
CVDL - Transformer
十一、Transformer
11.1 架构
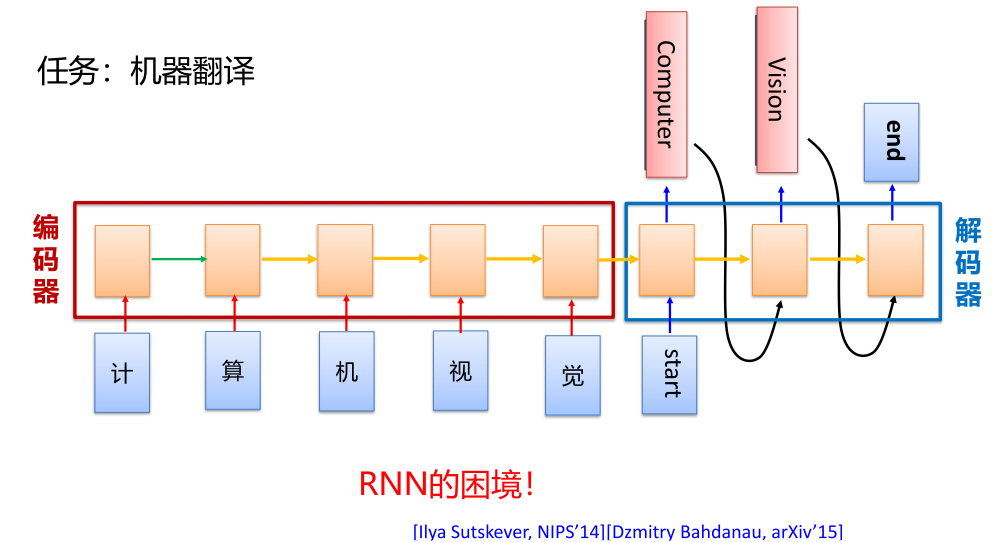
RNN困境
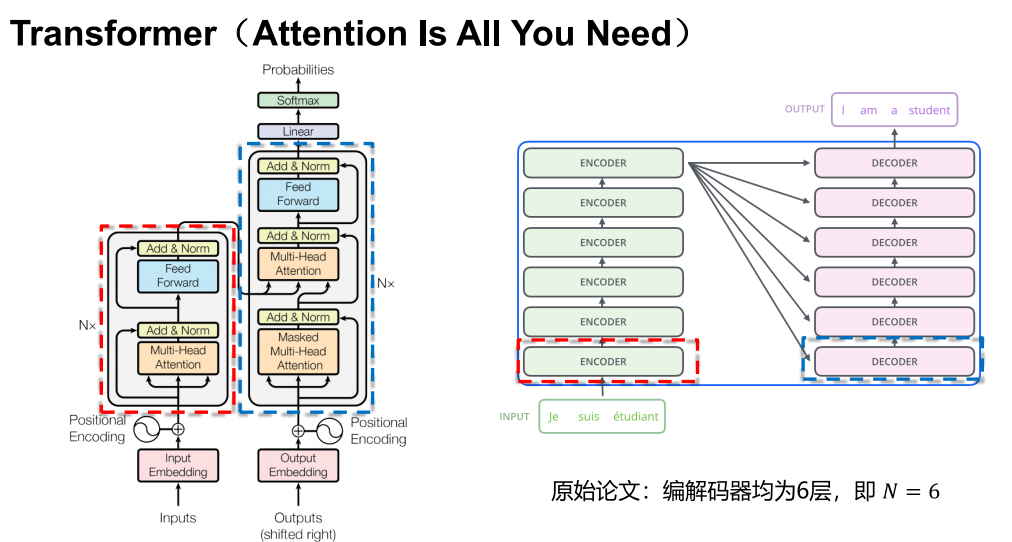
Transformer 提出
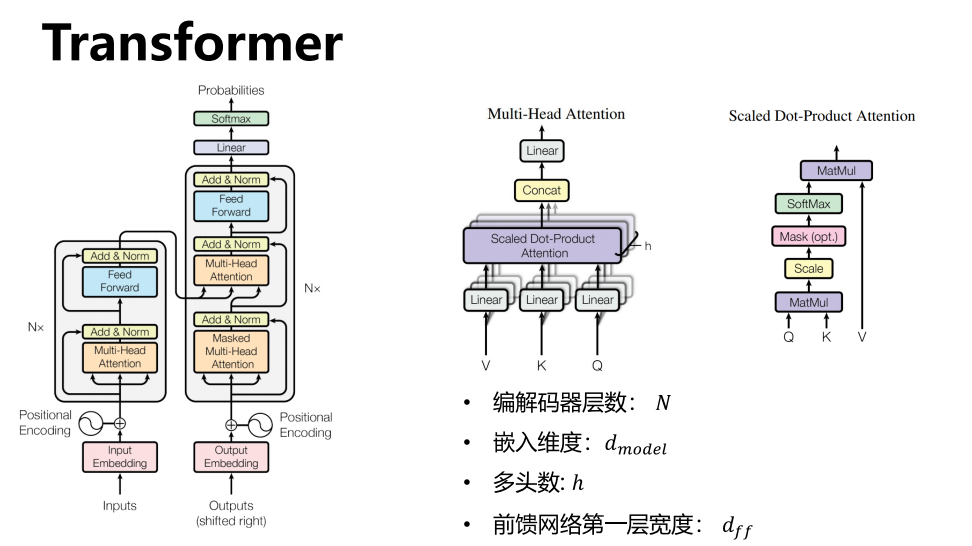
架构
11.2 输入输出
输入输出
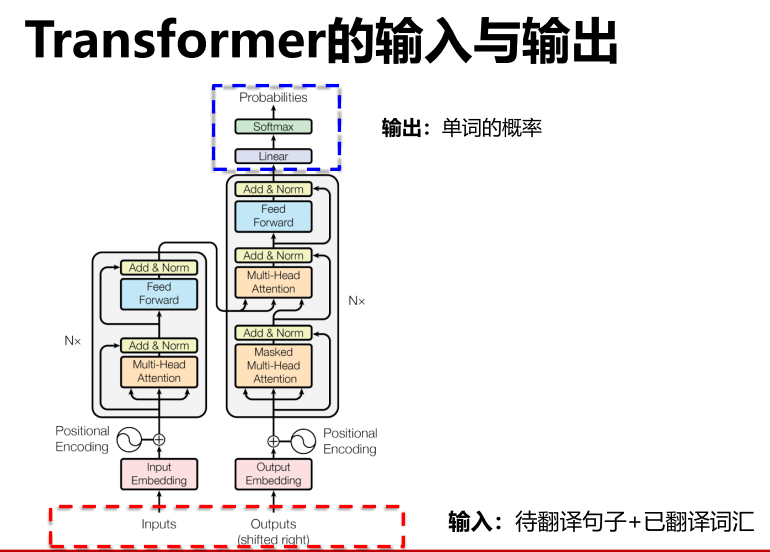
