
《数据库系统原理》知识点梳理
《数据库系统原理》知识点梳理
来源:同济大学《数据库系统原理》李文根老师课件
仅包含硬性知识点(背、记、看),不含理解性或实操性知识点(如SQL)。
2024-06-23@isSeymour
CH1 - 数据库系统概述
1.1 数据库系统
-
传统文件处理系统的缺点
- 数据的冗余和不一致性 (data redundancy and inconsistency)
- 数据访问困难(difficulty in accessing data)
- 数据孤立(data isolation)
- 完整性问题(integrity problems)
- 原子性问题(atomicity problem)
- 并发访问异常(concurrent-access anomaly)
- 安全性问题(security problems)
-
数据库(Database, DB)
-
什么是数据库?
- 一组相互有关联的数据集合
- 长期储存在计算机中的有组织的、可管理和可共享的数据集合
-
数据库的基本特征
- 数据按一定的数据模型组织、描述和储存
- 支持数据的增删改查
- 支持并发查询处理
-
什么是数据库系统?
-
数据库系统是指由数据库管理系统和相关工具组成的软件系统,用于管理和操作大量数据
-
一般包括
- 数据库
- 数据库管理系统
- 开发工具、应用系统
- 数据库管理员和终端用户
-
-
什么是数据库管理系统?
-
管理数据库的软件
-
定义1:用户(应用程序)与操作系统之间的数据库管理软件
-
定义2:一个管理数据的大型复杂基础软件系统
-
-
数据库管理系统的用途
- 优雅查询和数据抽象
- 高效组织和存储数据
- 正确一致的并发更新
- 低时延高吞吐的查询
- 并行高效的有序执行
- 可用性和高可靠保证
- 安全可信的统一控制
- 方便易用的用户接口
-
数据库的核心用途
- 数据库是数据基础设施
- 数据库是核心基础软件
- 数据库已赋能千行百业
数据库是计算机的核心基础软件之一。向下发挥算力、向上支撑应用。
-
1.2 数据视图
-
数据抽象的层次
- 物理层(Physical level)
- 逻辑层(Logical level)
- 视图层(View level)
-
模式与实例(Schema and Instance)
-
模式(Schema)
数据库的逻辑结构。三种模式:
-
Physical schema(物理模式/内模式/存储模式): design at the physical level
-
Logical schema(逻辑模式/模式): design at the logical level
-
External schema(外模式/子模式): define at the app level
-
-
实例(Instance)
特定时刻存储在数据库中信息的集合称为数据库的一个实例。
模式和实例之间的关系类似编程语言中数据类型和变量之间的关系。
- 物理数据独立性(Physical data independence)
- 逻辑数据独立性(Logical data independence)
-
-
数据模型(Data Models)
描述数据、数据联系、数据语义及一致性约束的概念工具集合。
- 关系模型(Relational model)
- 实体-联系模型(Entity-Relationship data model)
- 半结构化数据模型(Semi-structured data model)
- 基于对象的数据模型(Object-based data models)
- 其他数据模型
-
数据模型和数据库模式
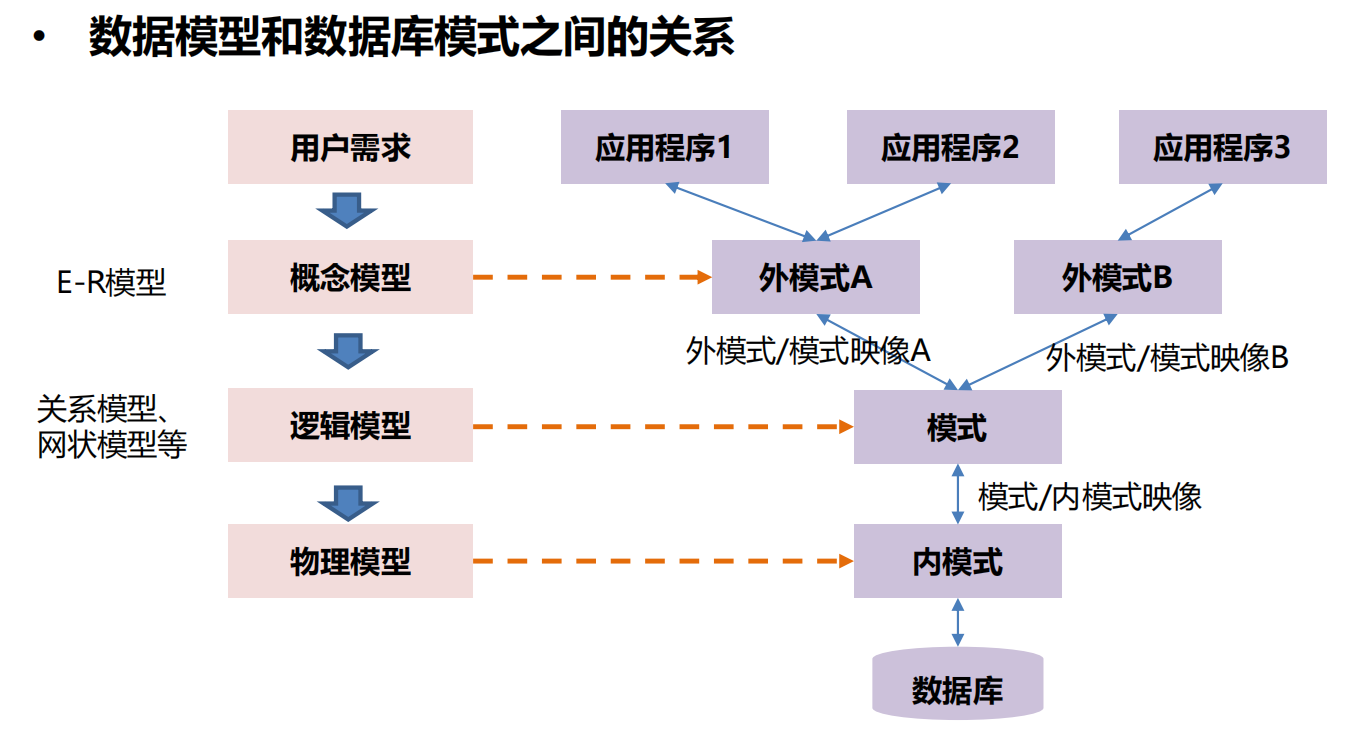
1.3 数据库语言
-
数据库语言
-
数据定义语言(Data-definition language, DDL)
定义数据库模式
-
