参考
精排(五)多场景建模
在现代大规模推荐系统中,用户的行为和兴趣往往呈现出高度的场景依赖性 。这里的“场景”可以指不同的业务形态(如电商APP的首页推荐、商品详情页的“猜你喜欢”、购物车页的“你可能还想要”)、不同的流量入口(如主站、独立子频道)、不同的用户状态(如新用户、老用户、活跃用户、沉默用户)、甚至不同的设备或时间上下文。传统的单一全局模型,试图用一个“万能”的模型覆盖所有场景,常常面临场景特性淹没 与数据稀疏性 的双重困境:
共性淹没特性: 强行融合所有场景数据训练,模型容易被数据量大的主导场景所主导,难以捕捉和适应小场景或特性鲜明场景的独特模式。数据稀疏性: 对于新场景、小流量场景或长尾用户群体,独立建模所需的高质量训练数据往往不足,导致模型效果不佳。参数效率低下: 为每个场景独立训练和维护一个完整模型,成本高昂且难以实现场景间的知识迁移。
多场景建模(Multi-scenario Modeling / Multi-domain Modeling) 正是为了解决这些核心挑战而提出的关键技术范式。其核心思想在于:充分利用多个场景数据之间的潜在“共性”来提升模型的泛化能力和鲁棒性,同时精细地识别和建模不同场景的“特性”差异,以实现场景间的差异化精准推荐。
简单来说,多场景建模的目标是:既要“合”得好(共享有益知识),也要“分”得清(保留独有特性) 。
实现这一目标的技术路径丰富多样,但根据其处理“共性”与“特性”的核心机制,大致可以归纳为以下两大类主流且互补的范式,这也是本章重点探讨的内容:
多塔结构建模范式:在模型结构层面进行显式划分,为共享的“共性”知识构建一个或多个 公共塔(Shared Tower) ,同时为每个场景(或场景组)的“特性”知识构建独立的场景塔(Scenario-Specific Tower) 。通过精心设计的结构(如门控网络、路由机制)来控制信息在不同塔之间的流动与融合。
动态权重建模范式:不依赖固定的模型结构划分,而是利用输入样本自身的 场景上下文信息 (如场景ID、用户在该场景的历史行为、场景属性特征等),动态地调整模型内部组件(如特征嵌入、网络权重、损失函数权重)的计算方式或重要性 。模型的核心结构可能是共享的,但其行为会根据当前场景上下文进行实时“微调”。
通过本章的学习,将掌握多场景建模的核心原理、主流技术路线及其演进逻辑,具备在实践中根据业务需求选择和设计合适的多场景推荐模型的能力,从而有效应对复杂多变的现实推荐环境,提升推荐系统在多样化场景下的整体性能和用户体验。
1、多塔结构
在多目标建模领域,如 MMoE 所展现的那样,专家网络(Expert)承担着挖掘不同任务之间共享的底层特征表示的重任,而门控网络(Gate)则灵活地动态分配专家权重,依据不同任务的特性需求进行精准适配。这种由 “共享专家 + 任务专属门控” 构成的架构,与生俱来地具备处理共性(共享专家所提取的通用特征)与特性(门控网络赋予的特定权重)的卓越能力。
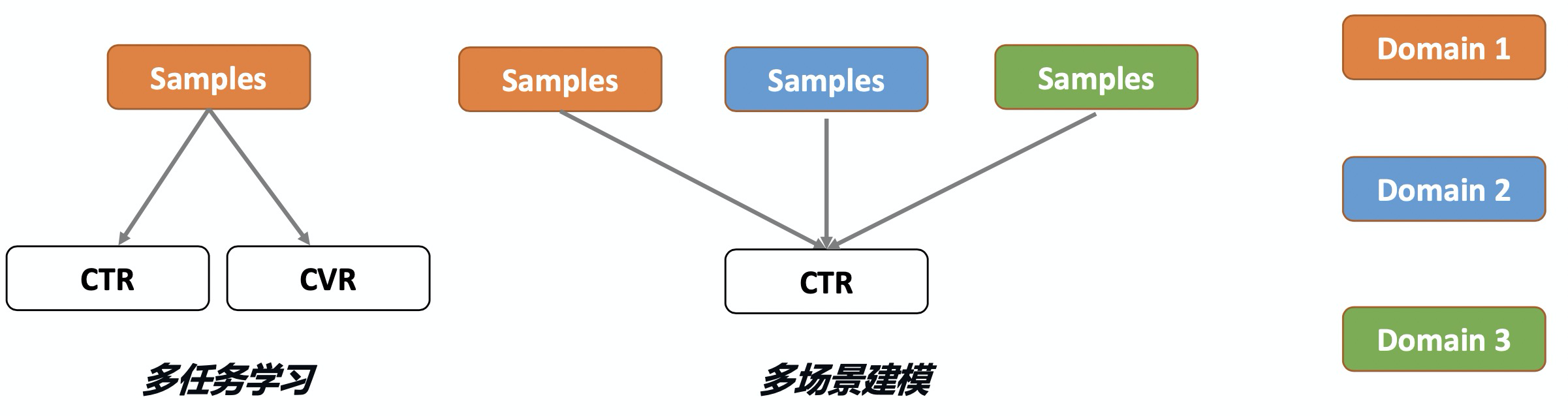
多场景建模与多任务学习类似但关注点不同:多任务学习处理相同场景/分布下的不同任务(如单样本同时预估CTR、CVR),而多场景建模处理不同场景/分布下的相同任务(如不同场景预估相同CTR)。前者是对于一条样本预估多个不同的目标值,后者是对于不同的样本预估相同的目标值。多场景建模若采用独立模型,会忽视场景共性,导致小场景效果差且资源消耗剧增;若混合样本训练单一模型,则会忽视场景差异,降低预测精度。
本小节将会介绍基于多塔结构建模时,在利用多场景共性的前提下,显示的使用不同场景的信号来捕捉场景的特性。
1.1 HMoE
原理
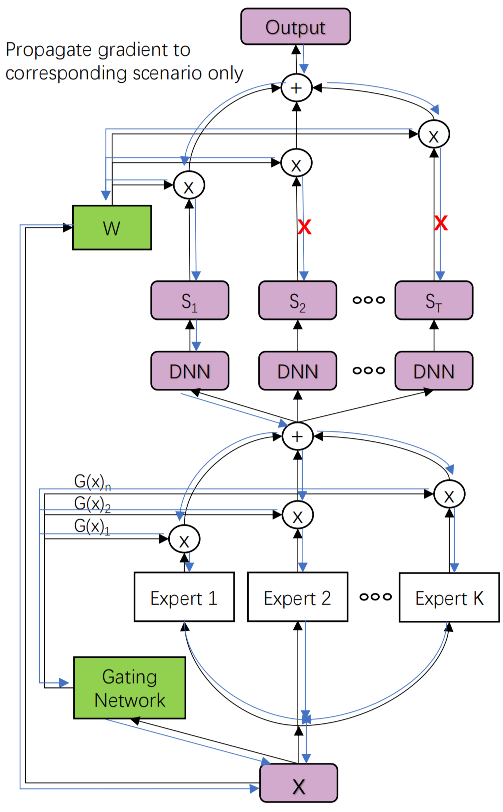
在多任务建模小节中,介绍了MMoE(Mixture-of-Experts)底层通过多专家网络作为多任务的共享特征,顶层对于不同的任务使用门控机制融合专家特征实现不同任务差异化的学习。在多场景建模中HMoE借鉴了MMoE的思路,底层同样适用多专家网络提取提取多个场景的特征作为共享特征,只不过顶层的多个塔不再是多个任务的输出,而是多个场景的输出,HMoE模型结构如下:
模型的底层使用多个专家抽取多个场景的特征,并通过一组门控网络将多个专家的输出结果进行融合,最后输入给上层不同的场景塔。
M ( x ) = ∑ i = 1 K G i ( x ) E i ( x ) M(x) = \sum_{i=1}^{K} G_i(x) E_i(x)
M ( x ) = i = 1 ∑ K G i ( x ) E i ( x )
原论文中是对于所有场景的塔都使用同一组门控融合后的专家特征,这种方式可以看成是多任务建模中的Shared-Bottom式的特征共享,只不过以多个FCN的融合输出替代了单个FCN的输出。从MMoE的经验来看,如果多个任务之间的相关性较差,底层这种特征硬共享可能会出现负迁移的现象。所以这种方式也不一定就是多场景建模的最优方案,也可以尝试对于不同的场景,使用不同门控融合后的专家特征。如第t t t M t ( x ) = ∑ i = 1 K G i t ( x ) E i ( x ) M_t(x) = \sum_{i=1}^{K} G_i^t(x) E_i(x) M t ( x ) = ∑ i = 1 K G i t ( x ) E i ( x )
在得到了底层多场景特征之后,模型单场景的最终预估值不是简单的直接使用对应场景Tower打分,而是将多个场景输出打分融合为单个场景的打分。第t t t
o u t t = ∑ i = 1 T W i ( x ) S i ( x ) out_t = \sum_{i=1}^{T} W_i(x) S_i(x)
o u t t = i = 1 ∑ T W i ( x ) S i ( x )
其中W i ( x ) W_i(x) W i ( x ) i i i W W W t t t o u t t = ∑ i = 1 T W i t ( x ) S i ( x ) out_t = \sum_{i=1}^{T} W_i^t(x) S_i(x) o u t t = ∑ i = 1 T W i t ( x ) S i ( x )
从最终单场景由多个场景打分融合可以看出,对于某个场景t t t t t t t t t t t t
虽然在前向推理时可以将一条样本预估出不同场景的打分,但是对于某个场景t t t a a a b b b t t t
o u t t ( x ) = W t ( x ) S t ( x ) + ∑ j = 1 , j ≠ t T W j ( x ) S j ( x ) ⏟ stop gradient out_t(x) = W_t(x) S_t(x) + \sum_{j=1, j \neq t}^{T} W_j(x) \underbrace{S_j(x)}_{\text{stop gradient}}
o u t t ( x ) = W t ( x ) S t ( x ) + j = 1 , j = t ∑ T W j ( x ) stop gradient S j ( x )
不共享融合权重的打分公式为:o u t t ( x ) = W t t ( x ) S t ( x ) + ∑ j = 1 , j ≠ t T W j t ( x ) S j ( x ) ⏟ stop gradient out_t(x) = W_t^t(x) S_t(x) + \sum_{j=1, j \neq t}^{T} W_j^t(x) \underbrace{S_j(x)}_{\text{stop gradient}} o u t t ( x ) = W t t ( x ) S t ( x ) + ∑ j = 1 , j = t T W j t ( x ) stop gradient S j ( x )
代码
