
CVDL - 视觉识别
七、视觉识别

7.1 分类
- 前面讲的都是
- 从
- 线性分类器
- 全连接神经网络
- 卷积神经网络
7.2 语义分割
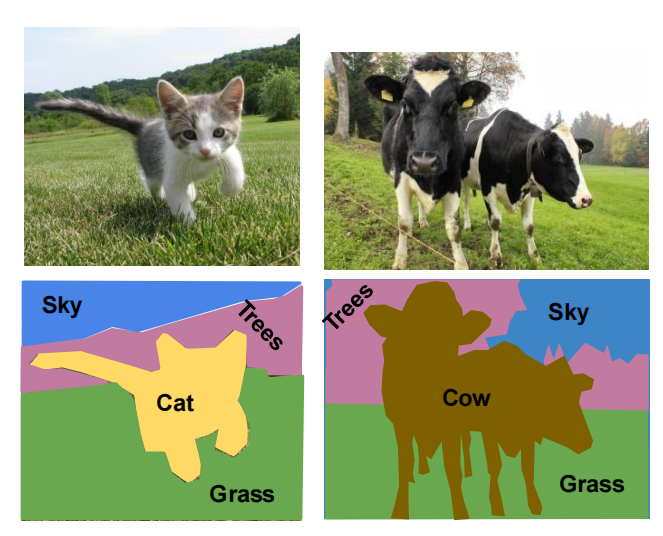
- 给每个像素分配类别标签不区分实例,只考虑像素类别
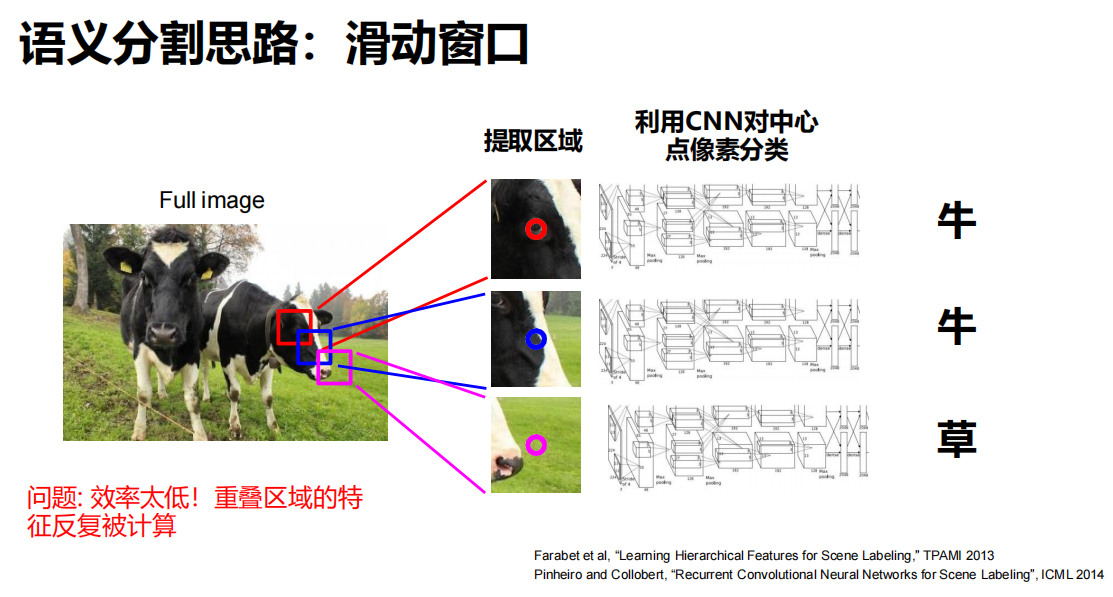
滑动窗口
-
问题
效率太低!重叠区域的特征反复被计算。
