
《PyTorch入门教程》
《PyTorch入门教程》
来源 : PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
代码参考:Github | PyTorch-Tutorial 代码
2024-01-30@isSeymour
一、安装初步
关于环境问题,下面这个文章讲的挺好的:
1.1 安装与环境
Anaconda
-
镜像源
1 | 查看镜像源 |
CUDA 显卡驱动
安装完成,cmd下检测:
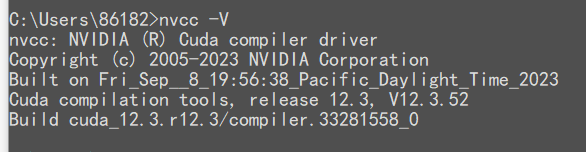
版本查询
1 | 查看python版本(不必,现在的PyTorch不区分python版本了) |
1.2 创建工作环境
CMD下创建Python 环境
1 | 创建环境 |
1.3 下载PyTorch
-
到官网PyTorch 官网寻找对应版本,执行安装
在对应的工作环境(我的是
PyTorchEnv)中执行安装包操作
1 | conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia |
- 安装完成,会出现一个
done字符
若下载太慢:
更改镜像源
下载到本地,然后放入
Anaconda3\pkgs\文件夹下,然后cmd下使用
conda install --user-local 包名,即可安装完成(本地安装)若使用pip安装,也可以切换镜像源
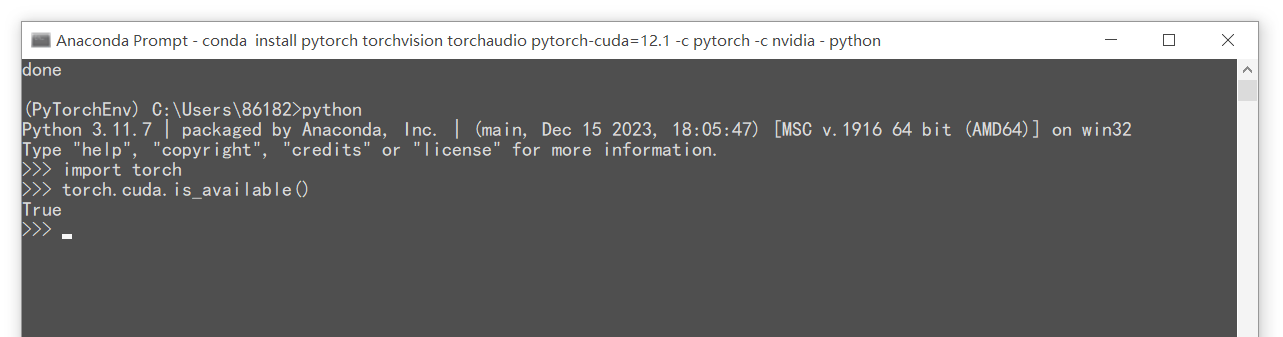
1.4 测试
- 进入交互模式,查看是否可用GPU
1 | python |
返回True,说明成功!
可以开始你的 PyTorch 之旅了!
如果没有Nvidia显卡,
torch.cuda.is_available()就是False,是正确的。 即便没有显卡,也是可以往后面学习的。
二、编辑器选择
-
PyCharm
-
Jupyter
若安装了Anaconda则会有Jupyter
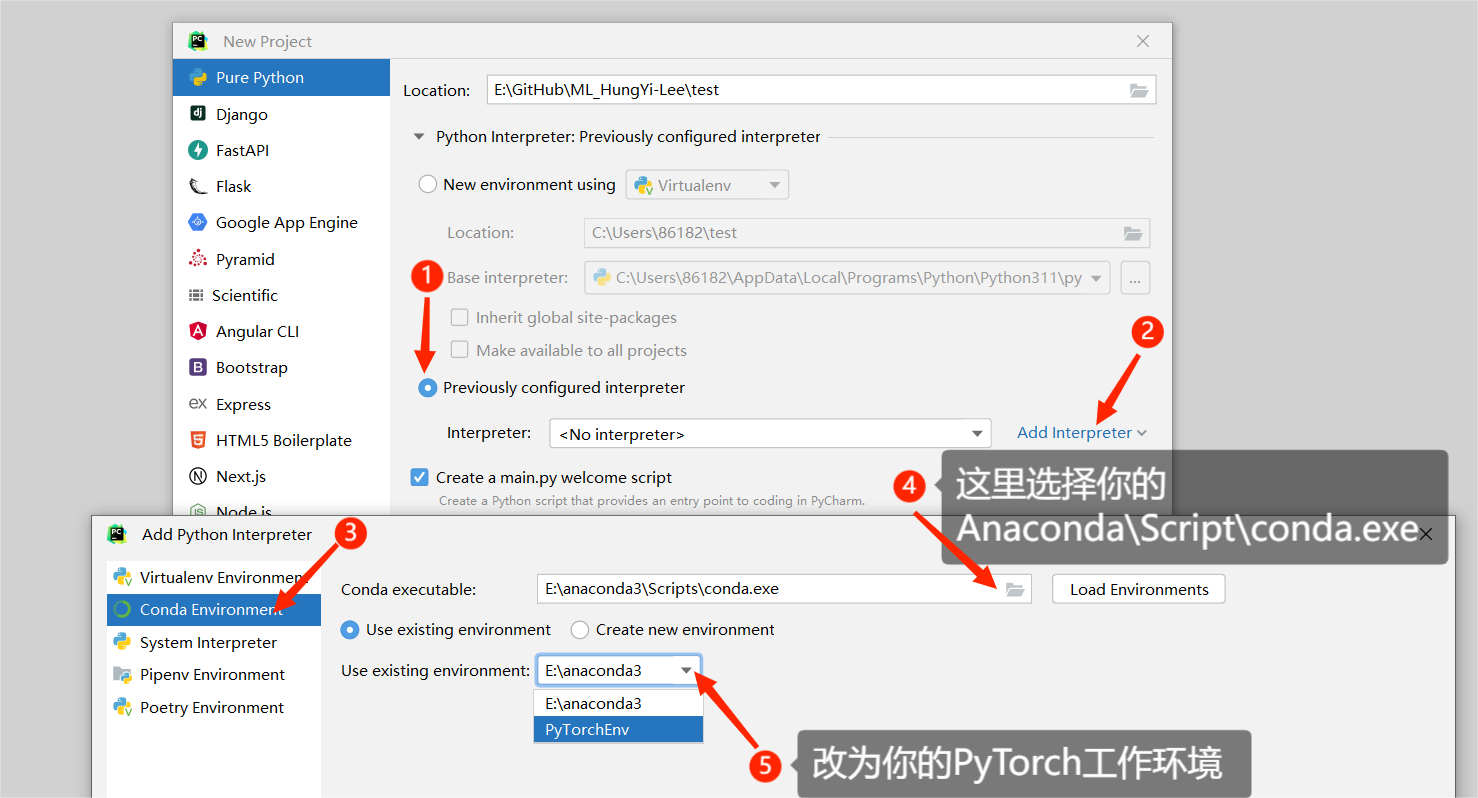
2.1 PyCharm
- 创建新的Project时
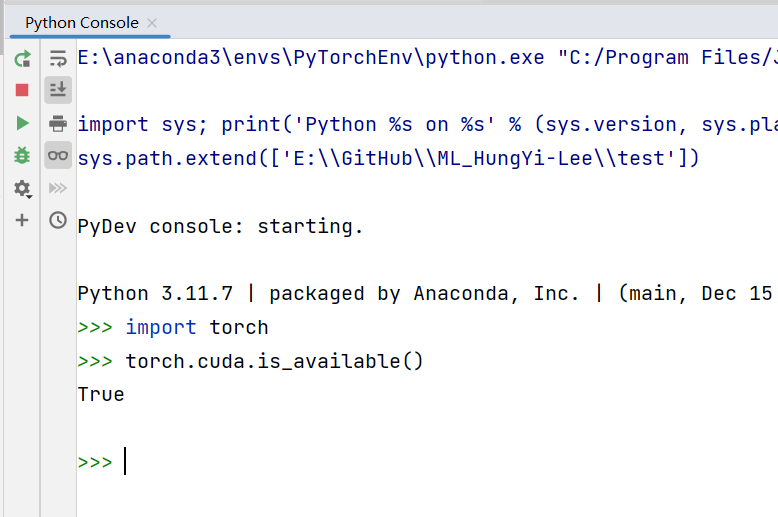
- 测试
2.2 Jupyter
-
打开Anaconda 的prompt 命令行,切换到 工作环境(PyTorchEnv),
然后安装 jupyter的工作包
1 | 激活工作环境 |
- 运行打开
1 | jupyter notebook |
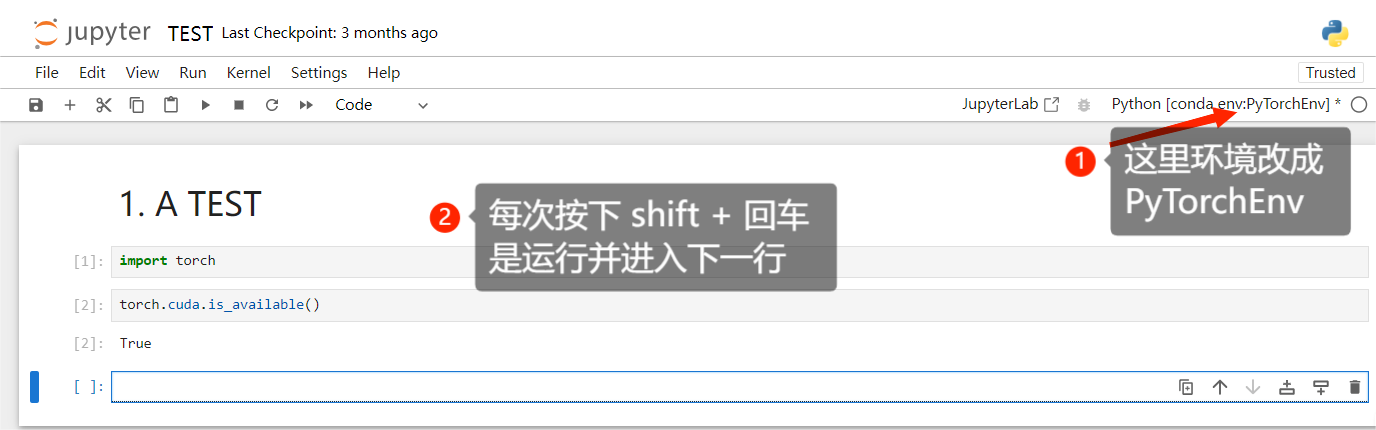
2.3 对比
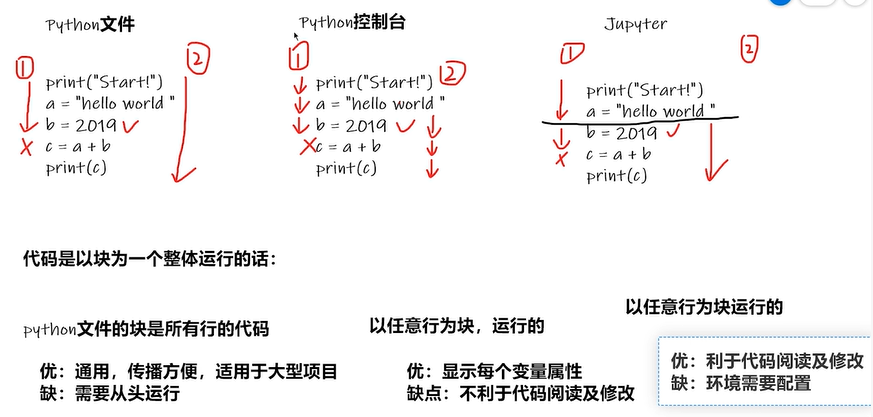
2.4 关于包的帮助