hmoe.py 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 import tensorflow as tffrom .layers import DNNsfrom .utils import ( build_input_layer, build_group_feature_embedding_table_dict, concat_group_embedding, get_linear_logits, add_tensor_func, ) def build_hmoe_model (feature_columns, model_config ): """ 构建分层专家混合(HMoE)排序模型(多域CTR风格)。 参数: feature_columns: List[FeatureColumn] model_config: 包含以下配置的字典: - num_domains: int, 域的数量(默认: 5) - domain_feature_name: str, 域指示特征名称(默认: 'tab') - share_gate: bool, 门控是否在域间共享(默认: False) - share_domain_w: bool, 域权重是否共享(默认: False) - shared_expert_nums: int, 共享专家数量(默认: 5) - shared_expert_dnn_units: List[int], 专家MLP单元(默认: [256, 128]) - gate_dnn_units: List[int], 门控MLP单元(默认: [256, 128]) - domain_tower_units: List[int], 域塔单元(默认: [128, 64]) - domain_weight_units: List[int], 域权重网络单元(默认: [128, 64]) - linear_logits: bool, 添加线性项(默认: True) 返回: (model, None, None): FunRec流水线的排序模型元组 """ num_domains = model_config.get("num_domains" , 5 ) domain_feature_name = model_config.get("domain_feature_name" , "tab" ) share_gate = model_config.get("share_gate" , False ) share_domain_w = model_config.get("share_domain_w" , False ) shared_expert_nums = model_config.get("shared_expert_nums" , 5 ) shared_expert_dnn_units = model_config.get("shared_expert_dnn_units" , [256 , 128 ]) gate_dnn_units = model_config.get("gate_dnn_units" , [256 , 128 ]) domain_tower_units = model_config.get("domain_tower_units" , [128 , 64 ]) domain_weight_units = model_config.get("domain_weight_units" , [128 , 64 ]) use_linear_logits = model_config.get("linear_logits" , True ) input_layer_dict = build_input_layer(feature_columns) domain_input = input_layer_dict[domain_feature_name] if domain_input.dtype != tf.int32 and domain_input.dtype != tf.int64: domain_input = tf.keras.layers.Lambda( lambda x: tf.cast(tf.round (x), tf.int32), name="cast_domain_to_int" )(domain_input) group_embedding_feature_dict = build_group_feature_embedding_table_dict( feature_columns, input_layer_dict, prefix="embedding/" ) dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "dnn" ) expert_output_list = [] for i in range (shared_expert_nums): expert_output = DNNs(shared_expert_dnn_units, name=f"expert_{str (i)} " )( dnn_inputs ) expert_output_list.append(expert_output) expert_concat = tf.keras.layers.Lambda(lambda x: tf.stack(x, axis=1 ))( expert_output_list ) if share_gate: domain_tower_input_list = [] gate_output = DNNs(gate_dnn_units, name=f"shared_gates" )(dnn_inputs) gate_output = tf.keras.layers.Dense( shared_expert_nums, use_bias=False , activation="softmax" , name=f"domain_{i} _softmax" , )(gate_output) gate_output = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1 ))( gate_output ) gate_expert_output = tf.keras.layers.Lambda(lambda x: x[0 ] * x[1 ])( [gate_output, expert_concat] ) gate_expert_output = tf.keras.layers.Lambda( lambda x: tf.reduce_sum(x, axis=1 , keepdims=False ) )(gate_expert_output) for _ in range (num_domains): domain_tower_input_list.append(gate_expert_output) else : domain_tower_input_list = [] for i in range (num_domains): gate_output = DNNs(gate_dnn_units, name=f"domain_{str (i)} _gates" )( dnn_inputs ) gate_output = tf.keras.layers.Dense( shared_expert_nums, use_bias=False , activation="softmax" , name=f"domain_{i} _softmax" , )(gate_output) gate_output = tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1 ))( gate_output ) gate_expert_output = tf.keras.layers.Lambda(lambda x: x[0 ] * x[1 ])( [gate_output, expert_concat] ) gate_expert_output = tf.keras.layers.Lambda( lambda x: tf.reduce_sum(x, axis=1 , keepdims=False ) )(gate_expert_output) for _ in range (num_domains): domain_tower_input_list.append(gate_expert_output) domain_tower_output_list = [] for i in range (num_domains): domain_dnn_input = domain_tower_input_list[i] task_output = DNNs(domain_tower_units)(domain_dnn_input) domain_tower_output_list.append(task_output) domain_weight_list = [] if share_domain_w: domain_weight = DNNs(domain_weight_units)(dnn_inputs) for i in range (num_domains): domain_weight_list.append(domain_weight) else : for i in range (num_domains): domain_weight = DNNs(domain_weight_units)(dnn_inputs) domain_weight = tf.keras.layers.Lambda(lambda x: tf.nn.softmax(x, axis=1 ))( domain_weight ) domain_weight_list.append(domain_weight) domain_output_list = [] for i in range (num_domains): domain_weight = domain_weight_list[i] domain_tower_output = domain_tower_output_list[i] weighted_output = tf.keras.layers.Lambda(lambda x: x[0 ] * x[1 ])( [domain_weight, domain_tower_output] ) for j in range (num_domains): if i == j: continue grad_output = tf.keras.layers.Lambda(lambda x: tf.stop_gradient(x))( domain_tower_output_list[j] ) weighted_output = tf.keras.layers.Add()( [ weighted_output, tf.keras.layers.Multiply()( [domain_weight_list[i][:, j : j + 1 ], grad_output] ), ] ) dummy_domain = tf.keras.layers.Lambda( lambda x: tf.ones_like(x[0 ], dtype=tf.int32) * tf.cast(x[1 ], tf.int32) )([domain_input, i]) domain_mask = tf.keras.layers.Lambda( lambda x: tf.squeeze(tf.equal(x[0 ], x[1 ]), axis=-1 ) )([domain_input, dummy_domain]) domain_output = tf.keras.layers.Lambda(lambda x: tf.boolean_mask(x[0 ], x[1 ]))( [weighted_output, domain_mask] ) domain_output_list.append(domain_output) final_domain_output = tf.keras.layers.Concatenate(axis=0 )(domain_output_list) dnn_logit = tf.keras.layers.Dense(1 , activation=None , name="dnn_logits" )( final_domain_output ) if use_linear_logits: linear_logit = get_linear_logits(input_layer_dict, feature_columns) final_logit = add_tensor_func( [dnn_logit, linear_logit], name="hmoe_final_logit" ) else : final_logit = tf.keras.layers.Identity(name="hmoe_final_logit" )(dnn_logit) output = tf.keras.layers.Activation("sigmoid" , name="hmoe_output" )(final_logit) output = tf.keras.layers.Flatten()(output) model = tf.keras.Model(inputs=list (input_layer_dict.values()), outputs=output) return model, None , None
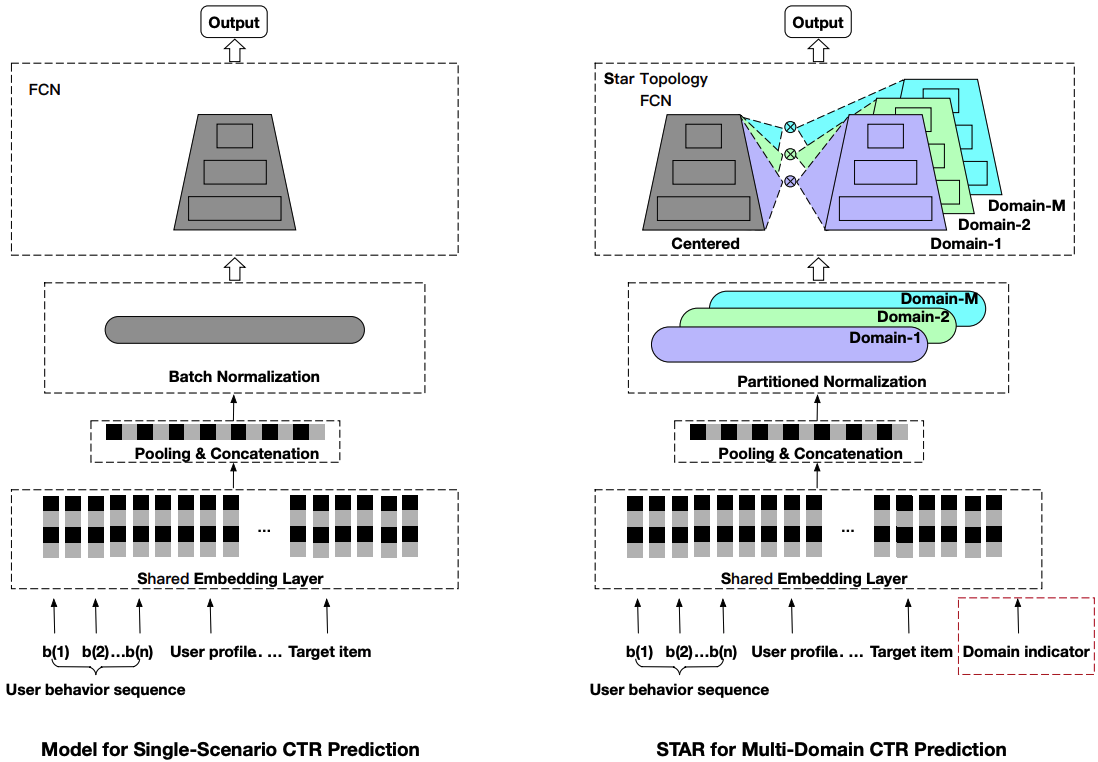
1.2 STAR
原理
STAR(Star Topology Adaptive Recommender)模型采用星型拓扑结构,实现场景私有参数和场景共享参数同时建模场景差异性和共性。场景私有参数以及场景共享参数最终聚合得到每个场景的模型。STAR结构如下图所示。
相比于单场景的模型,STAR有三个针对多场景建模的创新思路值得学习,分别是星型拓扑结构的全连接网络(STAR Topology Fully-Connected Network),Partitioned Normalization 以及辅助网络,下面将以此进行介绍。
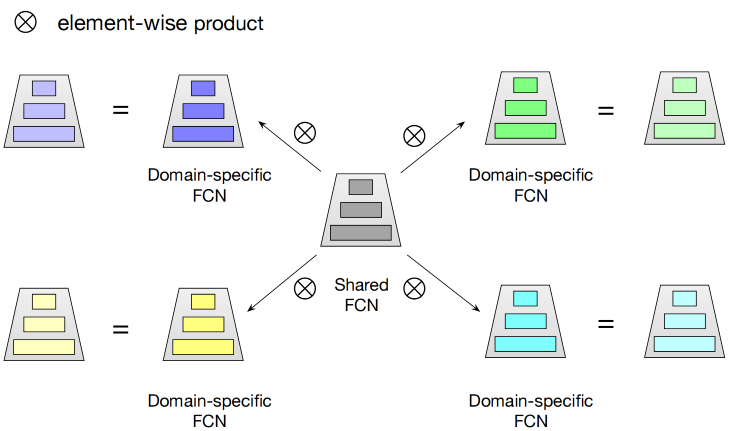
STAR Topology Fully-Connected Network
星形拓扑全连接结构的核心思想是对于每一个全连接网络(FCN)都有场景共享和场景独占的部分,每个场景最终的参数由共享和独占参数通过element-wise product融合计算得到。
具体而言,对于第p p p W p ⋆ , b p ⋆ W_p^{\star},b_p^{\star} W p ⋆ , b p ⋆
W p ⋆ = W p ⊗ W b p ⋆ = b p + b W_p^{\star} = W_p \otimes W \\
b_p^{\star} = b_p + b
W p ⋆ = W p ⊗ W b p ⋆ = b p + b
其中W p , W W_p,W W p , W p p p b p , b b_p,b b p , b
如果用i n p in_p i n p p p p o u t p out_p o u t p
o u t p = ϕ ( ( W p ⋆ ) ⊤ i n p + b p ⋆ ) , out_p = \phi((W_p^\star)^\top in_p + b_p^\star),
o u t p = ϕ (( W p ⋆ ) ⊤ i n p + b p ⋆ ) ,
其中ϕ \phi ϕ
Partitioned Normalization
在神经网络训练时,为了加快模型的收敛常会在模型中加入BN(Batch Normalization)。但是在多场景建模中,样本只在相同的场景内才满足独立同分布,多个场景混合的样本得到的统计量会忽略了不同场景独有的分布差异。为此应该让多场景中不同的场景独享统计量,这就是PN(Partitioned Normalization)提出的主要动机。
在介绍PN之前,先简单回顾一下经典的BN的原理:
z ′ = γ z − E V a r + ϵ + β \mathbf{z'} = \gamma \frac{\mathbf{z} - \mathbf{E}}{\sqrt{\mathrm{Var} + \epsilon}} + \beta
z ′ = γ Var + ϵ z − E + β
其中E , V a r \mathbf{E},\mathrm{Var} E , Var γ , β \gamma,\beta γ , β
PN相比BN来说,不仅可学习的缩放和平移参数包括场景共享和独占两部分的参数,统计的移动均值和方差也是在不同场景样本上得到的,具体表示如下:
z ′ = ( γ ∗ γ p ) z − E p V a r p + ϵ + ( β + β p ) \mathbf{z'} = (\gamma * \gamma_p) \frac{\mathbf{z} - \mathbf{E_p}}{\sqrt{\mathrm{Var_p} + \epsilon}} + (\beta + \beta_p)
z ′ = ( γ ∗ γ p ) Va r p + ϵ z − E p + ( β + β p )
其中γ , β \gamma,\beta γ , β γ p , β p \gamma_p,\beta_p γ p , β p E p , V a r p \mathbf{E_p},\mathrm{Var_p} E p , Va r p p p p
辅助网络
为了进一步加强场景特征对模型输出的影响,在STAR中还会单独构建一个场景的辅助网络(Auxiliary Network),辅助网络将场景特征和其他特征共同输入到浅层网络中得到一个辅助的Logits,最终和主网络的Logits相加计算得到最终的CTR预估值:
p C T R = S i g m o i d ( L o g i t s m a i n + L o g i t s a u x ) pCTR = Sigmoid(Logits_{main} + Logits_{aux})
pCTR = S i g m o i d ( L o g i t s main + L o g i t s a ux )
代码