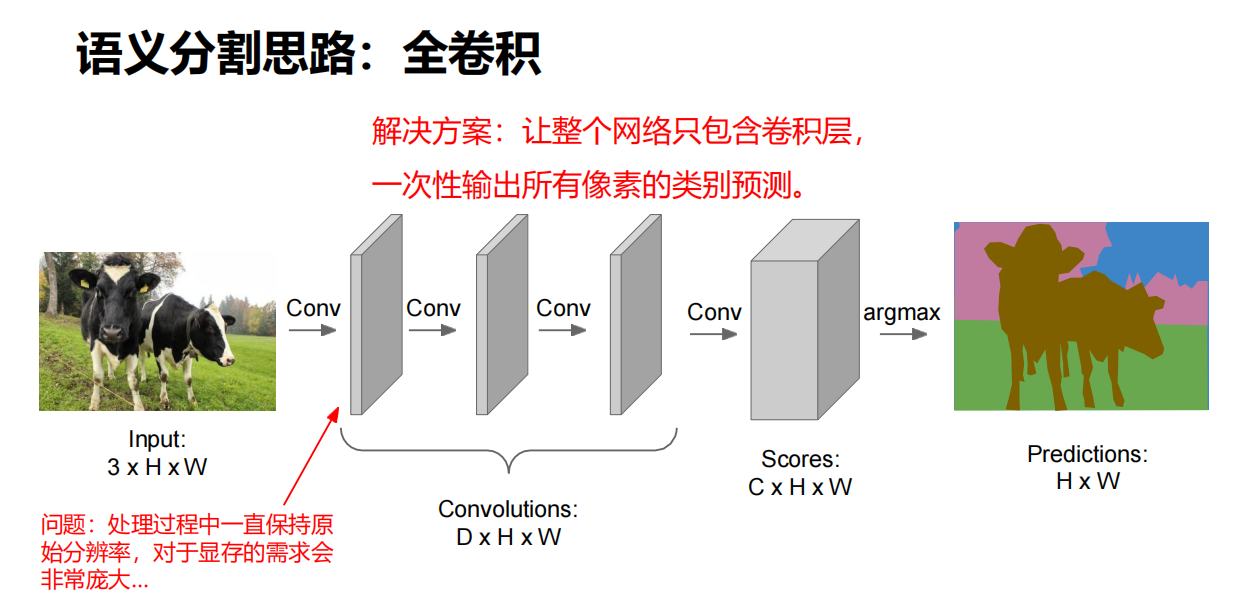
全卷积
-
解决方案
让整个网络只包含卷积层,一次性输出所有像素的类别预测。
-
问题
处理过程中一直保持原始分辨率,对于显存的需求会非常庞大。
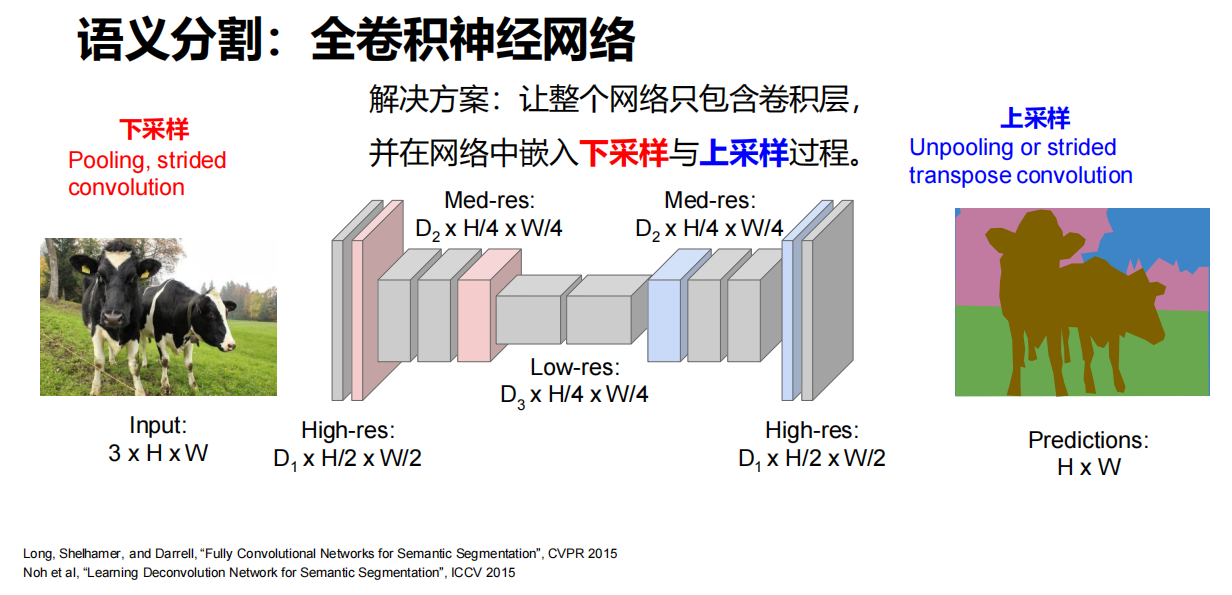
-
解决方案
让整个网络只包含卷积层,并在网络中嵌入下采样与上采样过程。
反池化操作