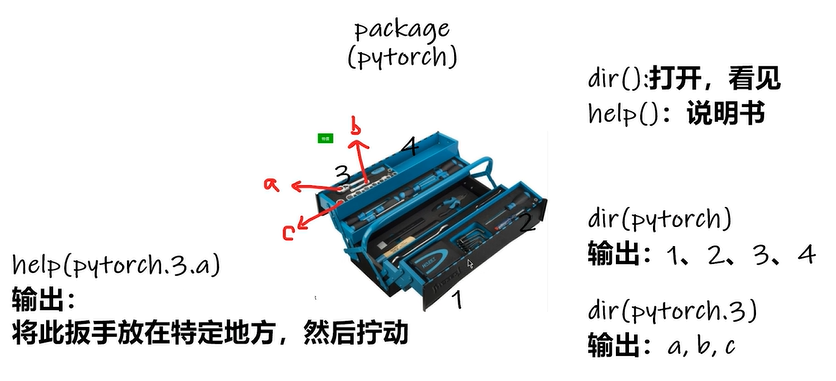
1 | dir(torch) |
三、基本使用
- 基本认知:
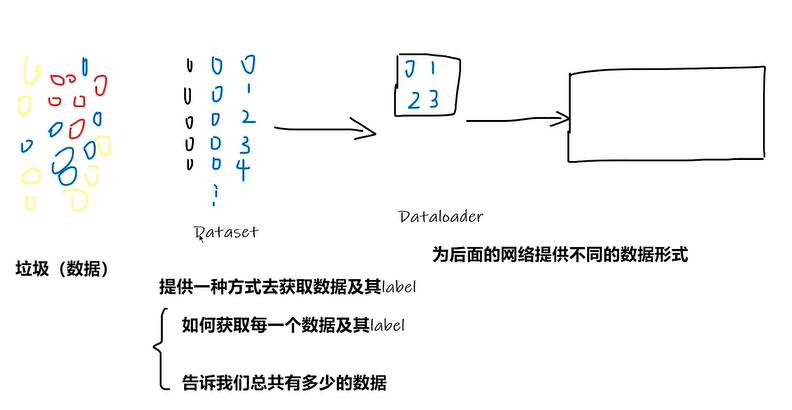
3.1 自定义数据集 Dataset
1 | from torch.utils.data import Dataset |
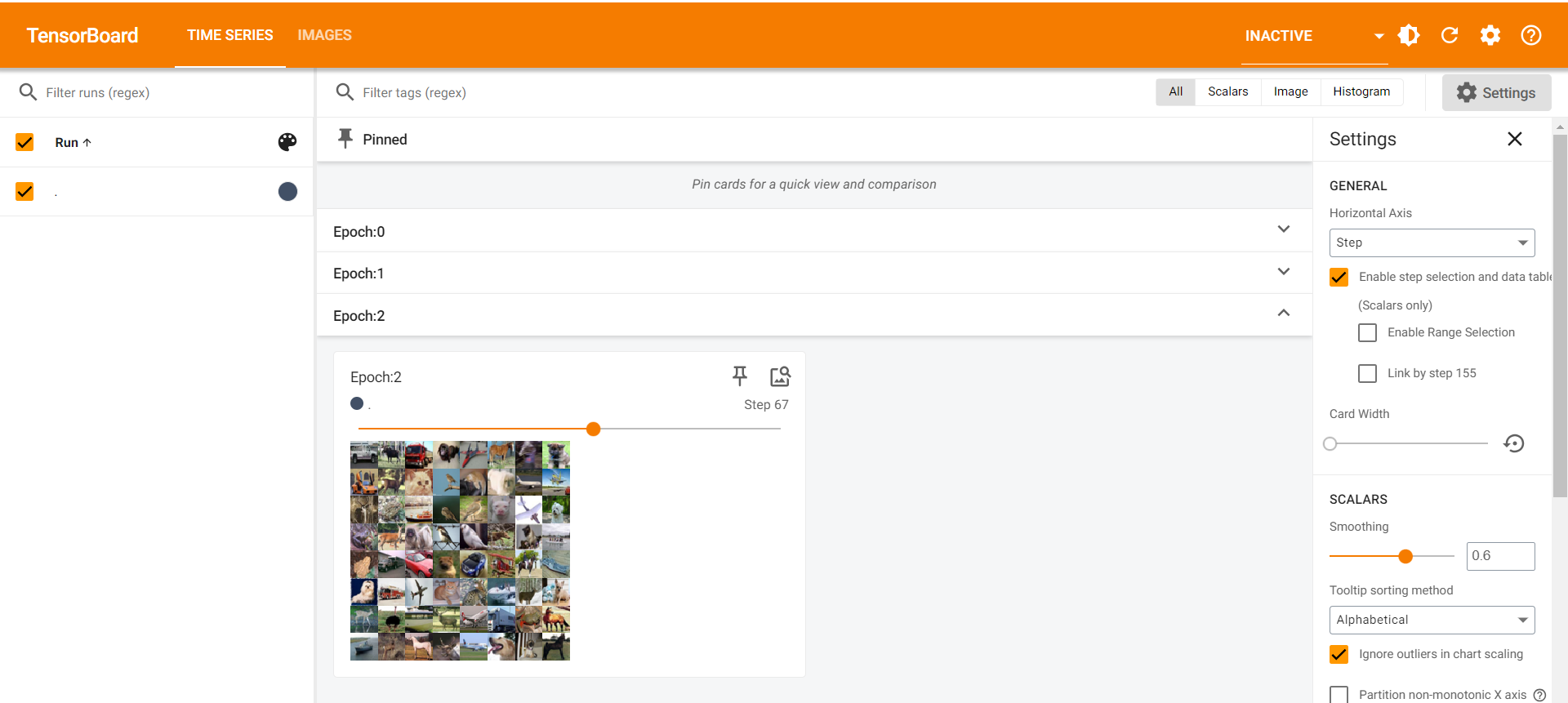
3.2 数据看板 TensorBoard
add_scalar()
安装TensorBoard
1 | from torch.utils.tensorboard import SummaryWriter |
- 运行上述代码后,会在当前目录下生成
log目录下的数据文件:
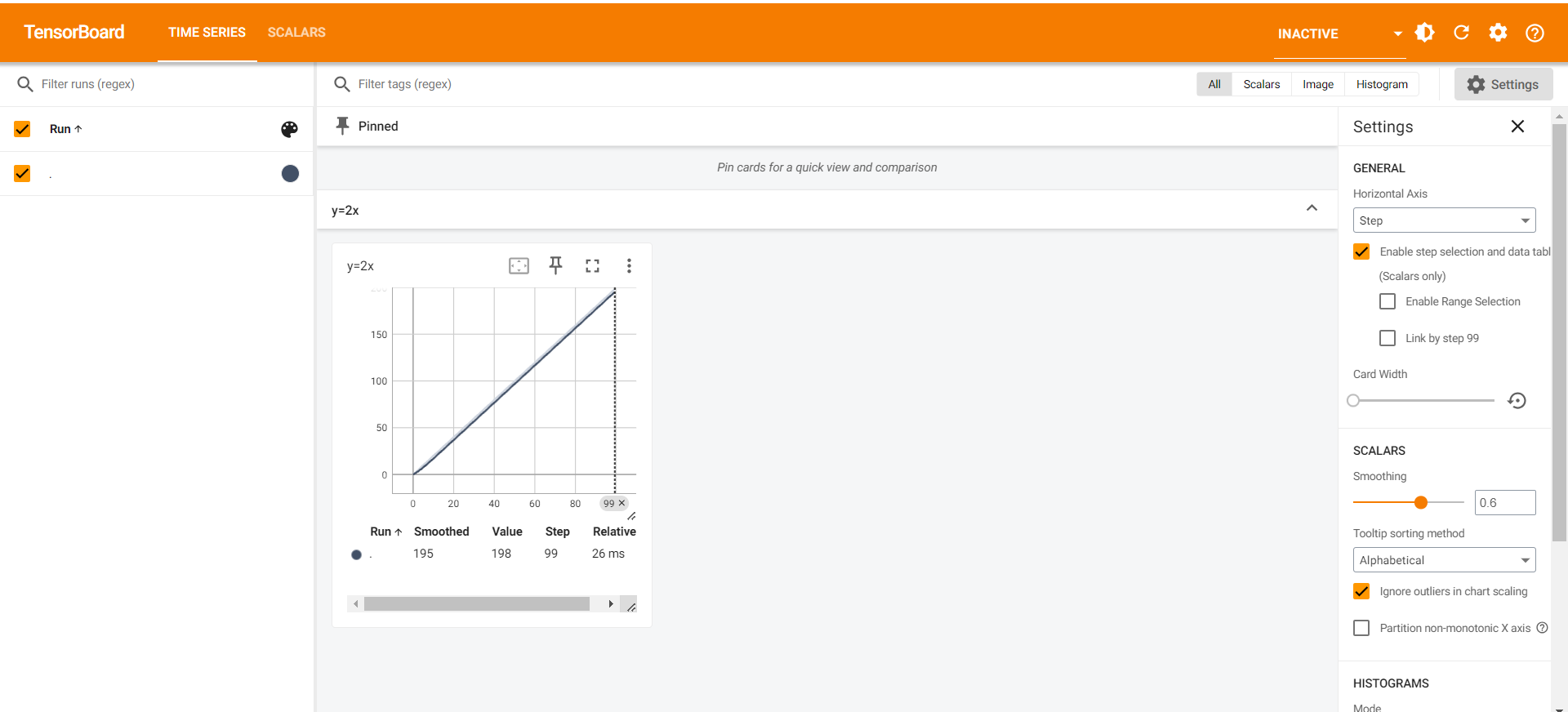
- 然后在当前环境(PyTorchEnv)的终端下,执行下面的命令,把数据进行展示:
1 | tensorboard --logdir=logs --port=6007 |
数据文件是并不会删除的,而是每次都是
添加状态。不同的
tag标识,会生成logs下的不同数据文件;对于相同的
tag标识的数据,会不断在对应的数据文件向后追加。每次运行代码,会进行一次新的追加,而展示时会自动进行拟合,
因此数据展示会有问题。
解决方法:
手动删除对应的数据文件(若发现无法删除,需要先关闭tensorboard)
Crtl + C 关闭
add_image()
练手数据集:
1 | from torch.utils.tensorboard import SummaryWriter |
1 | <class 'numpy.ndarray'> |
- 然后在当前环境(PyTorchEnv)的终端下,执行下面的命令,把数据进行展示:
1 | tensorboard --logdir=logs2 --port=6007 |
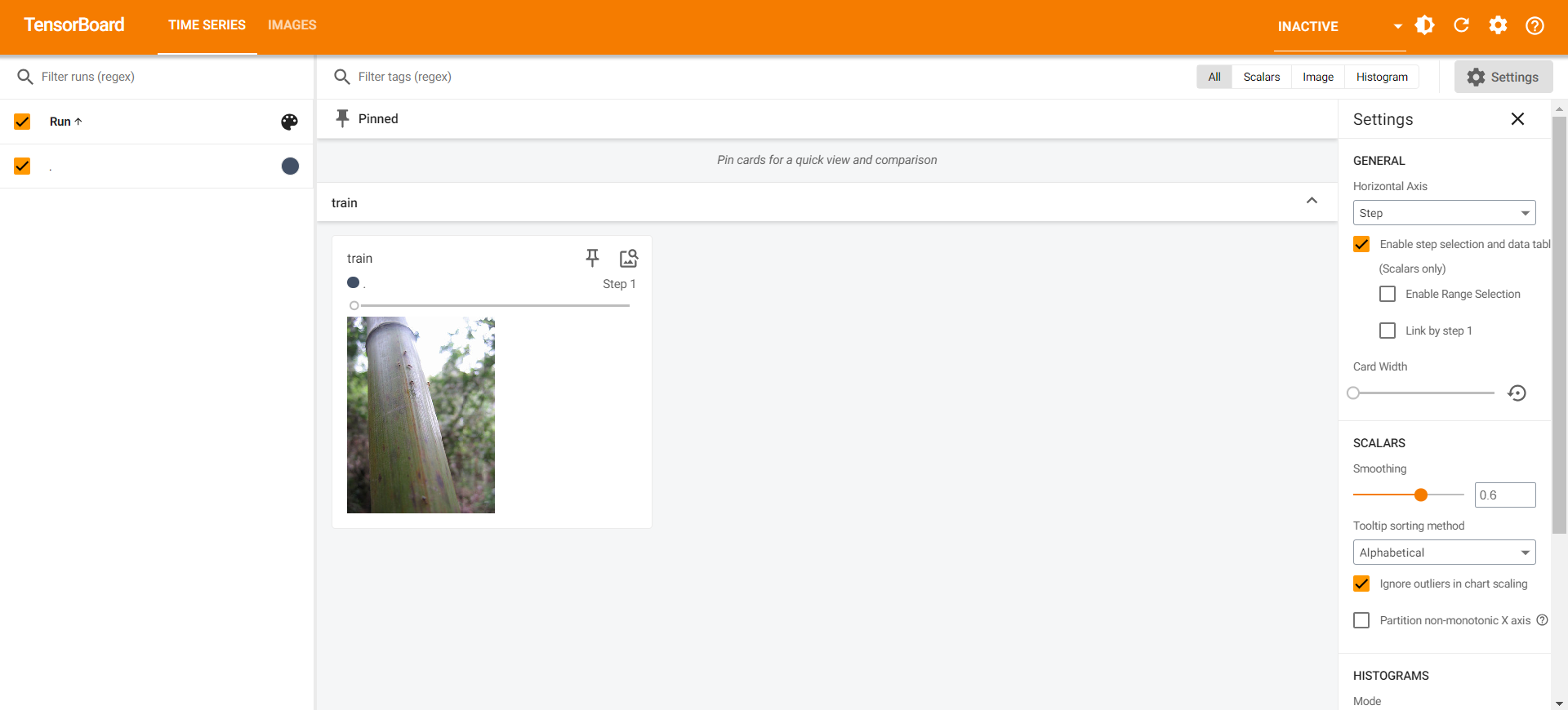
注:
PIL的Image类型是不可以作为输入数据的,类型不符合。需要转换为
numpy.ndarray类型。输入的
img_tensor只能是torch.Tensor, numpy.ndarray, or string/blobname。注意查看数据的shape,要和对应参数匹配。
2
(3通道,高度,宽度) CHW
3.3 图片转换 Transforms
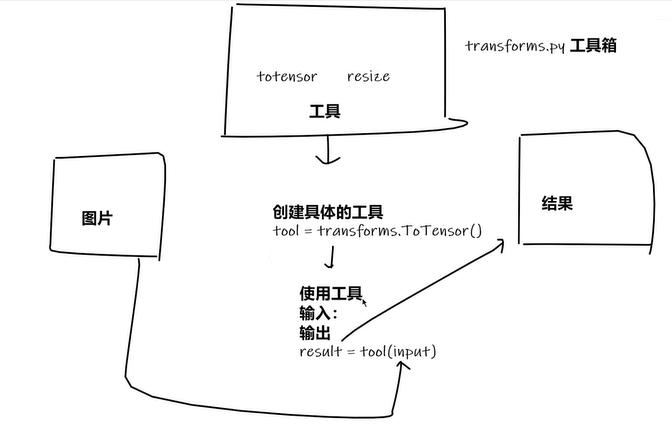

按住Alt,可点击进入对应的package查看源代码。
PyCharm左侧的Structure可以查看类、函数、属性结构,并定位。
ToTensor()
