DeepWalk 图嵌入:维基百科词条
1. 环境参考
参考资料
https://github.com/prateekjoshi565/DeepWalk
安装工具包
1 !pip install networkx gensim pandas numpy tqdm scikit-learn matplotlib
导入工具包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import networkx as nximport pandas as pdimport numpy as npimport randomfrom tqdm import tqdmimport matplotlib.pyplot as plt%matplotlib inline
2. 数据
获取数据
爬虫网站:https://densitydesign.github.io/strumentalia-seealsology/
设置 distance
输入链接:
https://en.wikipedia.org/wiki/Computer_vision
https://en.wikipedia.org/wiki/Deep_learning
https://en.wikipedia.org/wiki/Convoutional_neural_network
https://en.wikipedia.org/wiki/Decision_tree
https://en.wikipedia.org/wiki/Support_vector_machine
点击 START CRAWLING, 爬取完成点击 STOP
Download 下载为 TSV 文件(以\t分割的 CSV 文件)。
1 df = pd.read_csv("seealsology-data.tsv" , sep='\t' )
source
target
depth
0
support vector machine
in situ adaptive tabulation
1
1
support vector machine
kernel machines
1
2
support vector machine
fisher kernel
1
3
support vector machine
platt scaling
1
4
support vector machine
polynomial kernel
1
(4232, 3)
构建无向图
1 G = nx.from_pandas_edgelist(df, 'source' , 'target' , edge_attr=True , create_using=nx.Graph())
3059
可视化
1 2 3 plt.figure(figsize=(15 , 14 )) nx.draw(G) plt.show()
3. 随机游走
randomwalk 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def get_randomwalk (node, path_length ): ''' 输入起始节点和路径长度,生成随机游走节点序列 ''' random_walk = [node] for i in range (path_length-1 ): temp = list (G.neighbors(node)) temp = list (set (temp) - set (random_walk)) if len (temp) == 0 : break random_node = random.choice(temp) random_walk.append(random_node) node = random_node return random_walk
1 all_nodes = list (G.nodes())
1 get_randomwalk('computer vision' , 5 )
['computer vision',
'machine vision glossary',