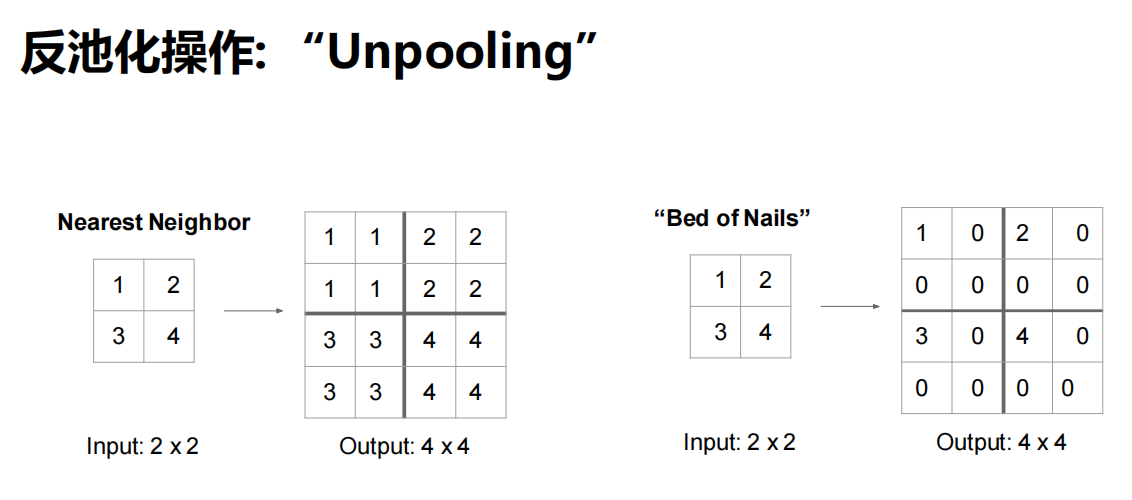
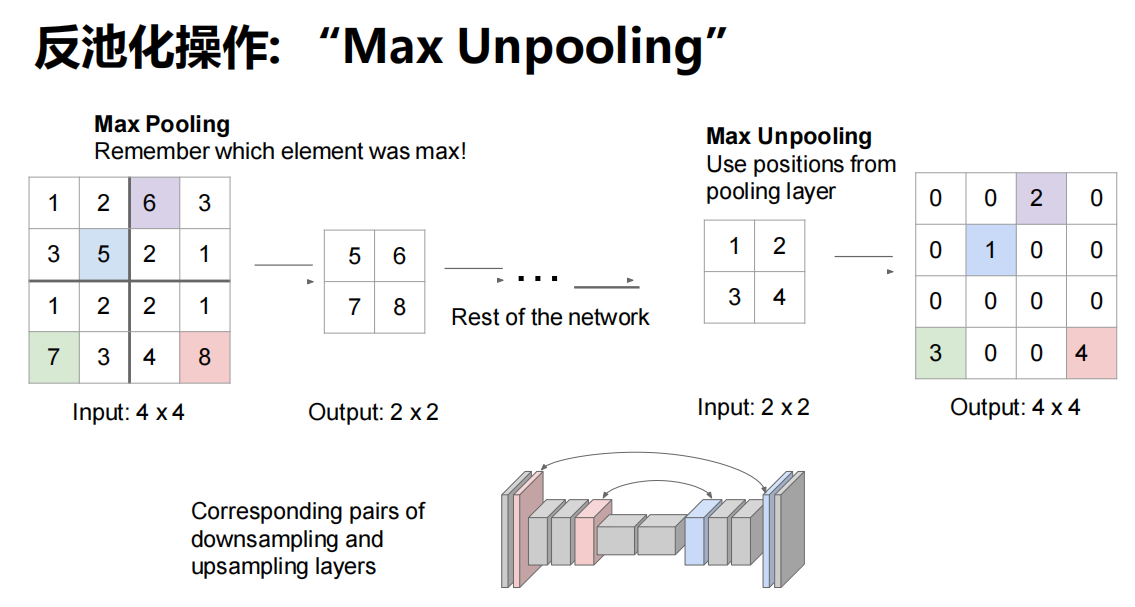
转置卷积
-
可学习的上采样
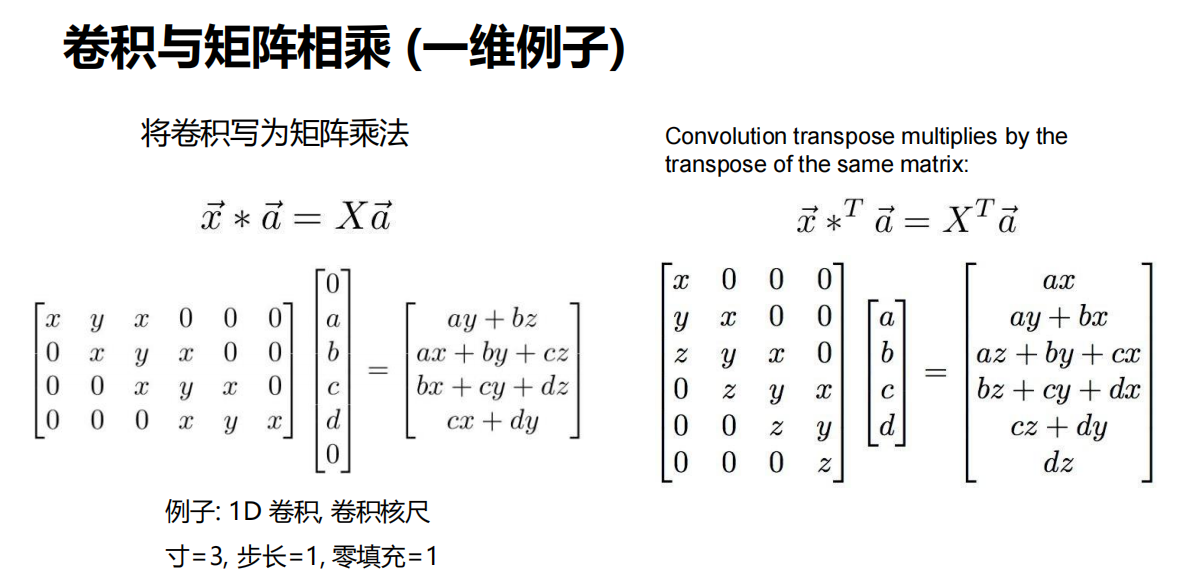
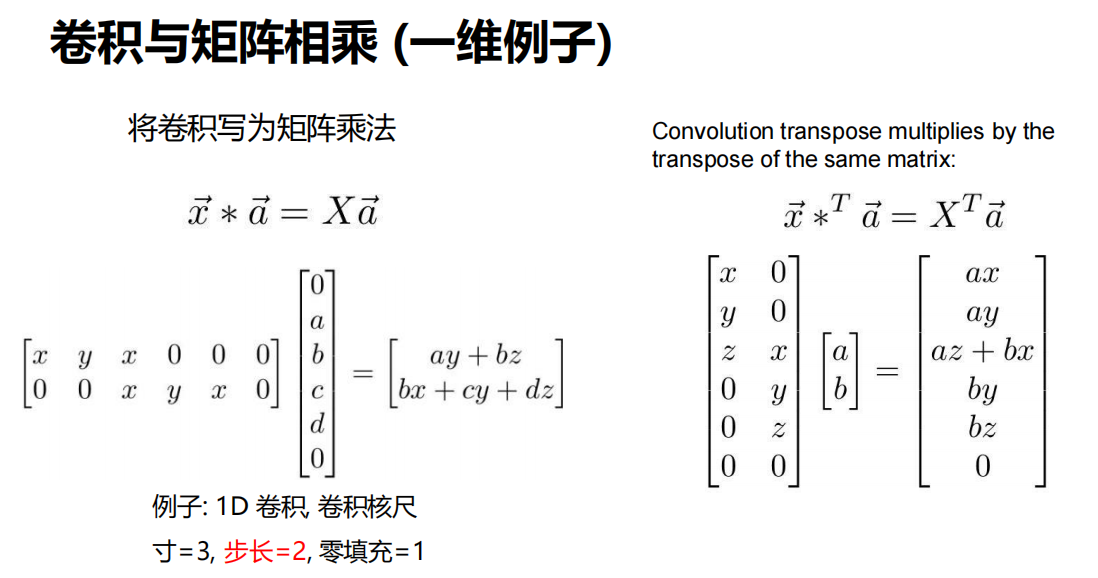
转置卷积(Transpose Convolution)