-
Convert a PIL Image or ndarray to tensor and scale the values accordingly.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
转换PIL 或ndarray 为 tensor 数据类型,用于后续处理(如SummaryWriter的添加)
```python
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "hymenoptera_data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs3")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
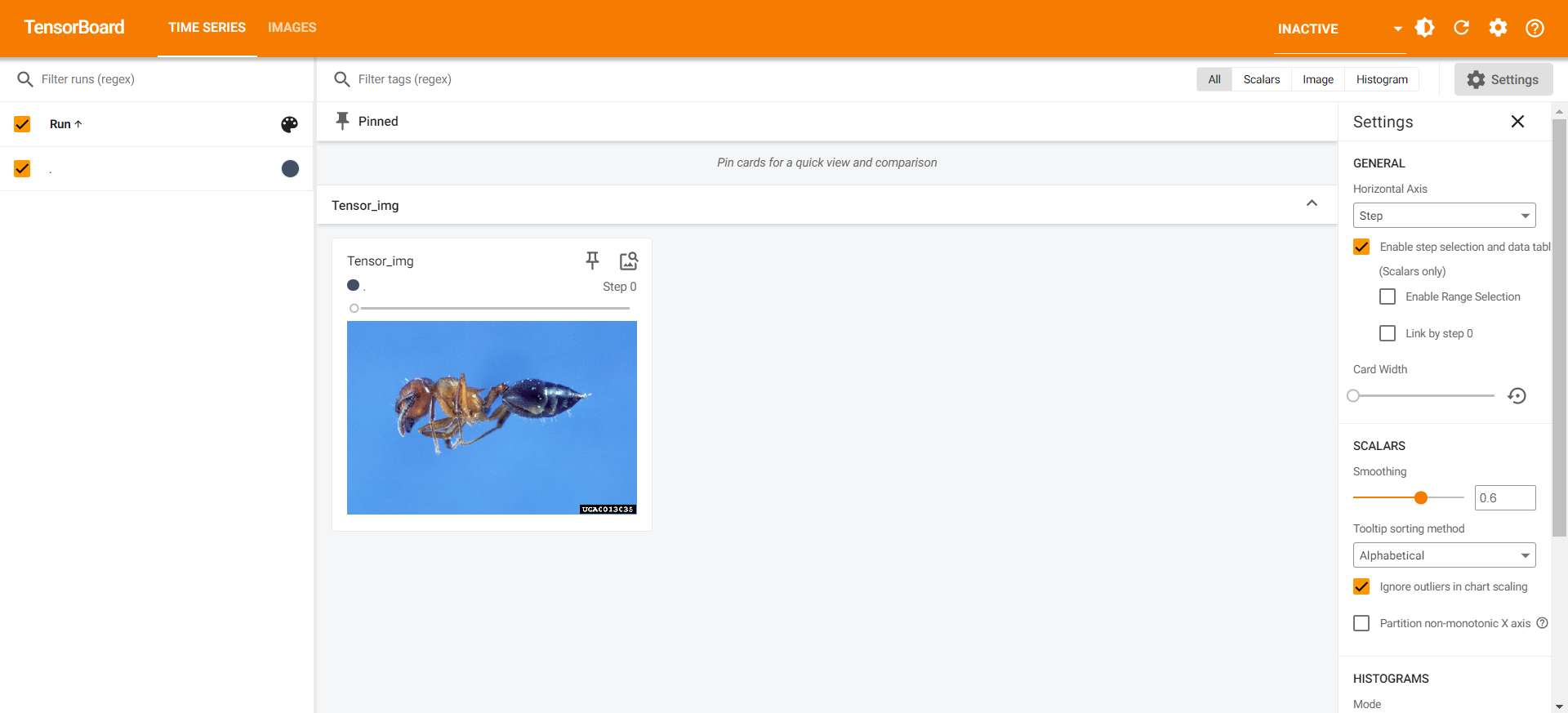
writer.add_image("Tensor_img", tensor_img)
writer.close()
1 | tensorboard --logdir=logs3 |
Normalize()
- 归一化处理
1 | from PIL import Image |
1 | <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x450 at 0x1F80D45F1D0> |
1 | tensorboard --logdir=logs4 |
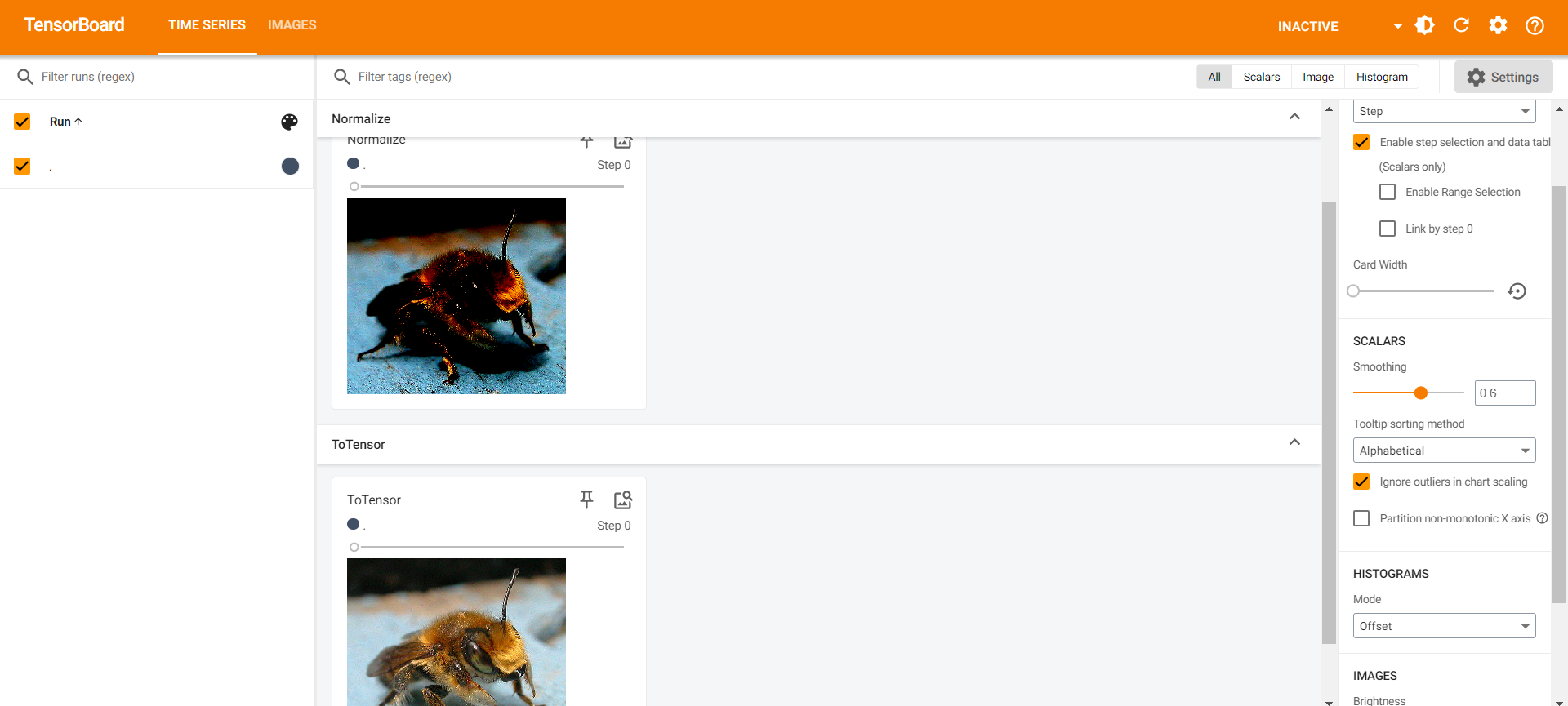
可以改动参数,查看不同情况:
2
3
4
5
trans_norm = transforms.Normalize([6, 3, 2], [9, 3, 5]) # 改动参数
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 1) # 改动步骤
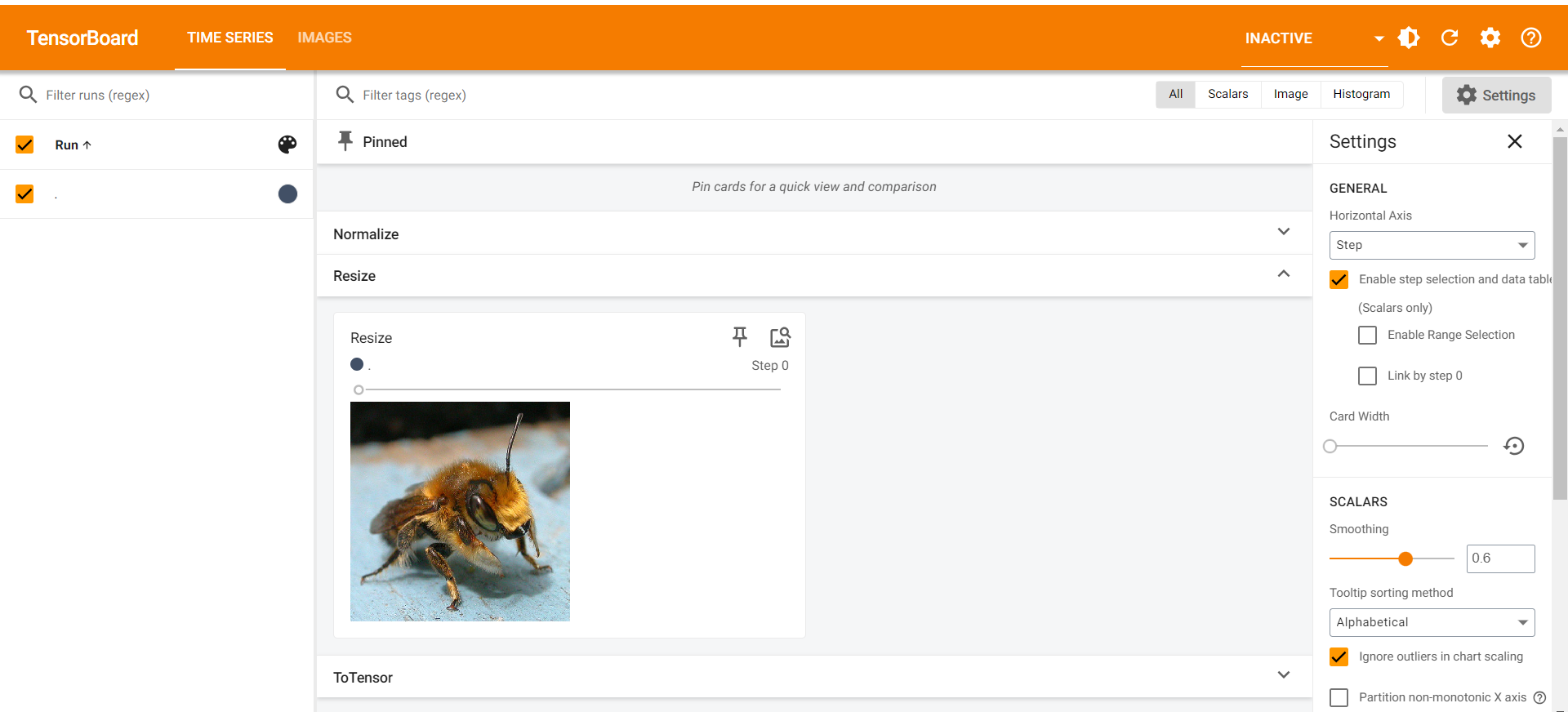
Resize()
- 改变图片大小
- 参数:序列或者int
1 | from PIL import Image |
1 | <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x450 at 0x2760C376750> |
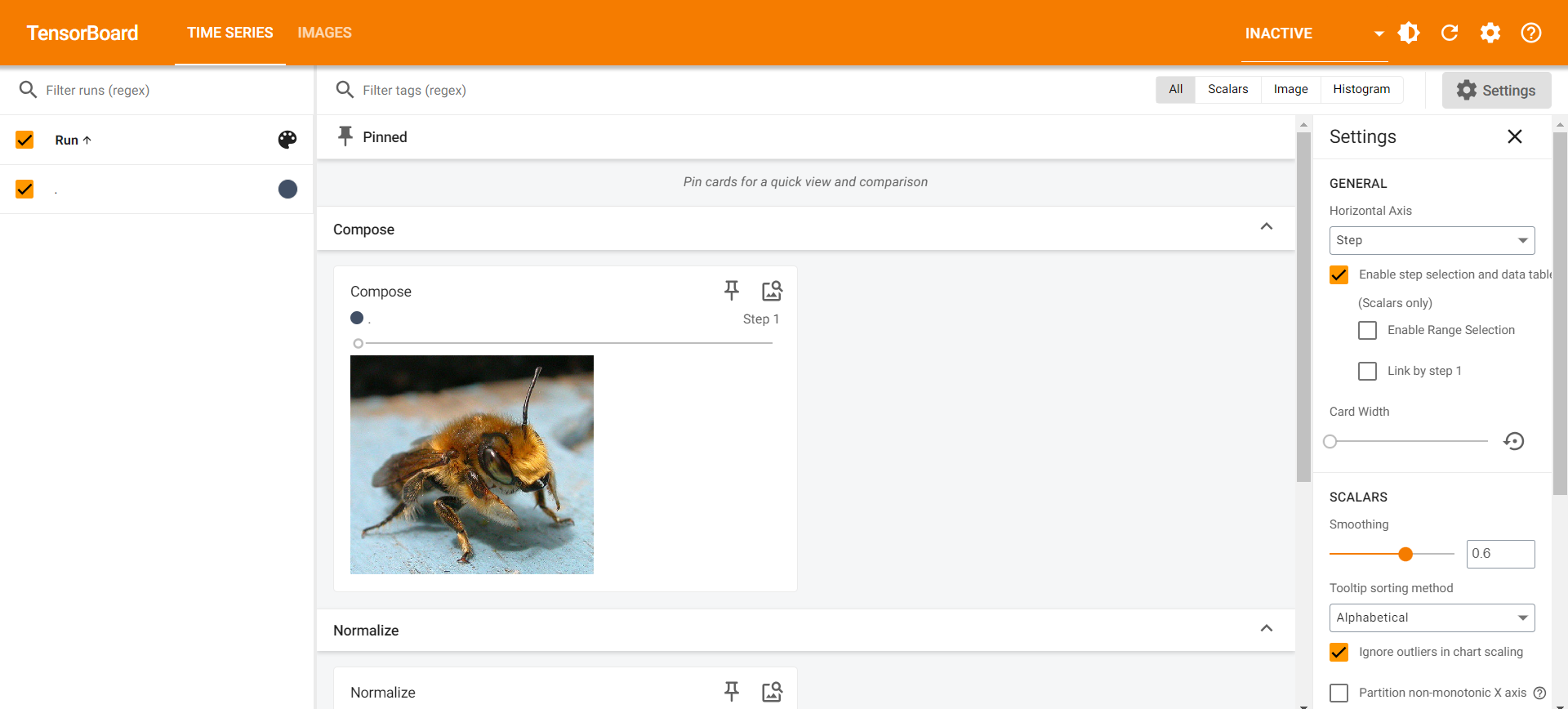
Compose()
- 会直接进行Resize然后进行ToTensor,一步到位
1 | from PIL import Image |
RandomCrop()
- 随机大小裁剪
1 | from PIL import Image |