'glossary of artificial intelligence',
'artificial intelligence',
'organoid intelligence']
生成随机游走序列
1 2 gamma = 10 walk_length = 5
1 2 3 4 5 6 7 random_walks = [] for nd in tqdm(all_nodes): for i in range (gamma): rdwk = get_randomwalk(nd, walk_length) random_walks.append(rdwk)
100%|████████████████████████████████████████████████████████████████████████████| 3059/3059 [00:00<00:00, 30093.95it/s]
30590
['support vector machine', 'relevance vector machine', 'kernel trick']
4. 模型
训练 Word2Vec 模型
1 2 from gensim.models import Word2Vec
1 2 3 4 5 6 7 8 model = Word2Vec(vector_size=256 , window=4 , sg=1 , negative=10 , alpha=0.03 , min_alpha=0.0007 , seed=14 )
1 2 model.build_vocab(random_walks, progress_per=2 )
1 2 model.train(random_walks, total_examples=model.corpus_count, epochs=50 , report_delay=1 )
(5623725, 5679950)
分析 Word2Vec 结果
1 2 model.wv.get_vector('computer vision' ).shape
(256,)
1 model.wv.get_vector('computer vision' )
array([-0.95459837, 0.10292508, -0.28316122, 0.34142157, -0.00524048,
0.09371996, -0.1954719 , -0.25347382, 0.51394266, 0.36131492,
0.49506772, 0.1907984 , -0.6219965 , -0.5140934 , -0.01667919,
-0.62039286, -0.05152594, 0.11786714, 0.18947525, 0.19846195,
-0.11716247, 0.4700267 , 0.07052463, -0.17666382, 0.1671837 ,
0.24031273, -0.18862735, -0.15001939, -0.15928511, -0.13938765,
-0.05735731, -0.17796549, -0.20125604, -0.13714062, 0.02854507,
-0.3297002 , 0.21914023, -0.03728085, -0.42431426, 0.28924662,
-0.07030115, 0.153452 , 0.02109604, -0.5424473 , -0.5128256 ,
0.09319318, -0.18759303, -0.20778346, 0.01962802, 0.2059087 ,
0.49449265, -0.43316683, 0.47074154, 0.32398415, 0.18804422,
0.30941215, -0.16319014, 0.5086255 , -0.4054713 , 0.18189834,
-0.0757796 , 0.01394054, 0.29209548, -0.20624508, 0.04370715,