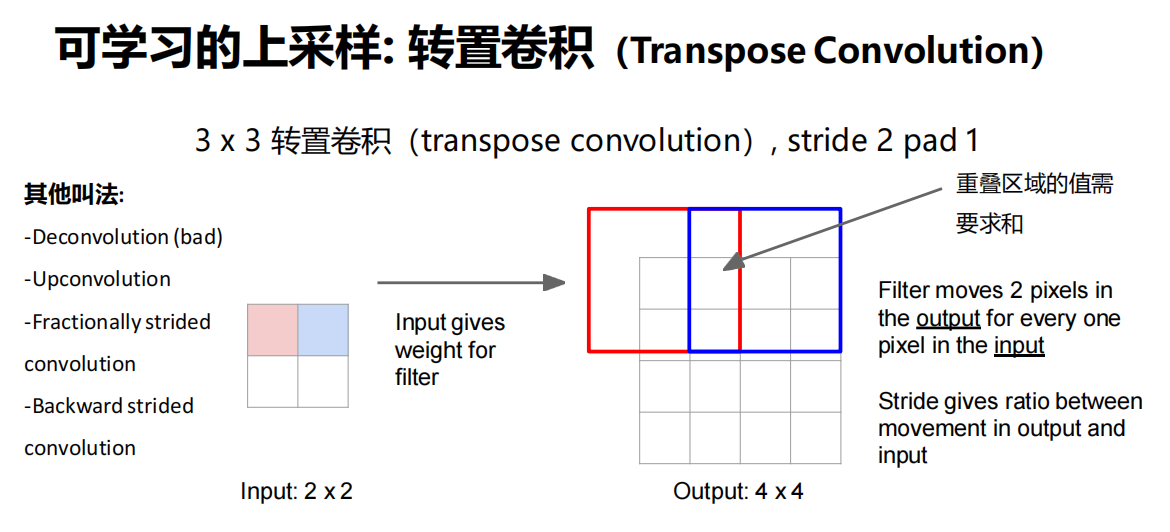
- 操作
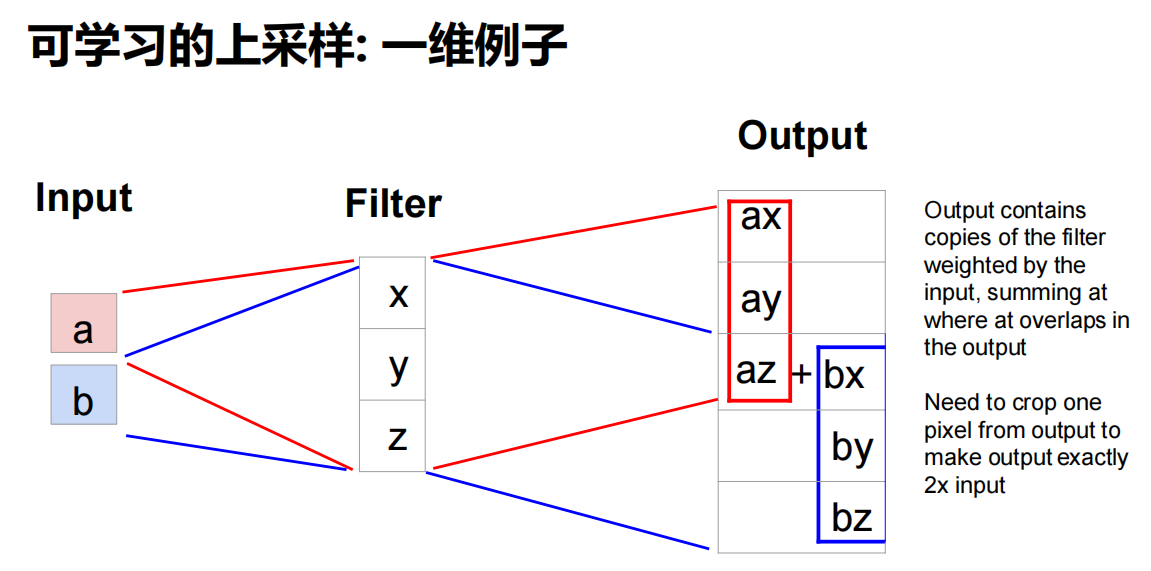
7.3 目标检测
单目标
-
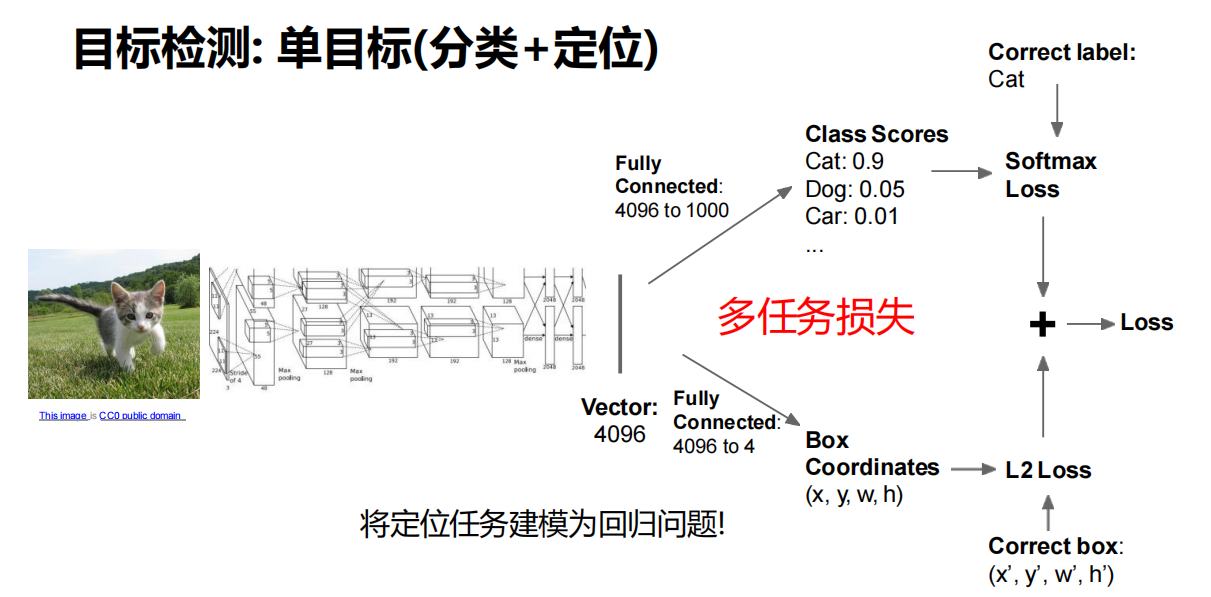
单目标(分类+定位)
将定位任务建模为回归问题!
采用多任务损失。
前面 常使用在ImageNet上预训练的模型 (迁移学习)
多目标
-
困境
每张图像期望输出的维度都不一样!