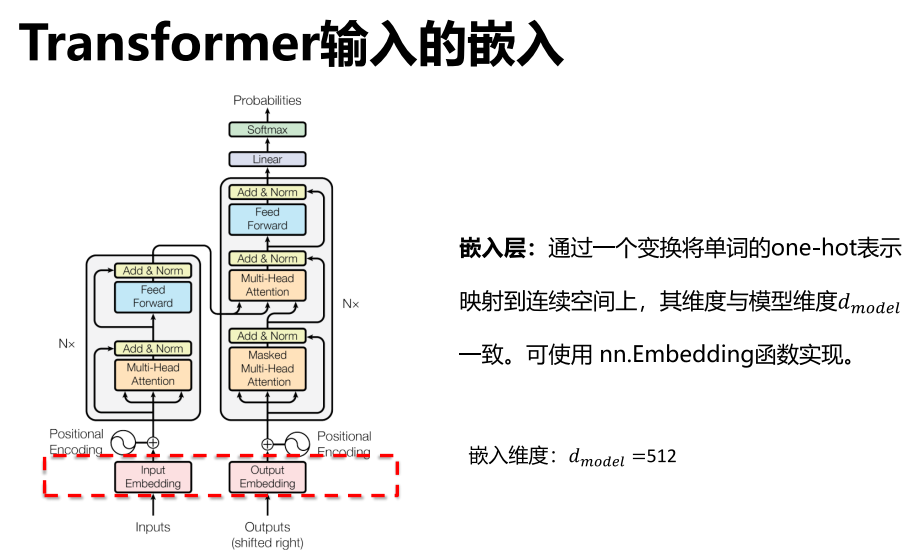
嵌入 PE 位置编码
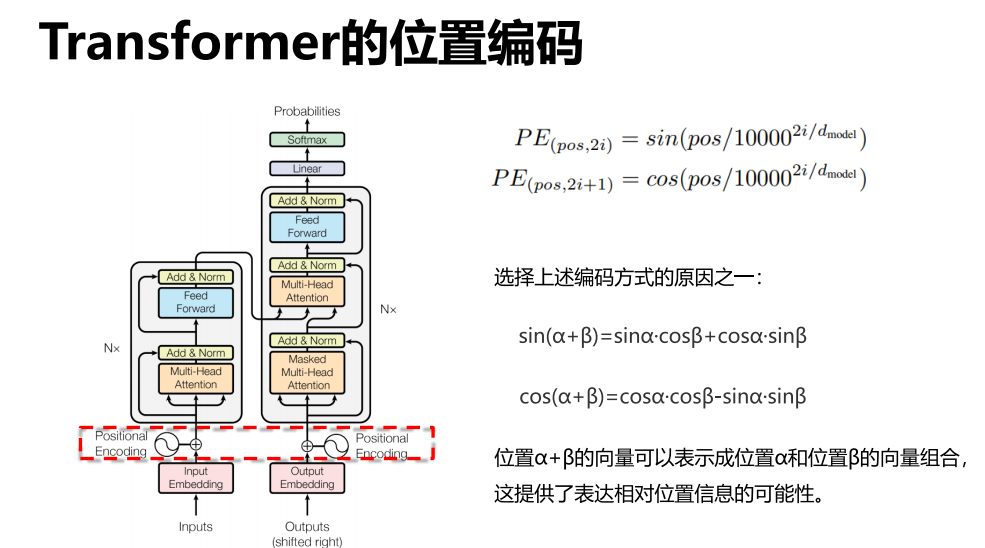
- 位置编码
输入还需要经过一个PE(检测位置信息)
如“我爱中国”和“爱我中国”不应该一样,但是若没有PE层,则会使得输入变得一样效果。
编码解码
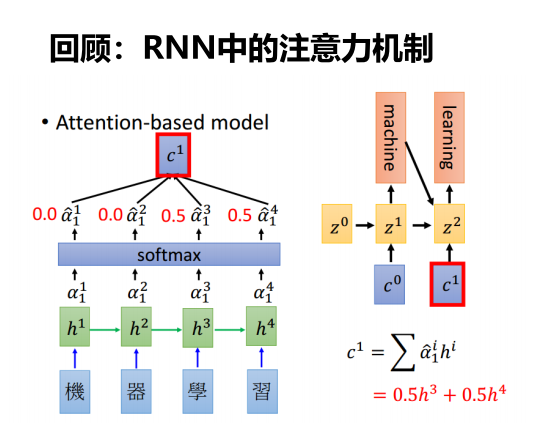
11.3 多头注意力
编码器
