参考
精排(四)多目标建模
多目标建模(Multi-Task Learning, MTL)通过联合优化多个相关任务,在推荐系统中实现用户体验与商业目标的协同提升。相比独立建模,多目标方法能够降低参数量、提升系统效率,并通过知识迁移缓解数据稀疏问题。
在实际应用中,电商场景联合优化CTR、CVR、GMV避免单一指标导致的低质商品推荐;视频平台同时优化播放完成率、评分预测、用户留存率提升长期用户价值。然而,多目标建模面临任务冲突、跷跷板效应和负迁移等核心挑战。
针对这些挑战,业界发展出三大解决方向:模型架构从Shared-Bottom到MMoE再到PLE的演进,解决任务冲突与负迁移;ESMM和ESM2等依赖关系建模方法,处理用户行为链路的样本偏差;以及从手工加权到自适应优化的多损失融合策略,解决量级失衡与收敛异步问题。
本章将详细介绍这些核心技术的原理与实践。
1、基础结构演进
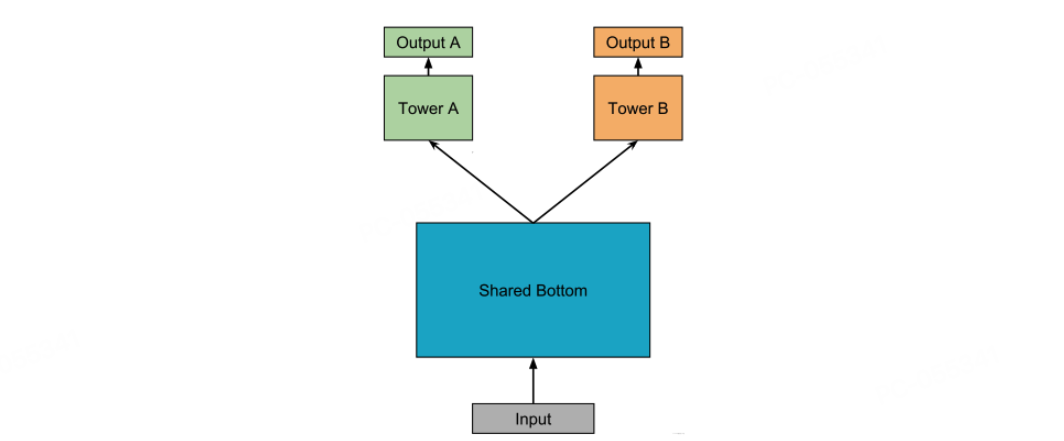
1.1 Shared-Bottom
原理
Shared-Bottom 模型作为多目标建模的奠基性架构,采用"共享地基+独立塔楼"的设计范式。其核心结构包含两个关键组件:
这种架构的数学表达可描述为:
y^t=ft(Wt⋅g(Wsx))
其中 Ws 为共享层参数,g(⋅) 为共享特征提取函数,ft(⋅) 为任务 t 的预测函数。其设计哲学建立在任务同质性假设上:不同任务共享相同的底层特征空间,仅需在顶层进行任务适配。
Shared-Bottom 模型在效率与泛化之间实现了良好的平衡,其核心优势主要体现在以下几点。
-
在参数效率方面,共享层占据了模型大部分的参数量这显著降低了模型的总参数量。
-
共享层具有正则化效应,它如同一个天然的正则化器,通过强制任务共用特征表示,有效防止了单个任务出现过拟合的情况。
-
在知识迁移方面,当任务之间存在潜在的相关性时,例如视频的点击率与完播率,共享层能够学习到通用的模式,从而提升小样本任务的泛化能力。
然而,Shared-Bottom 模型也存在一个致命缺陷,即负迁移现象。当任务之间存在本质上的冲突时,该模型的硬共享机制会引发负迁移问题。从机制本质上来看,共享层的梯度更新方向是由所有任务共同决定的,一旦任务目标之间出现冲突,参数优化就会陷入方向性的矛盾。
在一些典型场景中,例如电商平台同时优化“点击率”与“客单价”时,低价商品可能会推动点击率的提升,但同时却抑制了客单价的增长;又如内容平台在平衡“内容消费深度”与“广告曝光量”时,深度阅读行为往往与广告点击行为呈负相关。
从数学角度来解释,假设任务i与任务j的损失梯度分别为∇Li与∇Lj,当∇Li⋅∇Lj < 0时,共享层参数更新就会产生内在的冲突。这种冲突使得模型在处理矛盾任务时呈现出“零和博弈”的特性,即提升某一目标的性能往往需要以牺牲另一目标为代价,我们一般也称这类问题为跷跷板问题。
代码
- shared-bottom模型构建代码如下,先组装输入到shared-bottom网络中的特征dnn_inputs, 经过一个shared-bottom DNN网络,遍历创建各个任务独立的DNN塔,最后输出多个塔的预估值用于计算Loss。
shared_bottom.py 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| import tensorflow as tf
from .utils import (
build_input_layer,
build_group_feature_embedding_table_dict,
concat_group_embedding,
)
from .layers import DNNs, PredictLayer
def build_shared_bottom_model(feature_columns, model_config):
"""
构建Shared-Bottom多任务排序模型。
Args:
feature_columns: FeatureColumn列表
model_config: 包含参数的字典:
- task_names: 列表,任务名称 (默认 ["is_click"])
- share_dnn_units: 列表,共享底层DNN隐藏单元 (默认 [128, 64])
- task_tower_dnn_units: 列表,任务塔DNN隐藏单元 (默认 [128, 64])
- dropout_rate: 浮点数,dropout率 (默认 0.1)
Returns:
(model, None, None): 排序模型元组
"""
task_names = model_config.get("task_names", ["is_click"])
share_dnn_units = model_config.get("share_dnn_units", [128, 64])
task_tower_dnn_units = model_config.get("task_tower_dnn_units", [128, 64])
dropout_rate = model_config.get("dropout_rate", 0.1)
input_layer_dict = build_input_layer(feature_columns)
group_embedding_feature_dict = build_group_feature_embedding_table_dict(
feature_columns, input_layer_dict, prefix="embedding/"
)
dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "shared_bottom")
shared_bottom_feature = DNNs(
name="shared_bottom", units=share_dnn_units, dropout_rate=dropout_rate
)(dnn_inputs)
task_output_list = []
for task_name in task_names:
task_output_logit = DNNs(