-
寻找区域
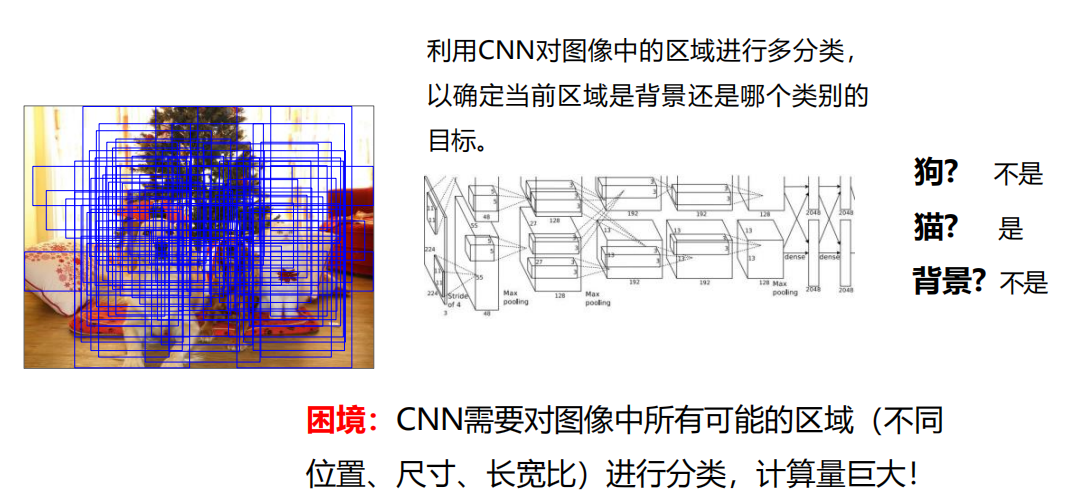
利用CNN对图像中的区域进行多分类,以确定当前区域是背景还是哪个类别的目标。
-
困境:
CNN需要对图像中所有可能的区域(不同位置、尺寸、长宽比)进行分类,计算量巨大!
区域建议

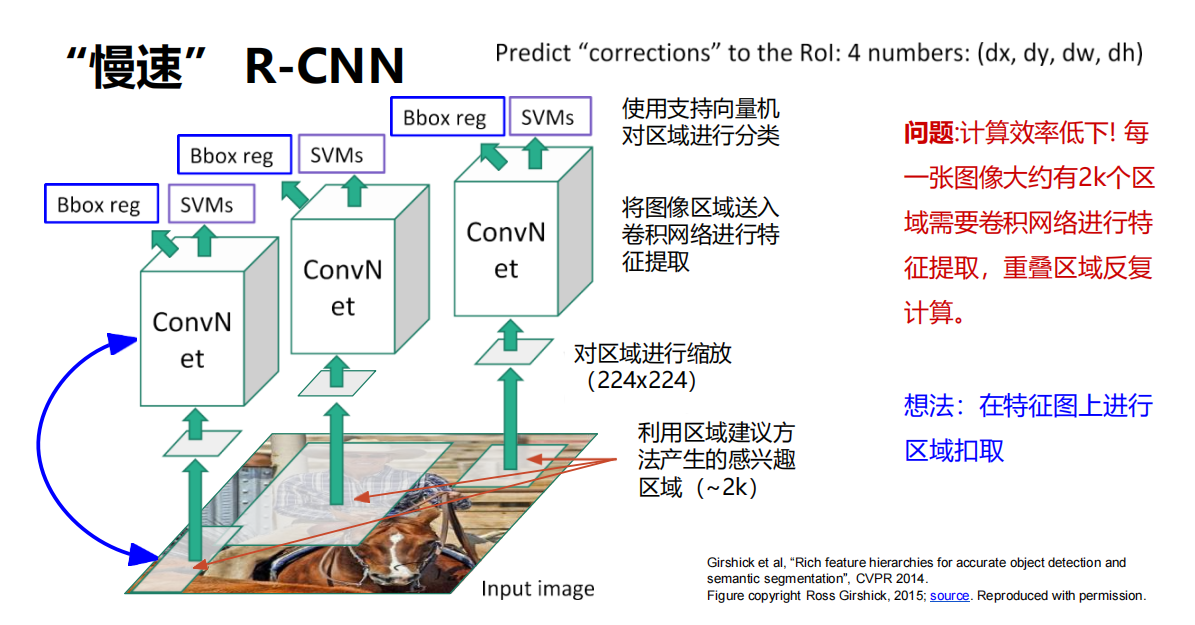
R-CNN
-
想法
在特征图上进行区域扣取