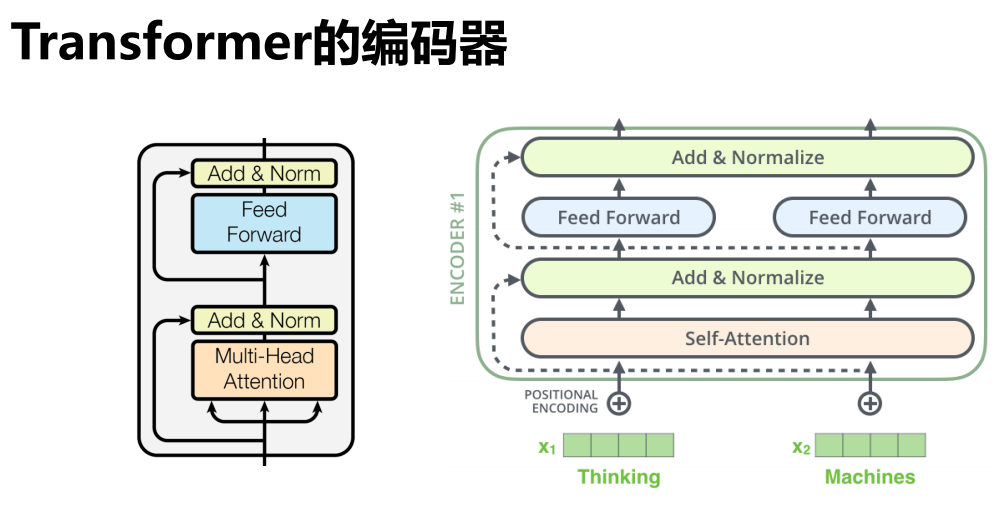
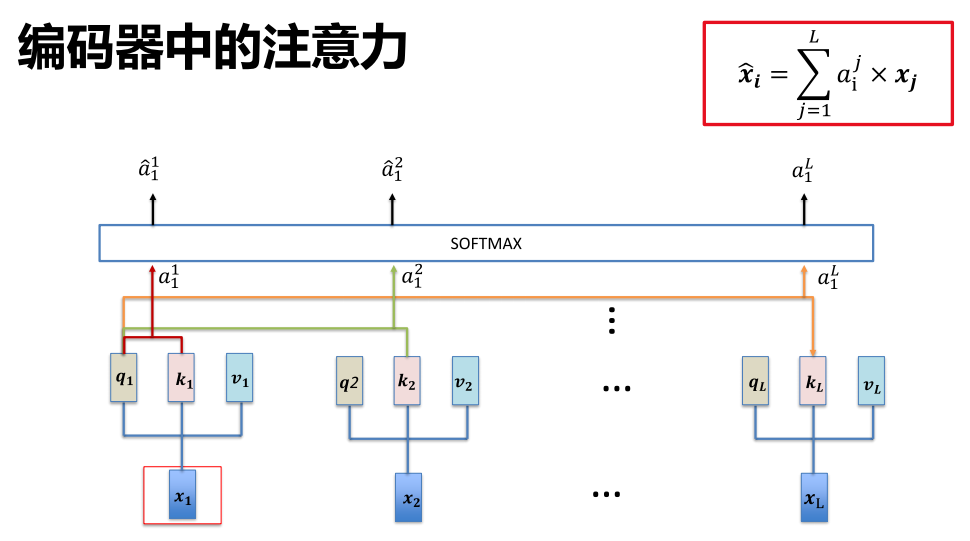
注意力计算
-
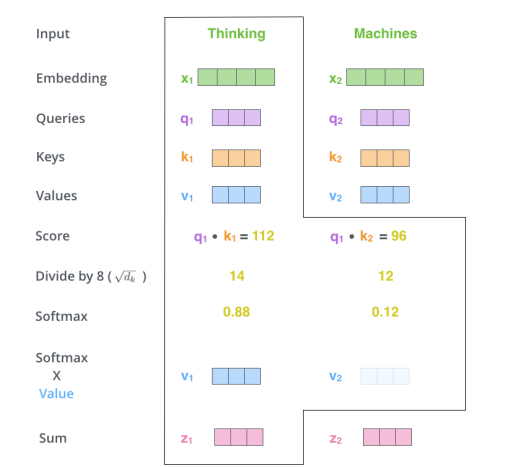
计算方法
下图为计算一个 x1得到 z1 的过程。
矩阵合并表示
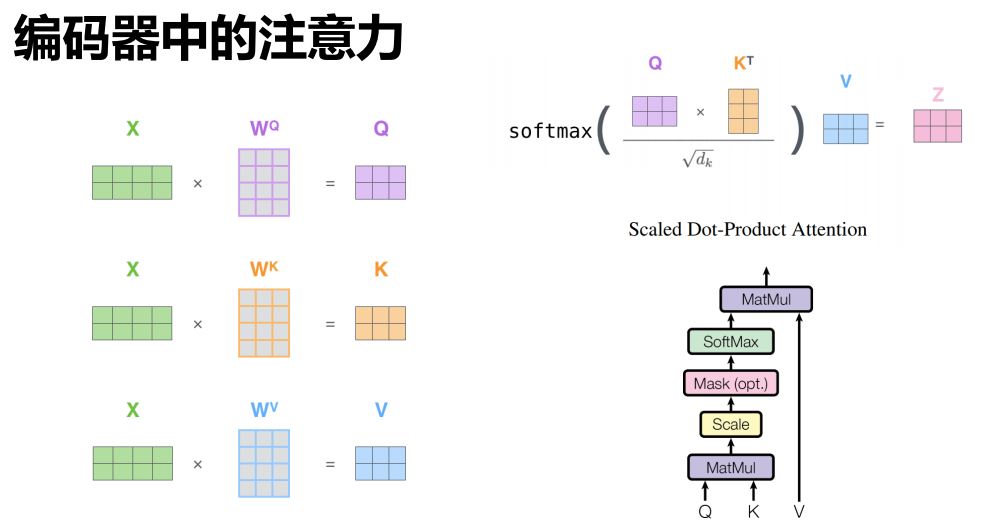
多头
- 并行地计算多个 Z ,最后使用 W 综合效果即可。