name=f"task_tower_{task_name}",
units=task_tower_dnn_units + [1],
dropout_rate=dropout_rate,
)(shared_bottom_feature)
task_output_prob = PredictLayer(name=f"task_{task_name}")(task_output_logit)
task_output_list.append(task_output_prob)
model = tf.keras.models.Model(
inputs=list(input_layer_dict.values()), outputs=task_output_list
)
return model, None, None
|
1.2 MMOE
原理
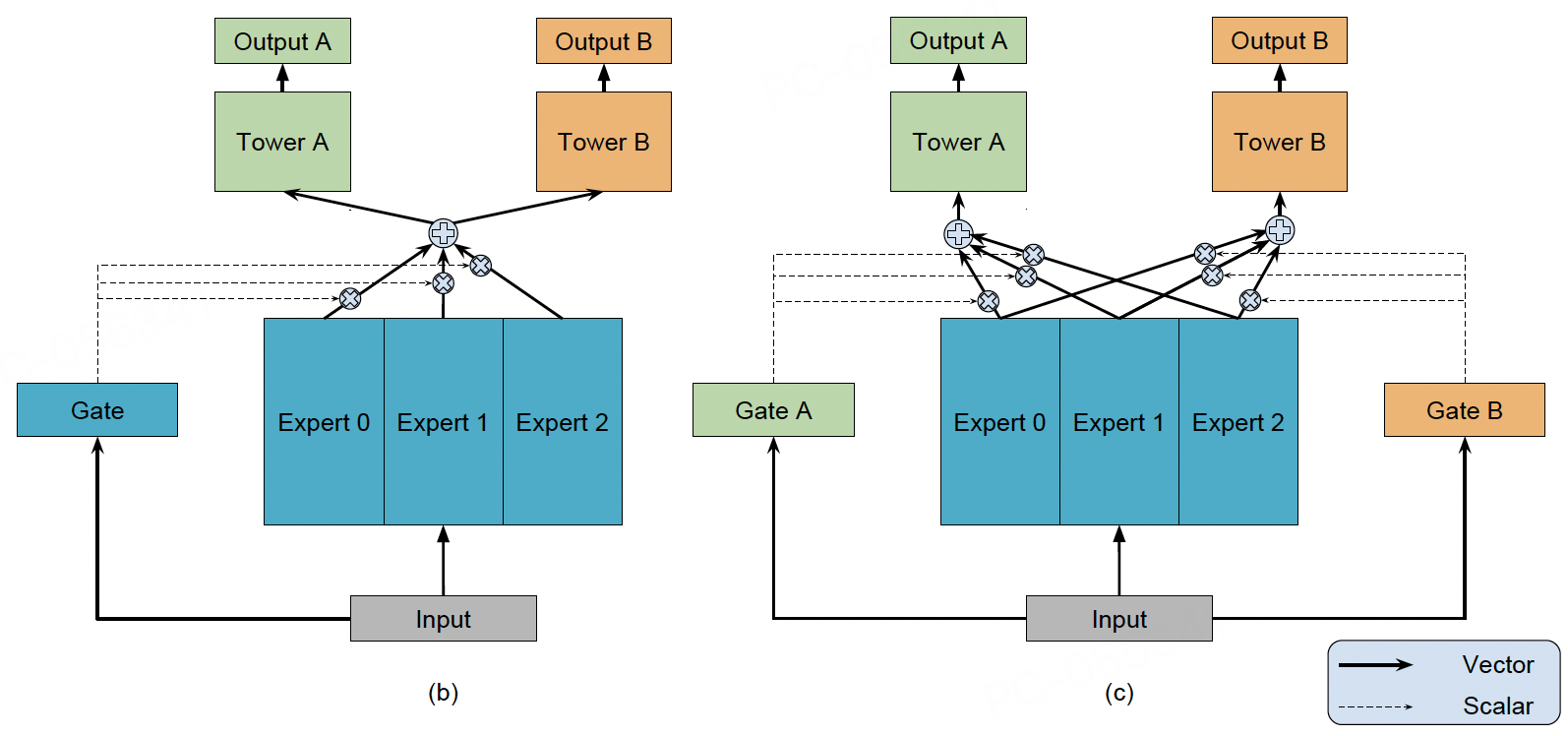
针对Shared-Bottom对相关性低的多个任务出现负迁移的现象,OMOE将底层共享的一个Shared-Bottom模块拆分成了多个Expert,最终OMOE的输出为多个Expert的加权和,本质可以看成是专家网络和全局门控的双层结构。
虽然OMOE通过底层多专家融合的方式提升了特征表征的多样性,从最终的实验结果看,确实可以一定程度上缓解低相关性任务的负迁移问题,但没有彻底解决多任务冲突的问题。因为不同任务反向传播的梯度还是会直接影响底层专家网络的学习。
为了进一步缓解多任务冲突,MMOE为每个任务配备专属门控网络,实现了门控从"全局共享"升级为"任务自适应"的方式。MMoE的数学表达式可以表示为:
ekgt(x)hty^t=fk(x)=softmax(Wtx)=k=1∑Kgt,k⋅ek=ft(ht)
其中,
-
x表示底层的特征输入
-
ek表示第k个专家网络的输出
-
gt(x)表示第t个任务融合专家网络的门控向量
-
ht表示第t个任务融合专家网络的输出
-
y^t表示第t个任务的预测结果
差异化特征融合门控网络gt根据任务特性选择专家组合,例如在电商场景,CTR任务门控加权"即时兴趣"“价格敏感"专家,CVR任务门控:侧重"消费能力”"品牌忠诚"专家。
当任务i与j冲突时,如果模型学的还不错,那么这两个任务对所有Expert的融合权重是有差异的。例如出现了某个em专家,对于任务i来说非常大,但是对于任务j来说非常小,那么最终em参数的更新就会被任务i来主导,起到了一定的梯度隔离的效果。
代码
- MMoE模型构建代码如下,先组装输入到MoE网络中的特征dnn_inputs, 然后为每个任务创建一个门控网络输出最终融合Expert的门控向量。最后为每个任务都创建一个任务塔,并且不同任务塔的输入都是对应任务的门控向量和多个Expert融合后的向量。
mmoe.py 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| import tensorflow as tf
from .utils import (
build_input_layer,
build_group_feature_embedding_table_dict,
concat_group_embedding,
)
from .layers import DNNs, PredictLayer
def build_mmoe_model(feature_columns, model_config):
"""
构建多门控专家混合(MMoE)多任务排序模型。
Args:
feature_columns: FeatureColumn 列表
model_config: 包含参数的字典:
- task_names: 列表,任务名称(默认 ["is_click"])
- expert_nums: 整数,专家数量(默认 4)
- expert_dnn_units: 列表,专家 DNN 隐藏单元(默认 [128, 64])
- gate_dnn_units: 列表,门控 DNN 隐藏单元(默认 [128, 64])
- task_tower_dnn_units: 列表,任务塔 DNN 隐藏单元(默认 [128, 64])
- dropout_rate: 浮点数,dropout 率(默认 0.1)
Returns:
(model, None, None): 排序模型元组
"""
task_names = model_config.get("task_names", ["is_click"])
expert_nums = model_config.get("expert_nums", 4)
expert_dnn_units = model_config.get("expert_dnn_units", [128, 64])
gate_dnn_units = model_config.get("gate_dnn_units", [128, 64])
task_tower_dnn_units = model_config.get("task_tower_dnn_units", [128, 64])
dropout_rate = model_config.get("dropout_rate", 0.1)
input_layer_dict = build_input_layer(feature_columns)
group_embedding_feature_dict = build_group_feature_embedding_table_dict(
feature_columns, input_layer_dict, prefix="embedding/"
)
dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "mmoe")
expert_output_list = []
for i in range(expert_nums):
expert_output = DNNs(
name=f"expert_{i}", units=expert_dnn_units, dropout_rate=dropout_rate
)(dnn_inputs)
