
Transformer 开山之作
Transformer 开山之作
模型架构
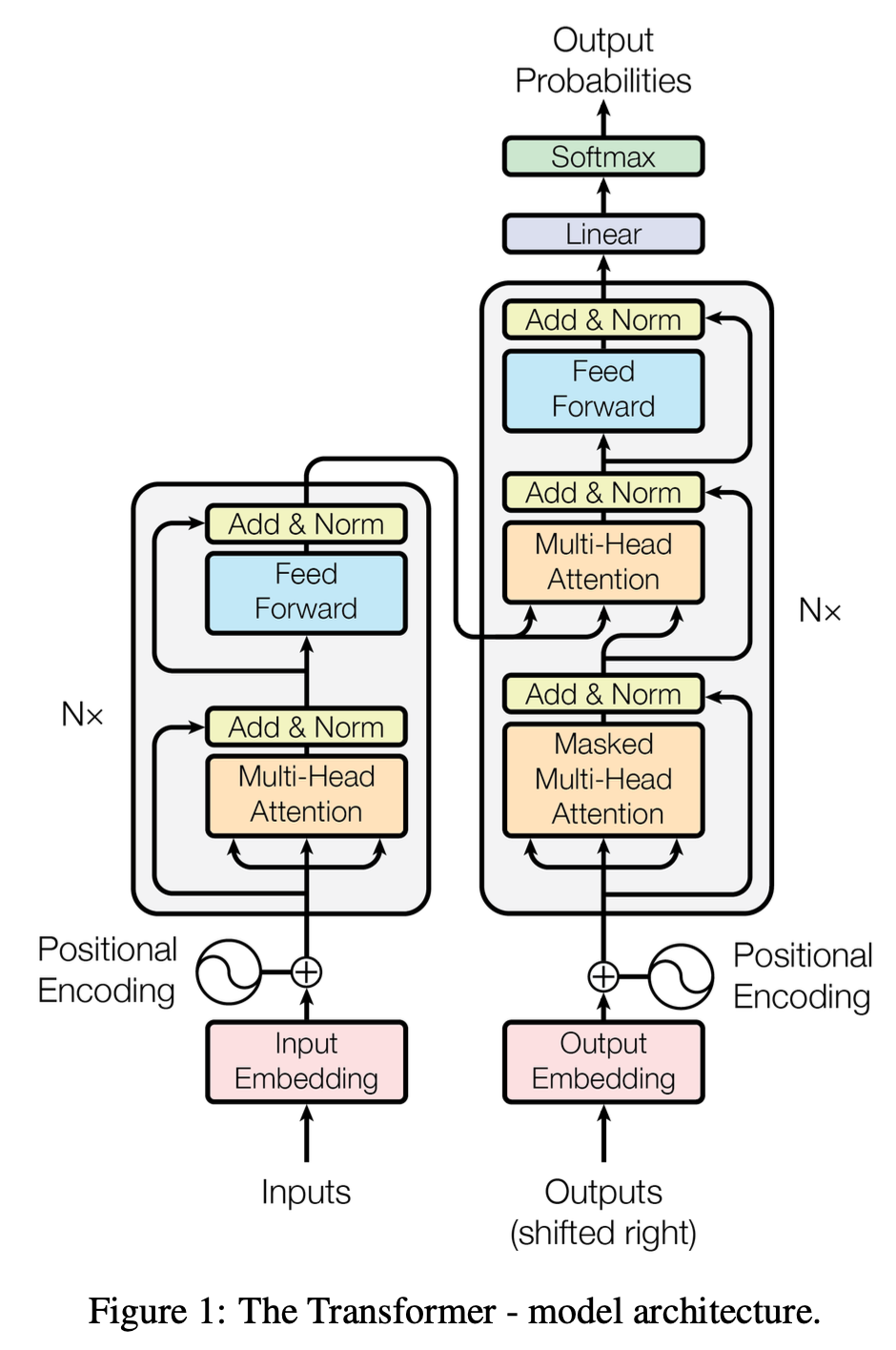
Encoder
编码器(左)Encoder:(可以有N个)
Multi-Head Attention层Feed Forward层(本质上就是MLP)
- 上述两者在输出后都残差连接
Residual Connection和层归一化Layer Normalization。
即 - 固定输出维度
Decoder
解码器(右)Decoder:(可以有N个)
Masked Multi-Head Attention层Multi-Head Attention层Feed Forward层
- 第一个注意力层需要 Masked,是为了模拟预测的状态,不会提前知道后续词。
- 第二个注意力层的输入的
K和V来自编码器Encoder 的输出,而Q是本解码器的。
解码器的最后需要输出:
- 通过
Linear线性层;- 使用
Softmax非线性激活输出。
注意力机制
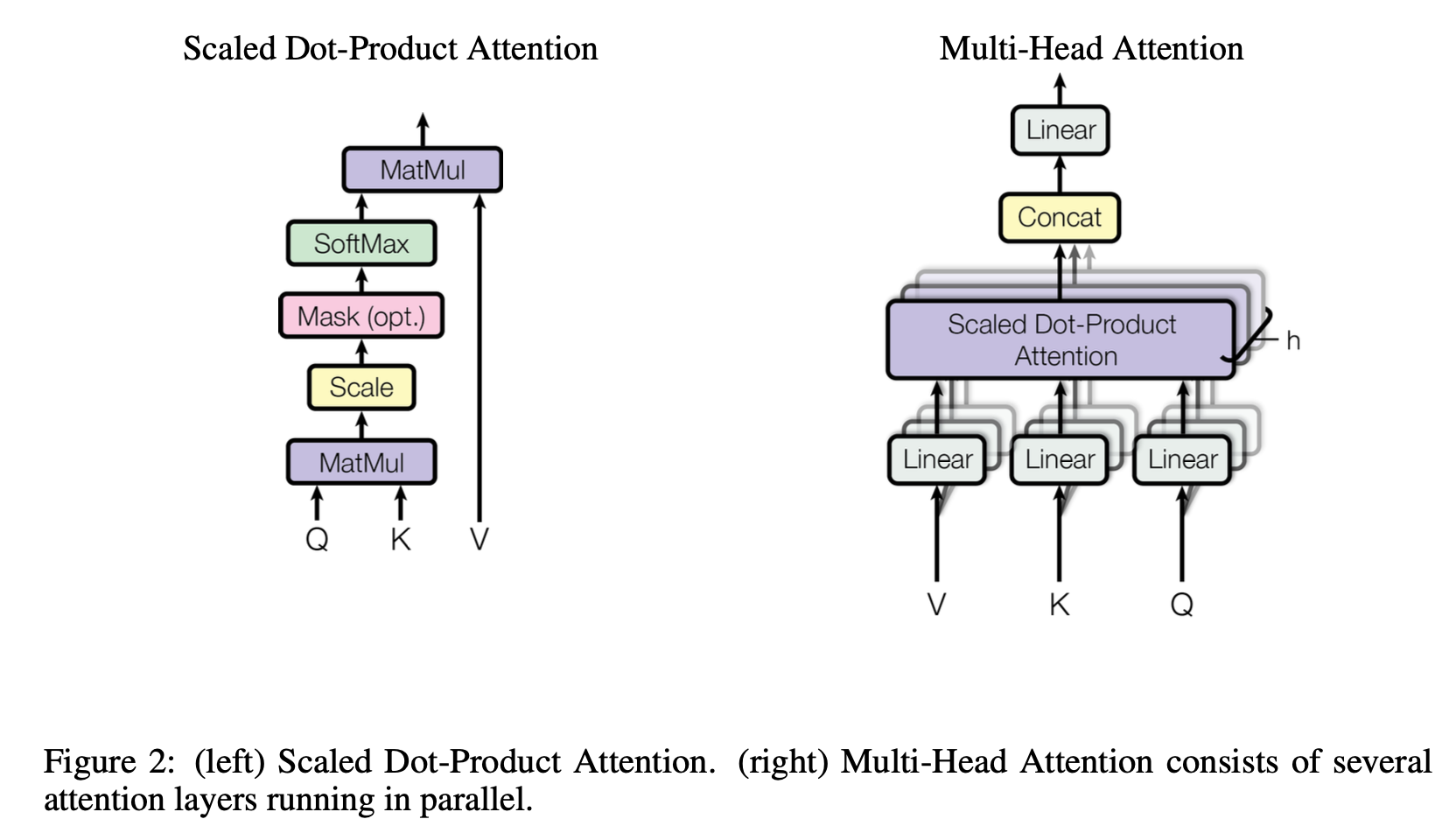
Scaled Dot-Product Attention
计算公式:
Multi-Head Attention
计算公式:
其中矩阵参数, ,
逐位前馈网络
- Position-wise Feed-Forward Networks 本质上就是 MLP。
- 计算公式:
- 输入输出维度都是
- 内部层维度为
位置编码
- 用于Attention层是在全局序列中直接聚合到一个数值上。
- 那么这个序列的所有位置的数值保持相同,顺序打乱,通过Attention层会仍然得到一个一样的值。
- 也就是说,Attention 层并不会感知时序。
- 因此,需要加入位置编码。
- 计算公式:
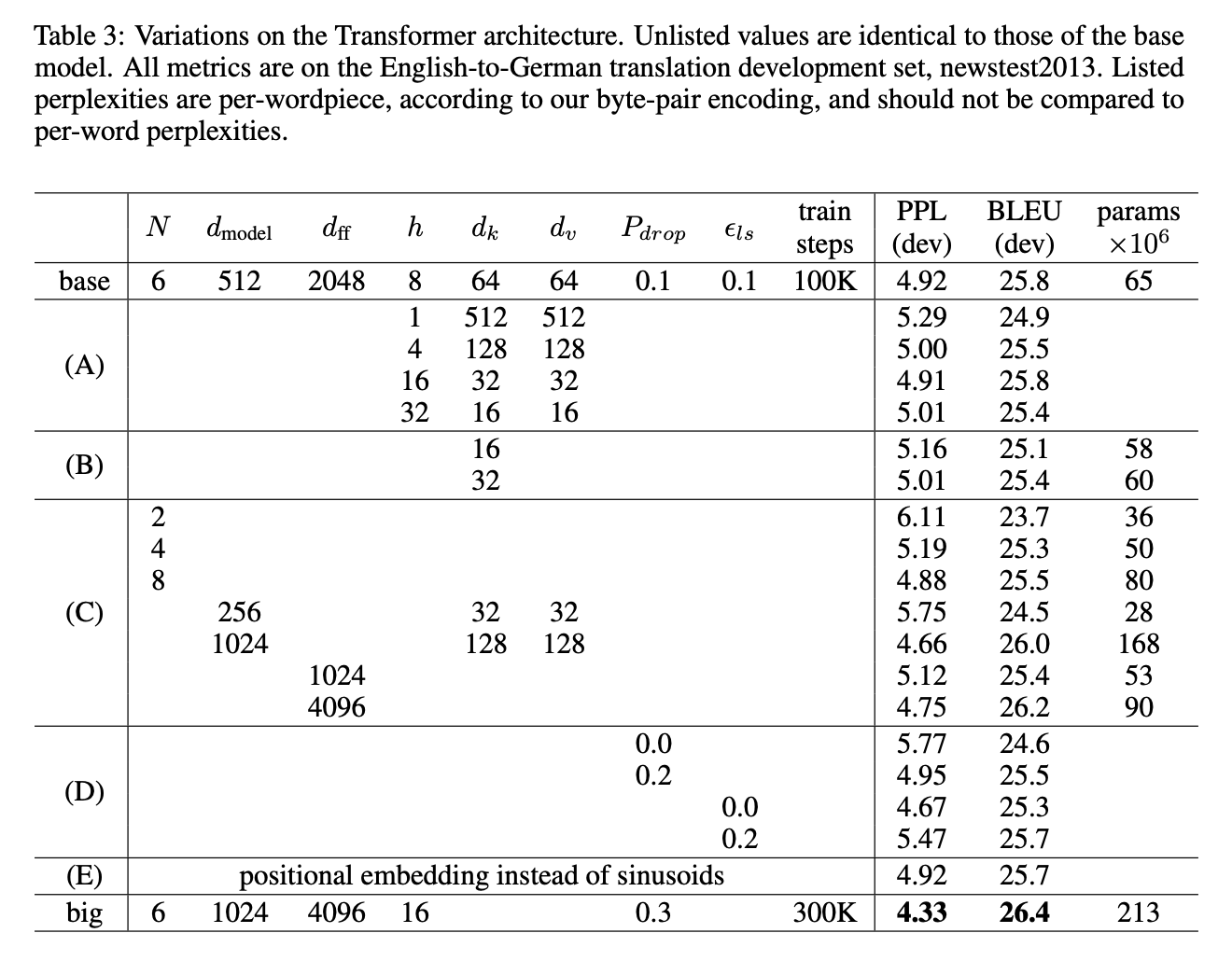
理论对比和实验结果
理论对比分析

实验调参结果
Q & A
-
Transformer为何使用多头注意力机制?(为什么不使用一个头)
- 多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
- 参考:https://www.zhihu.com/question/3412
-
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?(注意和第一个问题的区别)