数据操纵语言(Data-manipulation language, DML)
访问或操纵按照某种适当数据模型组织的数据
SQL同时包含DDL和DML。
SQL: Structured Query Language, widely used non-procedural language
-
1.4 数据库设计
-
数据库结构设计过程
- 概念设计(Conceptual design)
- 逻辑设计(Logical design)
- 物理设计(Physical design)
-
E-R模型
通过实体和关系建模数据
1.5 数据库引擎
-
组成
-
存储管理器(Storage manager)
存储访问、文件组织、索引
-
查询处理器(Query processor)
DDL解释器、DML编译器、查询执行引擎
-
事务管理器(Transaction manager)
并发控制管理器、恢复管理器
-
1.6 数据库和应用体系结构
- 数据库系统结构
- 用户
- 应用和工具
- 数据库管理系统
- 数据库
- 数据库应用系统结构
- 两层体系结构
- 三层体系结构
1.7 数据库用户和管理员
-
数据库用户分类
- Naive users(无经验用户)
- Application programmers (应用程序员)
- Sophisticated users(熟练用户)
-
数据库管理员(Database Administrator, DBA)
DBA是数据库系统中所有活动的管理者和协调者,对DBMS以及企业的信息资源和需求有较好的理解。
DBA的职责:
- 模式定义
- 存储结构和访问方法定义
- 修改架构和物理组织
- 授予数据访问授权
- 例行维护
- 指定完整性约束
- 与用户保持联系
- 监控性能,并对需求的变化做出反应
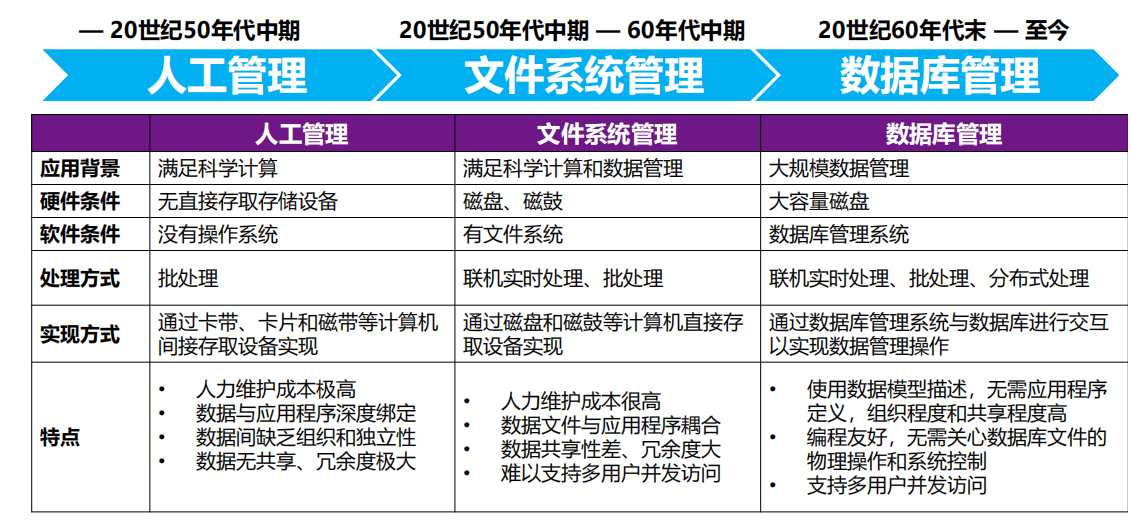
1.8 数据库系统的历史
-
数据库管理的三个历史阶段
1.9 前沿发展方向
-
数据库的3次主要变革
-
第1代是单机数据库
解决了数据存储、数据管理和查询处理等问题
代表系统包括Oracle, PostgreSQL和MySQL等
-
第2代是集群数据库
旨在为企业关键业务提供高可用性和可靠性保障
代表系统包括Oracle RAC, IBM DB2和Microsoft SQL Server
-
第3代是分布式数据库和云原生数据库
旨在解决大数据时代的弹性计算和动态数据迁移问题
代表系统包括亚马逊Aurora、华为openGauss和蚂蚁科技的OceanBase
-
-
四大目标与九大技术方向
- 降低成本,提升易用性。
- HTAP数据库
- 多模数据管理
- 数据库+AI
- 保障数据安全可信
- 防篡改数据库
- 全密态数据库
- 提升功能,增强性能
- 软硬件协同发展
- 云原生数据库
- 满足新兴业务需求
- 大规模图数据处理
- 实时湖仓
- 降低成本,提升易用性。
Part-1 关系数据库
CH2 - 关系模型 Relational model
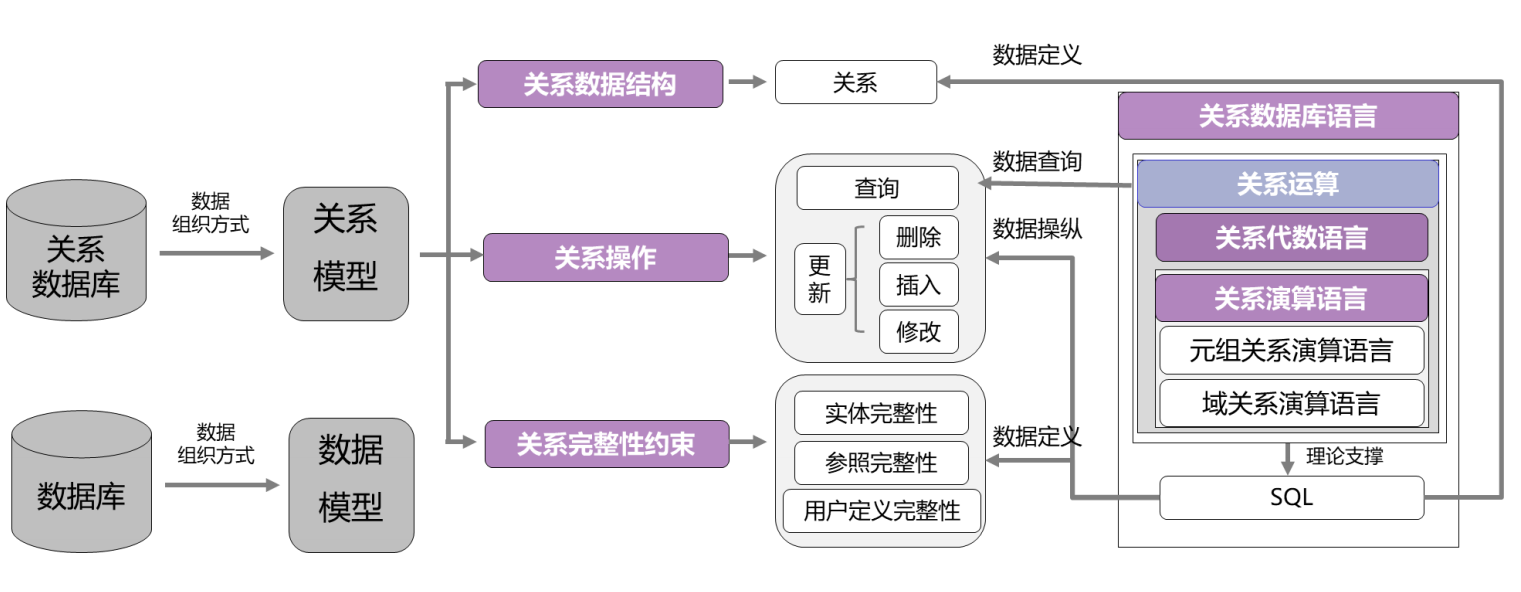
2.1 关系数据库的结构
- 关系、属性
- 关系模式、关系实例
2.2 数据库模式
- 无
2.3 码
-
超码(Superkey)
-
候选码(Candidate key)
-
主码(Primary key)
-
外码(Foreign key)
-
参照完整性约束(Referential integrity constraint)
2.4 模式图
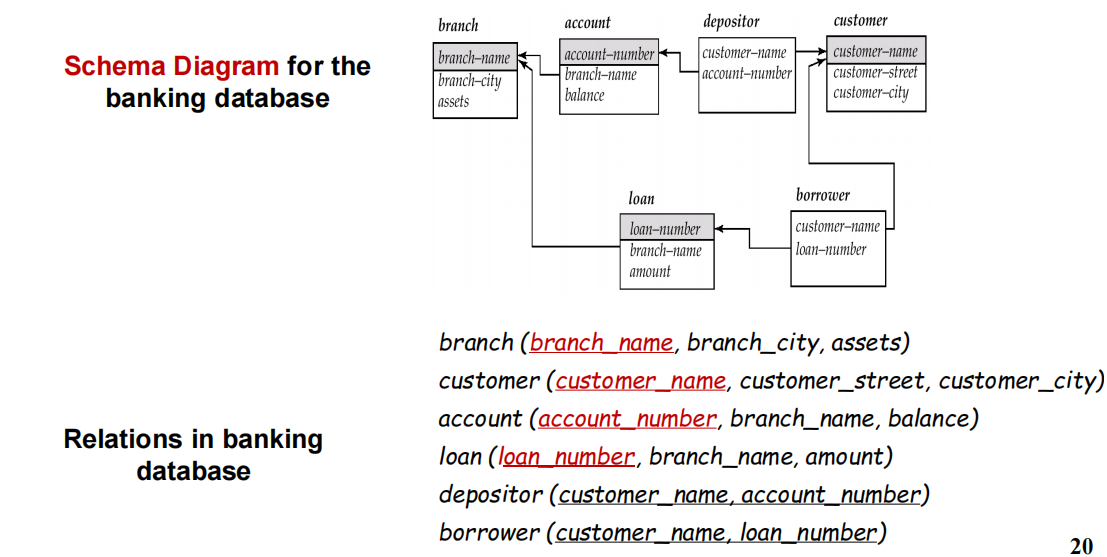
2.5 关系查询语言
-
分类
-
Procedural 过程式/函数式
- Relational Algebra(关系代数)
-
Non-procedural/Declarative 非过程式/声明式