expert_output_list.append(expert_output)
expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1))(
expert_output_list
)
task_tower_input_list = []
for i, task_name in enumerate(task_names):
gate_output = DNNs(
name=f"task_{i}_gates", units=gate_dnn_units, dropout_rate=dropout_rate
)(dnn_inputs)
gate_output = tf.keras.layers.Dense(
expert_nums, use_bias=False, activation="softmax", name=f"task_{i}_softmax"
)(gate_output)
gate_output = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(
gate_output
)
gate_expert_output = tf.keras.layers.Lambda(lambda x: x[0] * x[1])(
[gate_output, expert_concat]
)
gate_expert_output = tf.keras.layers.Lambda(
lambda x: tf.reduce_sum(x, axis=1, keepdims=False)
)(gate_expert_output)
task_tower_input_list.append(gate_expert_output)
task_output_list = []
for i, task_name in enumerate(task_names):
task_output_logit = DNNs(
name=f"task_tower_{task_name}",
units=task_tower_dnn_units + [1],
dropout_rate=dropout_rate,
)(task_tower_input_list[i])
task_output_prob = PredictLayer(name=f"task_{task_name}")(task_output_logit)
task_output_list.append(task_output_prob)
model = tf.keras.models.Model(
inputs=list(input_layer_dict.values()), outputs=task_output_list
)
return model, None, None
|
1.3 PLE
原理
MMoE 通过为每个任务配备专属门控网络,在一定程度上缓解了多任务冲突问题。专属门控网络能够根据任务特性选择专家组合,从而使得不同任务可以关注不同的特征表示。但其架构仍存在一个根本性局限:所有专家对所有任务门控可见。这种“软隔离”设计在实践中仍面临两大挑战:
- 负迁移未根除:
- 干扰路径未切断:即使某个专家(如em)被任务i的门控高度加权而被任务j的门控忽略,任务j的梯度在反向传播时仍会流经em(因为em是任务j门控的可选项)。当任务冲突强烈时,这种“潜在通路”仍可能导致共享表征被污染。
- 专家角色模糊:MMoE缺乏机制强制专家明确分工。一个专家可能同时承载共享信息和多个任务的特定信息,成为冲突的“重灾区”。尤其在任务相关性低时,这种耦合会加剧负迁移。
- 门控决策负担重:
- 每个任务的门控需要在所有K个专家上进行权重分配。当专家数量增加(通常需扩大K以提升模型能力)时,门控网络面临高维决策问题,易导致训练不稳定或陷入次优解。
- 门控需要“费力”地从包含混杂信息(共享+所有任务特定) 的专家池中筛选有用信息,增加了学习难度。
为解决上述问题,CGC结构被提出,其核心思想是通过硬性结构约束,显式分离共享知识与任务特定知识:
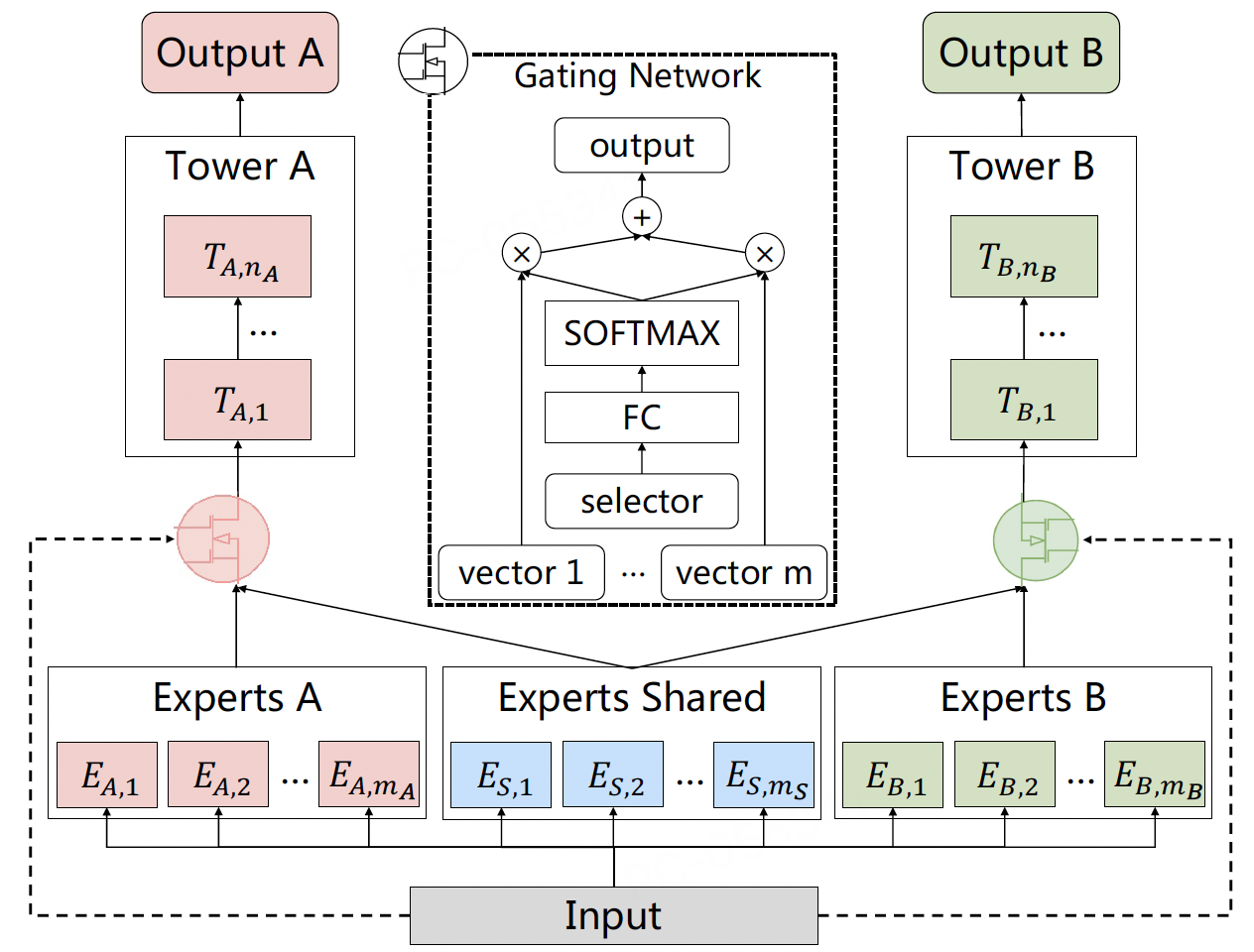
专家职责强制分离:
-
共享专家 (C-Experts):一组专家仅负责学习所有任务的共性知识。设其数量为M,输出为c1,c2,...,cM。
-
任务专家 (T-Experts):每个任务t拥有自己专属的专家组,仅负责学习该任务特有的知识或模式。设任务t的专属专家数量为Nt,输出为tt1,tt2,...,ttNt。
任务专属门控的输入限制:
-
任务t的门控gt的输入被严格限制为:共享专家输出 (ckk=1M) + 本任务专属专家输出 (ttjj=1Nt)。
-
物理切断干扰路径:任务t的门控完全无法访问其他任务s(s=t)的专属专家tsj。同样,任务s的梯度绝不会更新任务t的专属专家参数。
CGC门控的计算如下:
gt(x)=softmax(Wt⋅x+bt)
ht=k=1∑Mgt,k⋅ck+j=1∑Ntgt,M+j⋅ttj
y^t=ft(ht)
其中:
- Wt,bt:任务t门控的参数。
- gt,k:分配给第k个共享专家的权重。
- gt,M+j:分配给任务t第j个专属专家的权重。
CGC解决了知识分离的核心问题,但其本质是单层结构,表征学习深度有限。受深度神经网络逐层抽象特征的启发,PLE (Progressive Layered Extraction) 将多个CGC单元纵向堆叠,形成深层架构,实现渐进式知识提取与融合。
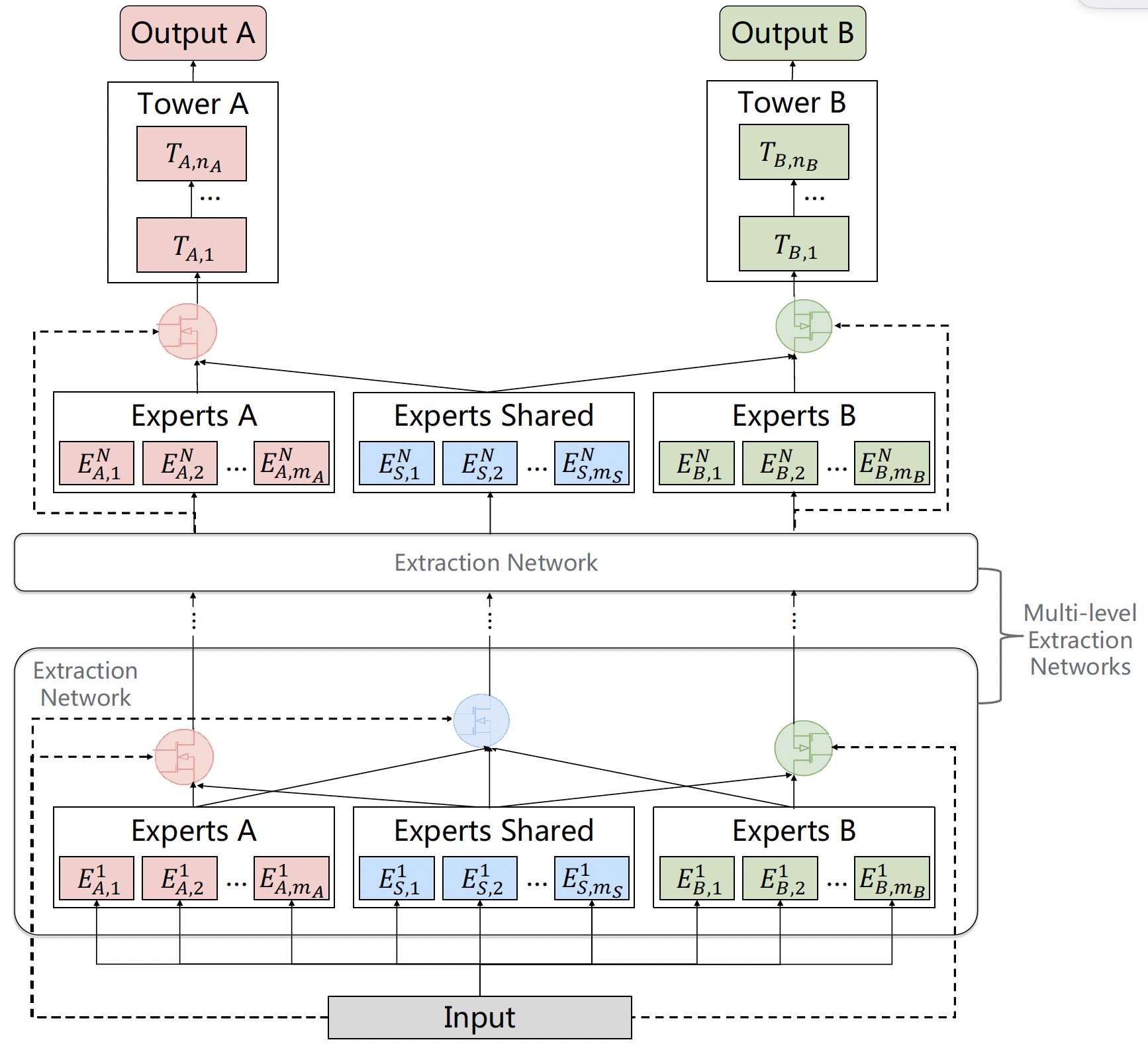
代码
ple.py 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
| import tensorflow as tf
import itertools
from .utils import (
build_input_layer,
build_group_feature_embedding_table_dict,
concat_group_embedding,
)
from .layers import DNNs, PredictLayer
def cgc_net(