-
问题
计算效率低下!
每一张图像大约有2k个区域需要卷积网络进行特征提取,重叠区域反复计算。
-
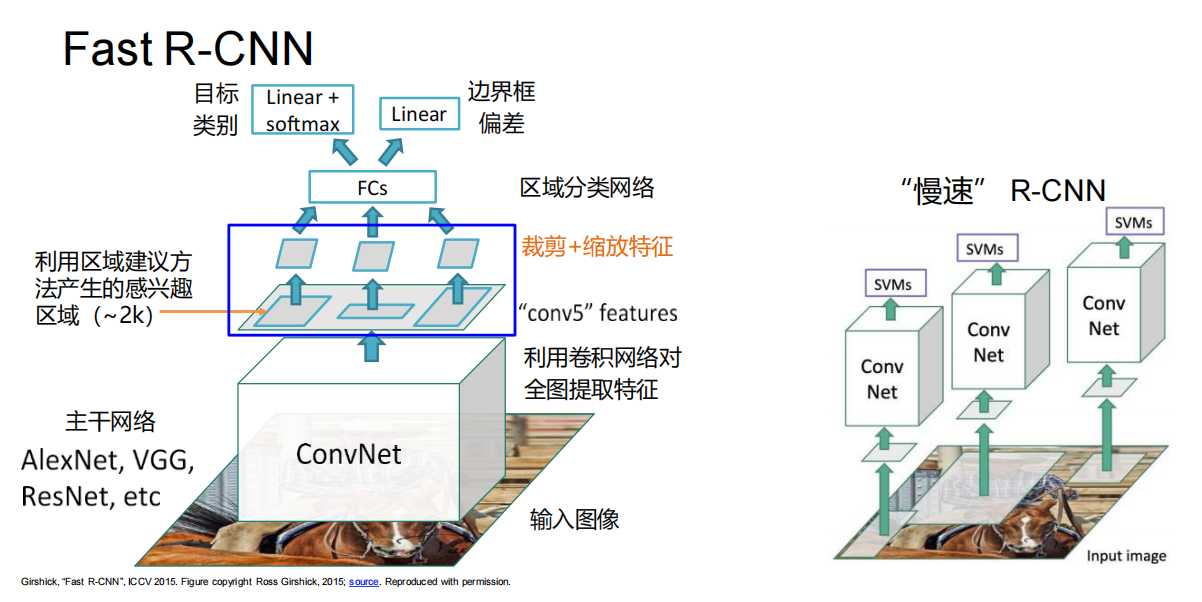
改进
裁剪+缩放特征
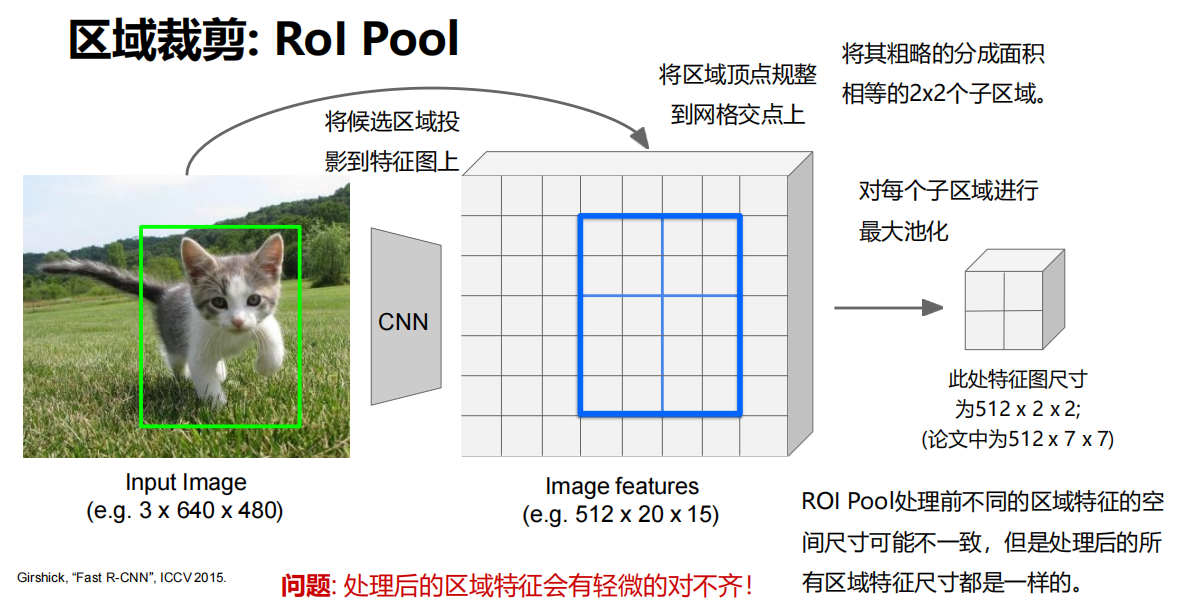
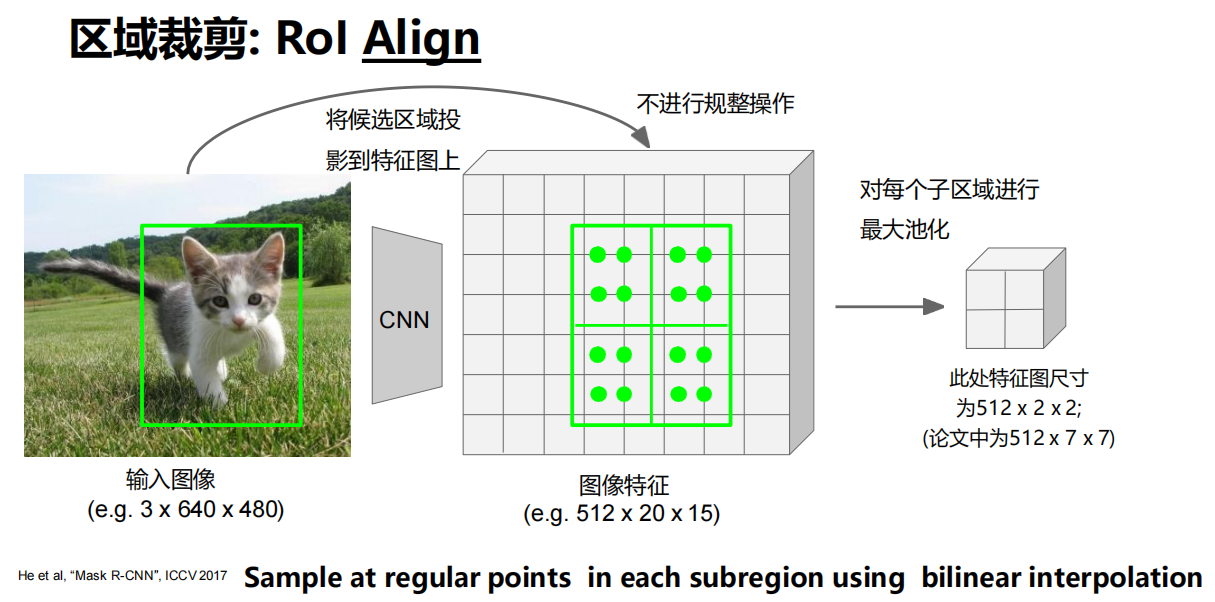
- 两种区域裁剪