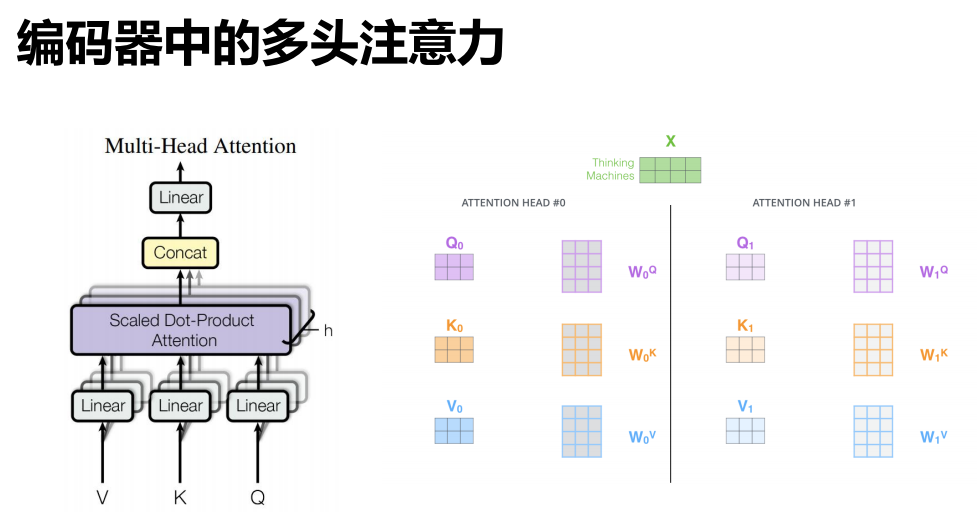
计算过程:
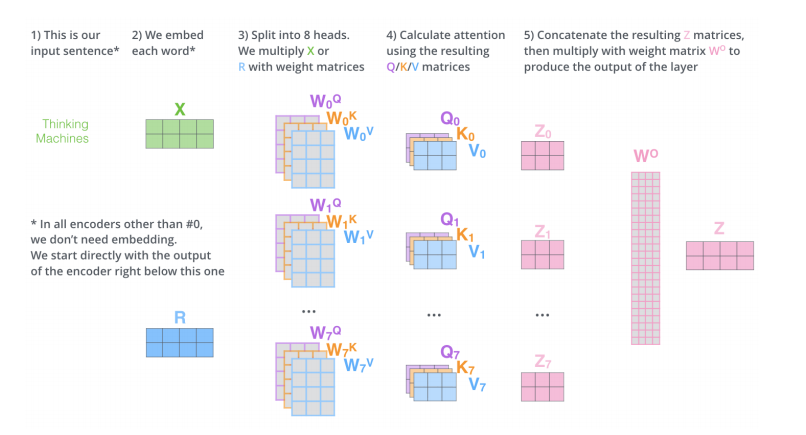
头数推导:

11.4 ADD&Norm
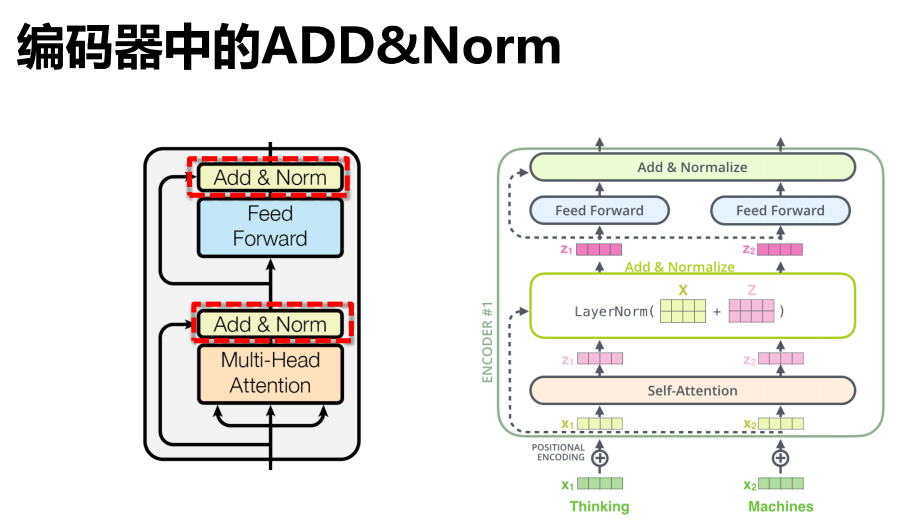
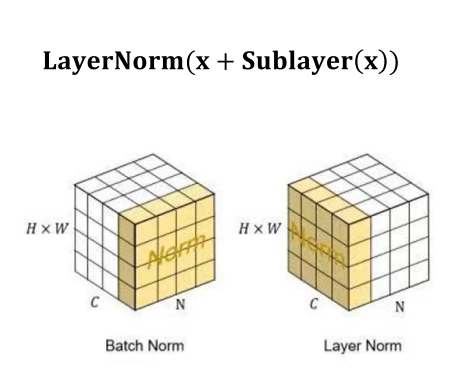
区分不同的Norm:
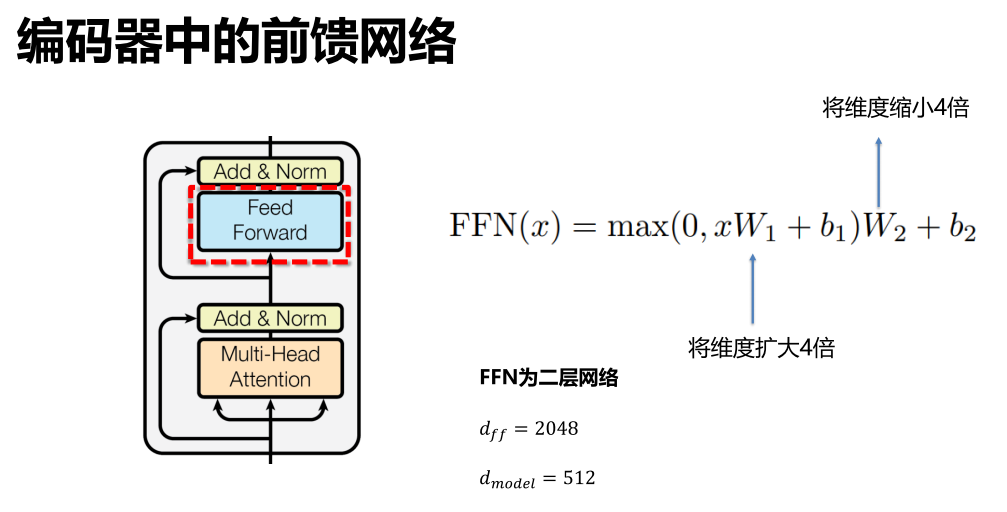
11.5 前馈网络