input_list,
task_num,
task_expert_num,
shared_expert_num,
task_expert_dnn_units,
shared_expert_dnn_units,
task_gate_dnn_units,
shared_gate_dnn_units,
leval_name=None,
is_last=False,
):
"""CGC结构
input_list: 每个任务都有一个输入,这些任务的输入都是共享的,为了方便处理,给每个任务都复制了一份
is_last: 主要是判断是否是最后一层CGC,如果是的话,就不需要把共享部分添加到输出中了
"""
task_expert_list = []
for i in range(task_num):
task_i_expert_list = []
for j in range(task_expert_num):
expert_dnn = DNNs(
task_expert_dnn_units,
name=f"{leval_name}_task_{str(i)}_expert_{str(j)}",
)(input_list[i])
task_i_expert_list.append(expert_dnn)
task_expert_list.append(task_i_expert_list)
shared_expert_list = []
for i in range(shared_expert_num):
expert_dnn = DNNs(
shared_expert_dnn_units, name=f"{leval_name}_shared_expert_{str(i)}"
)(input_list[-1])
shared_expert_list.append(expert_dnn)
task_gate_list = []
fusion_expert_num = task_expert_num + shared_expert_num
for i in range(task_num):
gate_dnn = DNNs(task_gate_dnn_units, name=f"{leval_name}_task_{str(i)}_gate")(
input_list[i]
)
gate_dnn = tf.keras.layers.Dense(
fusion_expert_num, use_bias=False, activation="softmax"
)(gate_dnn)
gate_dnn = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(
gate_dnn
)
task_gate_list.append(gate_dnn)
cgc_output_list = []
for i in range(task_num):
cur_experts = task_expert_list[i] + shared_expert_list
expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1))(
cur_experts
)
cur_gate = task_gate_list[i]
task_gate_fusion_dnn = tf.keras.layers.Lambda(
lambda x: tf.reduce_sum(x[0] * x[1], axis=1, keepdims=False)
)(
[cur_gate, expert_concat]
)
cgc_output_list.append(task_gate_fusion_dnn)
if not is_last:
cur_experts = (
list(itertools.chain.from_iterable(task_expert_list)) + shared_expert_list
)
cur_expert_num = len(cur_experts)
expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1))(
cur_experts
)
shared_gate_dnn = DNNs(shared_gate_dnn_units, name=f"{leval_name}_shared_gate")(
input_list[-1]
)
shared_gate_dnn = tf.keras.layers.Dense(
cur_expert_num, use_bias=False, activation="softmax"
)(
shared_gate_dnn
)
shared_gate = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, -1))(
shared_gate_dnn
)
shared_gate_fusion_output = tf.keras.layers.Lambda(
lambda x: tf.reduce_sum(x[0] * x[1], axis=1, keepdims=False)
)([shared_gate, expert_concat])
cgc_output_list.append(shared_gate_fusion_output)
return cgc_output_list
def build_ple_model(feature_columns, model_config):
"""
构建PLE(渐进式分层提取)多任务排序模型。
参数:
feature_columns: FeatureColumn列表
model_config: 包含参数的字典:
- task_names: 列表,任务名称(默认["is_click"])
- ple_level_nums: 整数,PLE层数(默认1)
- task_expert_num: 整数,任务专用专家数量(默认4)
- shared_expert_num: 整数,共享专家数量(默认2)
- task_expert_dnn_units: 列表,任务专家DNN隐藏单元(默认[128, 64])