star.py 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 import tensorflow as tffrom .utils import ( build_input_layer, build_group_feature_embedding_table_dict, concat_group_embedding, add_tensor_func, get_linear_logits, concat_func, ) from .layers import ( DNNs, PredictLayer, PartitionedNormalization, StarTopologyFCN, ) def build_star_model (feature_columns, model_config ): """ 为FunRec构建STAR(星形拓扑自适应推荐器)排序模型。 Args: feature_columns: FeatureColumn列表 model_config: 包含参数的字典: - num_domains: 整数,域的数量 - domain_feature_name: 字符串,域指示特征名称 - star_dnn_units: 列表,STAR FCN隐藏单元 (默认 [128, 64]) - aux_dnn_units: 列表,辅助DNN隐藏单元 (默认 [128, 64]) - star_fcn_activation: 字符串,STAR FCN的激活函数 (默认 'relu') - dropout: 浮点数,dropout率 (默认 0.2) - l2_reg: 浮点数,L2正则化 (默认 1e-5) - linear_logits: 布尔值,是否添加线性项 (默认 False) Returns: (model, None, None): 排序模型元组 """ num_domains = model_config.get("num_domains" , 5 ) domain_feature_name = model_config.get("domain_feature_name" , "tab" ) star_dnn_units = model_config.get("star_dnn_units" , [128 , 64 ]) aux_dnn_units = model_config.get("aux_dnn_units" , [128 , 64 ]) star_fcn_activation = model_config.get("star_fcn_activation" , "relu" ) dropout = model_config.get("dropout" , 0.2 ) l2_reg = model_config.get("l2_reg" , 1e-5 ) linear_logits = model_config.get("linear_logits" , False ) input_layer_dict = build_input_layer(feature_columns) domain_input = input_layer_dict[domain_feature_name] group_embedding_feature_dict = build_group_feature_embedding_table_dict( feature_columns, input_layer_dict, prefix="embedding/" ) domain_embeddings = concat_group_embedding(group_embedding_feature_dict, "domain" ) dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "dnn" ) fcn_inputs = PartitionedNormalization(num_domain=num_domains, name="fcn_pn_layer" )( [dnn_inputs, domain_input] ) fcn_output = StarTopologyFCN( num_domains, star_dnn_units, star_fcn_activation, dropout, l2_reg, name="star_fcn_layer" , )([fcn_inputs, domain_input]) fcn_logit = PredictLayer(activation=None , name="fcn_logits" )(fcn_output) aux_inputs = concat_func([domain_embeddings, dnn_inputs], axis=-1 ) aux_inputs = PartitionedNormalization(num_domain=num_domains, name="aux_pn_layer" )( [aux_inputs, domain_input] ) aux_output = DNNs(aux_dnn_units, dropout_rate=dropout)(aux_inputs) aux_logit = PredictLayer(activation=None , name="aux_logits" )(aux_output) if linear_logits: linear_logits = get_linear_logits(input_layer_dict, feature_columns) final_logits = add_tensor_func([linear_logits, fcn_logit, aux_logit]) else : final_logits = add_tensor_func([fcn_logit, aux_logit]) final_logits = tf.keras.layers.Flatten(name="star_logits_flat" )(final_logits) final_prediction = tf.keras.layers.Dense( 1 , activation="sigmoid" , name="star_output" )(final_logits) final_prediction = tf.keras.layers.Flatten(name="star_output_flat" )( final_prediction ) model = tf.keras.Model( inputs=list (input_layer_dict.values()), outputs=final_prediction ) return model, None , None
性能对比
1 2 3 4 5 6 7 +--------+--------+--------+------------+ | model | auc | gauc | val_user | +========+========+========+============+ | hmoe | 0.5972 | 0.5471 | 217 | +--------+--------+--------+------------+ | star | 0.6648 | 0.6244 | 693 | +--------+--------+--------+------------+
2、动态权重建模
在前一小节,我们探讨了 HMoE 和 STAR 这类基于多塔结构的多场景建模方案。它们通过为不同场景构建独立的“专家”网络或塔底参数,有效地捕获了场景间的特异性信息,解决了模型在跨场景迁移时因参数冲突导致的性能下降问题。这类模型的核心思想是“分而治之”,通过物理隔离的参数空间来保障场景的独特性。
为了在保持模型参数高效共享的同时,实现更细粒度、更灵活的场景感知能力,研究者们提出了“动态权重建模”的新范式。 这类方法的核心理念不再是构建物理隔离的参数塔,而是让模型的核心网络参数在不同场景下共享一个基础,但通过动态生成的、与场景/样本高度相关的“权重”来调制(Modulate)这些共享参数的行为。这相当于为共享网络“注入”了场景和样本的上下文信息,使其能够根据当前上下文动态调整其计算逻辑。
本节将重点介绍几种具有代表性的动态权重建模方案,它们展示了如何巧妙地设计“权重生成器”来调制共享网络。它们通过引入动态性,在参数效率、灵活性和性能之间取得了更优的平衡,为构建更加智能、自适应的多场景推荐系统提供了有力工具。
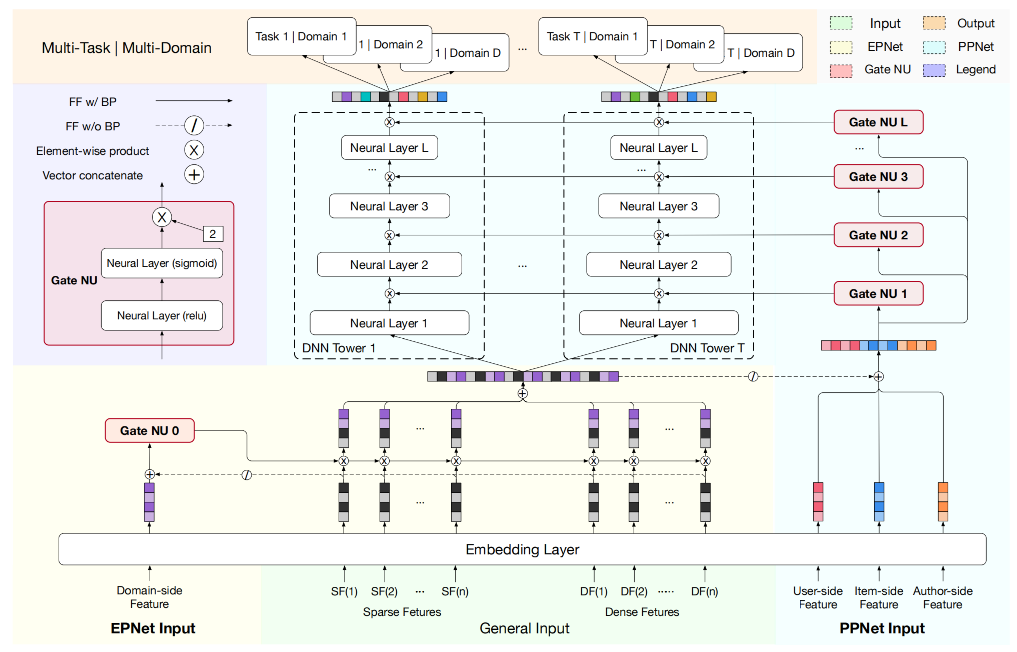
2.1 PEPNET
PEPNet(Parameter and Embedding Personalized Network)核心目标是解决多场景多任务中的双重跷跷板效应(Double Seesaw Phenomenon)。
场景跷跷板(Domain Seesaw):混合训练时不同场景数据分布差异导致表征无法对齐;
任务跷跷板(Task Seesaw):多任务间稀疏性与依赖关系失衡导致目标相互抑制;