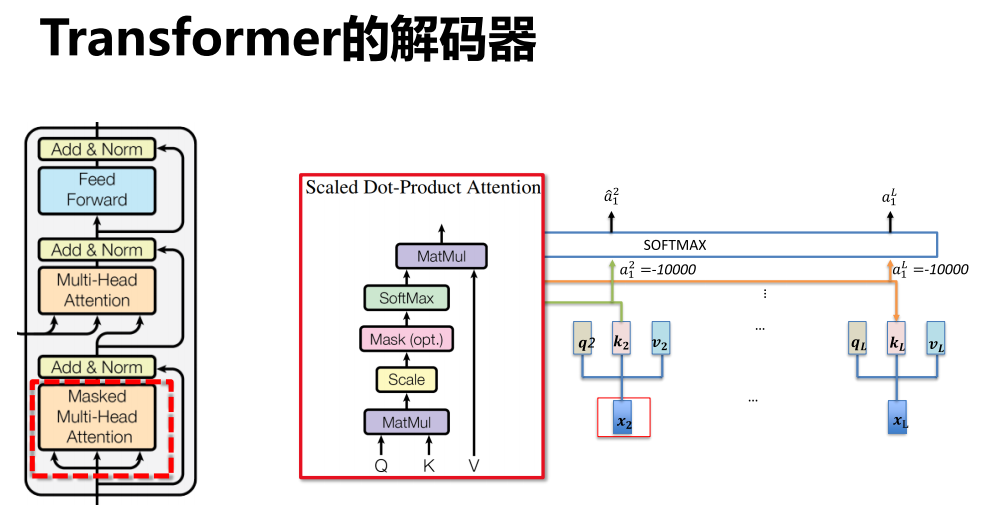
11.6 解码器
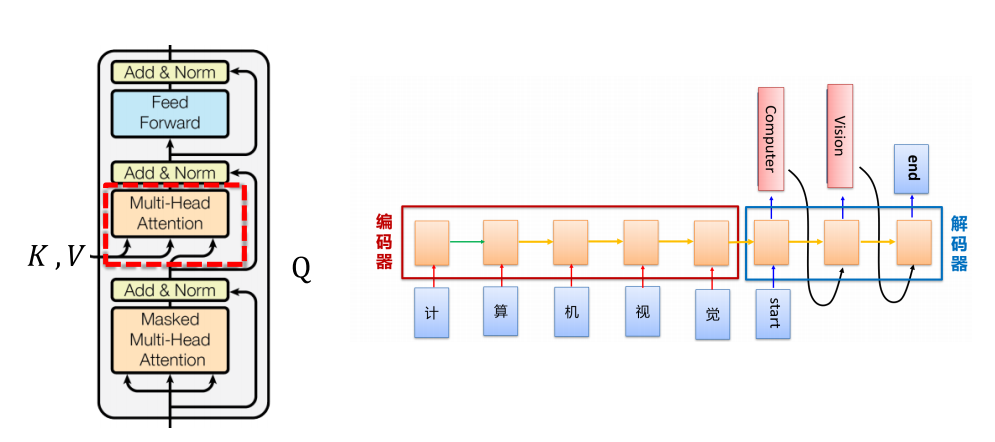
11.7 图像领域
自监督学习
-
使用无标注数据用自我监督的方式学习特征表示的方法。
其通过构造一个代理任务(pretext task)来实现特征表示学习。
-
代理任务
- 预测类任务
- 生成式任务
- 对比学习任务
- …
代理任务的监督信息来源是从数据本身获得的。
-
举例