- shared_expert_dnn_units: 列表,共享专家DNN隐藏单元(默认[128, 64])
- task_gate_dnn_units: 列表,任务门控DNN隐藏单元(默认[128, 64])
- shared_gate_dnn_units: 列表,共享门控DNN隐藏单元(默认[128, 64])
- task_tower_dnn_units: 列表,任务塔DNN隐藏单元(默认[128, 64])
- dropout_rate: 浮点数,dropout率(默认0.1)
返回:
(model, None, None): 排序模型元组
"""
task_names = model_config.get("task_names", ["is_click"])
ple_level_nums = model_config.get("ple_level_nums", 1)
task_expert_num = model_config.get("task_expert_num", 4)
shared_expert_num = model_config.get("shared_expert_num", 2)
task_expert_dnn_units = model_config.get("task_expert_dnn_units", [128, 64])
shared_expert_dnn_units = model_config.get("shared_expert_dnn_units", [128, 64])
task_gate_dnn_units = model_config.get("task_gate_dnn_units", [128, 64])
shared_gate_dnn_units = model_config.get("shared_gate_dnn_units", [128, 64])
task_tower_dnn_units = model_config.get("task_tower_dnn_units", [128, 64])
dropout_rate = model_config.get("dropout_rate", 0.1)
input_layer_dict = build_input_layer(feature_columns)
group_embedding_feature_dict = build_group_feature_embedding_table_dict(
feature_columns, input_layer_dict, prefix="embedding/"
)
dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "ple")
task_num = len(task_names)
ple_input_list = [dnn_inputs] * (task_num + 1)
for i in range(ple_level_nums):
if i == ple_level_nums - 1:
cgc_output_list = cgc_net(
ple_input_list,
task_num,
task_expert_num,
shared_expert_num,
task_expert_dnn_units,
shared_expert_dnn_units,
task_gate_dnn_units,
shared_gate_dnn_units,
leval_name=f"cgc_level_{str(i)}",
is_last=True,
)
else:
cgc_output_list = cgc_net(
ple_input_list,
task_num,
task_expert_num,
shared_expert_num,
task_expert_dnn_units,
shared_expert_dnn_units,
task_gate_dnn_units,
shared_gate_dnn_units,
leval_name=f"cgc_level_{str(i)}",
is_last=False,
)
ple_input_list = cgc_output_list
task_output_list = []
for i in range(task_num):
task_output_logit = DNNs(
name=f"task_tower_{task_names[i]}",
units=task_tower_dnn_units + [1],
dropout_rate=dropout_rate,
)(cgc_output_list[i])
task_output_prob = PredictLayer(name=f"task_{task_names[i]}")(task_output_logit)
task_output_list.append(task_output_prob)
model = tf.keras.models.Model(
inputs=list(input_layer_dict.values()), outputs=task_output_list
)
return model, None, None
|
性能对比
1
2
3
4
5
6
7
8
9
| +----------------+----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+
| model | auc_is_click | auc_is_like | auc_long_view | auc_macro | gauc_is_click | gauc_is_like | gauc_long_view | gauc_macro | val_user_is_click | val_user_is_like | val_user_long_view |