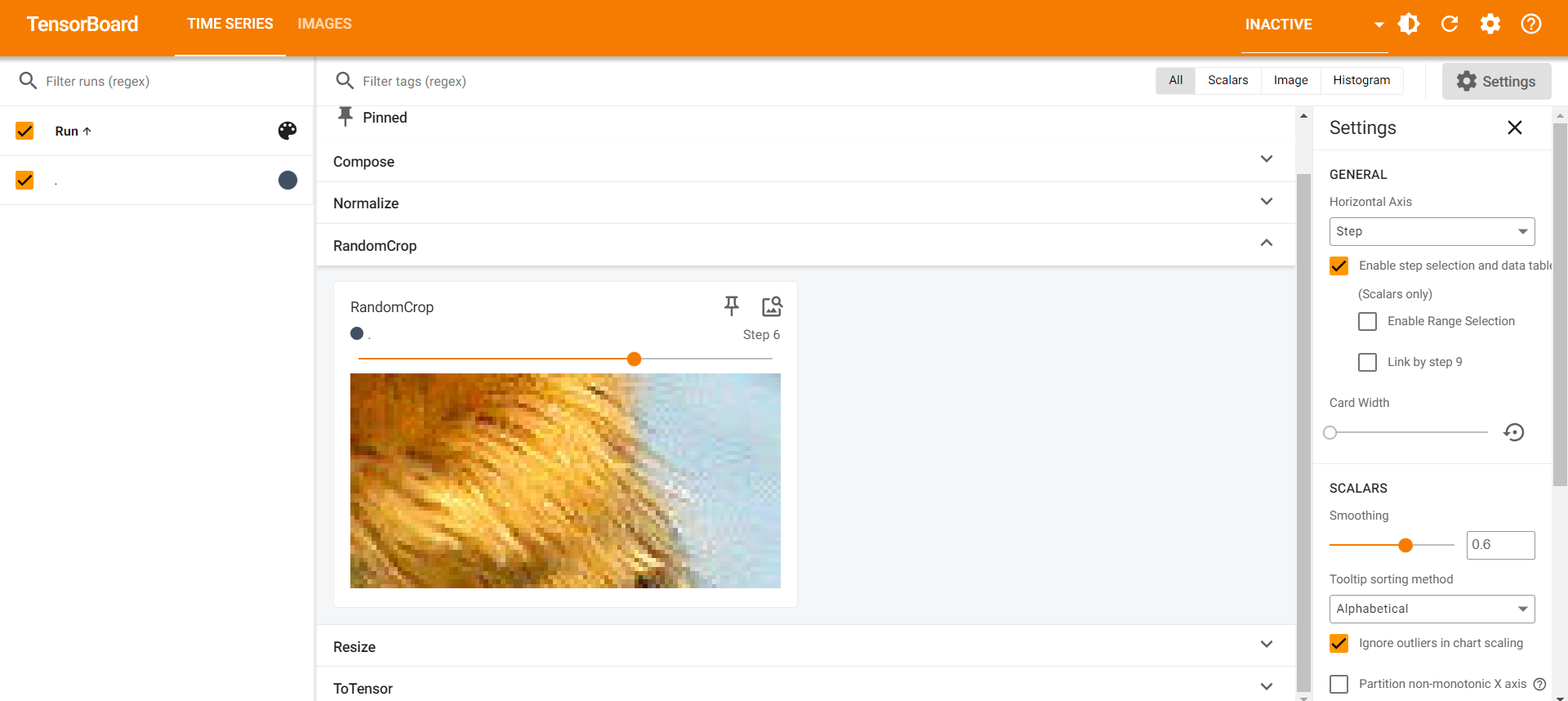
3.4 现有数据集 torchvision
以下,我们使用 CIFAR10 为例:
- 本数据集 详细官网
下载查看
1 | import torchvision |
1 | Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./dataset\cifar-10-python.tar.gz |
使用transform
1 | import torchvision |
1 | Files already downloaded and verified |
1 | tensorboard --logdir=logs5 |
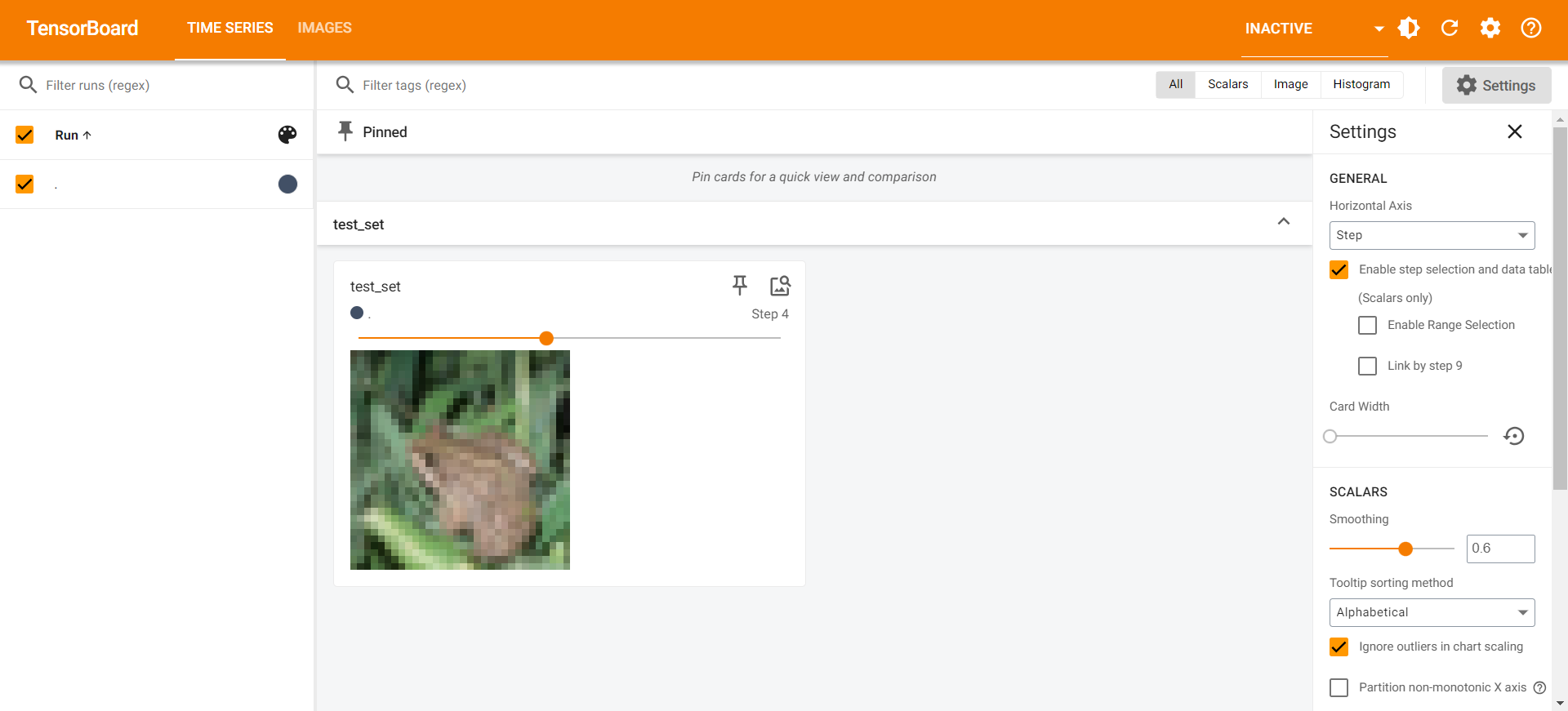
3.5 数据取用 DataLoader
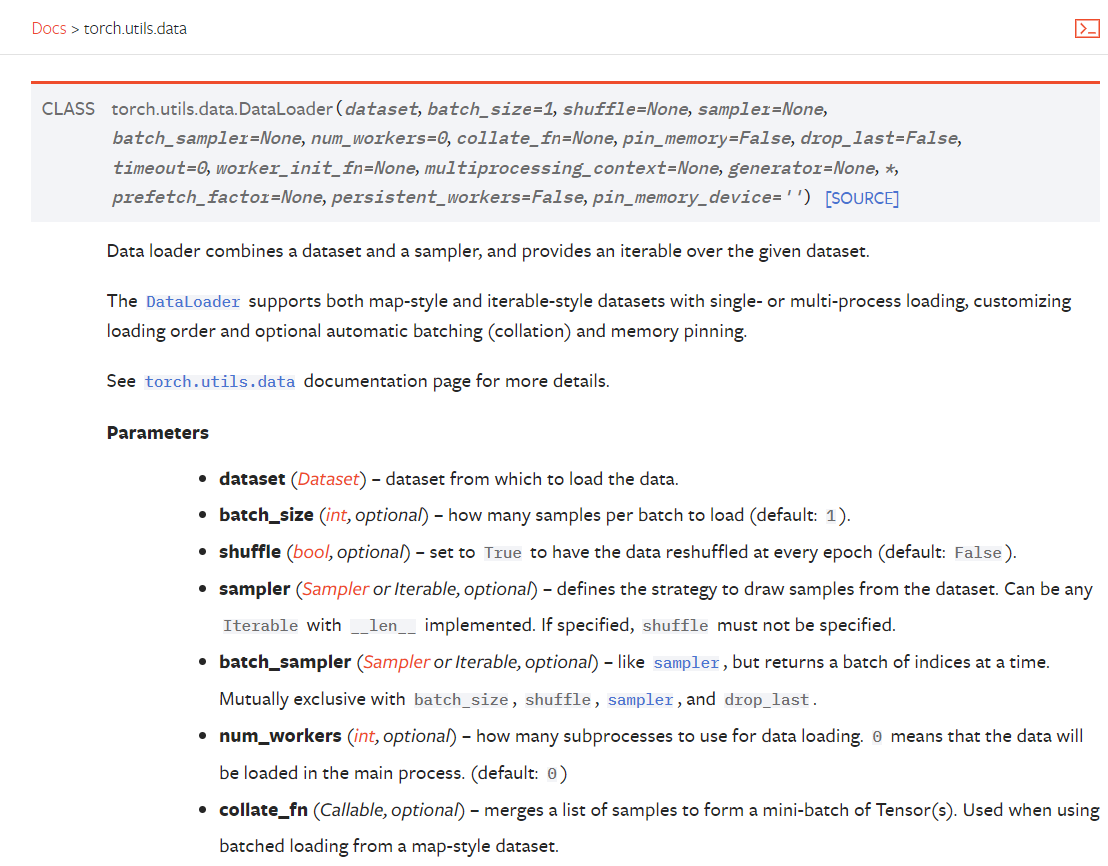

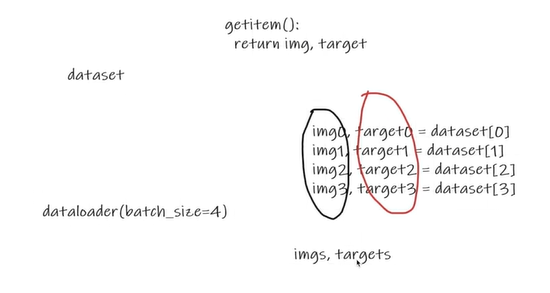
一次epoch更新
1 | import torchvision |
1 | torch.Size([3, 32, 32]) |
1 | tensorboard --logdir=logs6 |
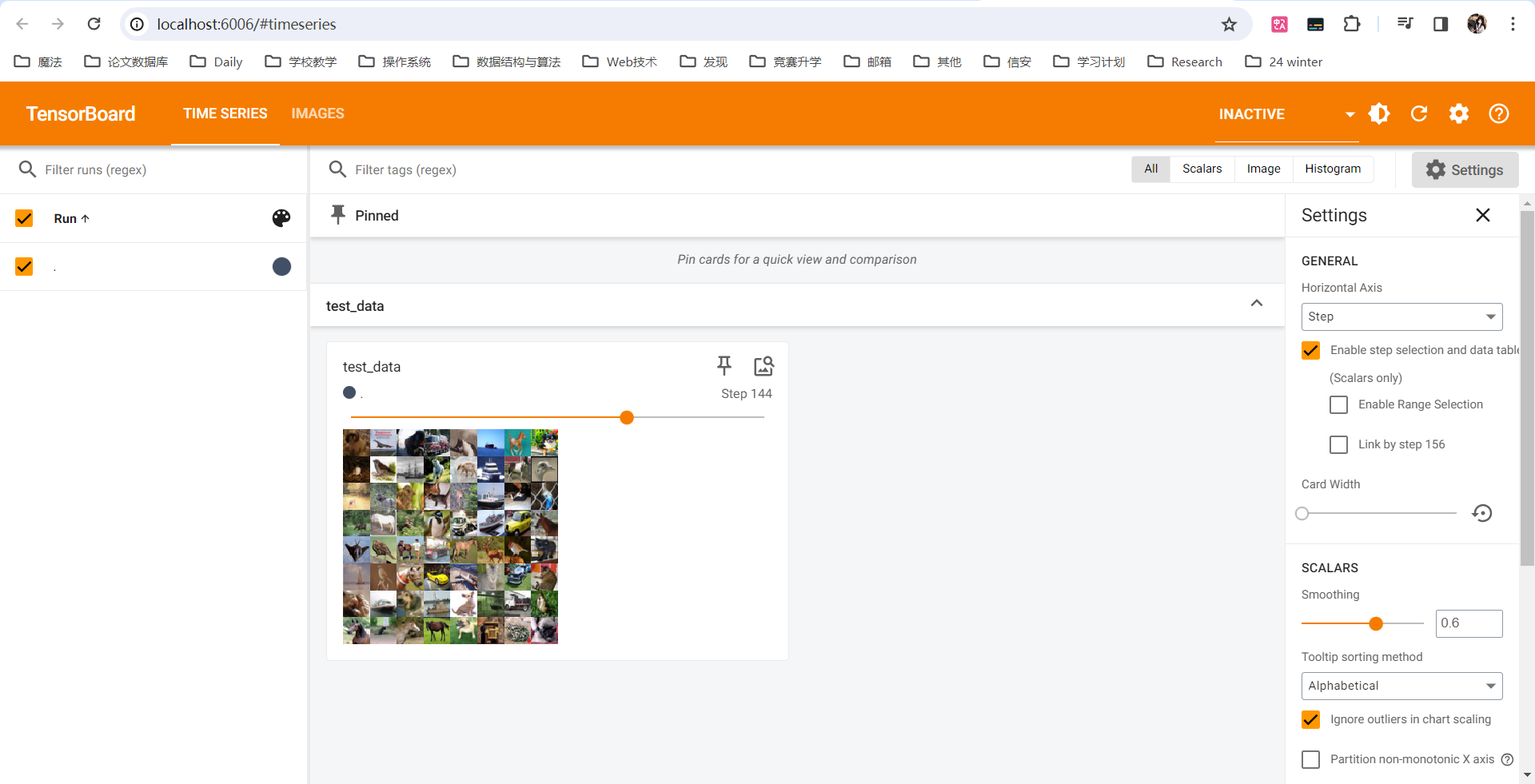
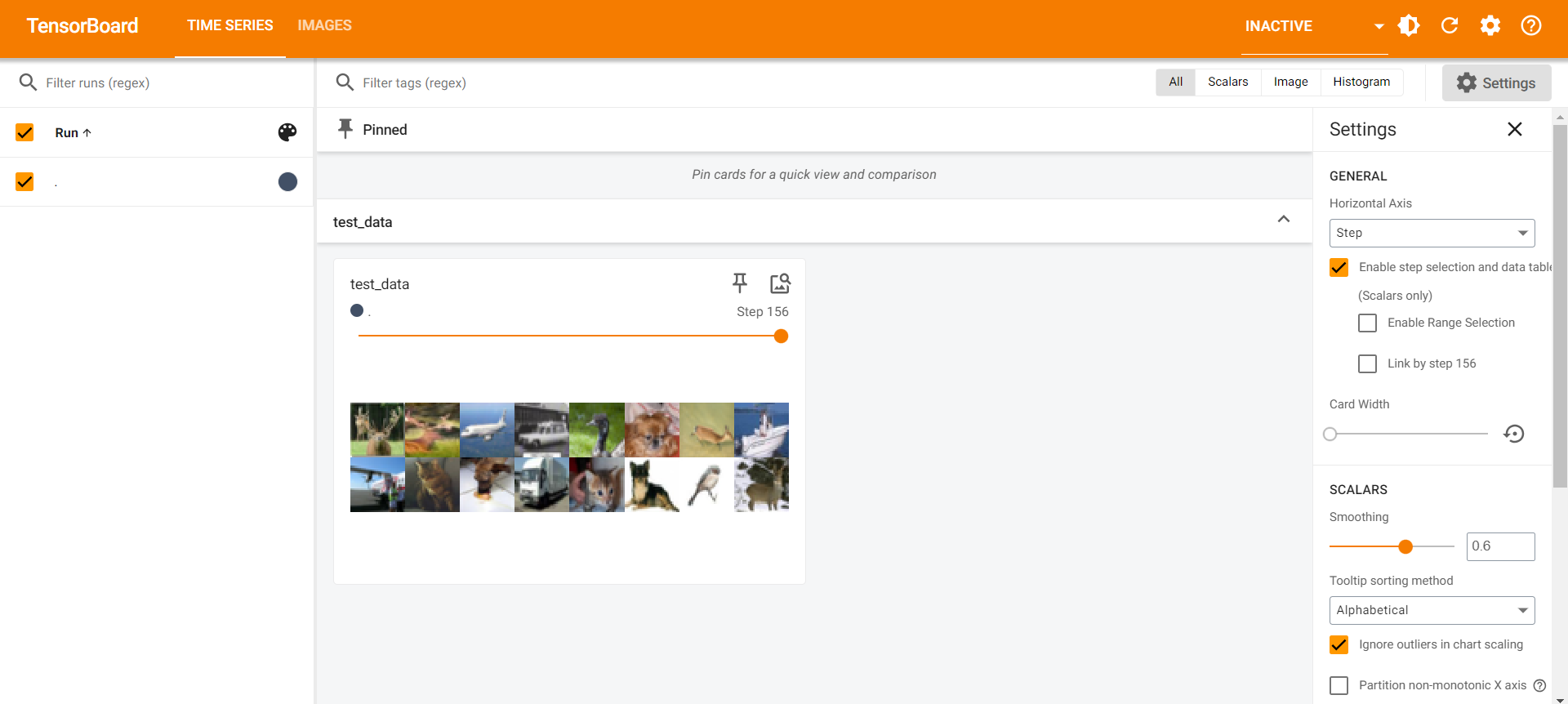
DataLoader 的 data 输出的大小类型是
2
print(targets)
2
3
4
tensor([1, 6, 3, 1, 3, 4, 0, 0, 6, 9, 4, 1, 1, 3, 8, 4, 9, 9, 0, 3, 6, 1, 1, 0,
8, 2, 4, 6, 0, 5, 2, 8, 7, 1, 8, 8, 7, 9, 7, 7, 9, 5, 4, 9, 9, 1, 0, 5,
5, 3, 0, 5, 9, 1, 2, 9, 9, 4, 2, 7, 3, 3, 3, 0])
多次epoch更新
1 | import torchvision |
1 | tensorboard --logdir=logs7 |
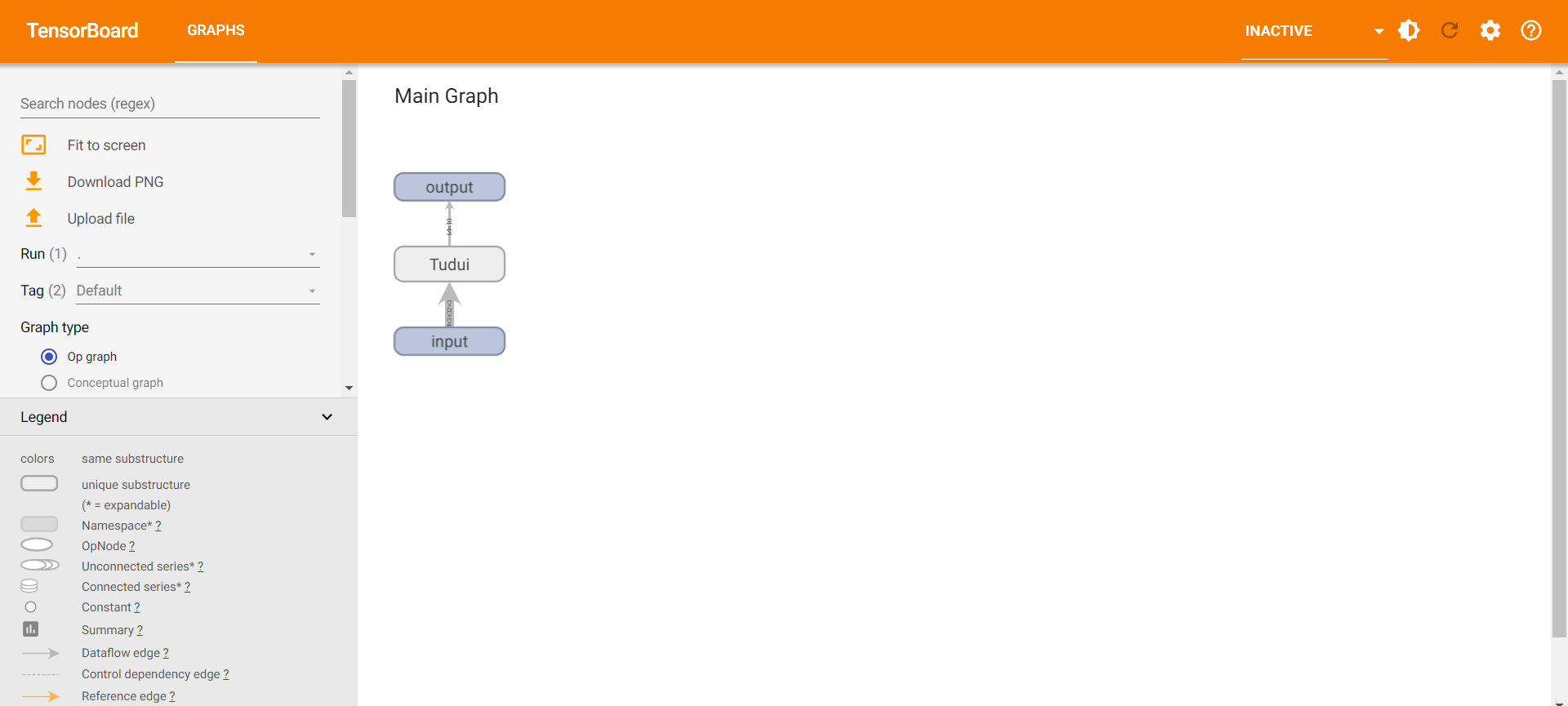
四、神经网络
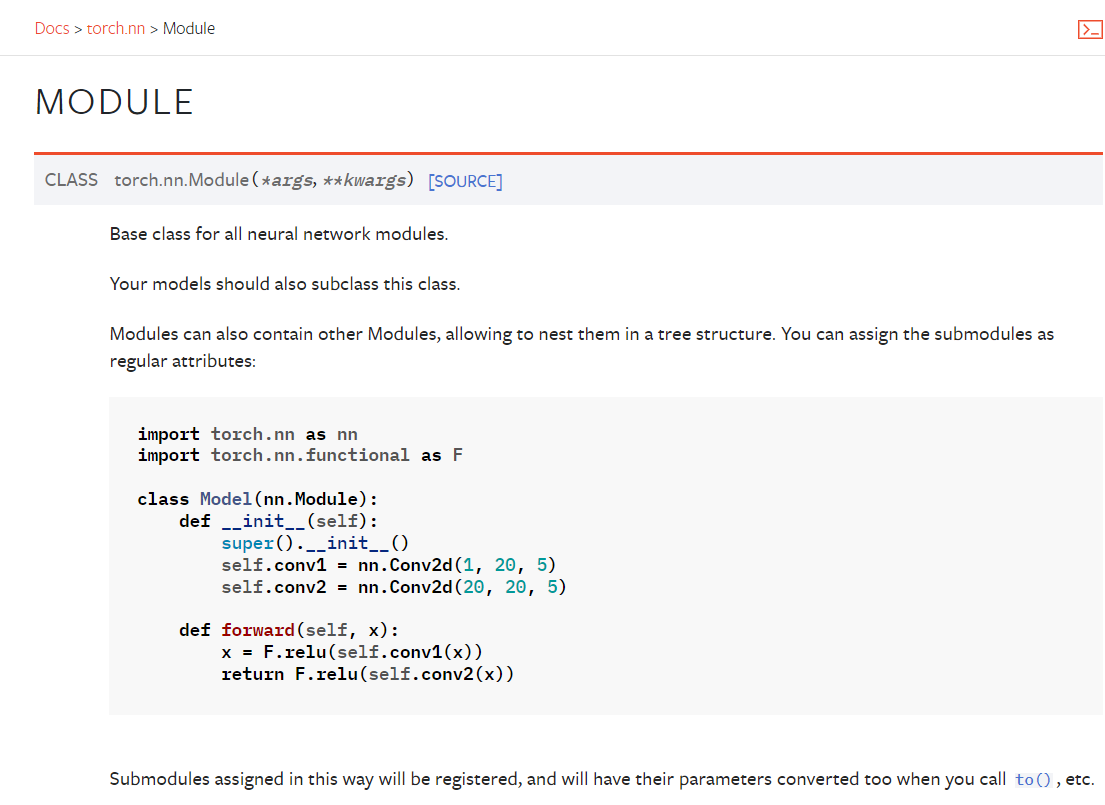
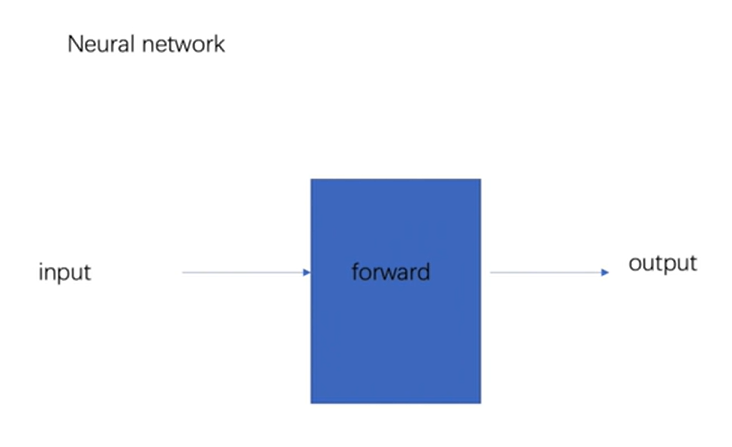
4.1 基本骨架 nn.Module
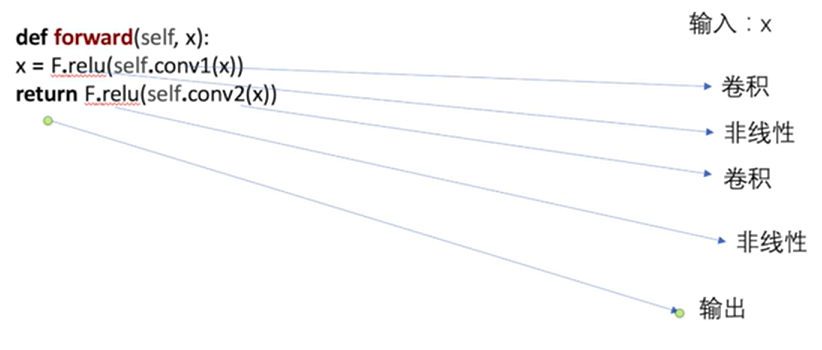
1 | import torch |
