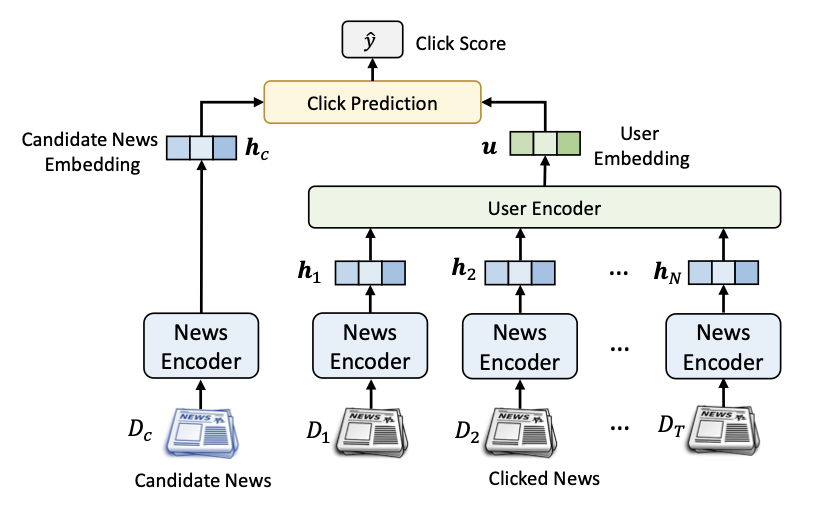
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
| import json
import requests
import torch
from datasets import load_dataset
from langchain.callbacks import StreamingStdOutCallbackHandler
from langchain.chains import LLMChain
from langchain.prompts.chat import ChatPromptTemplate
from langchain_community.llms import LlamaCpp
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from mlx_lm import load, generate
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
def icl_rec(
model_path: str = "",
icl_type: str = "",
instruction: str = "",
prompt: str = "",
temperature: float = 0.1,
top_p: float = 0.95,
ctx: int = 13000,
):
"""
针对单个prompt为用户进行icl推荐
:param model_path: 模型地址
:param icl_type: icl推理类型,我们实现了ollama、llamacpp、transformers、mlx 4类icl推理方法
:param instruction: 指令
:param prompt: 提示词
:param temperature: 大模型温度系数
:param top_p: 大模型的top_p
:param ctx: 输出token长度
:return: 无
"""
if not instruction:
instruction = ("You are a recommendation system expert who provides personalized recommendations to users "
"based on the background information provided.")
if not prompt:
prompt = """
"I've browsed the following news in the past in order:
[''Wheel Of Fortune' Guest Delivers Hilarious, Off The Rails Introduction','Hard Rock Hotel New Orleans collapse: Former site engineer weighs in','Felicity Huffman begins prison sentence for college admissions scam','Outer Banks storms unearth old shipwreck from 'Graveyard of the Atlantic'','Tiffany's is selling a holiday advent calendar for $112,000','This restored 1968 Winnebago is beyond adorable','Lori Loughlin Is 'Absolutely Terrified' After Being Hit With New Charge','Bruce Willis brought Demi Moore to tears after reading her book','Celebrity kids then and now: See how they've grown','Felicity Huffman Smiles as She Begins Community Service Following Prison Release','Queen Elizabeth Finally Had Her Dream Photoshoot, Thanks to Royal Dresser Angela Kelly','Hundreds of thousands of people in California are downriver of a dam that 'could fail'','Alexandria Ocasio-Cortez 'sincerely' apologizes for blocking ex-Brooklyn politician on Twitter, settles federal lawsuit','The Rock's Gnarly Palm Is a Testament to Life Without Lifting Gloves']
Then if I ask you to recommend a new news to me according to my browsing history, you should recommend 'Donald Trump Jr. reflects on explosive 'View' chat: 'I don't think they like me much anymore'' and now that I've just browsed 'Donald Trump Jr. reflects on explosive 'View' chat: 'I don't think they like me much anymore'', there are 22 candidate news that I can browse next:
1. 'Browns apologize to Mason Rudolph, call Myles Garrett's actions 'unacceptable'',
2. 'I've been writing about tiny homes for a year and finally spent 2 nights in a 300-foot home to see what it's all about here's how it went',
3. 'Opinion: Colin Kaepernick is about to get what he deserves: a chance',
4. 'The Kardashians Face Backlash Over 'Insensitive' Family Food Fight in KUWTK Clip',
5. 'THEN AND NOW: What all your favorite '90s stars are doing today',6. 'Report: Police investigating woman's death after Redskins' player Montae Nicholson took her to hospital',
7. 'U.S. Troops Will Die If They Remain in Syria, Bashar Al-Assad Warns',
8. '3 Indiana judges suspended after a night of drinking turned into a White Castle brawl',
9. 'Cows swept away by Hurricane Dorian found alive but how?',
10. 'Surviving Santa Clarita school shooting victims on road to recovery: Latest',
11. 'The Unlikely Star of My Family's Thanksgiving Table',
12. 'Meghan Markle and Hillary Clinton Secretly Spent the Afternoon Together at Frogmore Cottage',
13. 'Former North Carolina State, NBA player Anthony Grundy dies in stabbing, police say',
14. '85 Thanksgiving Recipes You Can Make Ahead',
15. 'Survivor Contestants Missy Byrd and Elizabeth Beisel Apologize For Their Actions',
16. 'Pete Davidson, Kaia Gerber Are Dating, Trying to Stay 'Low Profile'',
17. 'There's a place in the US where its been over 80 degrees since March',
18. 'Taylor Swift Rep Hits Back at Big Machine, Claims She's Actually Owed $7.9 Million in Unpaid Royalties',
19. 'The most talked about movie moments of the 2010s',
20. 'Belichick mocks social media in comments on Garrett incident',
21. '13 Reasons Why's Christian Navarro Slams Disney for Casting 'the White Guy' in The Little Mermaid',
22. '66 Cool Tech Gifts Anyone Would Be Thrilled to Receive'
Please select some news that I would like to browse next according to my browsing history. Please think step by step.