- SQL(结构化查询语言)
- Tuple Relational Calculus(元组关系演算)
- Domain Relational Calculus(域关系演算)
-
2.6 关系代数
-
六大基本操作
- Select (选择)
- Project (投影)
- Union (集合并)
- Set difference (集合差)
- Cartesian product (笛卡尔积)
- Rename (重命名)
-
附加操作
- Set intersection (集合交)
- Natural join (自然连接)
- Outer join(外连接)
- Division (除)
- Assignment (赋值)
- 聚合函数
-
聚合函数(Aggregate Functions)
- 聚合操作:
- avg: average value
- min: minimum value
- max: maximum value
- sum: sum of values
- count: number of values
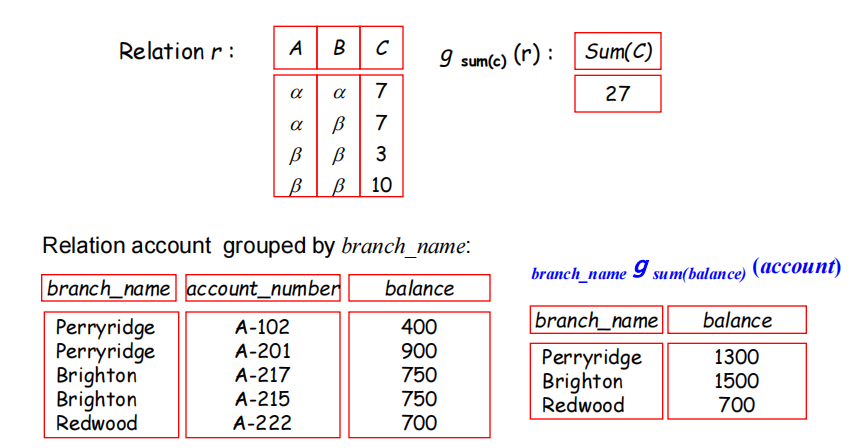
- 聚合操作:
CH3 - SQL介绍
本章实操多,概念没什么。
-
SQL
- DDL
- DML
-
DDL
- 数据库模式、完整性约束等
-
SQL查询
-
select子句、from子句、where子句
-
natural join, join … using (…)
-
-
SQL附加运算
- 更名运算、字符串运算、排序order by
-
集合运算
- union、intersect、except
-
空值
-
聚集函数
-
avg、min、max、sum、count
-
group by、having
-
-
嵌套子查询
-
集合包含:in、not in
-
集合比较:some子句、all子句、exists、unique
-
视图、导出关系、with子句、标量子查询
-
-
数据库的修改
- Deletion、Insertion、Updates
CH4 - 中级SQL
-
连接类型
-
Inner and outer join
-
Left, right and full outer join
-
Natural, using, and on
-
-
视图
-
定义
-
物化视图
-
视图更新
-
-
事务
-
Commit work
-
Rollback work
-
-
完整性约束
-
实体完整性、域约束、唯一约束
-
Check子句
-
参照完整性
-
断言
-
-
数据类型
-
日期与时间类型
-
默认值
-
大对象
-
用户自定义类型
-
-
索引定义
-
授权
- 权限的授予与收回
- 权限:select、insert、update、all privileges
- 角色
- 视图的授权
- 行级授权
CH5 - 高级SQL
- 编程访问SQL
- 函数和过程
- 触发器
- 递归查询
- 高级聚集特性
Part-2 数据库设计
CH6 - 数据库设计与E-R模型
6.1 设计过程概览
- 数据库设计阶段
- S1: Requirement analysis
- S2: Conceptual design (E-R Model)
- S3: Logical implementation
- S4: Physical implementation
6.2 E-R模型
- 三个概念
- 实体集
- 属性
- 联系集
6.3 约束
- 映射基数
- One to one (1对1)
- One to many (1对多)
- Many to one (多对1)
- Many to many (多对多)
- 参与约束
- Total participation
- Partial participation
6.4 E-R图
- 略
6.5 E-R图转换为关系模式