完型填空(BERT)、预测下一个单词(GPT)
典型用法:通过自监督学习完成特征提取器的预训练,然后,在下游任务上进行微调。
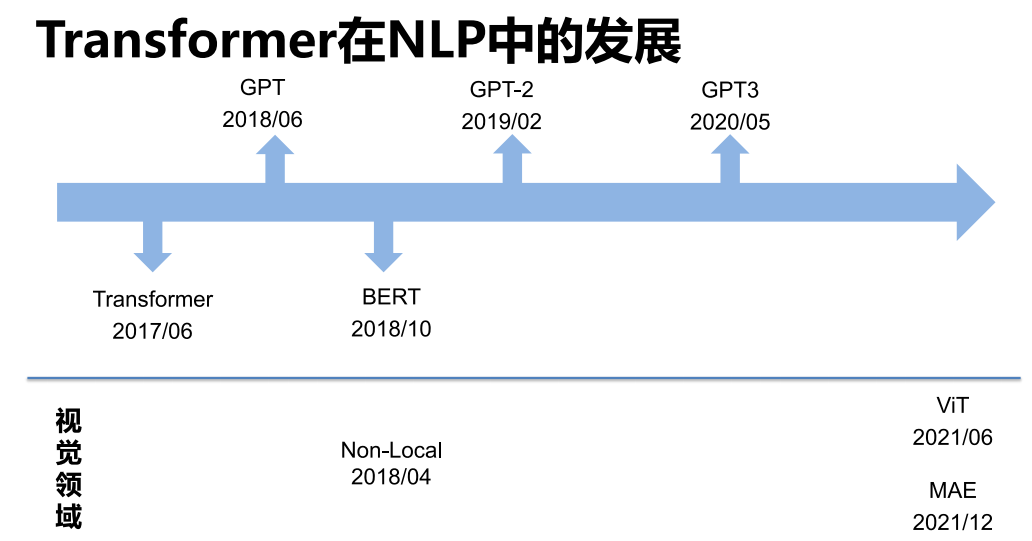
发展
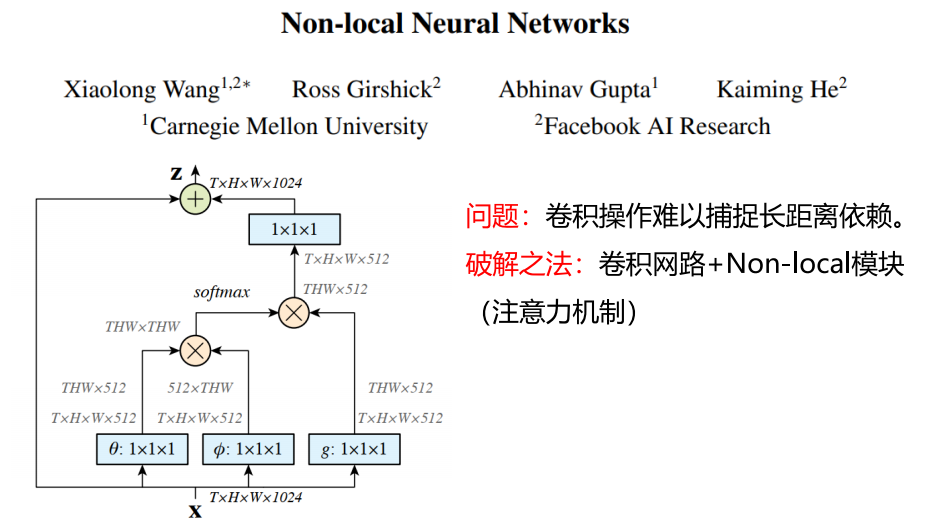
Non-Local
-
问题
卷积操作难以捕捉长距离依赖(卷积的做法是不断堆积更多层,从而获得更大的感受野)
-
破解之法
卷积网络 + Non-Local 模块(注意力机制)