Faster R-CNN
-
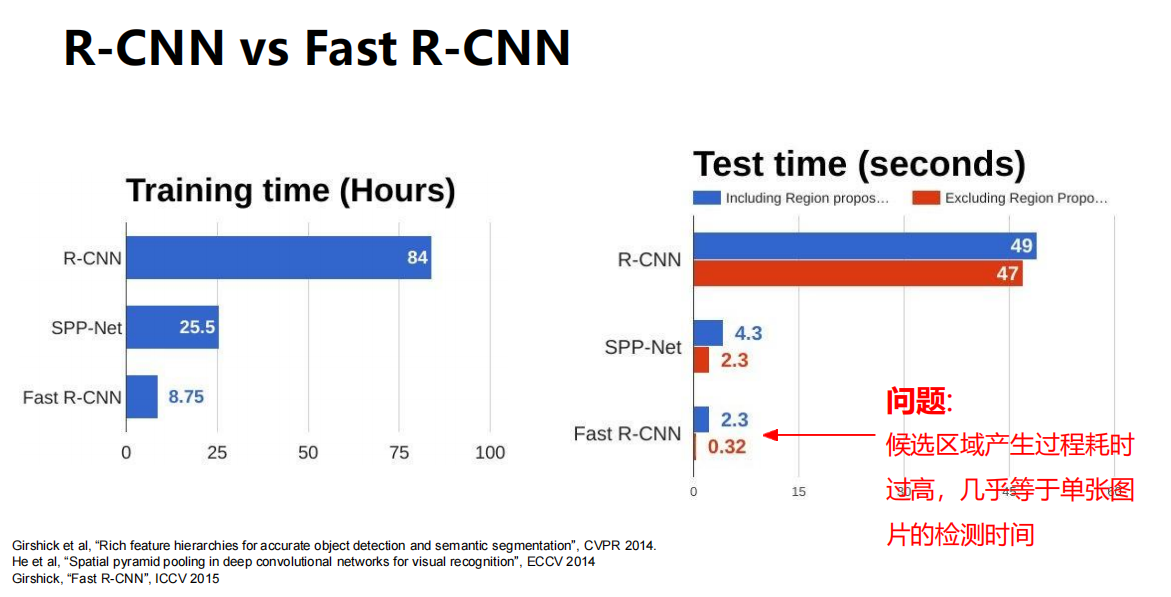
还不够快
候选区域产生过程耗时过高,几乎等于单张图片的检测时间。
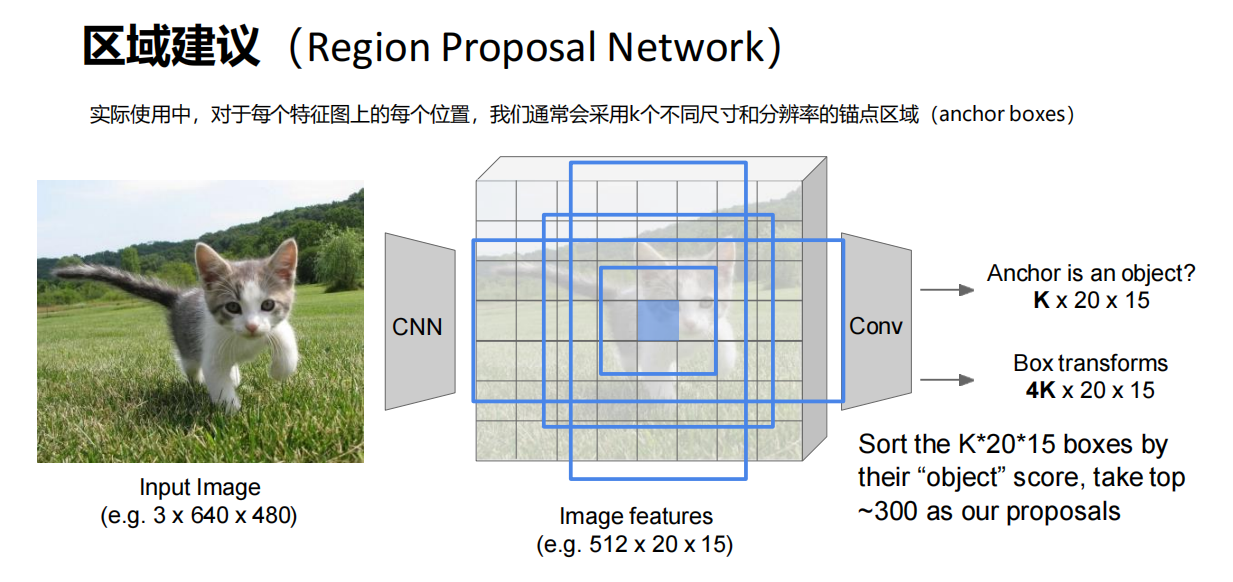
- ”锚点“ 区域裁剪
- 二段的网络
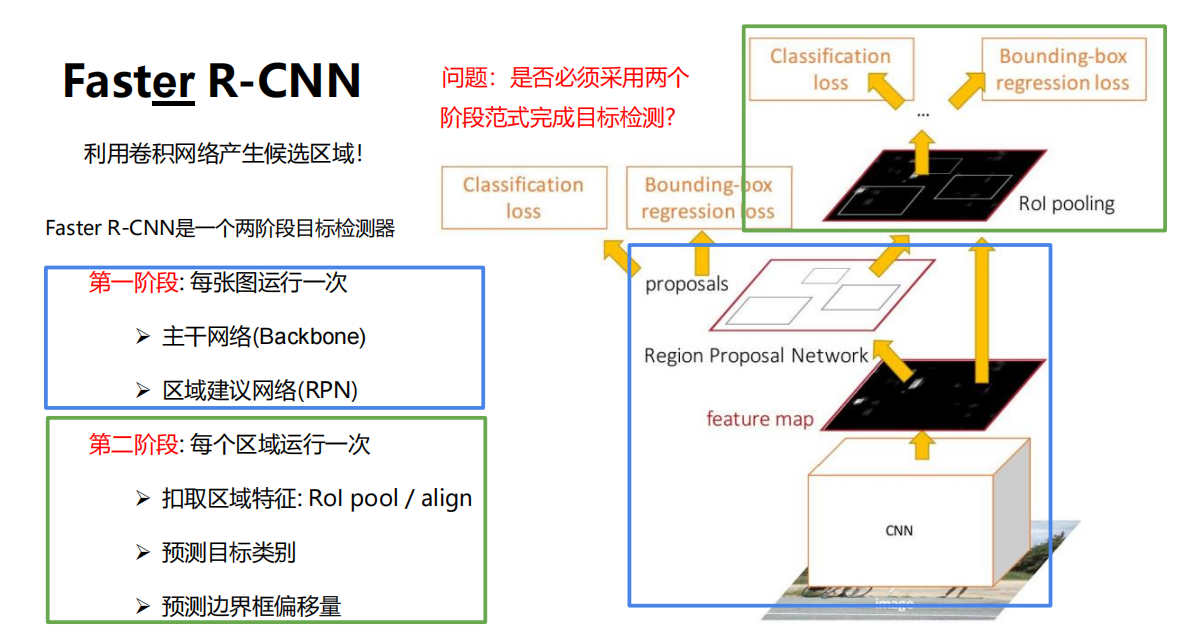
- 利用卷积网络产生候选区域!