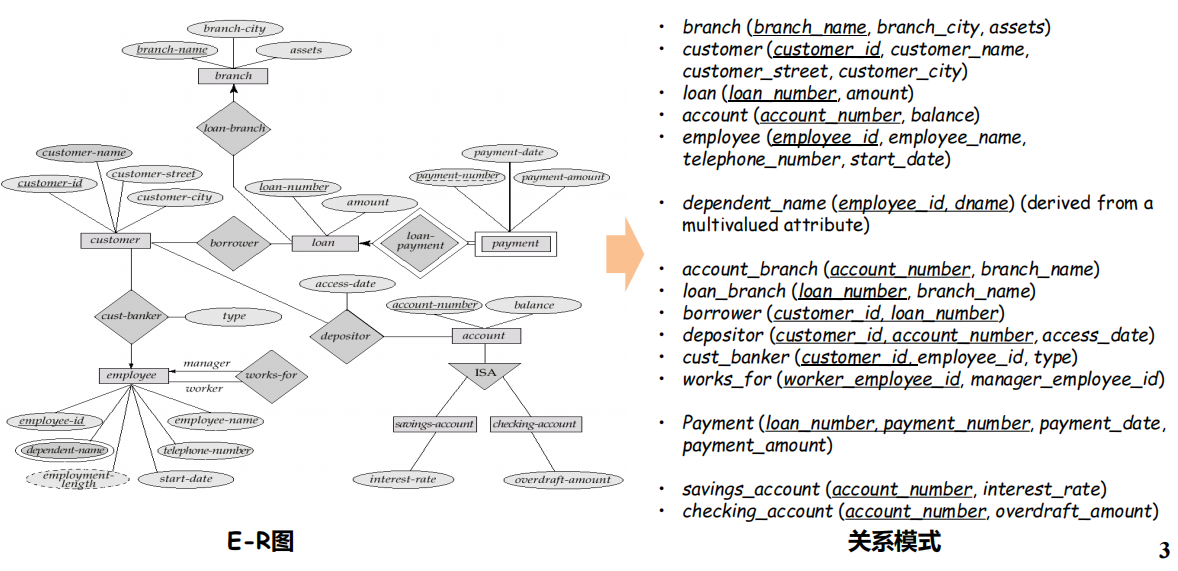
CH7 - 关系数据库设计优化
7.1 良好关系的特征
- 略
7.2 函数依赖
有大题,学会怎么做。
-
函数依赖(Functional Dependency)
-
分解(Decomposition)
-
无损连接分解(Lossy-join Decomposition)
-
函数依赖集的闭包
-
属性集的闭包(Closure of Attribute Set)
-
正则覆盖(Canonical Cover)
-
寻找候选码
-
无损连接分解的检测
-
依赖保持检测
7.3 规范化与范式
-
第一范式 1NF
所有属性的域都是原子的。(不是多值属性)
-
第二范式 2NF
非主属性 对 候选码 没有部分函数依赖。
-
第三范式 3NF
非主属性 对 候选码 没有传递函数依赖。
-
BC范式 BCNF
主属性 对 候选码 没有部分、传递函数依赖。
7.4 多值依赖
- 第四范式 4NF
- 第五范式 5NF
7.5 数据库设计过程
- E-R模型和规范化
- 去规范化(Denormalization)
- 其他设计问题
Part 3 Application Design & Development
没有
Part 4 Big data analytics
没有
Part-5 数据存储与检索
CH12-13 - 物理存储系统 & 数据存储结构
写的思维导图,不用管。
- 物理存储介质概述
- 磁盘
- 闪存
- RAID
- 三级存储
- 存储访问
- 文件组织
- 文件中记录的组织
- 数据字典存储
CH14 - 索引 Indexing
14.1 基本概念
-
索引可提高检索效率,其结构(二叉树、B+树等)占用空间小,访问速度快
-
两种类型
- ordered index (顺序索引)
- hash index (散列索引)
-
索引评价标准
- 数据访问类型
- 数据访问时间
- 数据插入时间
- 数据删除时间
- 存储空间开销
14.2 顺序索引
-
聚集索引
树形结构聚集索引的叶节点可以是数据节点。
索引顺序就是数据物理存储顺序。
一个表最多只能有一个聚集索引。
-
非聚集索引
树形结构非聚集索引的叶节点仍然是索引节点,通过指针指向对应的数据块。
非聚集索引顺序与数据物理排列顺序无关。
-
稠密索引
为文件中的每个搜索键值显示索引记录。
-
稀疏索引
当数据记录按搜索键顺序排序时,仅包含某些搜索键值的索引记录。
-
多级索引
为了减少对索引记录的磁盘访问次数,请将主索引视为一个顺序文件,并在其上构造一个稀疏索引。
-
inner index
稀疏、稠密均可
-
outer index
稀疏
-
-
索引维护
删除、插入
二级索引必须是密集的
当数据文件被修改时,必须更新该文件的索引。更新索引会增加数据库修改的开销。
使用主索引的顺序扫描效率很高,但使用辅助索引的顺序扫描成本很高。每个记录访问可能从磁盘获取一个新的块。
14.3 B+树和B树索引
略,请去看实操方法,看这里的知识点,屁用没有。
14.4 散列索引
-
静态散列(Static Hashing)
- 散列文件组织
- 散列函数
- 溢出桶的处理
-
动态散列(Dynamic Hashing)
- 可扩展散列结构
-
对比 顺序索引
-
插入和删除的频率
-
是否以牺牲最坏情况访问时间为代价,优化平均访问时间
-
预期的查询类型
- 散列通常更适合检索具有指定键值的记录
- 如果范围查询是常见的,则选顺序索引
-
14.5 多码访问
- 多属性索引
- 网格文件(Grid Files)
- 位图索引(Bitmap Indices)
14.6 索引创建
屁用没有
Part-6 查询处理与优化
CH15 - 查询处理 Query processing
15.1 概述
- 查询处理的基本步骤
- 语法分析与翻译/Parsing and translation