PEPNet通过两大模块实现动态权重调控,形成“底层场景适配 + 顶层任务适配”的分层个性化,这也是PEPNet实现参数个性化的核心思路,PEPNet模型结构如下:
在介绍PEPNet的量大核心组件之前,需要先简单介绍一个通过模块Gate NU,EPNet与PPNet均基于轻量级门控单元Gate NU构建,以极低参数量实现参数个性化,Gate NU受语音识别领域LHUC模型启发,通过两层网络生成动态缩放权重:
x ′ = ReLU ( x W 1 + b 1 ) δ = γ ⋅ Sigmoid ( x ′ W 2 + b 2 ) ∈ [ 0 , γ ] \begin{aligned}
&\mathbf{x'} = \text{ReLU}(\mathbf{x} \mathbf{W_1} + \mathbf{b_1}) \\
&\delta = \gamma \cdot \text{Sigmoid}(\mathbf{x'} \mathbf{W_2} + \mathbf{b_2}) \quad \in [0, \gamma]
\end{aligned}
x ′ = ReLU ( x W 1 + b 1 ) δ = γ ⋅ Sigmoid ( x ′ W 2 + b 2 ) ∈ [ 0 , γ ]
其中x \mathbf{x} x γ \gamma γ δ \boldsymbol{\delta} δ ⊗ \otimes ⊗
EPNet:场景感知的嵌入个性化
在实际的推荐模型中,特征Embedding层的参数量往往是最大的,共享底层Embedding也成为了业界标准的做法。但在多场景建模中,这种底层共享的机制更多的强调的是不同场景之间的共性,忽略了不同场景下Embedding的差异性。为此EPNet在Embedding层的基础上,将场景先验信息通过门控机制的方式以较低的参数量实现Embedding层的场景个性化。
EPNet 中Embedding层的门控单元U e p U_{ep} U e p E E E E ( F d ) E(\mathcal{F}_d) E ( F d ) δ d o m a i n \delta_{domain} δ d o main
δ d o m a i n = U e p ( E ( F d ) ⊕ ( ⊘ ( E ) ) ) , \delta_{domain} = \mathcal{U}_{ep}(E(\mathcal{F}_d) \oplus (\oslash(E))),
δ d o main = U e p ( E ( F d ) ⊕ ( ⊘ ( E ))) ,
其中,U e p U_{ep} U e p
为了让场景感知的个性化模块EPNet不影响底层共享Embedding的学习,在计算个性化门控结果时让共享Embedding层的梯度不反向传播,⊘ \oslash ⊘
然后,通过元素级乘积得到场景个性化的Embedding表征O e p O_{ep} O e p
O e p = δ d o m a i n ⊗ E O_{ep} = \delta_{domain} \otimes E
O e p = δ d o main ⊗ E
通过将场景个性化先验信息整合到Embedding层中,EPNet可以有效地平衡多场景之间的共性和差异。
PPNet:用户感知的参数个性化
EPNet解决的是多场景跷跷板问题,PPNet则更多考虑的是多任务之间的跷跷板。相比MMOE,PLE等其他多任务模型是任务级的个性化而言,PPNet则可以看成是样本粒度的个性化。PEPNet将用户ID、内容ID及作者ID作为个性化的先验特征,同时拼接上述EPNet得到的场景个性化的Embedding O e p O_{ep} O e p U p p U_{pp} U pp
O p r i o r = E ( F u ) ⊕ E ( F i ) ⊕ E ( F a ) δ t a s k = U p p ( O p r i o r ⊕ ( ⊙ ( O e p ) ) ) O_{prior} = E(F_u) \oplus E(F_i) \oplus E(F_a) \\
\delta_{task} = \mathcal{U} _ {pp} (O_{prior} \oplus ( \odot (O_{ep} )))
O p r i or = E ( F u ) ⊕ E ( F i ) ⊕ E ( F a ) δ t a s k = U pp ( O p r i or ⊕ ( ⊙ ( O e p )))
为了防止PPNet模块影响到EPNet的参数更新,在计算δ t a s k \delta_{task} δ t a s k O e p O_{ep} O e p δ t a s k \delta_{task} δ t a s k
在得到了用户个性化的门控结果后,将其应用在所有任务塔中每个DNN网络上,从模型的结构图中可以看出不同任务塔中DNN的个性化门控是共享一份的,对于某个task的第l l l
O p p ( l ) = δ t a s k ( l ) ⊗ H ( l ) H ( l + 1 ) = f ( O p p ( l ) W ( l ) + b ( l ) ) , l ∈ { 1 , … , L } \begin{aligned}
\mathbf{O}^{(l)}_{pp} &= \delta^{(l)}_{task} \otimes \mathbf{H}^{(l)} \\
\mathbf{H}^{(l+1)} &= f\left( \mathbf{O}^{(l)}_{pp} \mathbf{W}^{(l)} + \mathbf{b}^{(l)} \right), l \in \{1, \ldots, L\}
\end{aligned}
O pp ( l ) H ( l + 1 ) = δ t a s k ( l ) ⊗ H ( l ) = f ( O pp ( l ) W ( l ) + b ( l ) ) , l ∈ { 1 , … , L }
其中,L L L H ( l ) \mathbf{H}^{(l)} H ( l ) l l l l + 1 l+1 l + 1 O p p ( l ) \mathbf{O}^{(l)}_{pp} O pp ( l ) l l l δ t a s k \delta_{task} δ t a s k
代码
pepnet.py 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 import tensorflow as tffrom .layers import EPNet, PPNet, PredictLayerfrom .utils import ( build_input_layer, build_group_feature_embedding_table_dict, concat_group_embedding, add_tensor_func, get_linear_logits, ) def build_pepnet_model (feature_columns, model_config ): """构建PEPNet排序模型并遵循FunRec接口约定 Args: feature_columns: 特征列配置 model_config: 模型参数配置,包含: - task_names: 任务名称列表(默认 ["is_click", "long_view", "is_like"]) - pepnet_dnn_units: PPNet中DNN层的隐藏单元数量(默认 [128, 64]) - pepnet_activation: PPNet中DNN层的激活函数(默认 'relu') - pepnet_dropout: PPNet中的dropout比例(默认 0.1) - l2_reg: L2正则化系数(默认 1e-5) - linear_logits: 是否加上线性项(默认 False) Returns: (model, None, None): 排序模型返回单一主模型 """ task_name_list = model_config.get( "task_names" , ["is_click" , "long_view" , "is_like" ] ) pepnet_dnn_units = model_config.get("pepnet_dnn_units" , [128 , 64 ]) pepnet_activation = model_config.get("pepnet_activation" , "relu" ) pepnet_dropout = model_config.get("pepnet_dropout" , 0.1 ) l2_reg = model_config.get("l2_reg" , 1e-5 ) linear_logits = model_config.get("linear_logits" , False ) input_layer_dict = build_input_layer(feature_columns) group_embedding_feature_dict = build_group_feature_embedding_table_dict( feature_columns, input_layer_dict, prefix="embedding/" ) epnet_inputs = concat_group_embedding(group_embedding_feature_dict, "epnet" ) pepnet_inputs = concat_group_embedding(group_embedding_feature_dict, "pepnet" ) dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "dnn" ) epnet = EPNet(l2_reg, name="dnn/epnet" ) ppnet = PPNet( len (task_name_list), pepnet_dnn_units, pepnet_activation, pepnet_dropout, l2_reg, name="dnn/ppnet" , ) ep_emb = epnet([epnet_inputs, dnn_inputs]) pp_output = ppnet([ep_emb, pepnet_inputs]) if linear_logits: linear_logits = get_linear_logits(input_layer_dict, feature_columns) pp_output_logits = [] for pp in pp_output: ppout_logit = tf.keras.layers.Dense(1 , use_bias=False )(pp) task_logit = add_tensor_func([linear_logits, ppout_logit]) pp_output_logits.append(task_logit) pp_output = pp_output_logits output_list = [] for i, task_name in enumerate (task_name_list): prediction = PredictLayer(name=task_name)(pp_output[i]) output_list.append(prediction) model = tf.keras.Model(inputs=list (input_layer_dict.values()), outputs=output_list) return model, None , None
2.2 APG
原理
在上一小节中,介绍了PEPNet通过场景/个性化的先验信号作为门控网络的输入,然后将门控网络的输出作用在底层Embedding和多目标塔的DNN层上,分别实现了基于门控的场景和多任务塔参数的个性化。本节将要介绍的APG模型同样希望实现样本粒度的个性化,但是做法却与PEPNet不太相同。APG的核心思想是为不同的样本动态生成模型参数,根据样本的不同生成相应的参数,从而提升模型的容量和表达能力。
APG通过样本感知的输入 来生成自适应参数,这种方式可以应用在大多数的混合样本分布建模的问题中,多场景建模也不例外。具体来说,它提出了三种策略来生成样本的条件表示
Group-wise策略,适用于样本可以被分组成不同Group的情况,同一Group内的样本具有相似的模式,此时可以将Group相关特征作为输入
Mix-wise策略,将多种因素考虑进来生成,能够实现更细粒度的样本组划分,甚至可以做到 “千样本千模型”,如将<user, item> pair向量作为输入。
Self-wise策略,不需要先验知识的输入,直接将Deep CTR Models的隐层输出作为参数生成的输入。
在APG中通过MLP来自适应生成参数,将需要感知样本的输入z i \mathbf{z_i} z i
W i = reshape ( MLP ( z i ) ) \mathbf{W}_i = \text{reshape}(\text{MLP}( \mathbf{z}_i ))
W i = reshape ( MLP ( z i ))
生成的参数矩阵,等价于MLP网络中的参数矩阵,通过矩阵乘法和激活函数实现和MLP一样的功能,如点击率模型的预估可以表示如下:
y i = σ ( W i x i ) y_i = \sigma(\mathbf{W}_i \mathbf{x}_i)
y i = σ ( W i x i )
APG的核心思想比较简单,但要实际的上生产还需要经过一些优化。
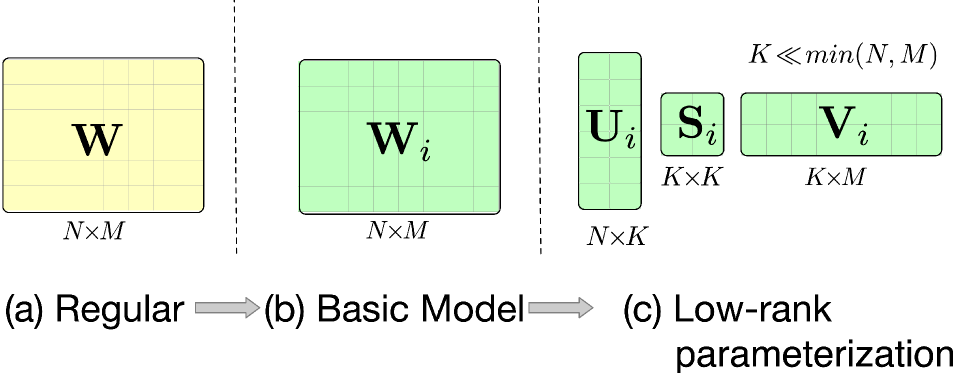
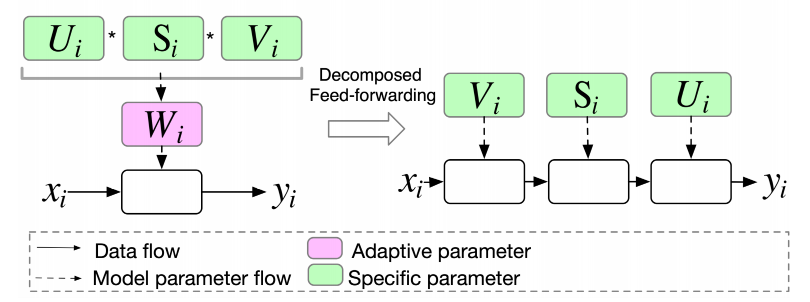
低质参数优化 :借鉴低秩相关方法,APG假设自适应参数存在低秩关系,将参数矩阵分解成三个子矩阵相乘的形式。通过设置较小的秩值,可以有效控制计算和存储开销,同时在需要时也可以通过增大秩值来增加参数空间,参数分解表达式如下:
U i , S i , V i = reshape ( MLP ( z i ) ) \mathbf{U}_i, \mathbf{S}_i, \mathbf{V}_i = \text{reshape}(\text{MLP}( \mathbf{z}_i ))
U i , S i , V i = reshape ( MLP ( z i ))
分解前向计算 :在低秩参数化的基础上,APG设计了一种分解前向计算的方式,让输入依次乘以各个子矩阵。这种方式避免了计算开销较大的子矩阵乘操作,降低了整体的计算复杂度,
y i = σ ( W i x i ) = σ ( ( U i S i V i ) x i ) = σ ( U i ( S i ( V i x i ) ) ) y_i = \sigma(\mathbf{W}_i \mathbf{x}_i) = \sigma((\mathbf{U}_i \mathbf{S}_i \mathbf{V}_i) \mathbf{x}_i) = \sigma(\mathbf{U}_i (\mathbf{S}_i (\mathbf{V}_i \mathbf{x}_i)))
y i = σ ( W i x i ) = σ (( U i S i V i ) x i ) = σ ( U i ( S i ( V i x i )))
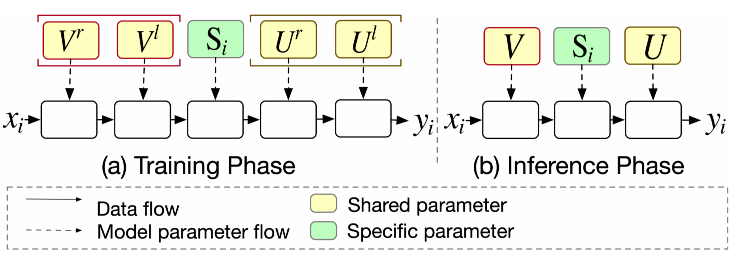
参数共享和过参数化 :得益于矩阵分解带来的灵活性,APG将参数矩阵分为私有参数和共享参数两类。私有参数用于刻画不同样本的特性,共享参数则用于刻画样本共性。通过这种划分,APG在生成自适应参数的同时,也保留了对样本共性的表达,丰富了模型的表达能力。而且,由于私有参数规模的缩减,整体的计算和存储开销也得到了降低。此外,APG 将共享参数替代为两个大矩阵,这种设计不仅可以增加参数数量来提升模型容量,还具有隐含的正则效果,有助于防止过拟合。
S i = reshape ( MLP ( z i ) ) U = U l U r , V = V l V r y i = σ ( U ( S i V x i ) ) \mathbf{S}_{i}=\text{reshape}(\text{MLP}(\mathbf{z}_{i})) \\
\mathbf{U} = \mathbf{U}^l \mathbf{U}^r, \mathbf{V} = \mathbf{V}^l \mathbf{V}^r \\
y_{i}=\sigma(\mathbf{U}(\mathbf{S}_{i}\mathbf{V}\mathbf{x}_{i}))
S i = reshape ( MLP ( z i )) U = U l U r , V = V l V r y i = σ ( U ( S i V x i ))
代码