-0.22285934, -0.1998267 , -0.07965406, -0.56047654, 0.39915815,
-0.14301345, 0.03823084, -0.51063114, -0.06177189, -0.12064032,
0.41043568, 0.61430806, 0.00198809, -0.44348234, -0.4718856 ,
0.17651486, 0.03726299, -0.16133447, -0.07498072, 0.27820274,
0.4717679 , -0.09105907, 0.23809573, 0.05806234, 0.1386895 ,
-0.00990544, -0.07417107, -0.13418426, 0.23991434, 0.229925 ,
0.8267156 , 0.1580667 , 0.36089334, 0.09349226, 0.33000064,
0.191074 , 0.07245437, -0.19699697, 0.1373127 , 0.00637828,
-0.393098 , 0.08118346, -0.33764714, 0.18177702, 0.6325778 ,
-0.2885028 , -0.6606645 , 0.25406113, -0.07453088, 0.0134876 ,
0.22993505, 0.2469321 , -0.31469256, 0.15289971, -0.2890252 ,
-0.24749073, -0.60842824, -1.0122712 , 0.12880209, -0.14758833,
0.05826454, -0.28706843, 0.14353754, -0.22783504, -0.18525298,
-0.48144853, 0.03936397, -0.7163454 , 0.2678299 , -0.03936832,
0.23881389, 0.47060257, -0.66273224, -0.10196779, 0.5657661 ,
-0.21970046, -0.11473361, 0.01603065, -0.17330663, -0.07658403,
-0.00363667, 0.30719343, 0.05218068, -0.0915609 , 0.18364 ,
-0.05932966, -0.12060771, 0.29323366, -0.68775976, 0.4539725 ,
0.3334422 , -0.45317262, 0.3847841 , -0.15240075, 0.11145896,
-0.5170747 , 0.28762746, 0.33697945, 0.0671319 , 0.41540784,
0.530296 , 0.7281354 , 0.3821813 , 0.05093963, 0.7988582 ,
-0.38773486, -0.21942078, -0.03484021, 0.3349887 , -0.19996904,
0.37933737, -0.26954234, 0.4171879 , 0.77916664, -0.1828221 ,
-0.19539501, -0.4173407 , 0.72097695, -0.03344366, 0.07354128,
0.17265108, -0.4285512 , -0.41779858, 0.31622657, 0.23919132,
-0.14859721, -0.112137 , -0.62065303, 0.02263851, 0.03000049,
-0.31004304, 0.16809928, 0.27590737, 0.30516142, -0.2884869 ,
-0.52874154, -0.0075765 , -0.22995523, -0.5217325 , 0.61138886,
0.26653954, 0.11882886, 0.8872766 , 0.32643762, -0.16740482,