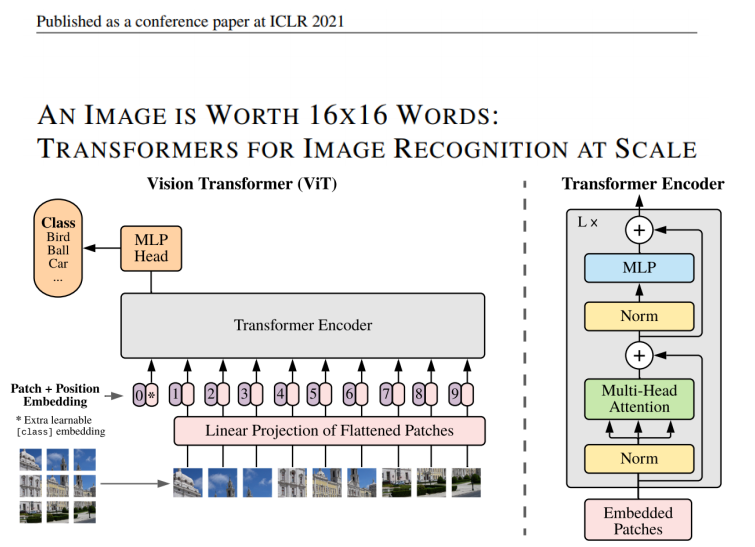
ViT
-
CNN在 图像领域 的统治地位
-
Transformer在 自然语言处理 领域如此成功
-
Transformer在 图像领域 也可以获得与CNN相当甚至更高的精度
虽然缺少局部性与平移性的归纳偏置需要大量的数据进行训练

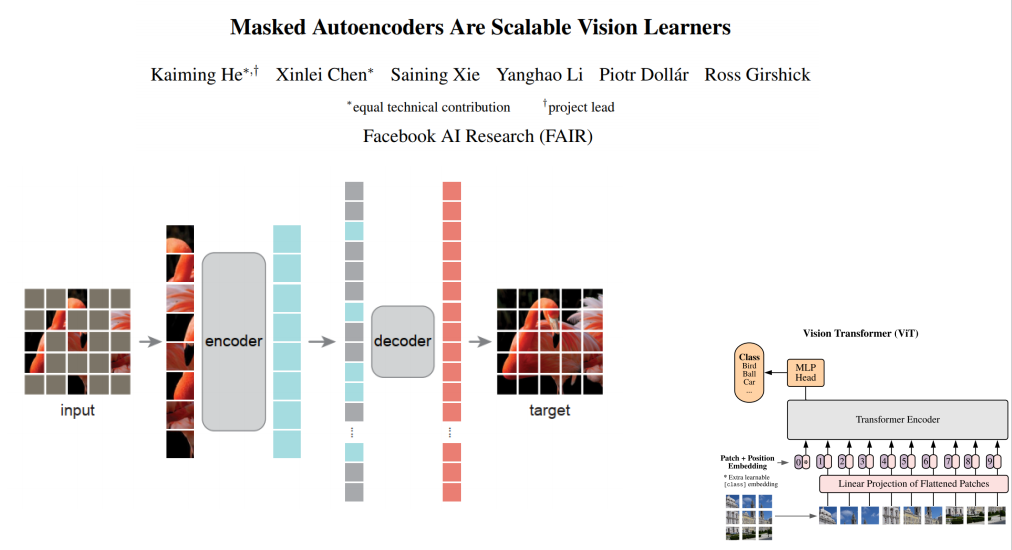
MAE
- 提出一个非对称的编解码器网络
- 自监督学习,采用高比率的遮挡预测任务作为代理任务