apg.py 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import tensorflow as tffrom .layers import APGLayer, PredictLayerfrom .utils import ( build_input_layer, build_group_feature_embedding_table_dict, concat_group_embedding, get_linear_logits, ) def build_apg_model (feature_columns, model_config ): """按照FunRec约定构建APG排序模型。 参数: feature_columns: FeatureColumn列表 model_config: 字典,支持以下键: - task_names: 任务名称列表 (默认 ["is_click"]) - scene_group_name: 提供场景嵌入的场景组名称 (例如 'domain') - apg_dnn_units: APG层隐藏单元列表 (默认 [256, 128]) - scene_emb_dim: 场景嵌入维度 (未使用;从嵌入中推导) - activation: APG内部/输出激活函数 (默认 'relu') - dropout: 每个APG层后的dropout (默认 0.2) - l2_reg: l2正则化 (保留) - use_uv_shared: bool,使用UV共享权重 (默认 True) - use_mf_p: bool,启用P路径因子分解 (默认 True) - mf_k: int,K路径因子分割因子 (默认 4) - mf_p: int,P路径因子分割因子 (默认 4) - linear_logits: bool,添加线性项 (默认 False) 返回: (model, None, None) """ task_name_list = model_config.get("task_names" , ["is_click" ]) scene_group_name = model_config.get("scene_group_name" , "domain" ) apg_dnn_units = model_config.get("apg_dnn_units" , [256 , 128 ]) scene_emb_dim = model_config.get("scene_emb_dim" , 8 ) activation = model_config.get("activation" , "relu" ) dropout = model_config.get("dropout" , 0.2 ) l2_reg = model_config.get("l2_reg" , 1e-5 ) use_uv_shared = model_config.get("use_uv_shared" , True ) use_mf_p = model_config.get("use_mf_p" , True ) mf_k = model_config.get("mf_k" , 4 ) mf_p = model_config.get("mf_p" , 4 ) linear_logits = model_config.get("linear_logits" , False ) input_layer_dict = build_input_layer(feature_columns) group_embedding_feature_dict = build_group_feature_embedding_table_dict( feature_columns, input_layer_dict, prefix="embedding/" ) dnn_inputs = concat_group_embedding(group_embedding_feature_dict, "dnn" ) if scene_group_name not in group_embedding_feature_dict: raise ValueError(f"在特征组中未找到scene_group_name '{scene_group_name} '" ) scene_group_list = group_embedding_feature_dict[scene_group_name] if isinstance (scene_group_list, dict ): scene_tensor = next (iter (scene_group_list.values())) else : scene_tensor = scene_group_list[0 ] scene_emb = tf.keras.layers.Lambda(lambda x: tf.squeeze(x, axis=1 ))(scene_tensor) input_dim = dnn_inputs.shape[-1 ] x = dnn_inputs for i, units in enumerate (apg_dnn_units): x = APGLayer( input_dim=input_dim, output_dim=units, scene_emb_dim=scene_emb_dim, activation=activation, use_uv_shared=use_uv_shared, use_mf_p=use_mf_p, mf_k=mf_k, mf_p=mf_p, name=f"apg_layer_{i} " , )([x, scene_emb]) if dropout and dropout > 0 : x = tf.keras.layers.Dropout(dropout)(x) input_dim = units linear_logits_tensor = None if linear_logits: linear_logits_tensor = get_linear_logits(input_layer_dict, feature_columns) task_outputs = [] for i, task_name in enumerate (task_name_list): task_logit = tf.keras.layers.Dense( 1 , use_bias=False , name=f"task_{task_name} _logit" )(x) if linear_logits and linear_logits_tensor is not None : task_logit = tf.keras.layers.Add()([task_logit, linear_logits_tensor]) output = PredictLayer(name=task_name)(task_logit) task_outputs.append(output) model = tf.keras.Model(inputs=list (input_layer_dict.values()), outputs=task_outputs) return model, None , None
2.3 M2M
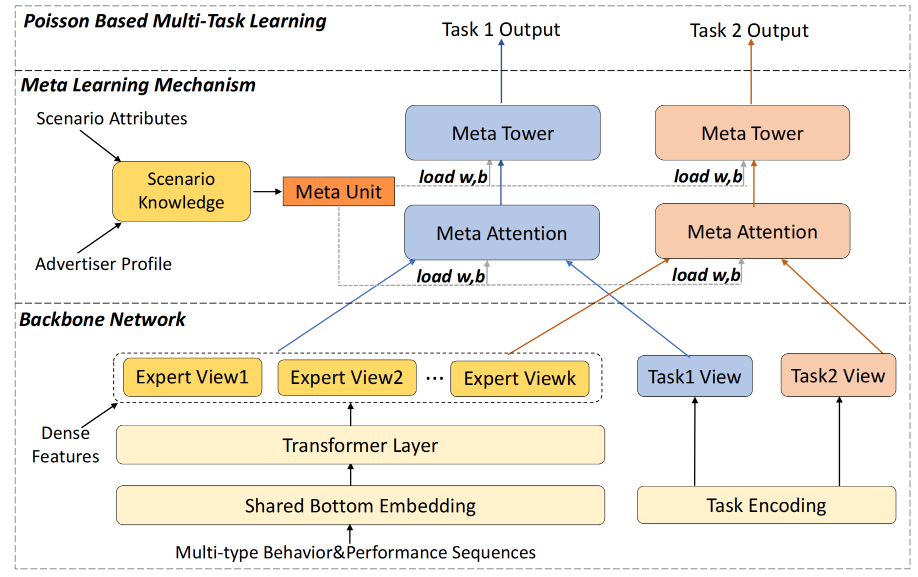
在推荐系统的多场景建模中,动态参数生成技术展现出了巨大的潜力。除了 APG 模型外,基于元学习的多场景多任务商家建模(M2M)是另一个在该领域具有重要影响的模型。M2M模型结构中主要包含底层的主干网络和顶层的元学习网络,下面将分别展开详细的介绍。
主干网络
主干网络中包括三部分内容:专家信息表征E i E_i E i T t T_t T t S ~ \tilde{\mathbf{S}} S ~
专家信息表征 :主干网络中有一个多专家的网络结构,每个专家输入的特征是将序列特征和其他特征拼接后的结果,而序列特征都由多头注意力机制进行聚合,第i i i
E i = f M L P ( Concat ( X s e q , X o t h e r ) ) \begin{aligned}
\mathbf{E}_i = f_{MLP}(\text{Concat}(X_{seq}, X_{other}))
\end{aligned}
E i = f M L P ( Concat ( X se q , X o t h er ))
其中,X s e q , X o t h e r X_{seq},X_{other} X se q , X o t h er f M L P f_{MLP} f M L P M A H MAH M A H
任务信息表征 : 为了更好的表达不同任务的差异性,M2M将不同类别的任务进行全局表征,也就是对于每一条样本都会有对应多个任务表征特征。第t个任务对应的特征表征的数学形式:
T t = f M L P ( Embedding ( t ) ) \mathbf{T}_t = f_{MLP}(\text{Embedding}(t))
T t = f M L P ( Embedding ( t ))
场景信息表征 :与任务信息表征类似,为了更好的表达场景之间的差异性,通过MLP网络对场景信息进行单独的表征,其输入的信息不仅包括了直接与场景相关的特征S S S A A A S ~ \tilde{\mathbf{S}} S ~
S ~ = f M L P ( S , A ) \tilde{\mathbf{S}} = f_{MLP}(\mathbf{S}, \mathbf{A})
S ~ = f M L P ( S , A )