0.03697263, -0.26058164, -0.5465761 , -0.19003482, -0.14713594,
0.29176036, -0.15662532, -0.3437838 , -0.6559339 , 0.29693472,
0.01657276, 0.10343892, -0.01626491, -0.03184415, -0.15561788,
-0.39298484, -0.10999571, -0.29130518, 0.49602684, 0.1284142 ,
0.1823952 , -0.299319 , -0.35532302, -0.31292355, 0.5582348 ,
0.19172785, -0.29422763, 0.32814986, -0.17529616, -0.3650768 ,
-0.3434801 , -0.13502142, 0.19740753, -0.15909001, -0.26023048,
0.22111997, 0.45001796, 0.14510933, 0.40188378, 0.23440124,
0.02278174, -0.28787047, -0.13803658, 0.12221967, -0.00340613,
0.03851813], dtype=float32)
1 2 model.wv.similar_by_word('computer vision' )
[('computational imaging', 0.7198930978775024),
('teknomo–fernandez algorithm', 0.6524918079376221),
('vectorization (image tracing)', 0.6257413625717163),
('h-maxima transform', 0.6218506097793579),
('egocentric vision', 0.6183371543884277),
('multispectral imaging', 0.6168951988220215),
('sound recognition', 0.6164405345916748),
('ridge detection', 0.6114603281021118),
('google goggles', 0.6109517216682434),
('medical intelligence and language engineering lab', 0.6081306338310242)]
5. PCA 降维可视化
全部词条
1 2 3 4 5 from sklearn.decomposition import PCApca = PCA(n_components=2 ) embed_2d = pca.fit_transform(X)
(3059, 2)
1 2 3 plt.figure(figsize=(14 ,14 )) plt.scatter(embed_2d[:, 0 ], embed_2d[:, 1 ]) plt.show()
某个词条
1 2 3 4 term = 'computer vision' term_256d = model.wv[term].reshape(1 , -1 ) term_256d.shape
(1, 256)
1 term_2d = pca.transform(term_256d)
array([[-0.6757479, 0.6024744]], dtype=float32)
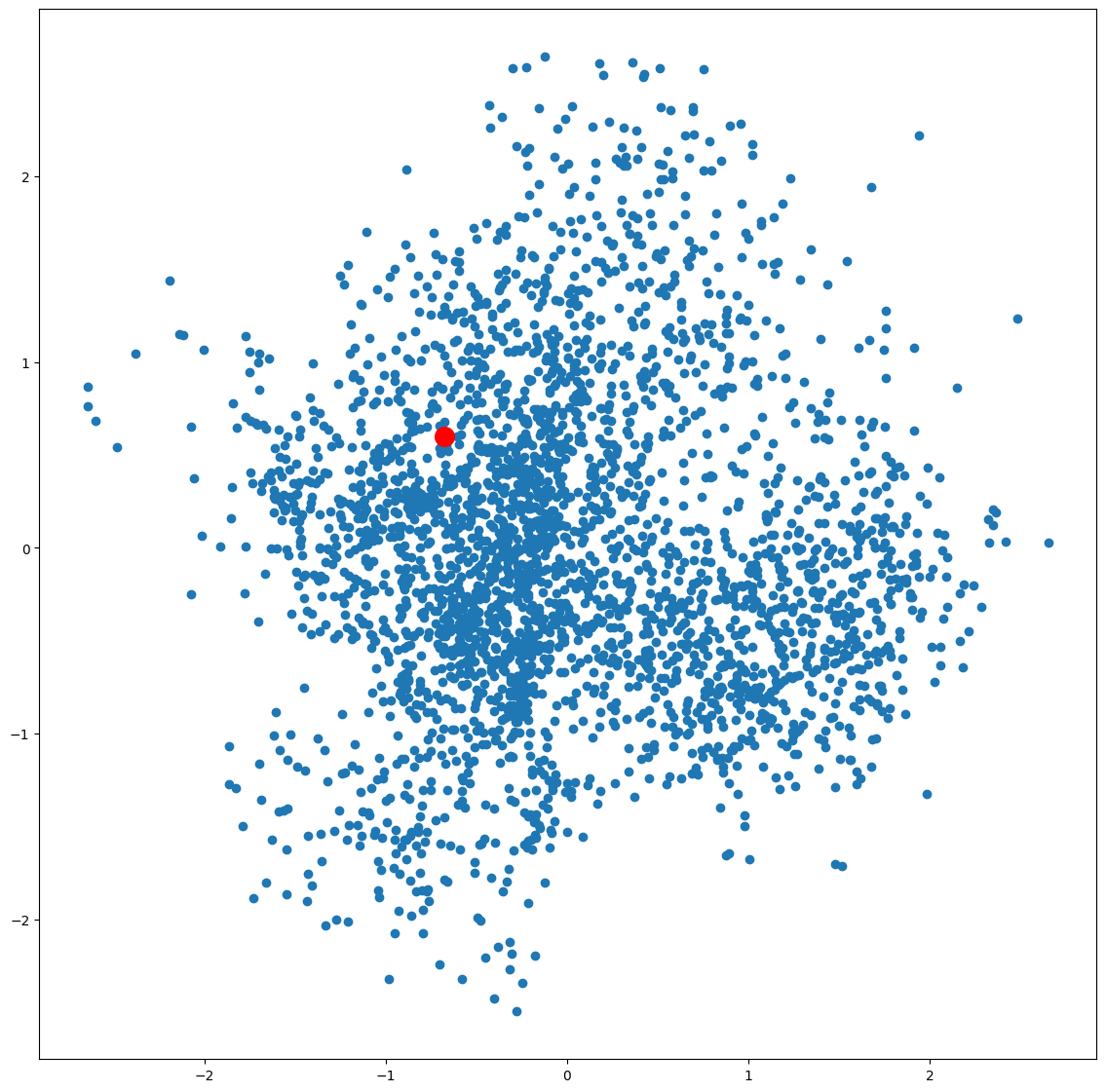
1 2 3 4 plt.figure(figsize=(14 ,14 )) plt.scatter(embed_2d[:, 0 ], embed_2d[:, 1 ]) plt.scatter(term_2d[:, 0 ], term_2d[:, 1 ], c='r' , s=200 ) plt.show()