- 优化/Optimization
- 执行/Execution
后面部分不用知道,不会考
可以看一下归并排序。
CH16 - 查询优化 Query optimization
16.1 概述
-
Cost-based Optimization,基于代价的优化
-
步骤1:产生逻辑上与给定表达式等价的表达式
- 使用等价规则
-
步骤2:对所产生的表达式以不同方式标注,产生不同的查询执行计划
-
步骤3:估计每个执行计划的代价,选择估计代价最小的执行计划
-
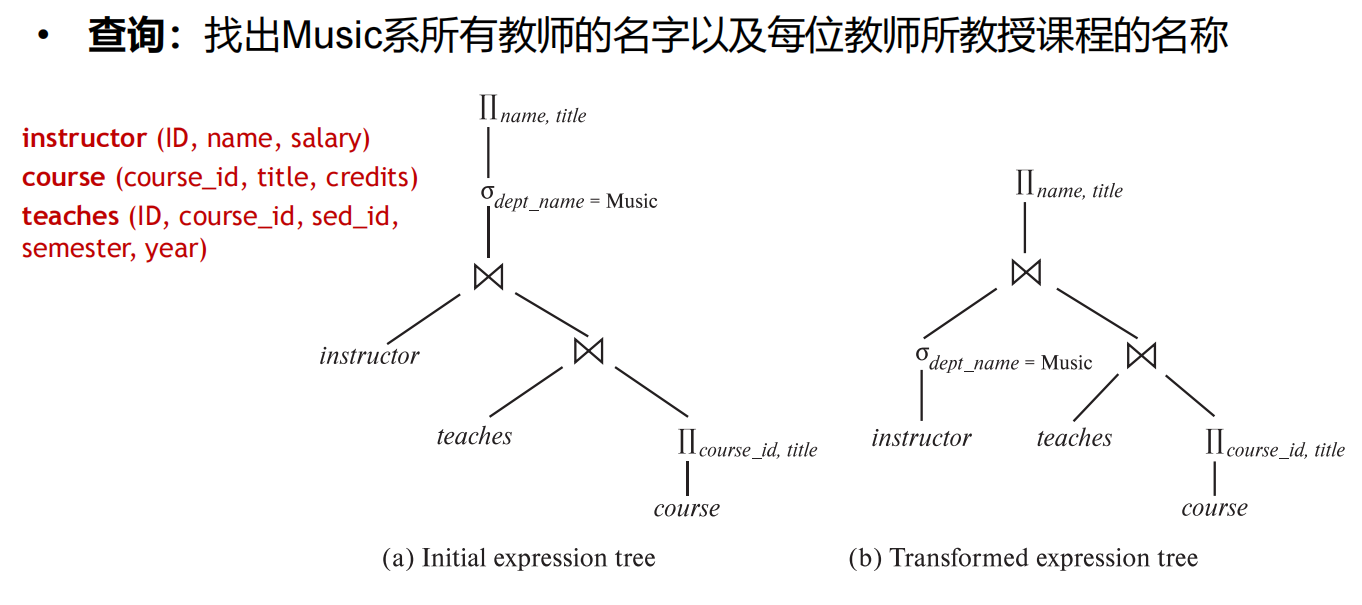
16.2 关系表达式的转换
-
等价规则

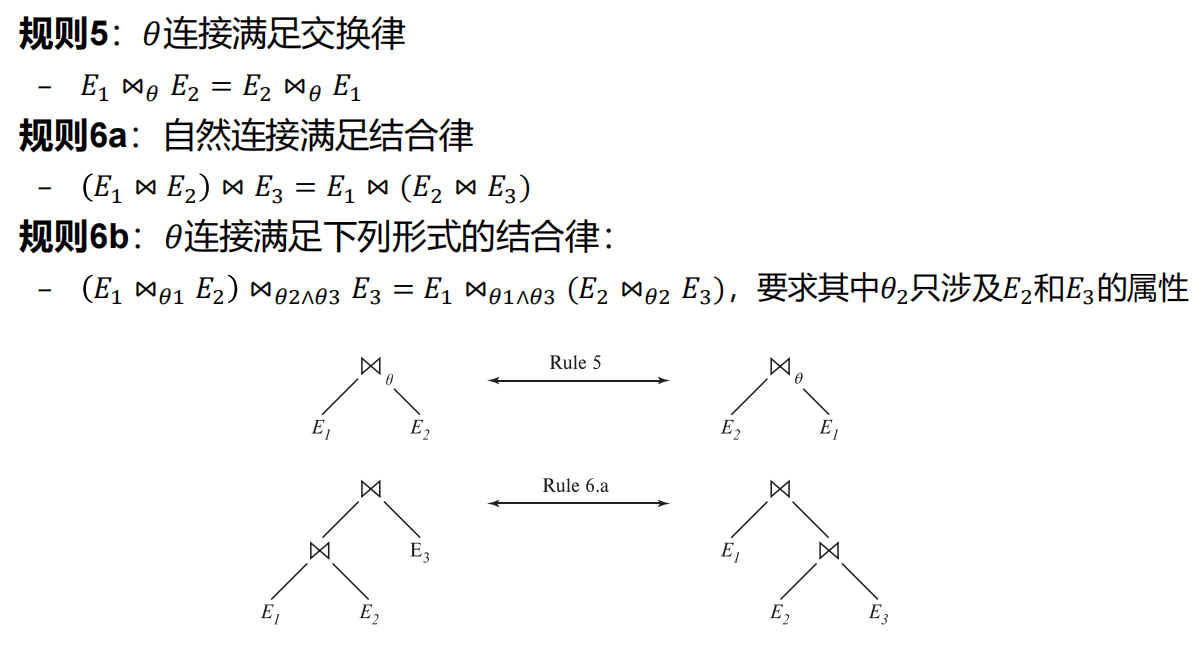
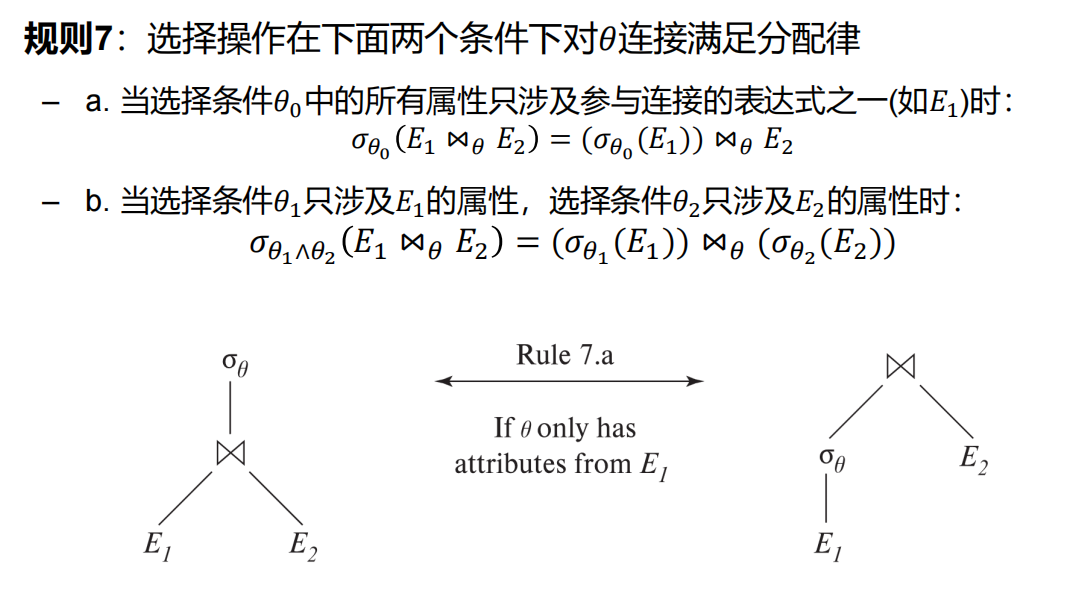


16.3 表达式执行代价估计
各种操作的代价大小估计,不用管
16.4 执行计划选择
-
枚举等价表达式
-
执行计划
-
执行计划的选择
-
基于代价的优化
-
动态规划优化
-
连接顺序优化算法
-
左深连接树
-
成本优化
-
启发式优化
-
将连接选择分解为一系列单个选择操作(等价规则1)。
-
将选择操作沿查询树下移,以便尽早执行(Equiv. rules 2,7a, 7b, 11)
-
首先执行那些产生最小关系的选择和连接操作(Equiv. rule 6)
-
用连接操作替换后面跟着选择条件的笛卡尔积操作(Equiv. rule 4a)
-
解构并尽可能地向下移动投影属性列表,在需要的地方创建新的投影(规则3、8)
-
Part-7 事务管理
CH17 - 事务 Transactions
17.1 事务的概念
-
事务是由多个操作组成的程序执行单元。
-
在事务执行过程中,可能出现数据库不一致的情况。
-
事务提交后,数据库必须保持一致。
-
-
两个主要问题
-
并发执行多个事务 -> 并发控制(Ch18)
-
从硬件故障和系统崩溃中恢复 -> 恢复(Ch19)
-
-
事务的ACID特性
- Atomicity(原子性)
- Consistency(一致性)
- Isolation(隔离性)
- Durability(持久性)
-
事务的状态
- Active(活跃)
- Partially committed(部分提交)
- Failed(失败)
- Aborted(中止)
- Committed(提交)
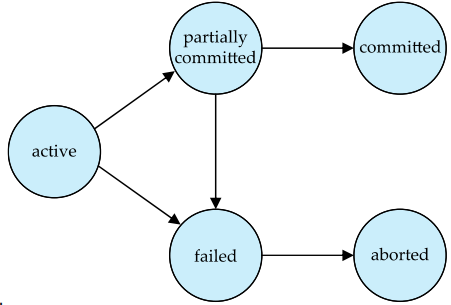
17.2 事务的调度
- 调度(Schedule)
- 调度类型
- serial schedule 串行化的调度
- Non-serial schedule 非串行化的调度
17.3 可串行化调度
-
可串行化
- Conflict serializability(冲突可串行性)
- View serializability(视图可串行性)
注:只关注 read、write 操作
-
冲突可串行化(Conflict Serializability)
- 𝐼𝑖 = read(Q), 𝐼𝑗 = read(Q). (no conflict)
- 𝐼𝑖 = read(Q), 𝐼𝑗 = write(Q). (conflict)
- 𝐼𝑖 = write(Q), 𝐼𝑗 = read(Q). (conflict)
- 𝐼𝑖 = write(Q), 𝐼𝑗 = write(Q). (conflict)
直观地说,𝐼𝑖和𝐼𝑗之间的冲突迫使它们之间有一个(逻辑的)时间顺序
-
Conflict equivalent (冲突等价)
-
视图可串行化(View Serializability)
17.4 可恢复调度
-
不可恢复调度
一个事务 读取一个先前由一个事务 写入的数据项, 的提交操作出现在 的提交操作之前。