1 | tensor(1.) |
4.2 卷积层
卷积操作动画说明
参考:
Convolution animations
N.B.: Blue maps are inputs, and cyan maps are outputs.
No padding, no strides Arbitrary padding, no strides Half padding, no strides Full padding, no strides No padding, strides Padding, strides Padding, strides (odd) Transposed convolution animations
N.B.: Blue maps are inputs, and cyan maps are outputs.
No padding, no strides, transposed Arbitrary padding, no strides, transposed Half padding, no strides, transposed Full padding, no strides, transposed No padding, strides, transposed Padding, strides, transposed Padding, strides, transposed (odd) Dilated convolution animations
N.B.: Blue maps are inputs, and cyan maps are outputs.
No padding, no stride, dilation








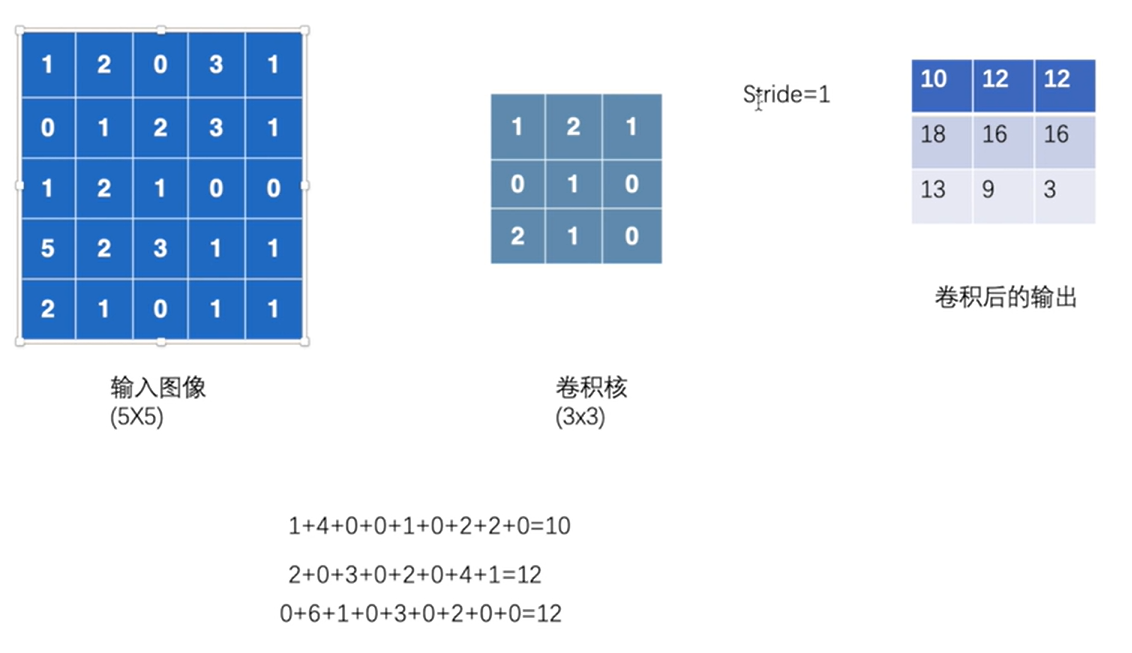
1 | import torch |
1 | torch.Size([5, 5]) |
卷积 Conv2d()

- 二维卷积操作

1 | import torch |
1 | Files already downloaded and verified |
1 | tensorboard --logdir=logs8 |
4.3 最大池化 MaxPool2d()
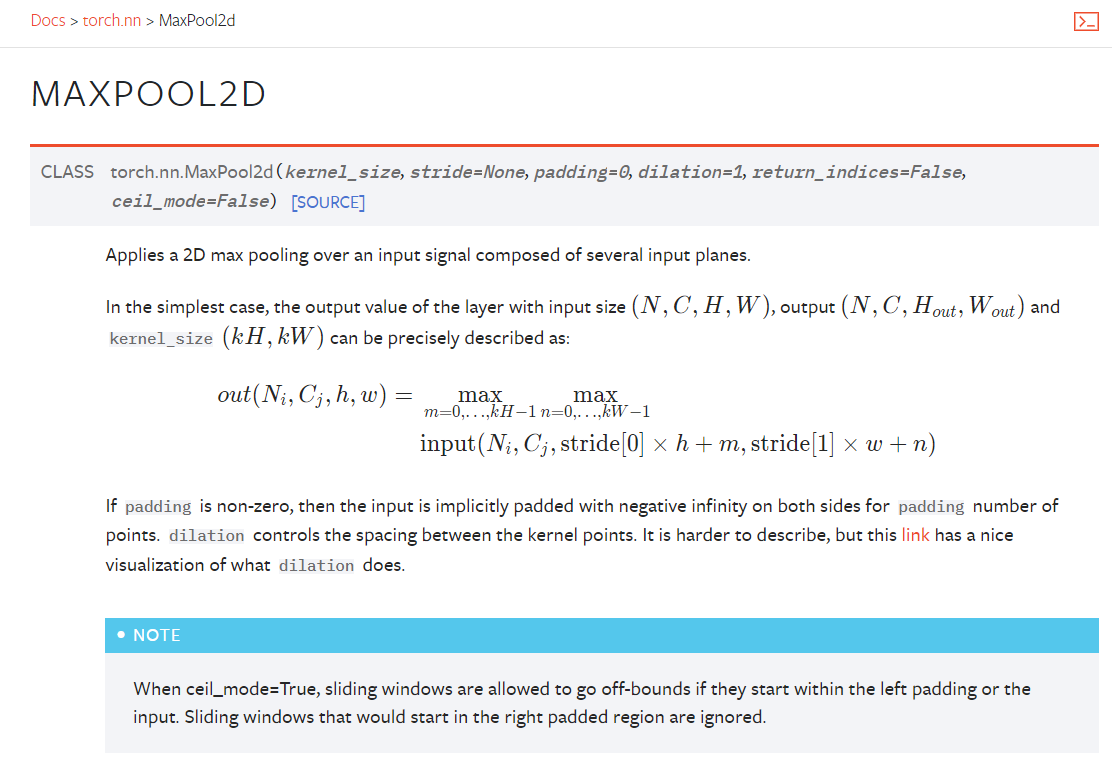
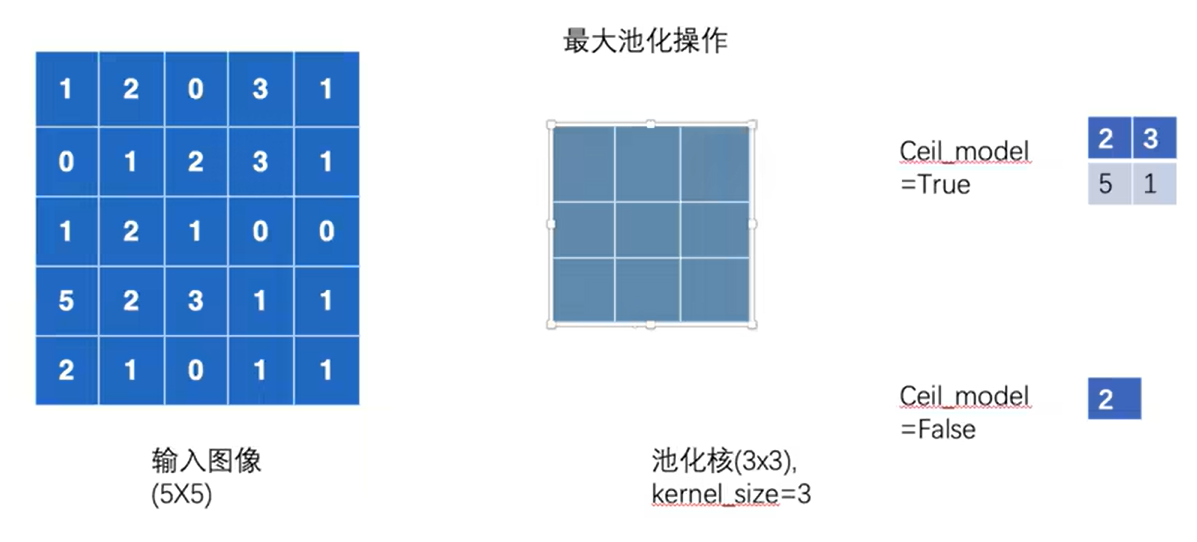
1 | import torch |
1 | tensor([[[[2., 3.], |
- 若改为
- 则会输出
- 下面使用一下,效果是模糊
1 | import torchvision |
1 | tensorboard --logdir=logs9 |
4.4 非线性激活 ReLU()、Sigmoid()