+================+================+===============+=================+=============+=================+================+==================+==============+=====================+====================+======================+
| shared_bottom | 0.6002 | 0.4335 | 0.4455 | 0.4931 | 0.5734 | 0.4358 | 0.4514 | 0.4869 | 928 | 530 | 925 |
+----------------+----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+
| mmoe | 0.6018 | 0.4447 | 0.4323 | 0.4929 | 0.5736 | 0.4463 | 0.4595 | 0.4931 | 928 | 530 | 925 |
+----------------+----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+
| ple | 0.5928 | 0.42 | 0.4575 | 0.4901 | 0.5713 | 0.4438 | 0.4638 | 0.493 | 928 | 530 | 925 |
+----------------+----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+
|
2、任务依赖建模
前面介绍的多目标方法主要解决任务间的相关性冲突,但现实场景中任务间往往存在明确的依赖关系。用户行为具有天然的时序性:曝光→点击→转化,这种严格的依赖关系带来了新的挑战。
传统方法在处理这种依赖时面临两个核心问题:样本选择偏差(CVR模型在点击样本上训练,却要在全量样本上预测)和数据稀疏性(转化事件极其稀少)。
本节介绍两个全空间建模方法:ESMM解决经典的CTR-CVR联合建模问题,ESM2将思想扩展到更复杂的多阶段行为链路。
2.1 ESMM
原理
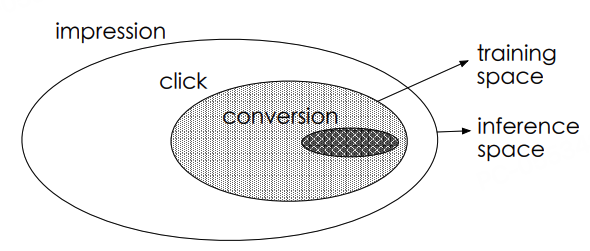
在推荐系统的用户行为链中,存在严格的时序依赖关系。以电商场景为例:
曝光(Impression)→点击(Click)→转化(Conversion)
这种链式结构导致两个关键问题:
-
样本选择偏差(Sample Selection Bias):传统CVR模型仅在点击样本(CTR正样本)上训练,但线上预估需覆盖全量曝光样本,训练/预估样本分布差异导致泛化能力下降
-
数据稀疏性(Data Sparsity):转化样本量 = 曝光量 × CTR × CVR,典型场景:CTR≈2%, CVR≈0.5% → 转化样本仅为曝光的万分之一,稀疏样本难以支撑复杂模型学习
ESMM (Entire Space Multi-task Model) 通过概率图约束重建任务关系:
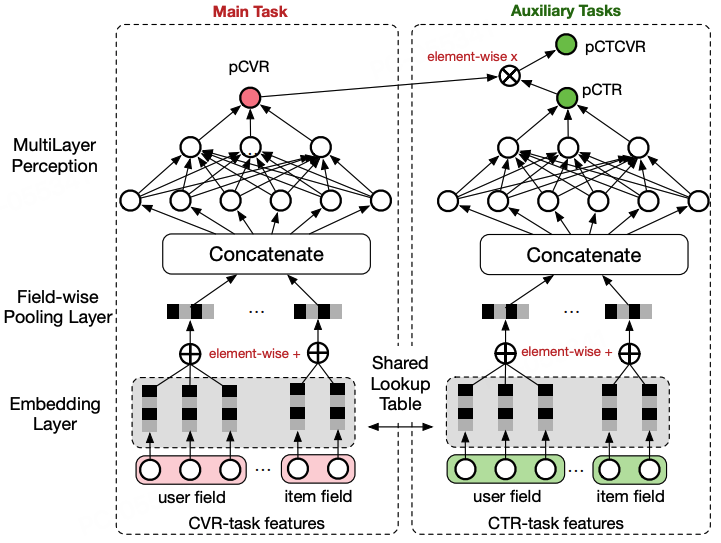
损失函数的设计:
L=LCTR+LCTCVR
其中:
- LCTR 是标准的二分类交叉熵损失,使用全量曝光样本:
LCTR=−N1i=1∑N[yiclicklog(pCTRi)+(1−yiclick)log(1−pCTRi)]
- LCTCVR 是CTCVR任务的交叉熵损失, 通过概率转化公式pCTCVR=pCTR×pCVR,使得CVR Tower的参数更新是在曝光空间下进行的:
LCTCVR=−N1i=1∑N[yiclick⋅yiconvlog(pCTCVRi)+(1−yiclick⋅yiconv)log(1−pCTCVRi)]
ESMM的核心创新在于CVR塔的梯度来源,CVR塔同时接收两种梯度:
∇CVR=全空间梯度∂pCTCVR∂LCTCVR⋅pCTR+共享层梯度∂h∂Lshared
代码
esmm.py 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import tensorflow as tf
from .utils import (
build_input_layer,
build_group_feature_embedding_table_dict,
concat_group_embedding,
)
from .layers import DNNs, PredictLayer
def build_esmm_model(feature_columns, model_config):
"""
构建ESMM(全空间多任务模型)排序模型。
参数:
feature_columns: FeatureColumn列表
model_config: 包含以下参数的字典:
- task_names: 列表,任务名称(默认 ["is_click", "is_like"])
- task_tower_dnn_units: 列表,任务塔DNN隐藏单元数(默认 [128, 64])
- dropout_rate: 浮点数,丢弃率(默认 0.1)
返回:
(model, None, None): 排序模型元组
"""
task_names = model_config.get("task_names", ["is_click", "is_like"])
task_tower_dnn_units = model_config.get("task_tower_dnn_units", [128, 64])
dropout_rate = model_config.get("dropout_rate", 0.1)
input_layer_dict = build_input_layer(feature_columns)
group_embedding_feature_dict = build_group_feature_embedding_table_dict(
feature_columns, input_layer_dict, prefix="embedding/"
)
dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "dnn")
ctr_output_logits = DNNs(
