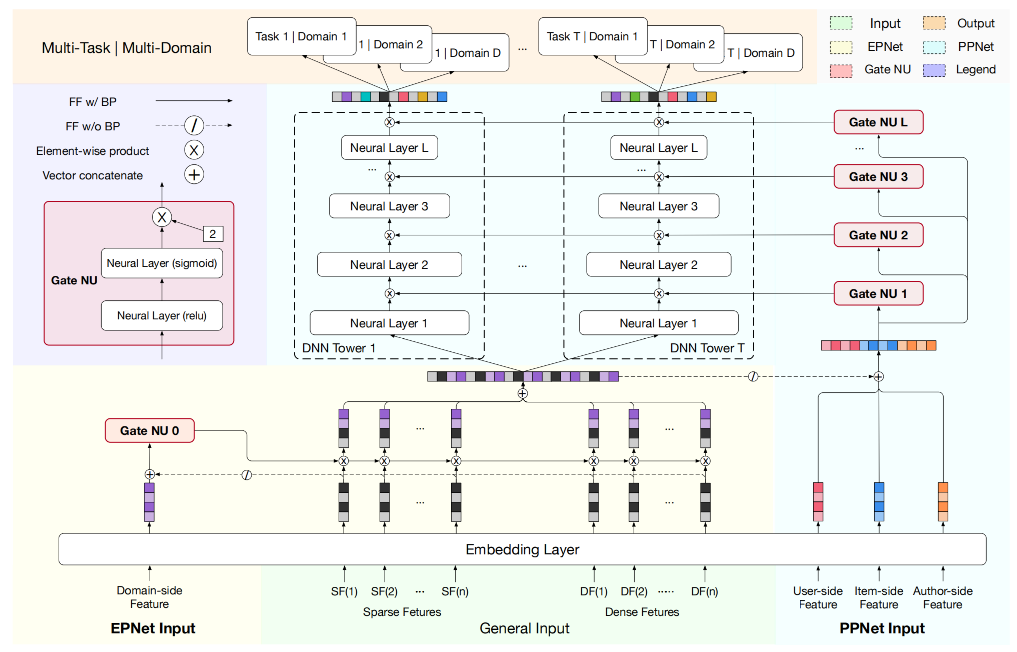
参考
精排(一)记忆与泛化
在构建推荐模型时,我们常常追求两个看似矛盾的目标:记忆(Memorization)与泛化(Generalization)。
-
记忆能力,指的是模型能够学习并记住那些在历史数据中频繁共同出现的特征组合。例如,模型记住“买了A的用户,通常也会买B”。这种能力可以精准地捕捉显性、高频的关联,为用户提供与他们历史行为高度相关的推荐。
-
泛化能力,指的是模型能够发掘特征之间更深层次的关联,探索那些在数据中从未或很少出现过的全新特征组合。例如,模型通过学习发现“物品A和物品C都属于某个抽象类别,而用户喜欢该类别的物品”,从而向喜欢A的用户推荐了他们从未见过的C。这种能力有助于提升推荐的多样性和新颖性。
如何在一个模型中平衡并兼具这两种能力,是推荐系统领域的一个核心挑战。于2016年提出的Wide & Deep模型 ,为此提供了一个影响深远的经典架构。它并非简单的模型集成,而是通过一种巧妙的 联合训练(Joint Training) 机制,将两种能力无缝融合。
这个架构的核心思想是将模型结构拆分为两个部分,分别承担不同的职责,如下图所示:
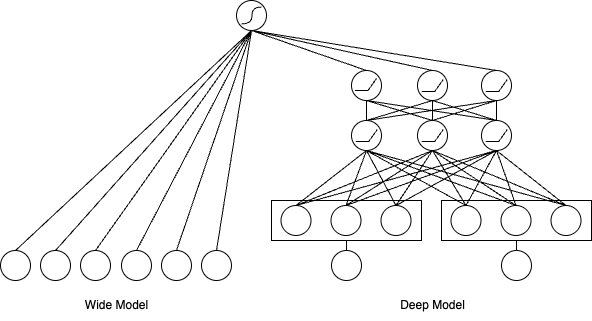
记忆的捷径:Wide部分
Wide部分本质上是一个广义线性模型,比如逻辑回归。它的优势在于结构简单、可解释性强,并且能高效地“记忆”那些显而易见的关联规则。其数学表达形式如下:
y=wTx+b
其中,y是预测值,w 是模型权重,x是特征向量,b是偏置项。
Wide部分的关键在于其输入的特征向量x。它不仅包含原始特征,更重要的是包含了大量人工设计的交叉特征(Cross-product Features)。交叉特征可以将多个独立的特征组合成一个新的特征,用于捕捉特定的共现模式。例如,在应用商店的推荐场景中,我们可以创建一个交叉特征AND(installed_app=photo_editor, impression_app=filter_pack),它代表用户已经安装了“照片编辑器”应用,并且现在看到了“滤镜包”应用的推荐。
通过这种方式,Wide部分能够直接、快速地学习到“照片编辑器用户对滤镜包应用有更高的安装意愿”这类强关联规则,这正是“记忆能力”的直接体现。
泛化的深度:Deep部分
Deep部分是一个标准的前馈神经网络(DNN),它负责模型的“泛化能力”。与Wide部分依赖人工特征工程不同,Deep部分可以自动学习特征之间的高阶、非线性关系。
它的工作流程如下:首先,对于那些高维稀疏的类别特征(如用户ID、物品ID),通过一个**嵌入层(Embedding Layer)**将它们映射为低维、稠密的向量。这些嵌入向量能够捕捉到特征的潜在语义信息,是实现泛化的基础。例如,《流浪地球》和《三体》的电影ID在嵌入空间中的距离,可能会比《流浪地球》和《熊出没》更近。
随后,这些嵌入向量与其他数值特征拼接在一起,被送入多层神经网络中进行前向传播:
a(l+1)=f(W(l)a(l)+b(l))
其中,a(l)是第l层的激活值,W(l)和b(l)是该层的权重和偏置,f是激活函数(如ReLU)。通过逐层抽象,DNN能够发掘出数据中隐藏的复杂模式,从而对未曾见过的特征组合也能做出合理的预测。
融合与演进
Wide & Deep模型通过联合训练,将两部分的输出结合起来进行最终的预测。其预测概率由下式给出:
P(Y=1∣x)=σ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)
在这里,σ是Sigmoid函数,[x,ϕ(x)]代表Wide部分的输入(包含原始特征和交叉特征),a(lf)是Deep部分最后一层的输出向量,wwide,wdeep和b是最终预测层的权重和偏置。模型的梯度在反向传播时会同时更新Wide和Deep两部分的所有参数。
一个值得注意的工程细节是,由于两部分处理的特征类型不同,它们通常会采用不同的优化器。
总而言之,Wide & Deep不仅是一个具体的模型,更是一种重要的设计哲学,它为如何在推荐系统中平衡准确性与多样性、精确记忆与有效泛化,提供了清晰而强大的解决思路。
代码
wide_deep.py 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| import tensorflow as tf
from .utils import (