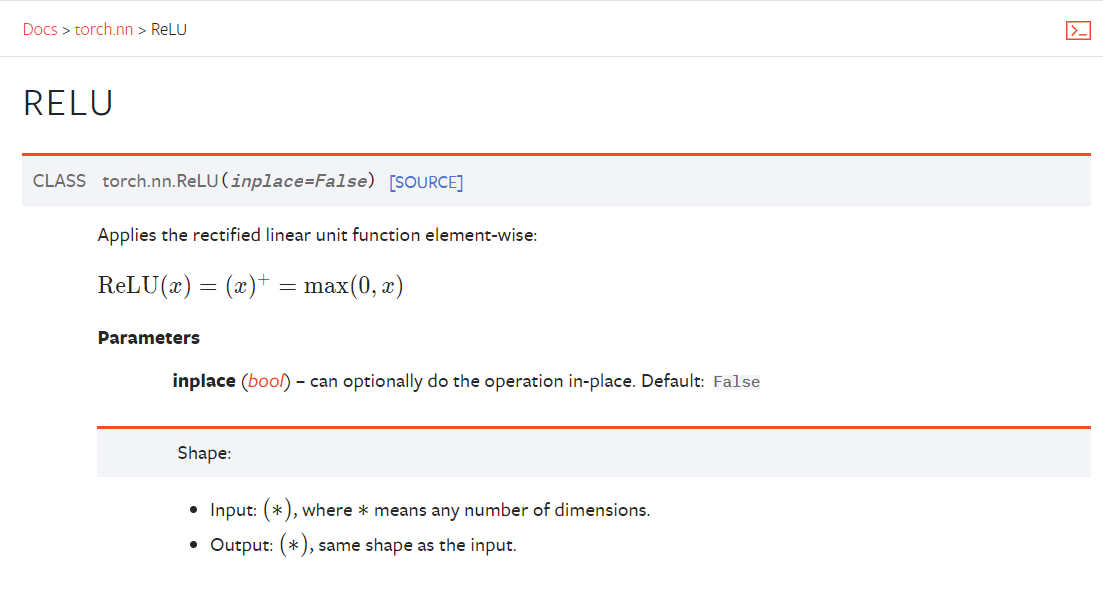
.png)
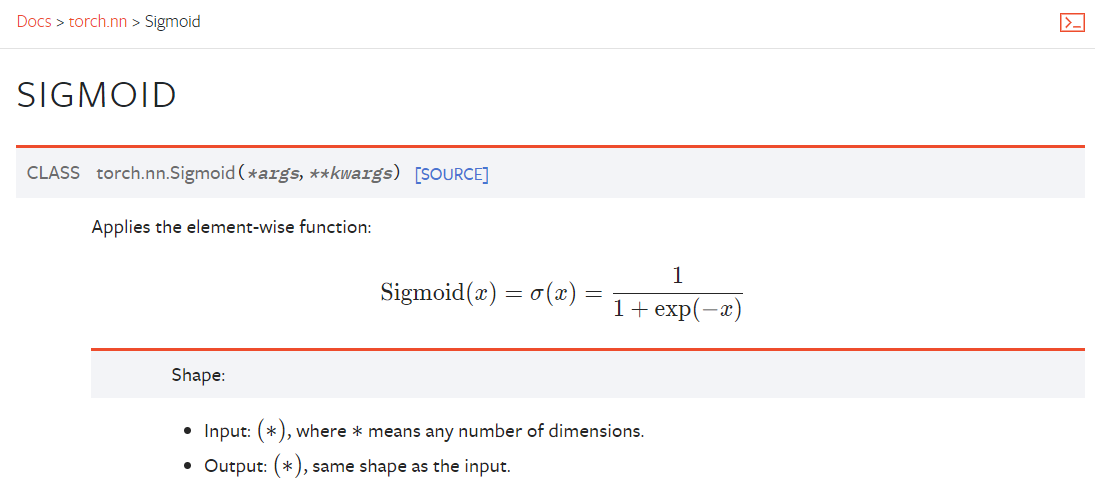
.png)

- 下例实际上只用了Sigmoid:
1 | import torchvision |
1 | tensorboard --logdir=logs10 |
%E4%BD%BF%E7%94%A8.png)
4.5 线性层 Linear()
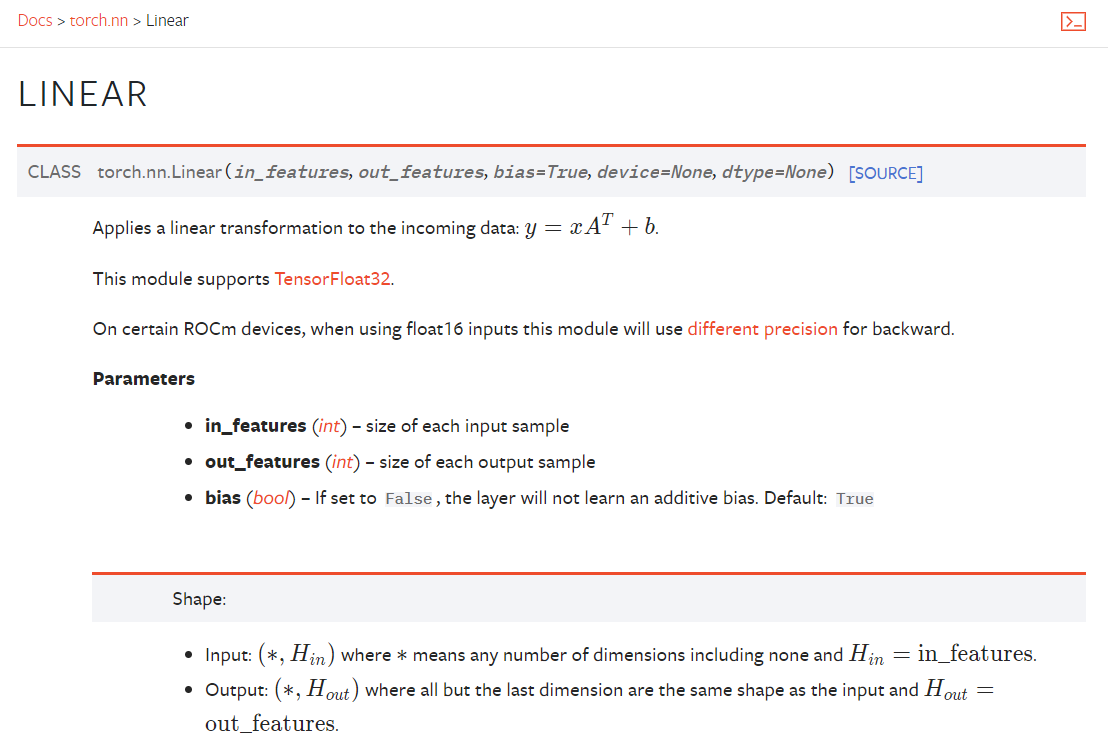
1 | import torch |
1 | Files already downloaded and verified |
4.6 其他层
- 一般是用于特定处理的层
- 如语音处理、图像处理、文字处理等
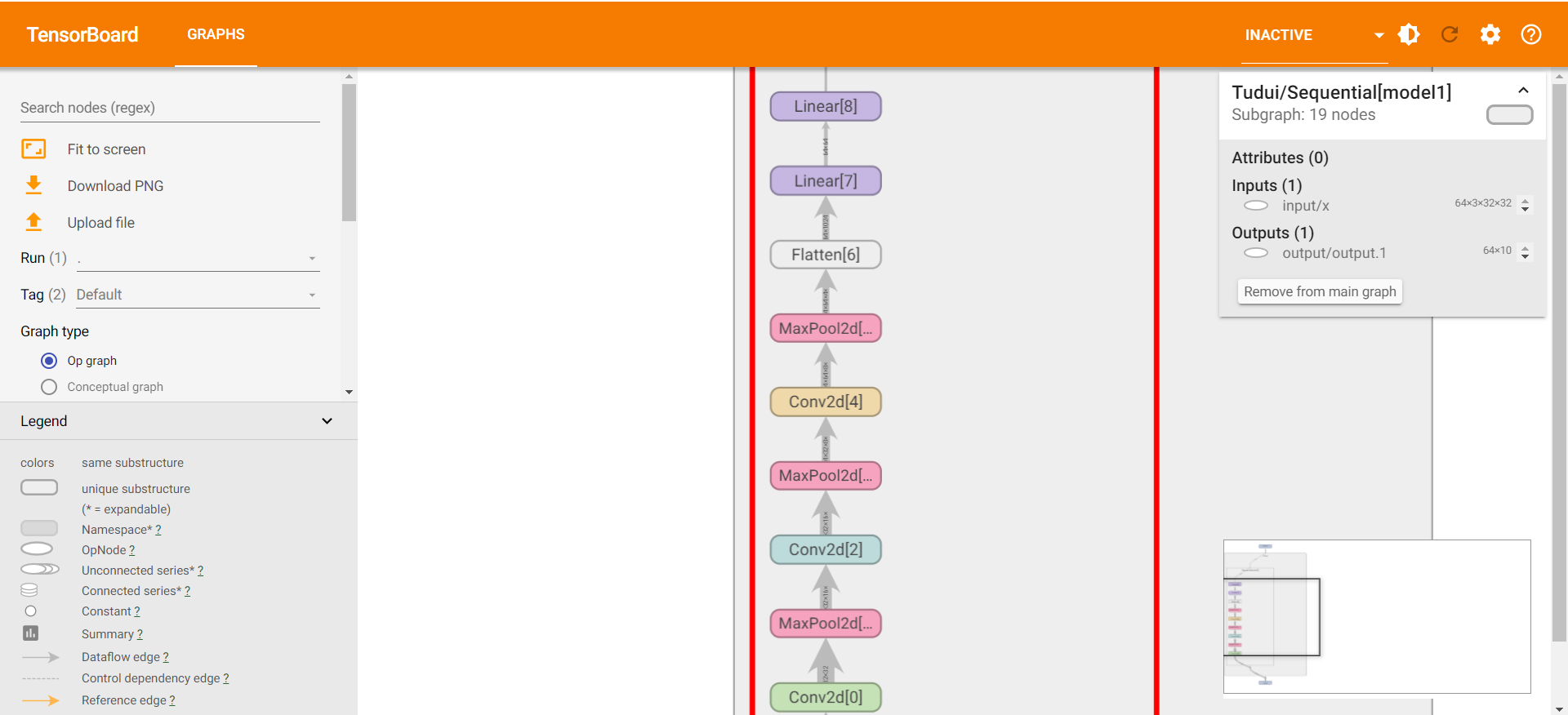
4.7 层序列 Sequential()
- 下面用 CIFAR10 示例:
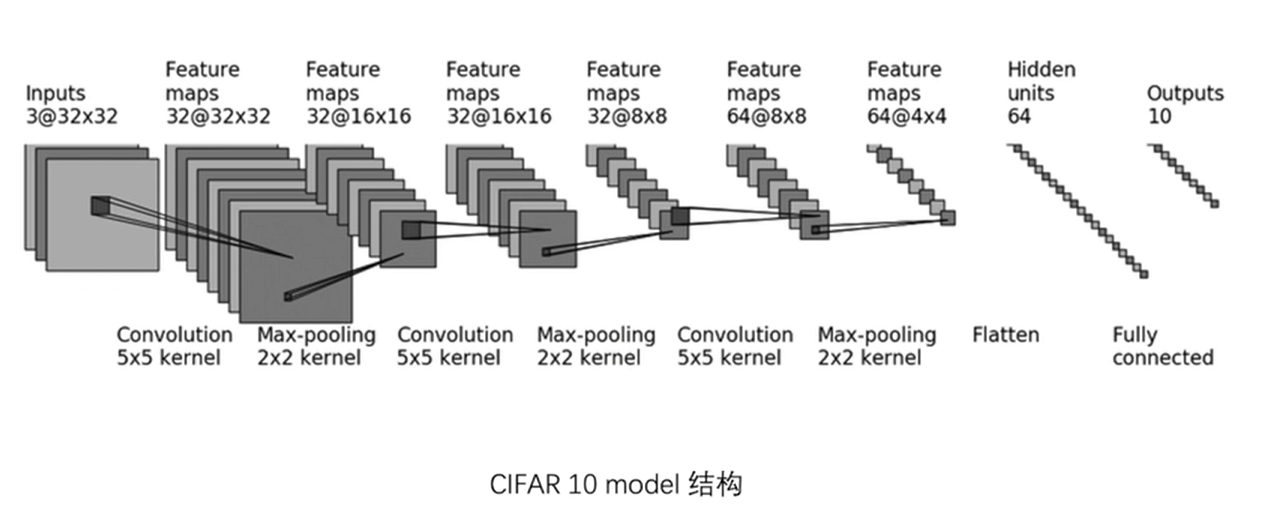
- Conv2d 参数计算示例:

不使用
1 | from torch import nn |
1 | Tudui( |
使用序列
1 | from torch import nn |
1 | Tudui( |
tensorboard展示
1 | import torch |
1 | torch.Size([64, 10]) |
1 | tensorboard --logdir=logs12 |
4.8 损失函数与方向传播
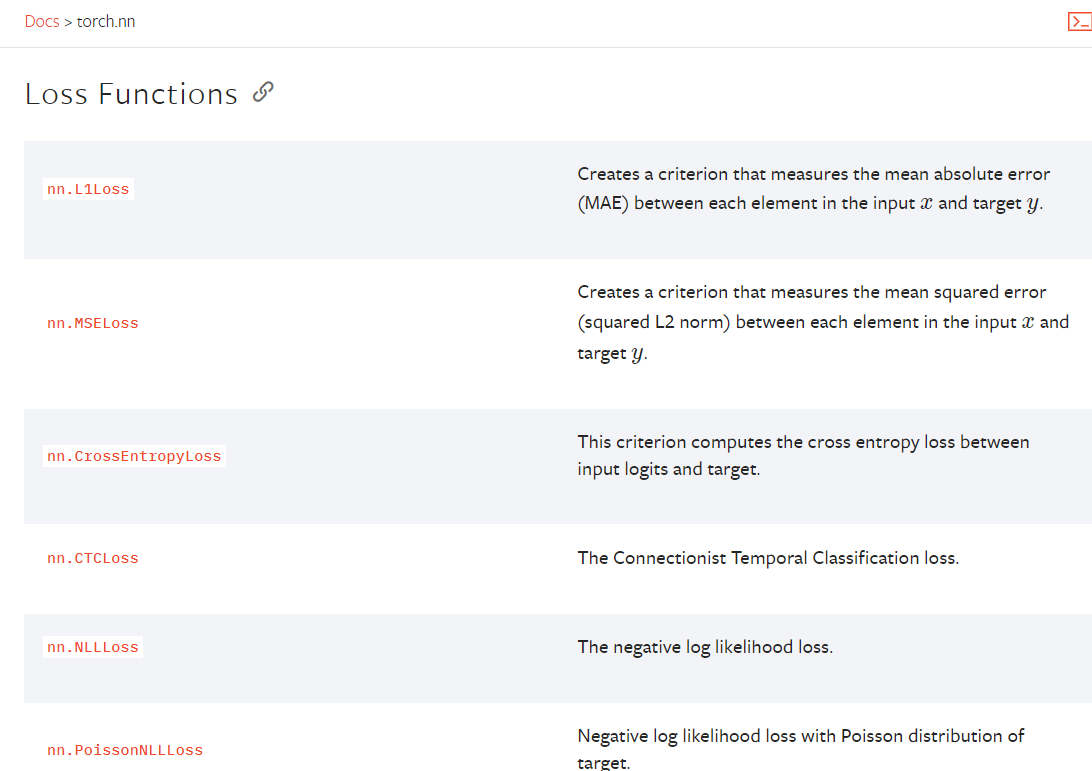

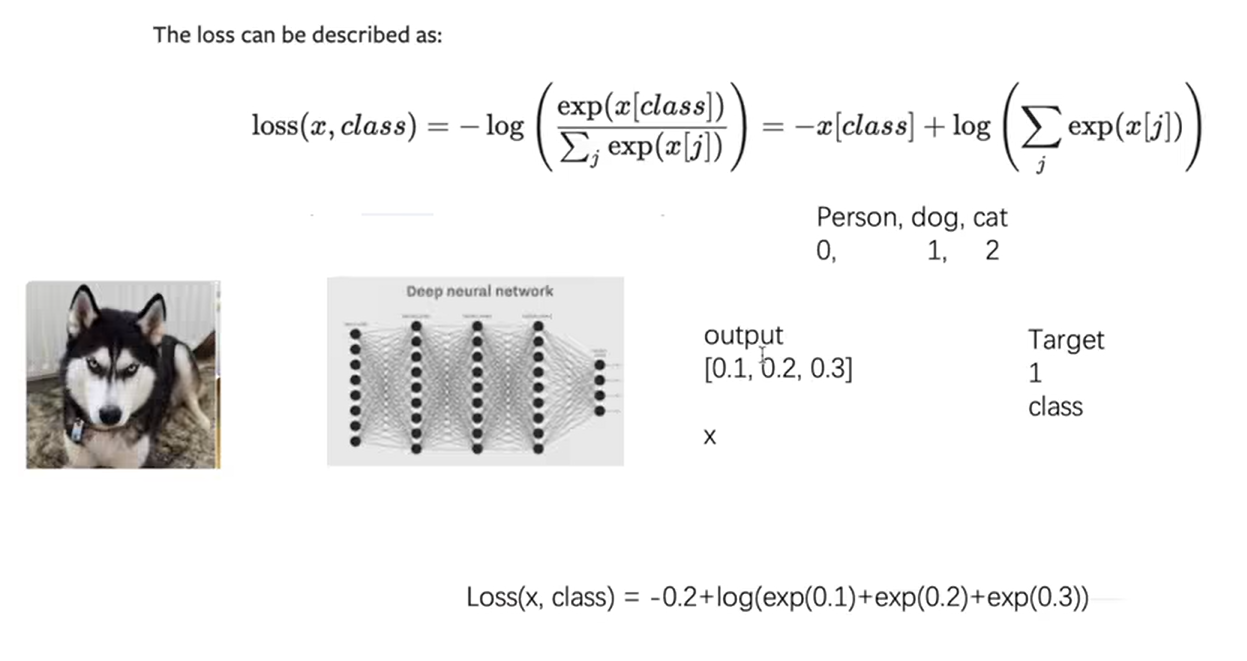
L1Loss()
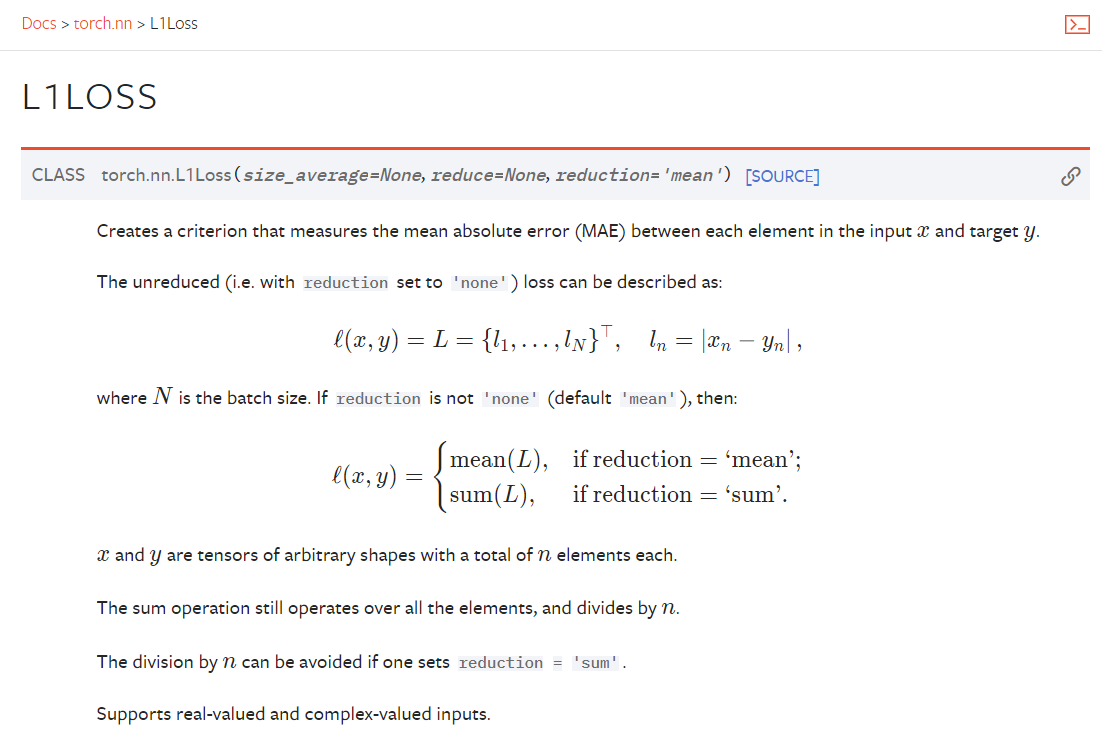
MSELoss()
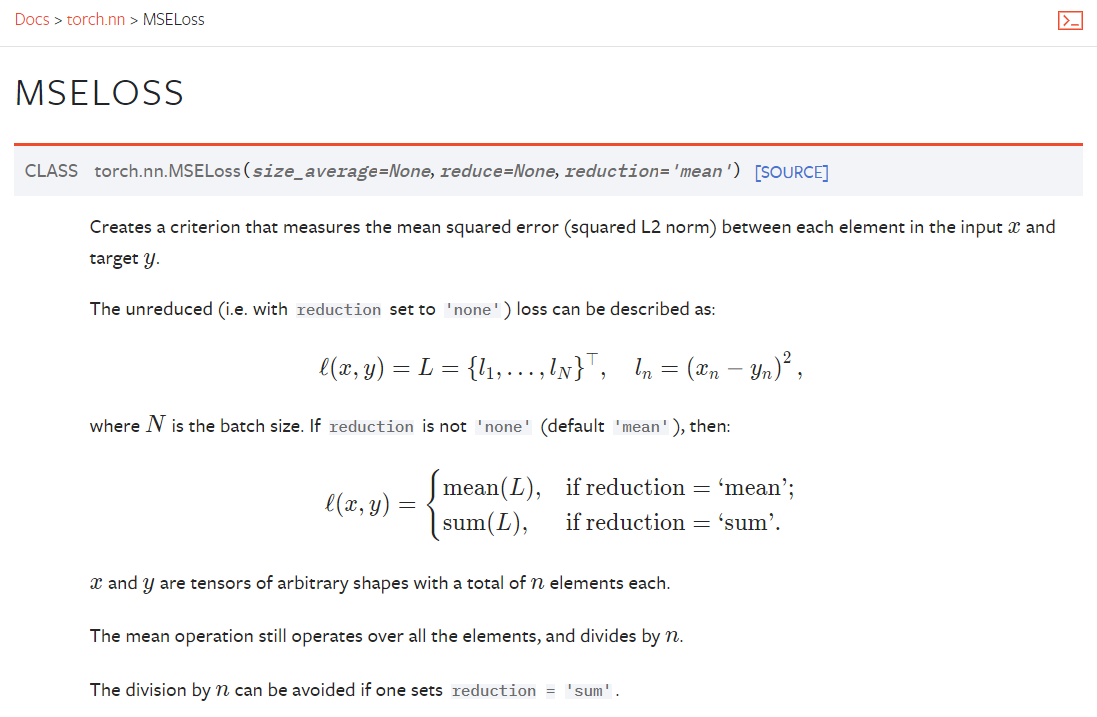
CrossEntropyLoss()
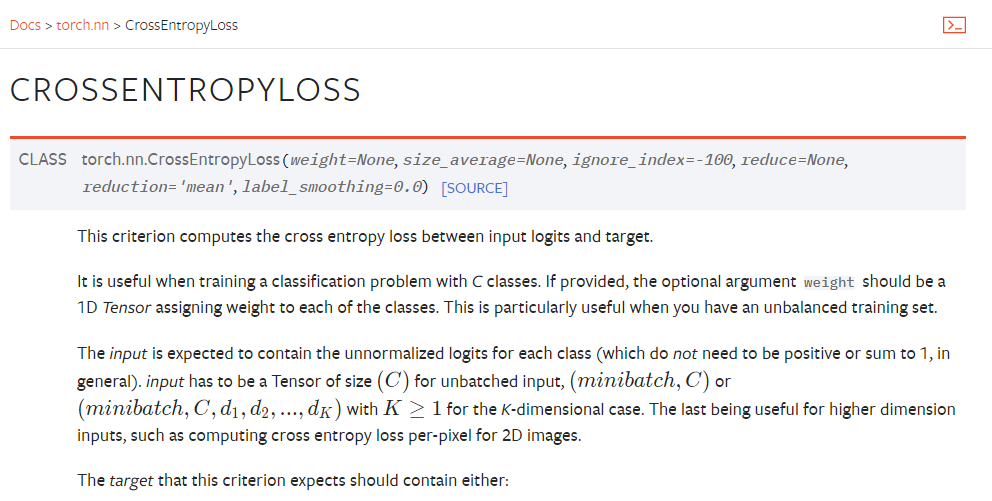


操作示例
1 | import torch |
1 | tensor(0.6667) |
模型示例
1 | import torch |
1 | Files already downloaded and verified |
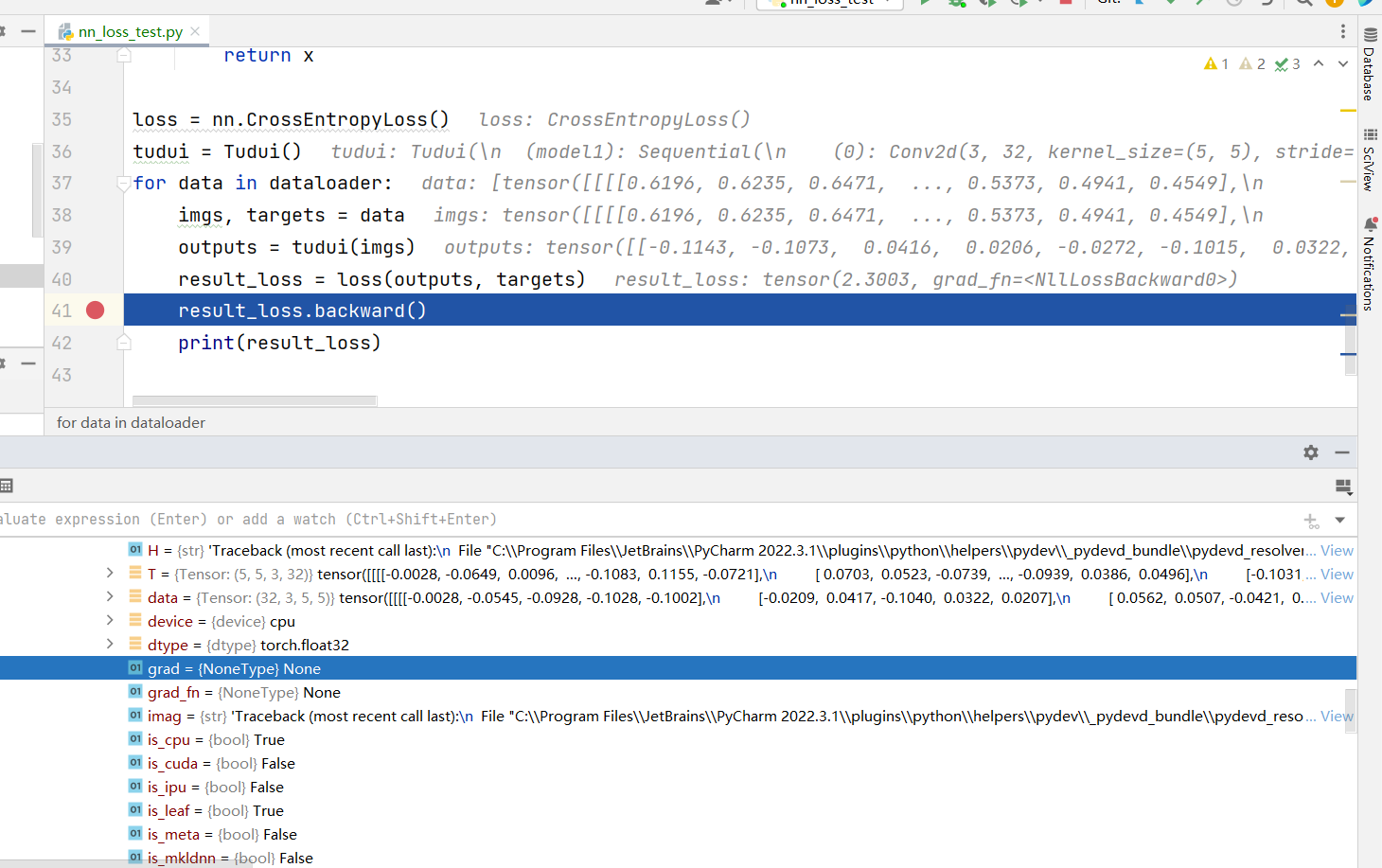
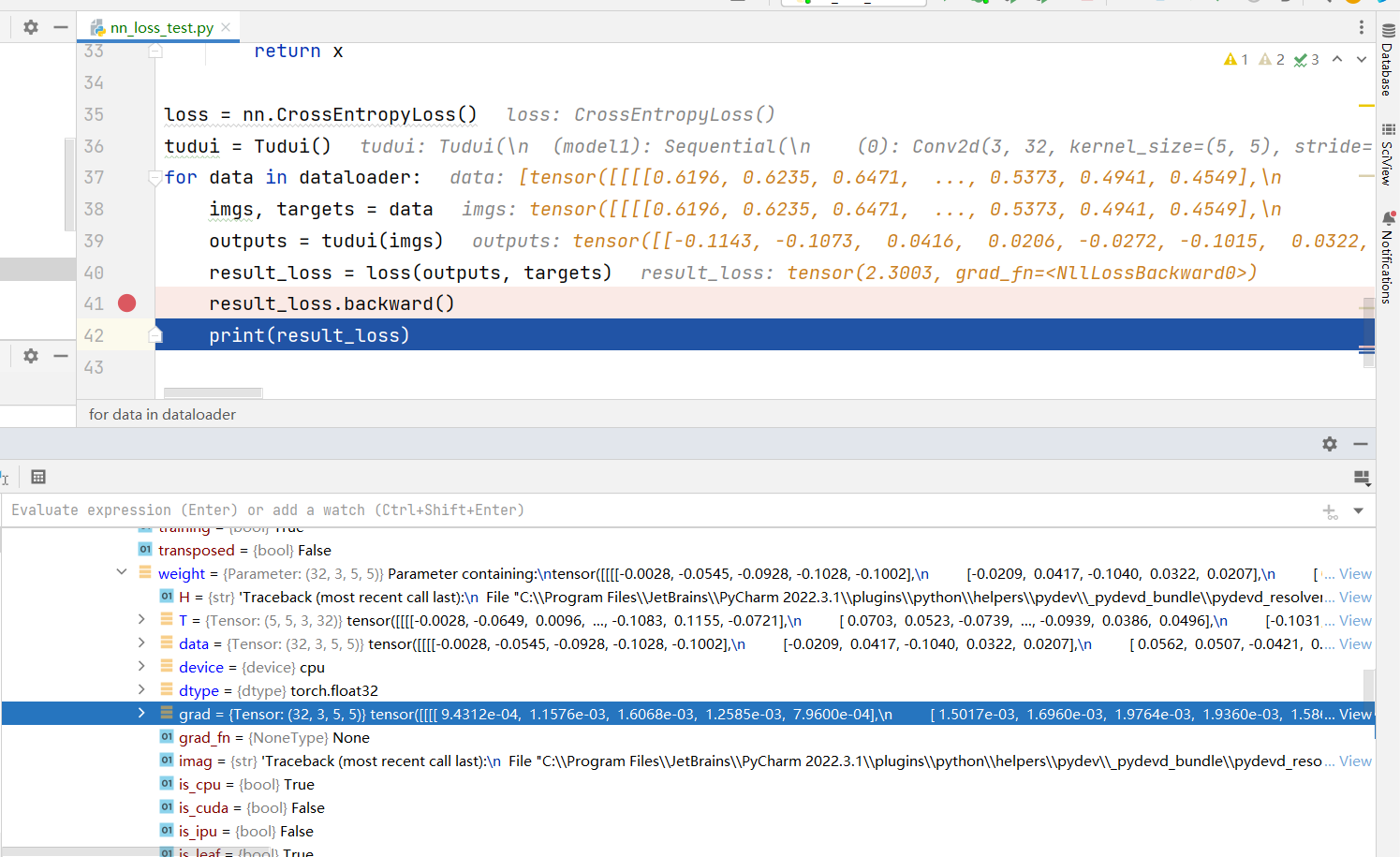
查看 grad
- 添加一个
1 | result_loss.backward() |
-
打下断点,进行DEBUG