- lmagenet-1K上训练达到了87.8%,且在检测、分割等任务上均达到了SOTA
- 训练过程快
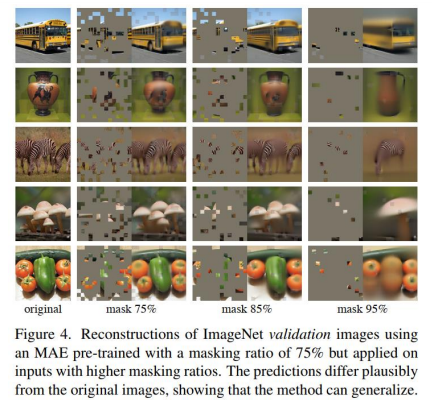
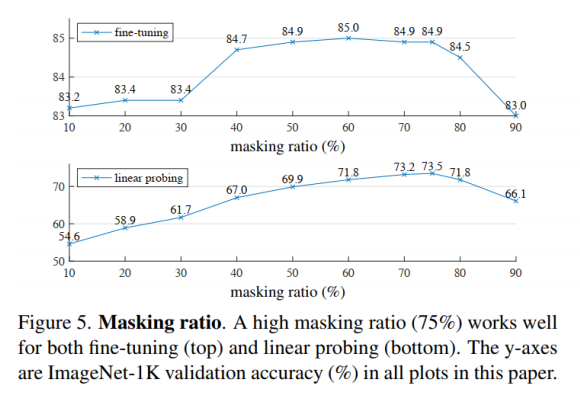
- 效果

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 isSeymour!
 微信支付
微信支付 支付宝
支付宝



评论