- 使用Q/K/V不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。同时,由softmax函数的性质决定,实质做的是一个soft版本的arg max操作,得到的向量接近一个one-hot向量(接近程度根据这组数的数量级有所不同)。如果令Q=K,那么得到的模型大概率会得到一个类似单位矩阵的attention矩阵,这样self-attention就退化成一个point-wise线性映射。这样至少是违反了设计的初衷。
- 参考:https://www.zhihu.com/question/3193
-
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
- K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的 , 来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
- 为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
-
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
- 这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale。
- 那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
- 参考:https://www.zhihu.com/question/3397
-
在计算attention score的时候如何对padding做mask操作?
- padding位置置为负无穷(一般来说-1000就可以),再对attention score进行相加。对于这一点,涉及到batch_size之类的
- 具体可看抱抱脸实现的源代码:https://github.com/huggingface/
-
为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
- 将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
- 基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN
-
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
- embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
-
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
- 因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
- 一文读懂Transformer模型的位置编码
-
你还了解哪些关于位置编码的技术,各自的优缺点是什么?(参考上一题)
- 相对位置编码(RPE)
- 1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。
- 2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置
- 3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。
- 前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
-
简单讲一下Transformer中的残差结构以及意义。
- 就是ResNet的优点,解决梯度消失
-
为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
- LN:针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
- CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
-
简答讲一下BatchNorm技术,以及它的优缺点。
- 优点:
- 第一个就是可以解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快的收敛速度。
- 第二个优点就是缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
- 缺点:
- 第一个,batch_size较小的时候,效果差。这一点很容易理解。BN的过程,使用 整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
- 第二个缺点就是 BN 在RNN中效果比较差。
- 优点:
-
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
- ReLU:$FFN(x)=max(0,xW_1+b_1) W_2 +b_2 $
-
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
- Cross Self-Attention,Decoder提供Q,Encoder提供K,V
-
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
- 让输入序列只看到过去的信息,不能让他看到未来的信息
-
Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
- Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
- Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
-
简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
- 传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题),传统词tokenization方法不利于模型学习词缀之间的关系”
- BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
- 优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
- 缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
-
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
- Dropout测试的时候记得对输入整体呈上dropout的比率
-
引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
- BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。
-
解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露?
- 没有,残差连接时已经走出Attention层了。并没有参与Attention层的计算。
- 即使残差连接将原始输入传递给下一层,下一层的注意力机制仍会重新应用掩码,确保后续信息不可见。
 微信支付
微信支付 支付宝
支付宝