在打开查看grad参数的变化
grad在
- tudui
- model1
- Protected Attributes
- _modules
- ‘0’
- weight
- grad
- weight
- ‘0’
- _modules
- Protected Attributes
- model1
- tudui
4.9 优化器
查看 data
- 添加下面的
optimizer内容
1 | loss = nn.CrossEntropyLoss() |
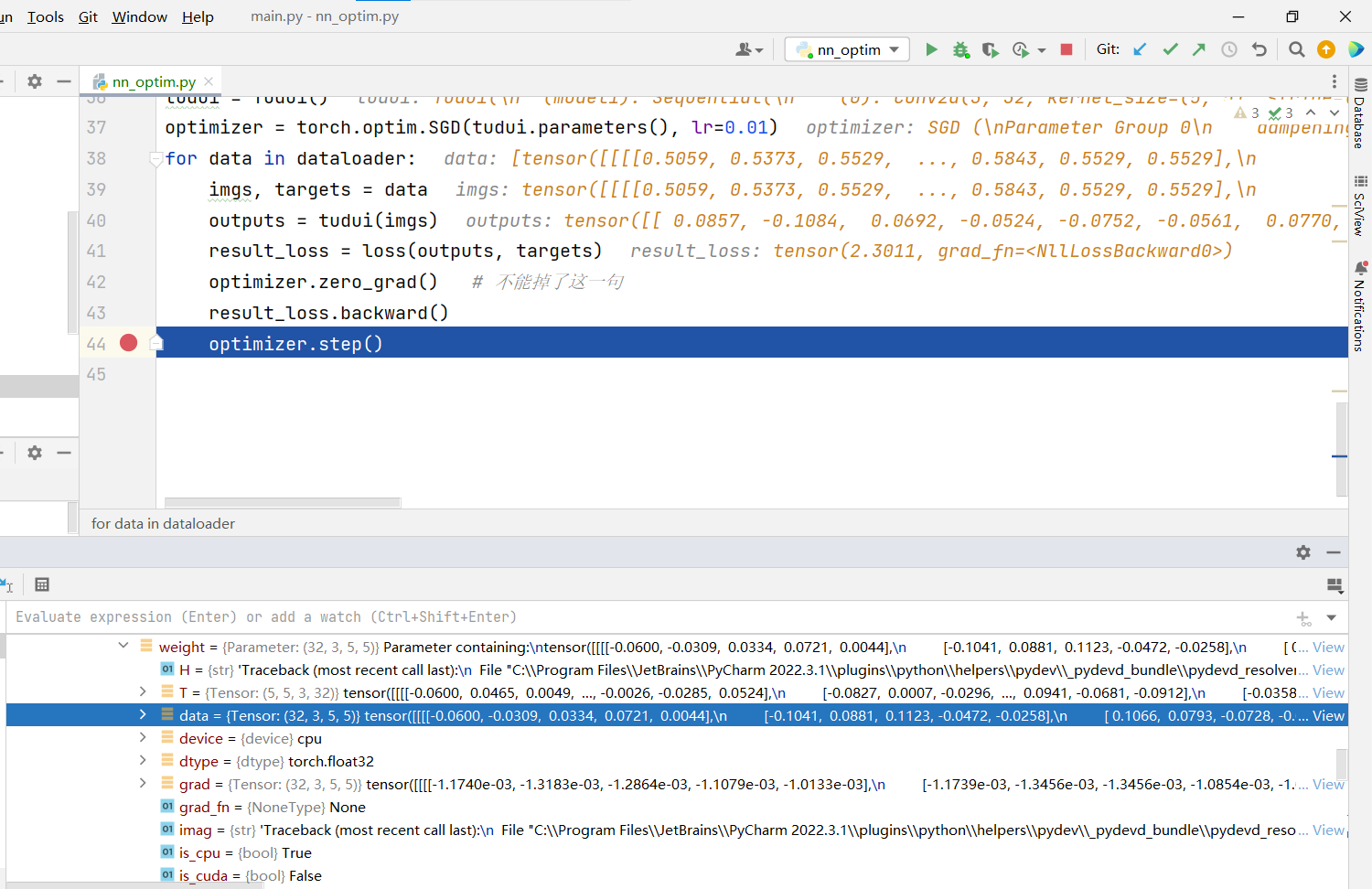
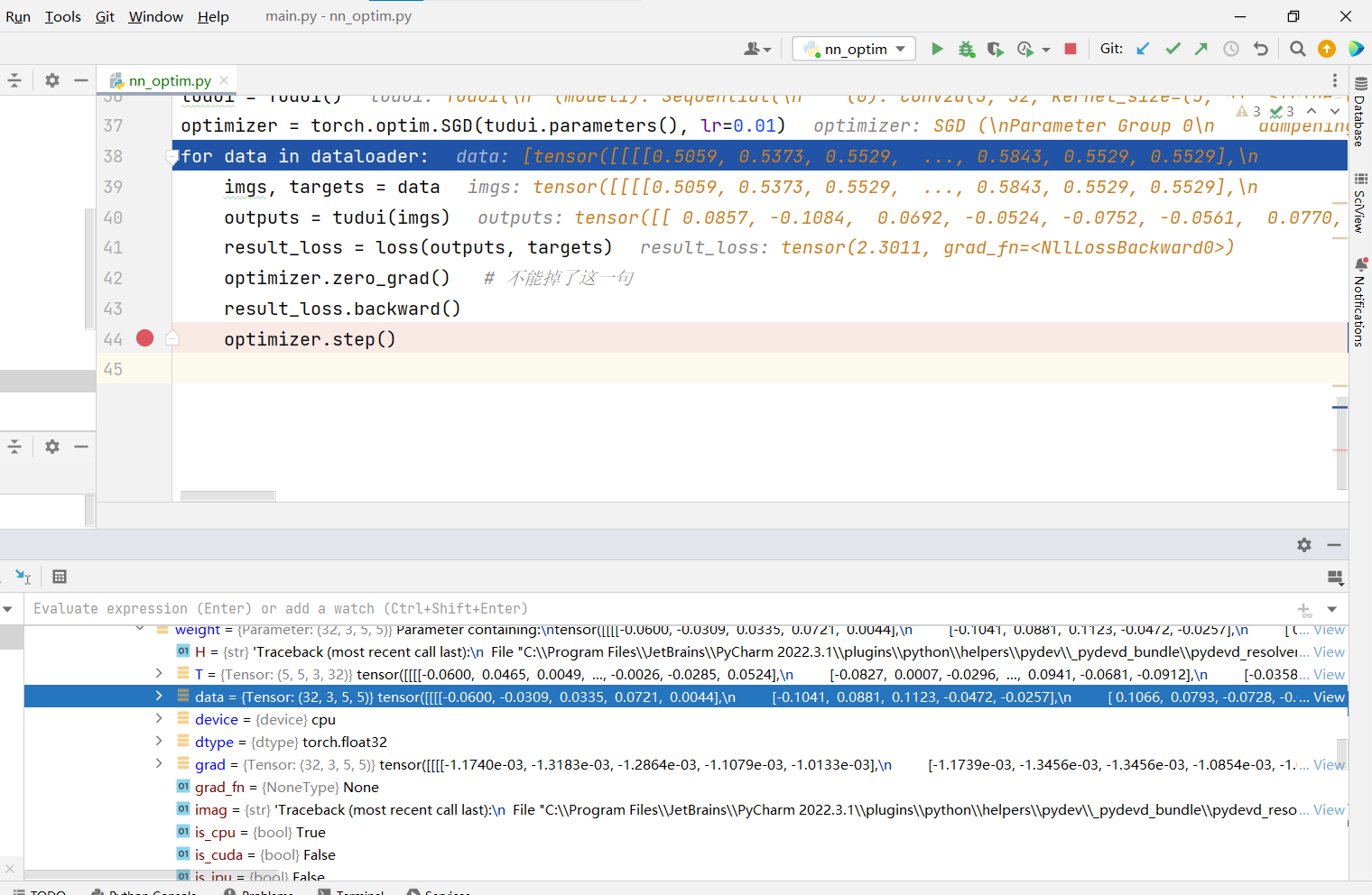
仔细看data,实际上更新了数字
是会根据grad梯度进行data参数的更新,从而更新了模型
完整示例
- 我们添加epoch多轮,每轮输出对应的 loss 和
1 | import torch |
1 | Files already downloaded and verified |
可以看到,损失越来越小了。
五、现有网络模型
5.1 网络模型的保存与读取
保存
1 | import torch |
读取
1 | import torch |
1 | VGG( |
注意:
保存自己的已训练模型后,再读取模型时,
需要自己把这个模型类先引入,才能正常读入。
前面的
torch.load("vgg16_method2.pth")的内容是
2
3
4
5
6
7
8
9
10
11
12
[ 0.0986, 0.0091, 0.0706],
[-0.1599, 0.0261, 0.1146]],
[[-0.0203, -0.0541, 0.1053],
[ 0.0094, -0.0109, 0.0597],
[ 0.0154, -0.1059, 0.0040]],
[[ 0.0358, -0.0205, 0.0215],
[-0.0723, 0.0951, 0.1017],
[ 0.0250, -0.0216, -0.1106]]],
......
5.2 使用现有网络模型
使用
1 | import torchvision |
1 | Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to C:\Users\86182/.cache\torch\hub\checkpoints\vgg16-397923af.pth |
修改
1 | import torchvision |
1 | Files already downloaded and verified |
可以看到最后一行有一个
add_linear是我们添加到层名
六、完整套路
6.1 模型训练
结构图
mymodel.py