T8 T9 read(A) write(A) read(A) commit read(B) -
Cascading rollback(级联回滚)
-
Cascadeless schedules (无级联回滚调度)
-
事务结束标志
- commit
- rollback
-
SQL-92指定的隔离级别 Levels of isolation
- Serializable – default:保证可串行化调度
- Repeatable read:只允许读取已提交数据,两次读取之间数据不能更新
- Read committed:只允许读取已提交数据,不要求可重复读
- Read uncommitted:允许读取未提交数据
17.5 可串行性检测
-
Precedence graph(优先图)
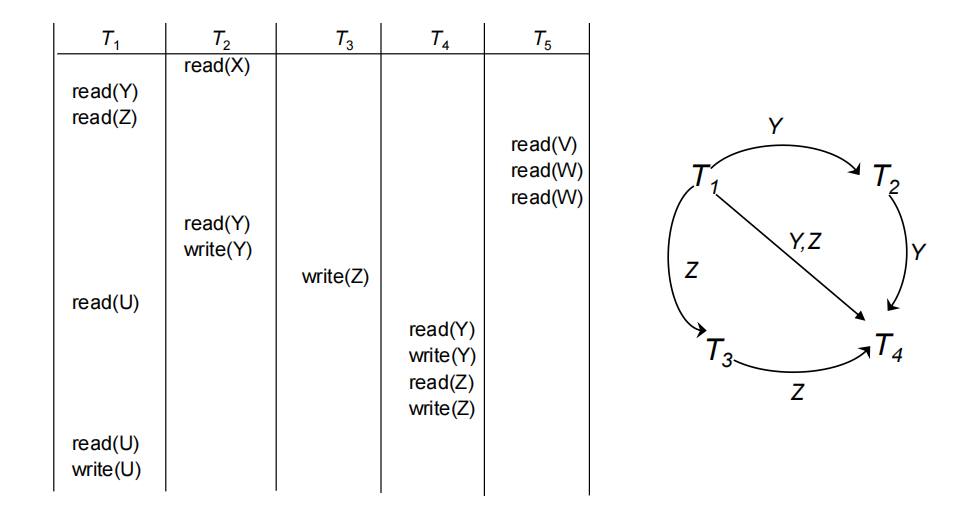
-
检测方法
当且仅当调度的优先级图不存在环时,则调度是可串行化的。
CH18 - 并发控制 Concurrency control
18.1 并发控制中的问题
-
并发事务引起的问题
-
Lost Update (丢失修改 )
- 事务T1和T2读取相同的数据项A并修改它。
- T2的提交结果消除了T1的更新。
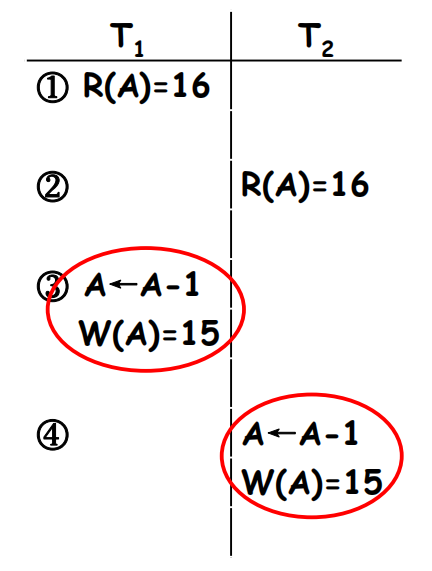
-
Non-repeatable Read (不可重复读 )
- T1读取B=100。
- T2读取B,然后更新B=200,并写回B。
- T1再次读取B, B=200,与第一次读取不同。
- 幻影现象(幻影现象)。同一查询的记录消失或新记录出现。
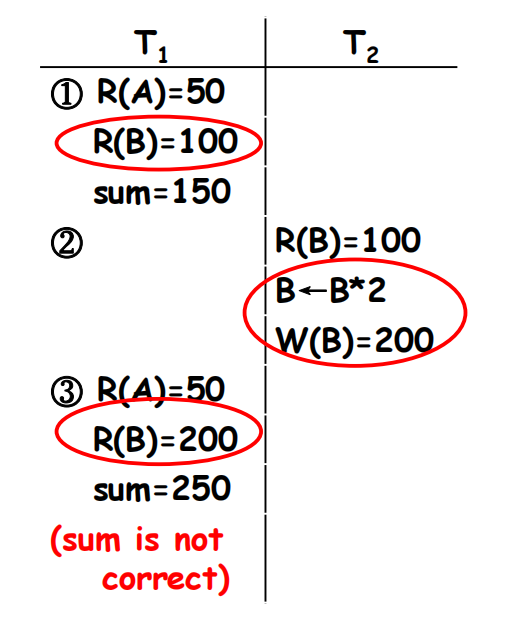
-
Dirty Read (脏读 )
- T1修改C为200,T2读取C是200。
- T1由于某种原因回滚,它的修改也回滚。C恢复到100。
- T2读取C为200,这与数据库不一致。
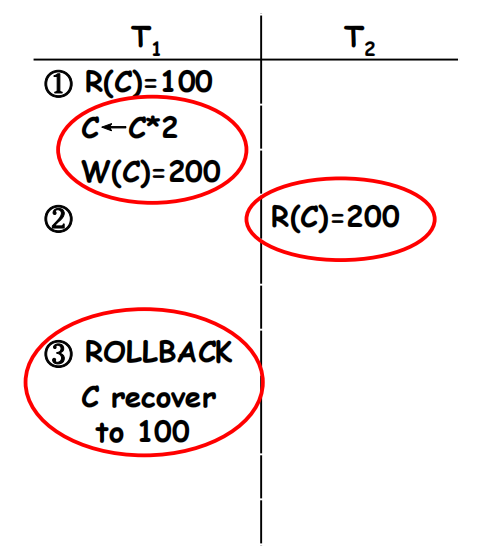
-
18.2 基于锁的协议
-
Lock-based protocols
一种控制并发访问数据项的机制。
-
数据项可以以两种模式锁定:
- exclusive (X) mode (排他锁)
- shared (S) mode (共享锁)
-
锁请求(并发控制管理器)
只有锁请求被批准后,事务才能继续进行。
-
解决问题:
- 丢失修改
- 不可重复读
- 脏读
均已解决。
-
-
两阶段锁协议(Two-Phase Locking Protocol)
一种确保可冲突序列化调度的协议
-
第一阶段:成长阶段(增长阶段)
事务可以获取锁,但不能释放锁
-
第二阶段:收缩阶段(缩减阶段)
事务可以释放锁,但不能获取锁
该协议保证了可串行化。
-
分类
-
Strict two-phase locking(严格两阶段封锁)
事务在提交之前必须持有所有的排他锁。可以实现级联回滚。
-
Rigorous two-phase locking (强两阶段封锁)
所有的锁被持有直到事务提交。
-
-
-
锁转换(Lock Conversions)
-
Upgrade (升级)
lock-S -> lock-X
-
Downgrade (降级)
lock-X -> lock-S
-
-
锁的自动获取
-
锁的实现
Lock manager (锁管理器)
-
锁表(Lock Table)
-
死锁(Deadlock)
如果存在一组事务,其中的每个事务都在等待另一个事务,那么系统就会发生死锁。
-
要处理死锁,必须中止或回滚某些事务并释放其锁
-
大多数锁协议都存在死锁
-
两阶段锁(严格、强)都不能避免死锁
-
-
饥饿(Starvation)
一个事务可能正在等待一个数据项的X锁,而其他一系列事务请求并被授予相同数据项的S锁。由于死锁,同一个事务被反复回滚,一直得不到资源,这种现象就叫饥饿。
