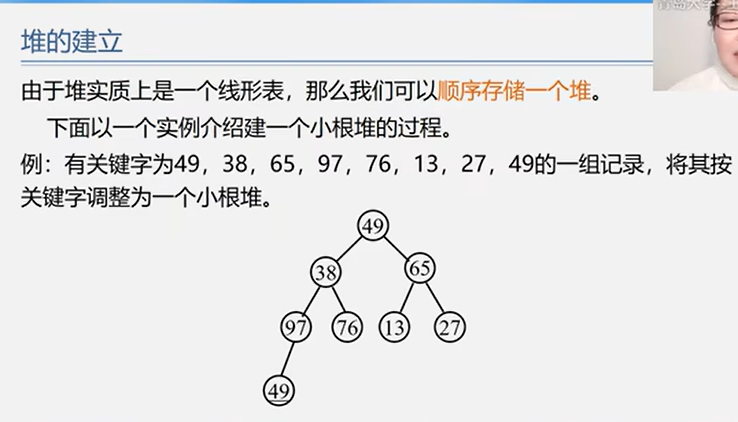
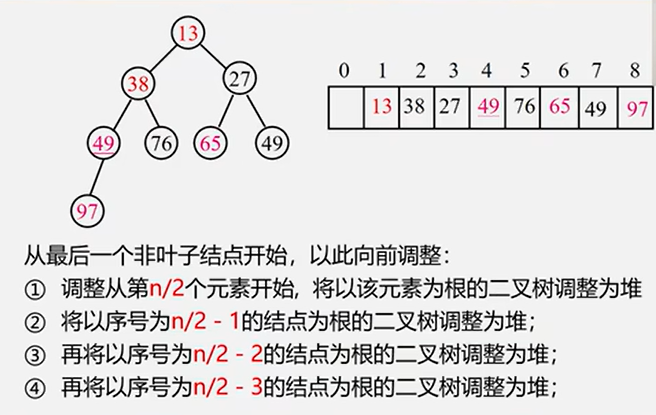
6.3.2 堆排序
注:虽然堆排序的逻辑结构是树形结构,但是存储结构是顺序存储!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 Status BuildMaxHeap (ElemType A[], int len) for (int i=len/2 ; i>0 ; i--) HeadAdjust (A, i, len); return OK; } Status HeadAdjust (ElemType A[], int k, int len) A[0 ] = A[k]; for (int i=2 *k; i<=len; i*=2 ) { if (i < len && A[i] < A[i+1 ]) i++; if (A[0 ] >= A[i]) break ; else { A[k] = A[i]; k = i; } } A[k] = A[0 ]; return OK; } Status HeapSort (ElemType A[], int len) BuildMaxHeap (A, len); for (int i=len; i>1 ; i--) { Visit (A[1 ]); swap (A[i], A[1 ]); HeadAdjust (A, 1 , i-1 ); } return OK; }
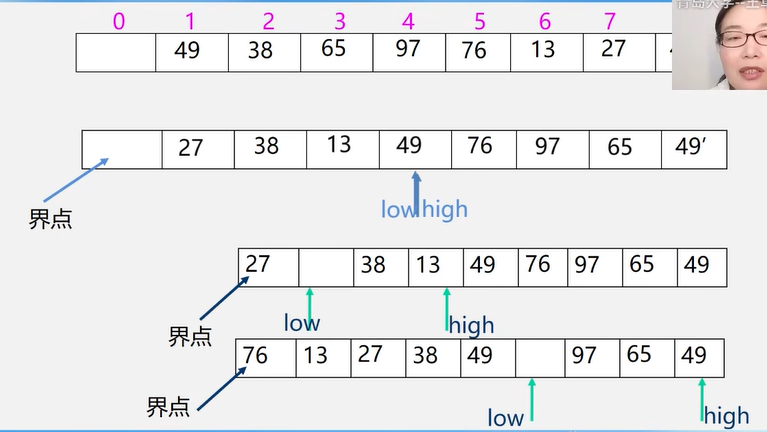
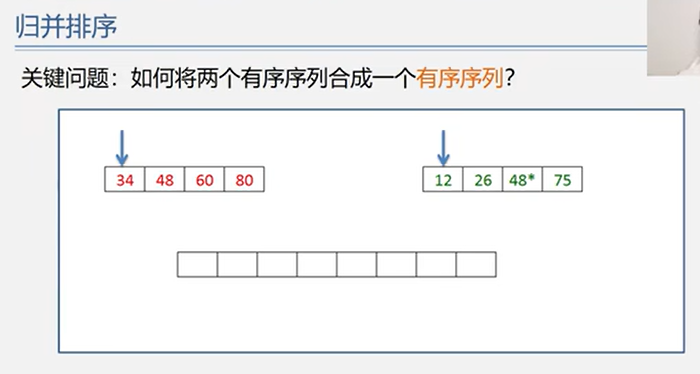
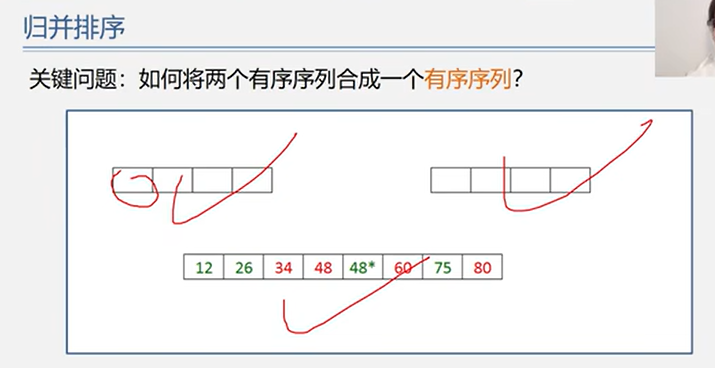
6.4 归并排序
又称“2 路归并排序”
时间复杂度:O(n log2 n)
空间复杂度:O(n)