- 四种损失联合训练:
- RPN分类损失(目标/非目标)
- RPN边界框坐标回归损失
- 候选区域分类损失
- 最终边界框坐标回归损失
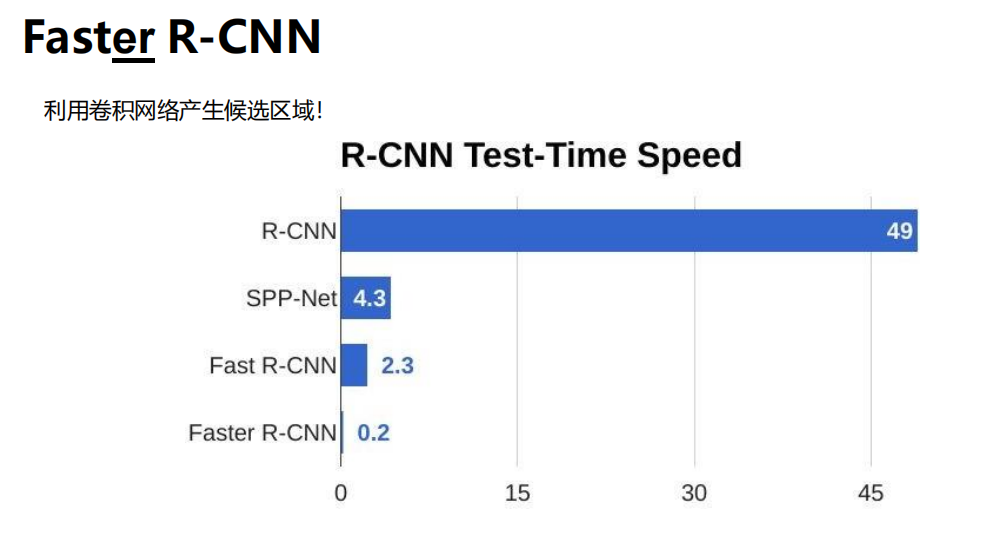
影响因素

7.4 实例分割
Mask R-CNN
- 添加一个小型 mask 网络,在每个RoI上运行
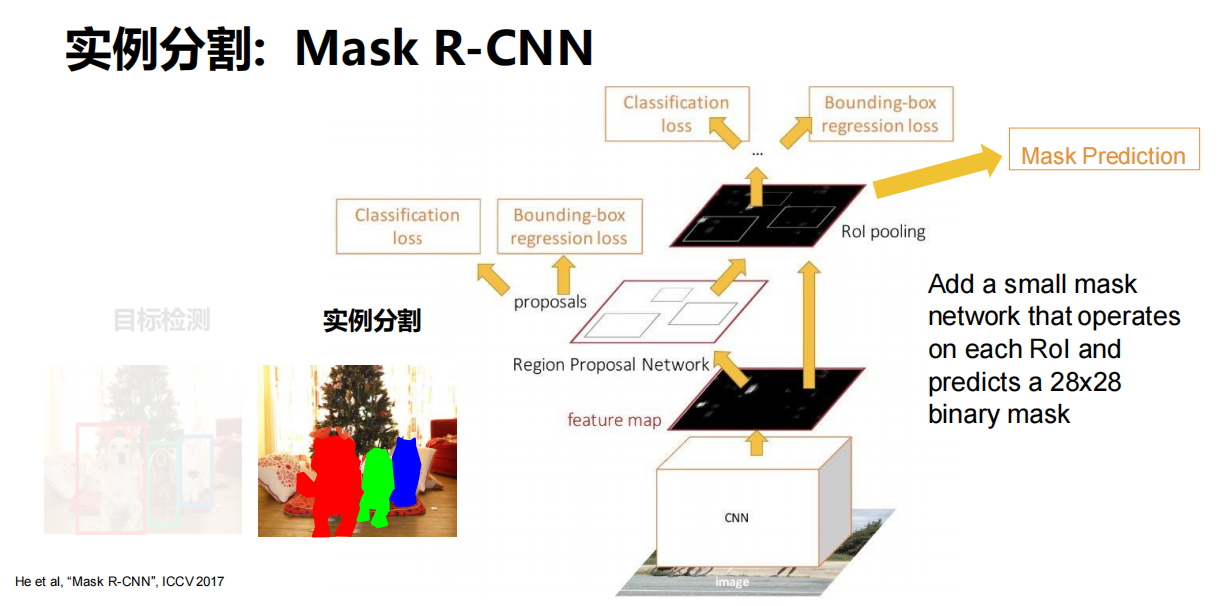
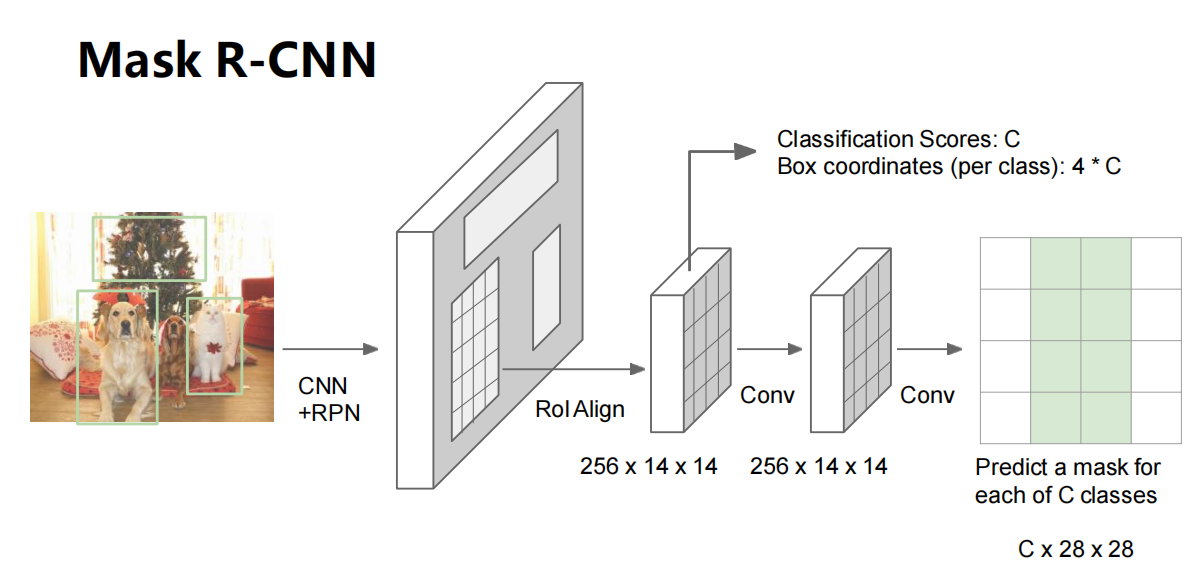

- 效果


本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 isSeymour!
 微信支付
微信支付 支付宝
支付宝



评论