- 并发控制管理器可以设计为防止饥饿
18.3 基于图的协议
-
Graph-based protocols
基于图的协议是两阶段锁定的替代方案。
-
树协议(Tree Protocol)
树协议是一种简单的图协议。
-
在树协议中只允许使用排他锁。
-
流程
- 事务 的第一个锁可以在任何数据项上。
- 随后,只有当数据 的父节点当前被 锁住时,数据 才能被 锁住。
- 数据项可以随时解锁。
- 已解锁的数据项不能通过 重新锁定。
-
-
优点
- 树协议确保冲突可串行化以及免于死锁。
- 解锁可能比两阶段锁定协议更早发生,因此等待时间更短,并发性更高。
-
缺点
- 事务的中止仍然会导致级联回滚。
- 可能必须锁定它不访问的数据项,从而增加锁定开销,并产生额外的等待时间。
18.4 基于时间戳的协议
-
事务的时间戳
每个事务在进入系统时都有一个时间戳。
-
Timestamp-based protocol
为了确保可串行化,协议为每个数据维护两个时间戳值。
-
W-timestamp(Q)
成功执行write(Q)的所有事务的最大时间戳
-
R-timestamp(Q)
成功执行read(Q)的所有事务的最大时间戳
基于时间戳的协议确保任何冲突的读写操作都按照时间戳顺序执行。
-
-
时间戳协议确保没有死锁,因为没有事务等待。
18.5 死锁处理
-
死锁
如果存在一组事务,其中的每个事务都在等待另一个事务,那么系统就会发生死锁。
-
Deadlock prevention protocols 死锁防止协议
确保系统永远不会进入死锁状态。
-
要求每个事务在开始执行之前锁定其所有数据项(预声明)
-
强制所有数据项的部分排序,并要求事务只能按照部分排序指定的顺序锁定数据项(基于图的协议)
-
-
死锁预防
- 基于图的协议
- 基于时间戳的协议
-
其中的协调控制:
-
wait-die scheme — non-preemptive(非抢占)
旧事务让出给新事务。
可能导致事务死亡。
-
wound-wait scheme — preemptive(抢占)
新事务让出给旧事务。
回滚的概率更低。
回滚的事务使用其原始时间戳重新启动。
旧事务因此优先于新事务,从而避免了饥饿。
-
-
Timeout-based schemes (基于超时的机制)
- 事务在指定的时间内等待锁。在此之后,事务被回滚,因此不可能出现死锁。
- 执行起来很简单,但是可能会饿死。也很难确定好值的超时间隔。
-
死锁检测
画 wait-for graph(等待图) 。查看是否存在环。
- 必须定期调用死锁检测算法来查找周期。
-
死锁恢复
- 某些事务需要回滚。
- 确定回滚事务的程度。
- Total rollback:中止事务,然后重新启动
- Partial rollback:只要需要回滚到打破死锁即可。
-
如果总是选择相同的事务作为被回滚事务,就会发生饥饿。
因此,可以在成本因素中包括回滚的次数,以避免饥饿。
18.6 多粒度
-
允许数据项具有各种大小,并定义数据粒度的层次结构。
-
粒度的控制
-
细粒度(树中较低)
高并发性,高锁定开销
-
粗粒度(在树中较高)
低并发性,低锁定开销
-
-
意向锁(Intention Lock)
- intention-shared (IS): 意向共享模式锁
- intention-exclusive (IX): 意向排他模式锁
- shared intention-exclusive (SIX): 共享意向排他锁
意图锁允许以S或X模式锁定更高级别的节点,而不必检查所有的子节点。
-
锁相容性矩阵
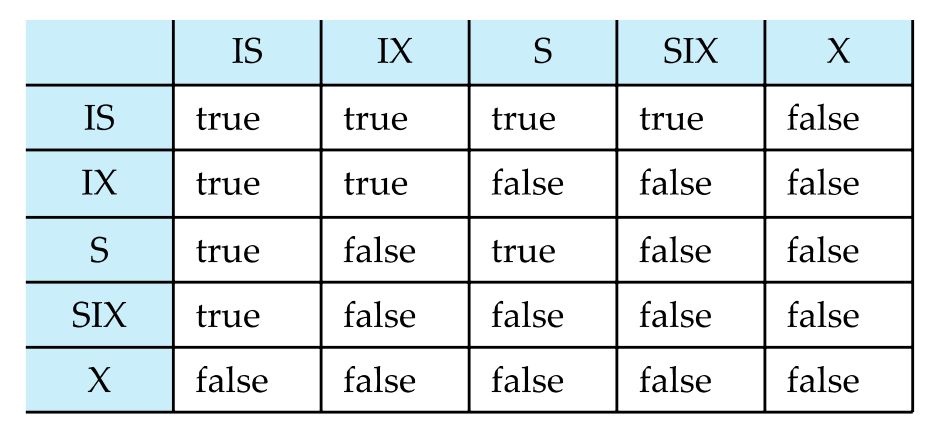
CH19 - 恢复系统 Recovery System
19.1 故障分类
-
故障分类
- Transaction failure (事务故障)