稳定性:稳定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Status Merge (ElemType A[], int low, int mid, int high) ElemType *B = (ElemType*)malloc ( (n+1 ) * sizeof (ElemType) ); int i, j, k; for (k=low; k<=high; k++) B[k] = A[k]; for (i=low, j=mid+1 , k=i; i<=mid && j<=high; k++) { if (B[i] <= B[j]) A[k] = B[i++]; else A[k] = B[j++]; } while (i <= mid) A[k++] = B[i++]; while (j <= high) A[k++] = B[j++]; } Status MergeSort (ElemType A[], int low, int high) if (low < high) { int mid = (low+high)/2 ; MergeSort (A, low, mid); MergeSort (A, mid+1 , high); Merge (A, low, mid, high); } }
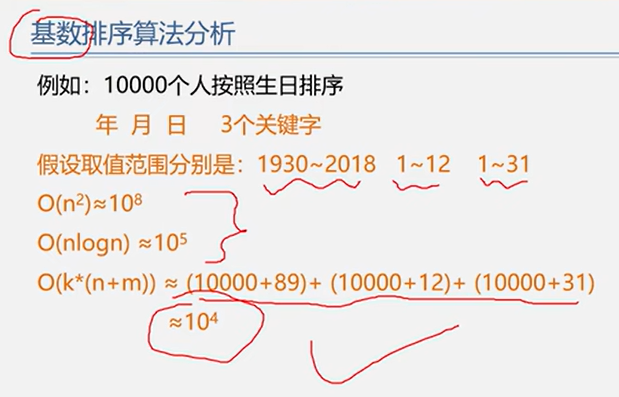
6.5 基数排序
基本思想:
借助多关键字排序的思想对单逻辑关键字进行排序。
示例1
示例2
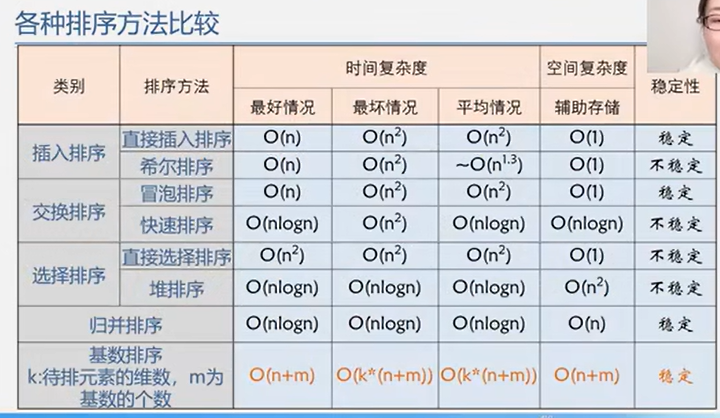
6.6 总结
6.6.1 性能对比
6.6.2 时间性能
当最初序列已经有序时,直接插入排序、冒泡排序能达到O(n)的效果;
而此时,快速排序反而退化为最差效果O(n^2)。
简单选择排序、堆排序、归并排序的时间性能与最初分布无关。
6.6.3 空间性能
O(1)
所有简单排序(直接插入、冒泡、简单选择)、堆排序
O(rd)
链式基数排序(队头队尾指针)
O(log n)
快速排序
O(n)
归并排序
6.6.4 稳定性
当有多关键字排序时,必须采用稳定排序。
证明排序不稳定,只需要举出例子即可。
不稳定的排序有:
折半插入排序、希尔排序、快速排序、简单选择排序、堆排序



















 微信支付
微信支付 支付宝
支付宝