1 | import torch |
train.py
1 | # -*- coding = utf-8 -*- |
CPU跑
1 | # 使用CPU |
1 | 训练数据集的长度为50000 |
GPU跑
1 | # 使用GPU |
1 | Files already downloaded and verified |
tensorboard显示
1 | tensorboard --logdir=logs13 |
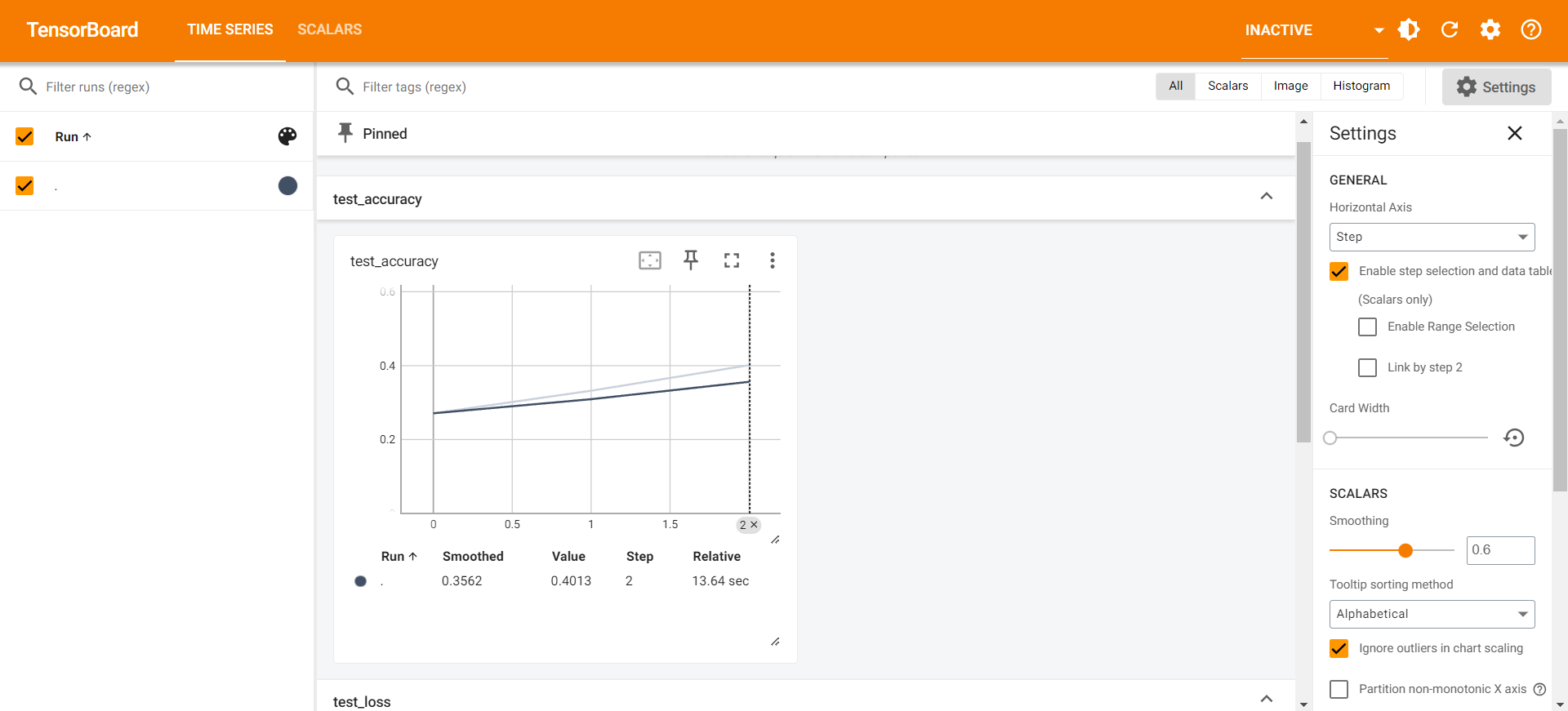
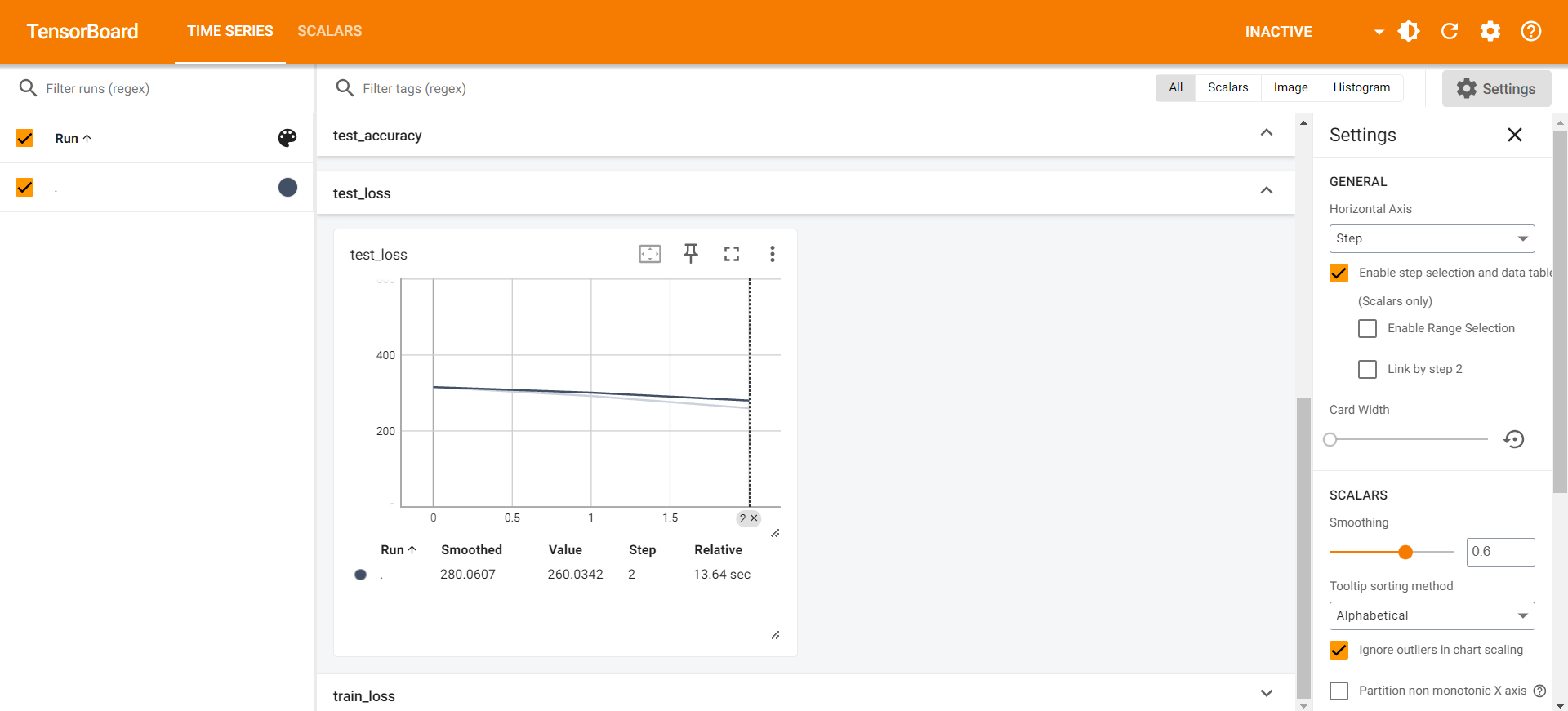
其中
使用GPU:
也可以单个询问,但是上面示例方法更好
2
3
4
5
6
7
8
9
10
11
# 一共是三个地方需要:1.网络模型 2.损失函数 3.数据(必须是data拆分后的)
if torch.cuda.is_available():
tudui = tudui.cuda()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
- 说明

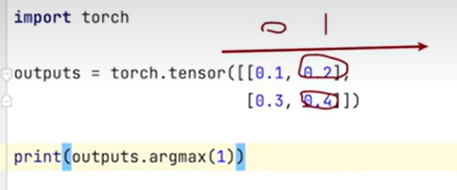
- argmax函数

2
3
4
5
tensor([0, 1])
# 第二个得到
tensor([1, 1])
6.2 模型验证

获取一张图片
- 在网络上截图了一张图片

写入测试
1 | import torch |
1 | <PIL.Image.Image image mode=RGB size=213x230 at 0x17E8A0F2C90> |
4对应是deer
说明错了。
但是可以看到是5-dog的概率也有2.51,至少不会太离谱。
只不过,训练不够,还需要继续训练,提高正确率。
我们改用下面这个图片试一下

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
torch.Size([3, 32, 32])
Tudui(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
tensor([[-2.6350, -2.5190, -1.2866, 2.8444, 0.6324, 3.7176, 2.9099, 1.6787,
-3.9632, -1.8650]])
tensor([5])这次是正确的!
6.3* 使用 colab 跑GPU
-
需要使用谷歌账号登录才能使用GPU
-
新建笔记本
-
修改
-
笔记本设置
-
硬件加速器
选择GPU,保存
-
-
-
-
编写格式类似 Jupyter Notebook
1 | # 编写代码 |
 微信支付
微信支付 支付宝
支付宝