- Logical errors, e.g., illegal inputs 非法输入
- System errors, e.g., dead locks 死锁
- System crash (系统崩溃)
- 电源故障
- 其他硬件和软件故障
- Disk failure (磁盘故障)
- 磁头故障
- Transaction failure (事务故障)
-
恢复算法
保证有足够的信息用于故障恢复。
恢复数据库到某个一致性状态。
19.2 存储器
-
存储器分类
- Volatile storage (易失性存储器)
- Non-volatile storage (非易失性存储器)
- Stable storage (稳定存储器)
-
数据访问
- Physical blocks (物理块)
- Buffer blocks (缓冲块)
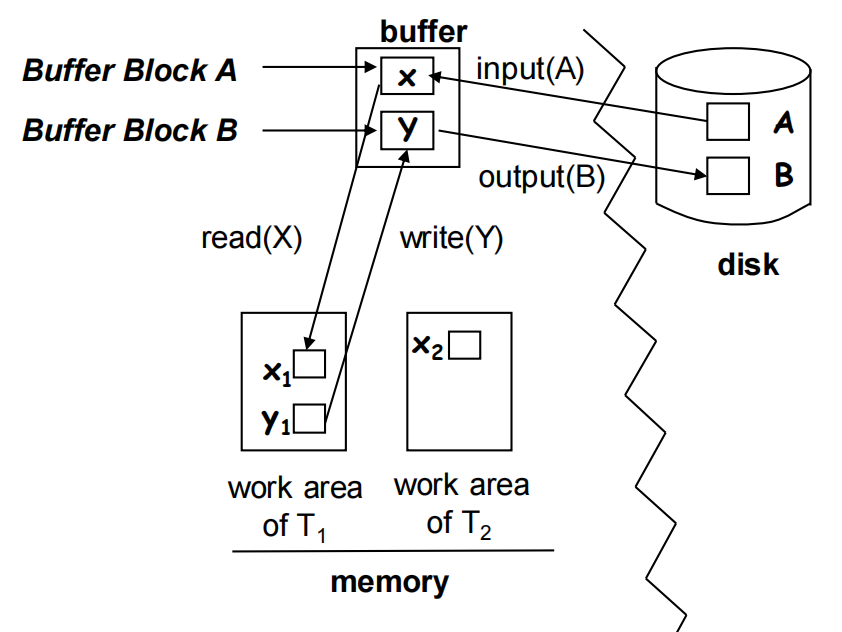
19.3 恢复与原子性
-
两种策略
- Log-based recovery (基于日志的恢复)
- Shadow-paging (影子页)
-
基于日志的恢复
日志保存在稳定的存储中。
使用 log 的两种强度:
- Deferred database modification (延迟数据库修改)
- Immediate database modification (即刻数据库修改)
-
延迟数据库修改
-
将所有修改记录到日志中,但将所有写操作推迟到部分提交之后。
- 事务开始:记录在日志里
- 事务写入操作:记录 在日志里,但此时不在X上执行写操作,而是被延迟了。
- 当部分提交时, 被写入日志,并读取日志记录开始执行先前延迟的写操作。
-
Recovery after a crash 恢复
- 如果日志中同时存在 和,则需要重新执行事务。
- 使用 redo 将事务更新的所有数据项的值设置为新值
例子: T0 在 T1 之前执行,初始化:A=1000, B=2000, C=700

发生故障时的三种可能状态如下:

- A:不需要redo
- B:T0需要redo
- C:T0、T1均需要redo
-
-
即刻数据库修改
允许未提交事务的数据库更新。
恢复过程有两个操作:
- undo:撤销恢复旧值
- redo:重做恢复新值
- 要求:
- 已经 start 但未 commit 的需要undo 。
- 已经 start 且 commit 的需要redo。
- 先执行 undo ,再执行 redo。
例子:
状态记录log如下:

- A:undo(T0)
- B:undo(T1)、redo(T0)
- C:redo(T0)、redo(T1)
-
检查点(Checkpoint)
-
恢复过程中的问题
- 搜索整个日志非常耗时
- 可能不必要地重做已经向数据库输出更新的事务
-
设置检查点
-
将当前主存中的所有日志记录输出到稳定的存储中
-
将修改后的所有缓冲块输出到磁盘
-
将日志记录写入稳定存储
-
-
恢复时
- 从日志的末尾开始扫描以查找最近的<检查点>记录
- 倒着继续扫描,直到找到记录。(我们假设所有的事务都是连续执行的)
- 只需要考虑这个 start 与故障之间的记录即可。
- 没有commit的,执行undo
- 已经commit的,执行redo
示例:
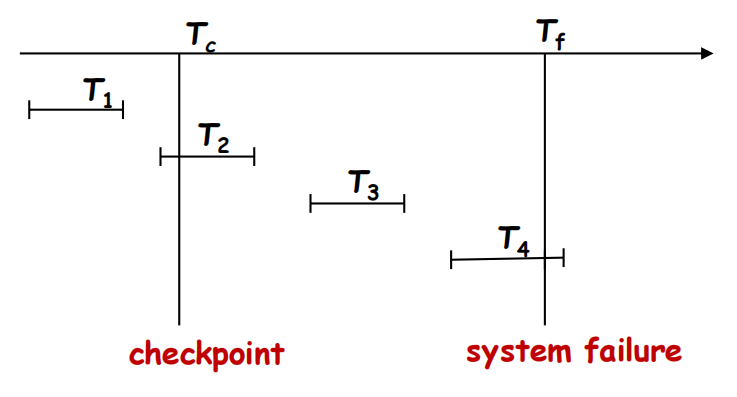
- T1忽略
- undo T4
- redo T2和T3
-
19.4 恢复算法
-
并发事务的恢复
做法和前面一样。
-
但是checkpoint要写成
其中, 是检查点被设置时,处于活动状态的事务列表(已start但未commit的)。
-
19.5 缓冲区管理
不知所云。。。
*QUIZ
CH7 函数依赖与范式

CH14 B+树索引

CH15 归并排序

CH16 查询优化
 微信支付
微信支付 支付宝
支付宝