某些词条
1 2 3 4 5 pagerank = nx.pagerank(G) node_importance = sorted (pagerank.items(), key=lambda x: x[1 ], reverse=True )
1 2 3 4 5 6 n = 30 terms_chosen = [] for nd in node_importance[:n]: terms_chosen.append(nd[0 ])
1 2 terms_chosen.extend(['computer vision' , 'deep learning' ])
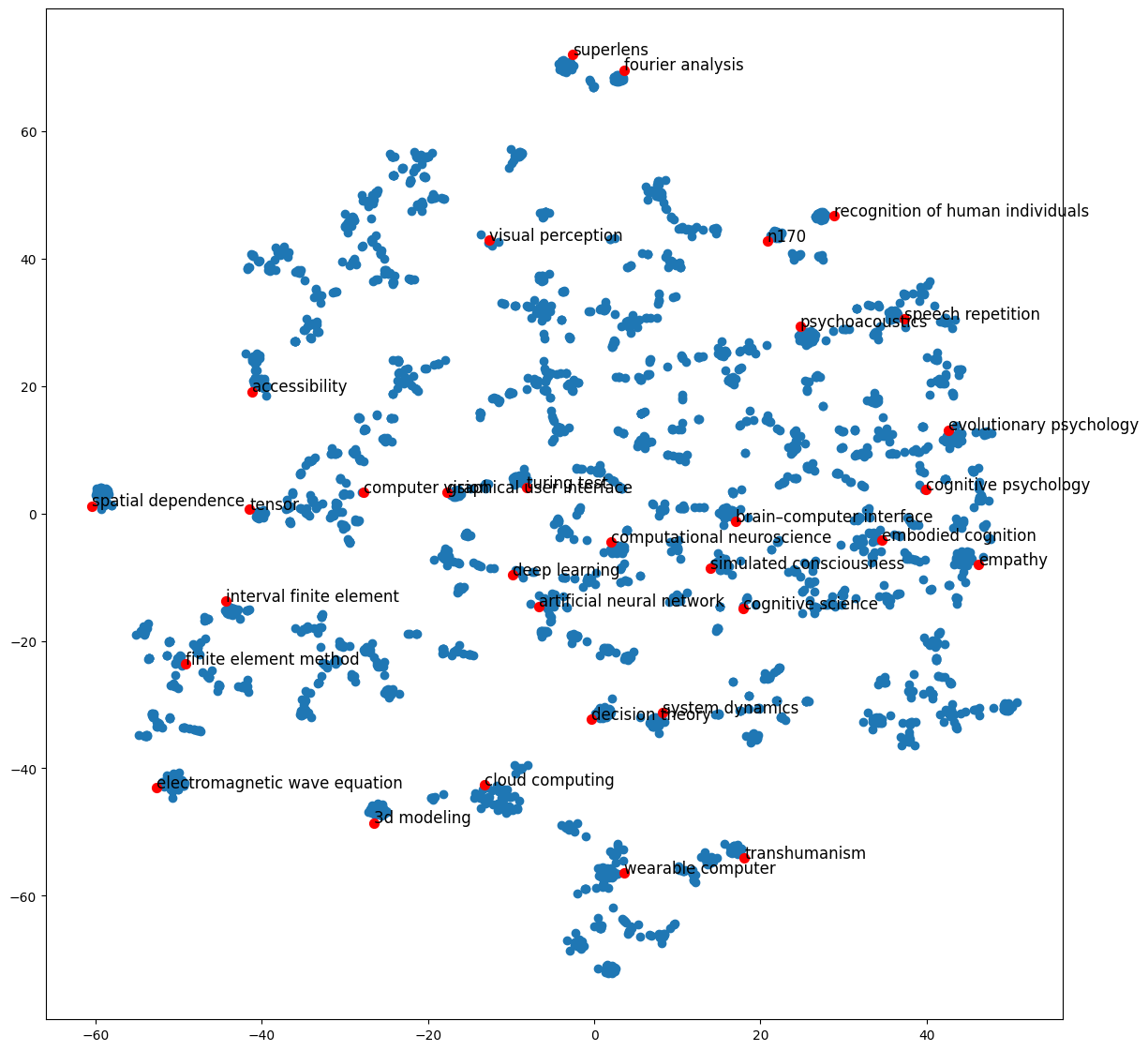
['cloud computing',
'electromagnetic wave equation',
'spatial dependence',
'3d modeling',
'empathy',
'psychoacoustics',
'evolutionary psychology',
'superlens',
'wearable computer',
'cognitive science',
'decision theory',
'system dynamics',
'accessibility',
'brain–computer interface',
'simulated consciousness',
'visual perception',
'artificial neural network',
'turing test',
'cognitive psychology',
'recognition of human individuals',
'transhumanism',
'speech repetition',
'embodied cognition',
'finite element method',
'computational neuroscience',
'fourier analysis',
'interval finite element',
'n170',
'graphical user interface',
'tensor',
'computer vision',
'deep learning']
1 2 3 4 term2index = model.wv.key_to_index index2term = model.wv.index_to_key
1 term_index = np.array(term2index.values())
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize=(14 ,14 )) plt.scatter(embed_2d[:, 0 ], embed_2d[:, 1 ]) for item in terms_chosen: idx = term2index[item] plt.scatter(embed_2d[idx, 0 ], embed_2d[idx, 1 ], c='r' , s=50 ) plt.annotate(item, xy=(embed_2d[idx, 0 ], embed_2d[idx, 1 ]), c='k' , fontsize=12 ) plt.show()
6. TSNE 降维可视化
全部词条
1 2 3 4 from sklearn.manifold import TSNEtsne = TSNE(n_components=2 , n_iter=1000 ) embed_2d = tsne.fit_transform(X)
/opt/anaconda3/envs/graph/lib/python3.11/site-packages/sklearn/manifold/_t_sne.py:1162: FutureWarning: 'n_iter' was renamed to 'max_iter' in version 1.5 and will be removed in 1.7.