name="ctr_dnn", units=task_tower_dnn_units + [1], dropout_rate=dropout_rate
)(dnn_inputs)
cvr_output_logits = DNNs(
name="cvr_dnn", units=task_tower_dnn_units + [1], dropout_rate=dropout_rate
)(dnn_inputs)
ctr_output_prob = PredictLayer(name="ctr_output")(ctr_output_logits)
cvr_output_prob = PredictLayer(name="cvr_output")(cvr_output_logits)
ctcvr_output_prob = tf.keras.layers.Lambda(lambda x: tf.multiply(x[0], x[1]))(
[ctr_output_prob, cvr_output_prob]
)
model = tf.keras.models.Model(
inputs=list(input_layer_dict.values()),
outputs=[ctr_output_prob, ctcvr_output_prob],
)
return model, None, None
|
2.2 ESM2
原理
ESMM成功解决了曝光→点击→转化这一两阶段行为链路的样本偏差问题,但在真实工业场景中,用户行为链路往往更长更复杂。

如图所示,用户从曝光到转化可能会有非常多条的路径,例如 曝光->点击->加入购物车->购买、曝光->点击->加入许愿池->加入购物车->购买等。为了方便后续建模,对点击后的行为分解做了进一步的简化,将加入购物车、加入心愿单归并为决定行为(Deterministic Action,DAction),将其余行为归并为其他行为(Other Action,OAction)

为了更好理解后续建模时的数学表达,先对简化后图中的过程,做进一步的数学表示。
- y1=p(点击∣曝光)
- y2=p(决定行为∣点击)
- y3=p(购买∣决定行为)
- y4=p(购买∣其他行为)
根据上述定义,更便于理解ESM2模型的结构图:

ESM2模型有四个塔,分别用来预测上述的y1,y2,y3和y4,对于这四个塔的输出并不是算4个Loss,而是分别计算曝光->点击、曝光->决定行为和曝光->购买这三个Loss。可以很明显的看出,这三个Loss都是在曝光空间上计算的,和ESMM在曝光空间优化CVR有着异曲同工之处。下面对于上述的三个Loss做简单的介绍,下面的BCELoss表示的是二元交叉熵损失。
Lctr点击率预估损失:
Lctr=N1BCELoss(yisClicki,pCTRi)=N1BCELoss(yisClicki,y1i)
Lctavr点击且决定行为概率预估损失:
Lctavr=N1BCELoss(yisDActioni,pCTAVRi)=N1BCELoss(yisDActioni,y1i⋅y2i)
Lctcvr转化率预估损失:
Lctcvr=N1BCELoss(yisPurchusei,pCTCVRi)=N1BCELoss(yisPurchusei,y1i(y2i⋅y3i+(1−y2i)⋅y4i))
从简化后的用户下单链路图中可以看出,用户最终转化是有两条链路的,分别为:
合并上述两条链路的结果就可以得到pCTCVR=y1(y2⋅y3+(1−y2)⋅y4)
最终上述三个损失通过加权融合的方式进行联合优化,
Lfinal=wctr⋅Lctr+wctavr⋅Lctavr+wctcvr⋅Lctcvr
其中wctr,wctavr,wctcvr分别为三个损失的权重。
ESM2通过这种多阶段的概率乘积方式,将复杂的用户行为链路分解为多个可建模的子任务,同时确保每个任务都在曝光空间中进行联合优化。这种设计不仅有效解决了样本选择偏差问题,还通过共享底层特征表征,降低了数据稀疏性对模型性能的影响。更重要的是,ESM2提供了一种通用的建模思路,可以灵活扩展到更长的行为链路和更多样化的用户决策路径中。
性能
1
2
3
4
5
| +----------------+----------------+---------------+-------------+-----------------+----------------+--------------+---------------------+--------------------+
| model | auc_is_click | auc_is_like | auc_macro | gauc_is_click | gauc_is_like | gauc_macro | val_user_is_click | val_user_is_like |
+================+================+===============+=============+=================+================+==============+=====================+====================+
| esmm | 0.5983 | 0.6552 | 0.6267 | 0.5719 | 0.5811 | 0.5765 | 928 | 530 |
+----------------+----------------+---------------+-------------+-----------------+----------------+--------------+---------------------+--------------------+
|
3、多目标损失融合
多目标往往伴随着多个损失的联合优化,这类优化方法更多的考虑的是在模型结构已经确定的条件下,结合任务的特点对模型进行训练和参数优化。简单的多目标Loss优化,是通过手工结合业务经验设定不同损失的权重,将多个损失加权为一个进行优化,如下所示:
Losstotal=i∑wiLi
其中,Li和wi分别表示第i个任务的损失及对应的权重。