Please show me your results. Split your output with line break. You MUST select from the given candidate news. You can not generate news that are not in the given candidate list."
"""
assert (
icl_type
), "Please specify a --icl_type, e.g. --icl_type='ollama'"
if icl_type == "ollama":
"""
利用Ollama框架将大模型封装成类似ChatGPT接口规范的API服务,直接通过调用接口来实现大模型icl推荐
"""
url = "http://localhost:11434/api/chat"
data = {
"model": "yi:34b-chat",
"options": {
"temperature": temperature,
"top_p": top_p,
"num_ctx": ctx,
"num_gpu": 128,
},
"messages": [
{
"role": "user",
"content": prompt
}
]
}
response = requests.post(url=url, json=data, stream=True)
for chunk in response.iter_content(chunk_size=None, decode_unicode=True):
j = json.loads(chunk.decode('utf-8'))
print(j['message']['content'], end="")
elif icl_type == "llamacpp":
if not model_path:
model_path = "/Users/liuqiang/Desktop/code/llm/models/gguf/qwen1.5-72b-chat-q5_k_m.gguf"
callback = StreamingStdOutCallbackHandler()
n_gpu_layers = 128
n_batch = 4096
llm = LlamaCpp(
streaming=True,
model_path=model_path,
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
f16_kv=True,
temperature=temperature,
top_p=top_p,
n_ctx=ctx,
callbacks=[callback],
verbose=True
)
system = [("system", instruction),
("user", "{input}")]
template = ChatPromptTemplate.from_messages(system)
chain = LLMChain(prompt=template, llm=llm)
chain.invoke({"input": prompt})
elif icl_type == "transformers":
if not model_path:
model_path = "/Users/liuqiang/Desktop/code/llm/models/Yi-34B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="mps",
use_cache=True,
)
model = model.to("mps")
streamer = TextStreamer(tokenizer)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
streamer=streamer,
max_length=13000,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id,
top_p=top_p,
repetition_penalty=1.15,
do_sample=False,
)
llm = HuggingFacePipeline(pipeline=pipe)
system = [("system", instruction),
("user", "{input}")]
template = ChatPromptTemplate.from_messages(system)
chain = LLMChain(prompt=template, llm=llm)
chain.invoke({"input": prompt})
elif icl_type == "mlx":
if not model_path:
model_path = "/Users/liuqiang/Desktop/code/llm/models/Yi-34B-Chat"
model, tokenizer = load(model_path)
response = generate(
model,
tokenizer,
prompt=prompt,
temp=temperature,
max_tokens=10000,
verbose=True
)
print(response)
else:
raise NotImplementedError("the case not implemented!")
def icl_rec_batch(validation_path: str, icl_type='llamacpp'):
"""
针对从训练数据构建的测试集,逐条为用户进行icl推理,你可以跟真实值(即output)对比,查看大模型icl推荐的效果
"""
data = load_dataset("json", data_files=validation_path)
index = 1
for row in data['train']:
instruction = row['instruction']
input = row['input']
output = row['output']
print(str(index) + " : --------------------")
icl_rec(icl_type=icl_type, instruction=instruction, prompt=input)
print(output)
if __name__ == "__main__":
icl_rec(icl_type="llamacpp")
|

 微信支付
微信支付 支付宝
支付宝