warnings.warn(
1 2 3 plt.figure(figsize=(14 ,14 )) plt.scatter(embed_2d[:,0 ], embed_2d[:,1 ]) plt.show()
某些词条
1 2 3 4 5 6 7 8 9 10 plt.figure(figsize=(14 ,14 )) plt.scatter(embed_2d[:, 0 ], embed_2d[:, 1 ]) for item in terms_chosen: idx = term2index[item] plt.scatter(embed_2d[idx, 0 ], embed_2d[idx, 1 ], c='r' , s=50 ) plt.annotate(item, xy=(embed_2d[idx, 0 ], embed_2d[idx, 1 ]), c='k' , fontsize=12 ) plt.show()
(3059, 2)
导出
1 2 3 4 5 terms_chosen_mask = np.zeros(X.shape[0 ]) for item in terms_chosen: idx = term2index[item] terms_chosen_mask[idx] = 1
1 2 3 4 5 6 df = pd.DataFrame() df['X' ] = embed_2d[:, 0 ] df['Y' ] = embed_2d[:, 1 ] df['item' ] = model.wv.index_to_key df['pagerank' ] = pagerank.values() df['chosen' ] = terms_chosen_mask
X
Y
item
pagerank
chosen
0
-13.242397
-42.560059
cloud computing
0.001352
1.0
1
42.664997
13.116780
evolutionary psychology
0.000699
1.0
2
-12.628043
42.939220
visual perception
0.000623
1.0
3
17.878042
-14.927996
cognitive science
0.000292
1.0
4
39.976368
3.763149
cognitive psychology
0.000255
1.0
...
...
...
...
...
...
3054
2.317700
-71.532204
browser isolation
0.000150
0.0
3055
15.404965
0.663236
neural engineering
0.000150
0.0
3056
40.051682
-20.218977
level of analysis
0.000150
0.0
3057
38.300884
9.790667
social cognitive and affective neuroscience
0.000150
0.0
3058
3.957638
-22.789871
problem solving
0.000150
0.0
3059 rows × 5 columns
1 df.to_csv('tsne_vis_2d.csv' , index=False )
三维 TSNE
1 2 3 4 from sklearn.manifold import TSNEtsne = TSNE(n_components=3 , n_iter=1000 ) embed_3d = tsne.fit_transform(X)
/opt/anaconda3/envs/graph/lib/python3.11/site-packages/sklearn/manifold/_t_sne.py:1162: FutureWarning: 'n_iter' was renamed to 'max_iter' in version 1.5 and will be removed in 1.7.
warnings.warn(
1 2 3 4 5 6 7 df = pd.DataFrame() df['X' ] = embed_3d[:, 0 ] df['Y' ] = embed_3d[:, 1 ] df['Z' ] = embed_3d[:, 1 ] df['item' ] = model.wv.index_to_key df['pagerank' ] = pagerank.values() df['chosen' ] = terms_chosen_mask
X
Y
Z
item
pagerank
chosen
0
-5.344084
-13.896581
-13.896581
cloud computing
0.001352
1.0
1
12.959835
1.637353
1.637353
evolutionary psychology
0.000699
1.0
2
-9.399863
5.780833
5.780833
visual perception
0.000623
1.0
3
2.417569
-12.603775
-12.603775
cognitive science
0.000292
1.0
4
5.512045
1.471242
1.471242
cognitive psychology
0.000255
1.0
...
...
...
...
...
...
...
3054
-7.936583
-12.397557
-12.397557
browser isolation
0.000150
0.0
3055
9.576207
-11.376499
-11.376499
neural engineering
0.000150
0.0
3056
18.333593
-2.940028
-2.940028
level of analysis
0.000150
0.0
3057
7.171093
3.361520
3.361520
social cognitive and affective neuroscience
0.000150
0.0
3058
5.557903
4.377861
4.377861
problem solving
0.000150
0.0
3059 rows × 6 columns
1 df.to_csv('tsne_vis_3d.csv' , index=False )
7. 课后作业*
用 tsne_vis_2d.csv 和 tsne_vis_3d.csv 做可视化
参考代码:https://echarts.apache.org/examples/zh/editor.html?c=scatter3d&gl=1&theme=dark



 微信支付
微信支付 支付宝
支付宝