build_input_layer,
build_group_feature_embedding_table_dict,
concat_group_embedding,
add_tensor_func,
get_linear_logits,
get_cross_logits,
)
from .layers import PredictLayer, DNNs
def build_wide_deep_model(feature_columns, model_config):
"""
构建Wide&Deep模型
参数:
feature_columns: 特征列配置
model_config: 模型配置字典,包含:
- dnn_units: DNN层单元数 (默认: [64, 32])
- dnn_dropout_rate: 丢弃概率 (默认: 0.1)
"""
dnn_units = model_config.get("dnn_units", [64, 32])
dnn_dropout_rate = model_config.get("dnn_dropout_rate", 0.1)
input_layer_dict = build_input_layer(feature_columns)
group_embedding_feature_dict = build_group_feature_embedding_table_dict(
feature_columns, input_layer_dict, prefix="embedding/"
)
group_feature_dict = {}
for group_name, _ in group_embedding_feature_dict.items():
group_feature_dict[group_name] = concat_group_embedding(
group_embedding_feature_dict, group_name, axis=1, flatten=True
)
deep_logits = []
for group_name, group_feature in group_feature_dict.items():
deep_out = DNNs(
units=dnn_units, activation="relu", dropout_rate=dnn_dropout_rate
)(group_feature)
deep_logit = tf.keras.layers.Dense(1, activation=None)(
deep_out
)
deep_logits.append(deep_logit)
linear_logit = get_linear_logits(input_layer_dict, feature_columns)
cross_logit = get_cross_logits(input_layer_dict, feature_columns)
wide_deep_logits = add_tensor_func(deep_logits + [linear_logit, cross_logit])
wide_deep_logits = tf.keras.layers.Flatten()(wide_deep_logits)
output = tf.keras.layers.Dense(1, activation="sigmoid", name="wide_deep_output")(
wide_deep_logits
)
output = tf.keras.layers.Flatten()(output)
model = tf.keras.Model(inputs=list(input_layer_dict.values()), outputs=output)
return model, None, None
|
性能效果
1
2
3
4
5
| +-----------+--------+--------+------------+
| model | auc | gauc | val_user |
+===========+========+========+============+
| wide_deep | 0.5928 | 0.5749 | 928 |
+-----------+--------+--------+------------+
|

 微信支付
微信支付 支付宝
支付宝