在多目标建模中,当模型结构确定后,损失函数融合策略成为决定模型性能的关键因素。传统的手工加权方法存在三个本质性缺陷:
-
量级失衡问题:不同任务的损失值量级差异显著(如CTR损失通常在0.1-0.5,CVR损失可达2.0+),导致大损失主导优化方向
-
收敛异步问题:稀疏任务收敛慢,密集任务收敛快,造成过拟合与欠拟合并存
-
梯度冲突问题:任务梯度方向不一致时产生抵消效应(如CTR与CTR任务梯度夹角>90°)
下面系统解析三大主流优化方法,包含理论框架、实现机制与工程实践。
3.1 Uncertainty Weight:基于不确定性的自适应加权
基于不确定性加权损失(Uncertainty Weighted Loss, UWL)。UWL的核心思想是根据任务的不确定性动态调整权重,具体来说,任务的损失越大,分配的权重越小。论文指出,在任务训练过程中存在两种不确定性:一种是认知不确定性(epistemic uncertainty),源于数据的缺乏;另一种是偶然不确定性(aleatoric uncertainty),源于数据本身或任务本身的特性。
在UWL中,任务的损失函数可以表示为:
Loss=≈2σ121L1(W)+σ221L2(W)+logσ1+logσ2
其中,σ表示的是任务的不确定性(uncertainty),是可学习的参数。从公式可以看出,当loss较大且σ较小时,2σ21L(W)会很大,损失函数在优化的时候就会将其往小了优化。可以直观的理解为,模型不会让任务往不确定性较大的方向大幅更新参数。
3.2 GradNorm:梯度标准化方法
在多任务优化的过程中,不同的任务loss的量级是不一样的,这样带来的问题就是loss大的任务梯度更新的幅度也会更大,进而导致模型在学习的过程中被loss大的任务主导带偏整个模型。此外,不同的任务由于数据分布的原因,loss的收敛速度也是不同的。为了同时考虑loss的量级和训练的速度。GradNorm在模型优化过程中除了正常的任务loss外,还引入了一个gradient loss,该loss通过梯度下降的方式来更新不同任务的loss权重。并且这两个loss是单独优化的,而不是简单的相加得到一个loss去综合优化。
在介绍gradient loss之前,我们先来看一下如何定义梯度的量级和loss的学习速度。
GW(i)(t)=∥∇Wwi(t)Li(t)∥2
GW(t)=Etask[GW(i)(t)]
其中W是所有任务loss对多个任务最后一层共享参数,GW(i)(t)表示任务i加权后的Loss,对共享参数W的梯度,该值较大时表示loss i当前的梯度量级较大,GW(t)表示所有任务对共享参数梯度的均值。
L~i(t~)=Li(t)/Li(0)
ri(t)=Etask[L~i(t)]L~i(t)
Li(t)表示的是训练的第t时刻,任务i的Loss值,所以L~i(t~)表示的是任务i在第t时刻的相对第0时刻的损失比率,该值如果越小的话则代表该任务loss收敛的比较快,训练速度较大。ri(t)则是在Li(t)的基础上做了一次归一化,让所有任务之间的速率相对可以比较,同样也是值越小表示任务的训练速度越快。
最终的梯度损失函数定义为如下表达式:
Lgrad(t;wi(t))=i∑GW(i)(t)−GW(t)×[ri(t)]α1
梯度损失函数综合了上述定义的梯度量级和学习速度,直观理解就是当某个loss的梯度非常大时,该loss的值也会较大进而会将该loss的权重降的更小,避免了梯度大的loss主导了模型的学习。同理当某个任务学习的速度较快时,即ri(t)较小,梯度loss也会变得更大,进而使得该loss的权重会变得更小,阻止某个任务过快的收敛。
3.3 Pareto Optimization:帕累托优化框架
在多任务学习中,当不同任务的梯度方向存在根本性冲突时(即优化任务A必然损害任务B),我们面临帕累托边界优化问题。传统加权平均方法在此场景下失效,需要专门的优化框架寻找帕累托最优解集:
θminL(θ)=θmin(L1(θ),L2(θ),...,LT(θ))
其中帕累托最优解定义为:不存在其他解能在不损害至少一个任务的情况下改进任一任务。
帕累托最优损失融合核心思想:
将多目标损失合并为加权和,并利用 KKT 条件动态调整权重,使优化方向指向帕累托前沿:
L(θ)=i=1∑KwiLi(θ)
其中 wi 为可学习的权重,满足 ∑wi=1 且 wi≥ci(ci 为权重下限)。
优化步骤(分两步迭代):
-
固定权重,更新模型参数 θ:通过梯度下降最小化加权损失 L(θ),即常规的模型训练步骤。
-
固定模型,更新权重 wi
- 目标:求解权重 wi,使加权梯度的二范数最小化(满足 KKT 条件):
wmini=1∑Kwi∇θLi(θ)22
- 约束条件: ∑wi=1,wi≥ci。
- 松弛与投影:
- 引入变量 w~i=wi−ci,将不等式约束转化为非负约束。
- 先忽略 w~i≥0,求解带等式约束的二次规划问题。
- 对解 w~∗ 进行投影,确保其非负性(投影问题可通过闭式解快速求解):
w~min∥w~−w~∗∥22s.t.∑w~i=1−∑ci,w~i≥0
PE-LTR的核心贡献在于将多目标优化的帕累托条件转化为权重学习的二次规划问题,通过交替更新模型参数与损失权重,引导模型收敛至帕累托前沿。
小结
多目标建模的发展历程反映了推荐系统从单一优化向协同优化的演进。早期的Shared-Bottom架构虽然简单,但任务间的负迁移问题促使了MMoE等专家混合模型的出现。随着业务复杂度提升,PLE进一步引入了专家分离机制,而STAR则通过拓扑结构优化解决了参数冗余问题。
在依赖关系建模方面,ESMM通过概率链式分解解决了样本选择偏差,ESM2则将这一思想扩展到更复杂的用户行为序列。这些方法的核心都是将复杂的多阶段问题转化为可建模的数学形式,从而实现端到端的联合优化。
损失融合优化则从另一个角度解决多目标冲突。无论是简单的加权求和,还是复杂的动态平衡策略,其本质都是在不同业务目标间寻找最优的权衡点。实践中,这往往需要结合具体的业务场景和数据特点来选择合适的融合策略。
多目标建模仍在快速发展中,但核心思想已经相对成熟:在共享与独立之间找到平衡,在效率与效果之间做出权衡。对于实际应用来说,选择合适的方法比追求最新的技术更重要。

 微信支付
微信支付 支付宝
支付宝