与任务信息表征不同的是,每条样本都有所属的场景,所以场景表达并不是全局的,此外由于该方法最早提出来是为了解决广告业务的,在实际的应用场景中,我们也可以将广告主相关的特征替换成我们业务中更合适的特征。
元学习网络
在传统的机器学习中,权重( W , b ) (W, b) ( W , b ) ( W , b ) (W, b) ( W , b )
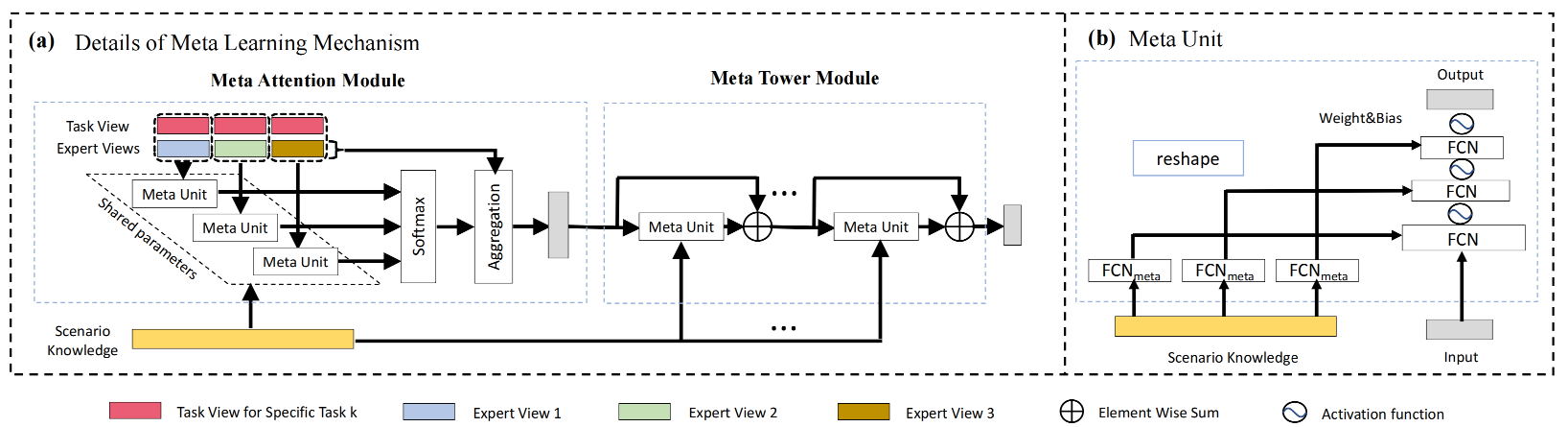
元学习单元原理 S ~ \tilde{\mathbf{S}} S ~ S ~ \tilde{\mathbf{S}} S ~ ( W , b ) (W,b) ( W , b ) M e t a Meta M e t a
h o u t p u t = Meta ( h i n p u t ) , h^{output} = \text{Meta}(h^{input}),
h o u tp u t = Meta ( h in p u t ) ,
其中,元学习单元处理的过程如下:
输入: 场景信息表征 S ~ , 输入特征 h input 输出: 输出特征 h output 步骤: 1. 初始化: h ( 0 ) = h input 2. 动态参数生成: 对于每一层元学习处理( i 从 1 到 K ): W ( i − 1 ) = Reshape ( V w S ~ + v w ) b ( i − 1 ) = Reshape ( V b S ~ + v b ) 3. 元学习处理: 对于每一层元学习处理( i 从 1 到 K ): h ( i ) = σ ( W ( i − 1 ) h ( i − 1 ) + b ( i − 1 ) ) 4. 输出: h output = h ( K ) \begin{aligned}
\text{输入:} & \quad \text{场景信息表征 } \tilde{\mathbf{S}}, \text{ 输入特征 } \mathbf{h}_{\text{input}} \\
\text{输出:} & \quad \text{输出特征 } \mathbf{h}^{\text{output}} \\
\text{步骤:} \\
& 1. \quad \text{初始化:} \\
& \quad \quad \mathbf{h}^{(0)} = \mathbf{h}_{\text{input}} \\
& 2. \quad \text{动态参数生成:} \\
& \quad \quad \text{对于每一层元学习处理(} i \text{ 从 } 1 \text{ 到 } K \text{):} \\
& \quad \quad \quad \mathbf{W}^{(i-1)} = \text{Reshape}(\mathbf{V}_w \tilde{\mathbf{S}} + \mathbf{v}_w) \\
& \quad \quad \quad \mathbf{b}^{(i-1)} = \text{Reshape}(\mathbf{V}_b \tilde{\mathbf{S}} + \mathbf{v}_b) \\
& 3. \quad \text{元学习处理:} \\
& \quad \quad \text{对于每一层元学习处理(} i \text{ 从 } 1 \text{ 到 } K \text{):} \\
& \quad \quad \quad \mathbf{h}^{(i)} = \sigma(\mathbf{W}^{(i-1)} \mathbf{h}^{(i-1)} + \mathbf{b}^{(i-1)}) \\
& 4. \quad \text{输出:} \\
& \quad \quad \mathbf{h}^{\text{output}} = \mathbf{h}^{(K)}
\end{aligned}
输入: 输出: 步骤: 场景信息表征 S ~ , 输入特征 h input 输出特征 h output 1. 初始化: h ( 0 ) = h input 2. 动态参数生成: 对于每一层元学习处理( i 从 1 到 K ): W ( i − 1 ) = Reshape ( V w S ~ + v w ) b ( i − 1 ) = Reshape ( V b S ~ + v b ) 3. 元学习处理: 对于每一层元学习处理( i 从 1 到 K ): h ( i ) = σ ( W ( i − 1 ) h ( i − 1 ) + b ( i − 1 ) ) 4. 输出: h output = h ( K )
元学习单元在后续多专家融合、多任务塔的建模中都有使用,为了方便理解,我们可以将经过元学习单元处理过的特征看成是,特征处理时注入了场景信息的一种类似MLP的通用结构。
Attention元网络
传统的多专家融合方式是将样本中的部分特征输入到门控网络中得到多个专家的融合参数,这种方式在模型训练的过程中,门控网络可以学习到任务与专家之间的关系,却忽略了场景的因素。为此,Attention网络在计算融合权重时引入场景信息,实现了不同场景的融合参数是更个性化的,权重系数的计算如下:
a t i = v T Meta t ( [ E i ∥ T t ] ) α t i = exp ( a t i ) ∑ j = 1 M exp ( a t j ) R t = ∑ i = 1 k α t i E t i a_{t_i} = \mathbf{v}^T \text{Meta}_t([\mathbf{E}_i \parallel \mathbf{T}_t]) \\
\alpha_{t_i} = \frac{\exp(a_{t_i})}{\sum_{j=1}^M \exp(a_{t_j})} \\
\mathbf{R}_t = \sum_{i=1}^k \alpha_{t_i} \mathbf{E}_{t_i}
a t i = v T Meta t ([ E i ∥ T t ]) α t i = ∑ j = 1 M exp ( a t j ) exp ( a t i ) R t = i = 1 ∑ k α t i E t i
其中,R t \mathbf{R}_t R t t t t E i , T t E_i,T_t E i , T t i i i t t t
Tower元网络
L t ( 0 ) = R t , L t ( j ) = σ ( Meta ( j − 1 ) ( L t ( j − 1 ) ) + L t ( j − 1 ) ) , ∀ j ∈ 1 , 2 , … , L \mathbf{L}_t^{(0)} = \mathbf{R}_t, \\
\mathbf{L}_t^{(j)} = \sigma( \text{Meta}^{(j-1)}( \mathbf{L}_t^{(j-1)} ) + \mathbf{L}_t^{(j-1)} ), \quad \forall j \in 1, 2, \ldots, L
L t ( 0 ) = R t , L t ( j ) = σ ( Meta ( j − 1 ) ( L t ( j − 1 ) ) + L t ( j − 1 ) ) , ∀ j ∈ 1 , 2 , … , L
代码
m2m.py 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 import tensorflow as tffrom .layers import ( DNNs, PositionEncodingLayer, MetaUnit, MetaAttention, MetaTower, PredictLayer, TaskEmbedding, ) from .utils import ( build_input_layer, build_group_feature_embedding_table_dict, concat_group_embedding, get_linear_logits, concat_func, ) def build_m2m_model (feature_columns, model_config ): """构建M2M排序模型并遵循FunRec接口约定 Args: feature_columns: 特征列配置 model_config: 模型参数配置,包含: - task_names: 任务名称列表(默认 ["is_click", "long_view", "is_like"]) - domain_group_name: 领域/场景分组名称(默认 'domain') - num_experts, view_dim, scenario_dim, meta_tower_depth, meta_unit_depth, meta_unit_shared, activation, dropout, l2_reg - positon_agg_func, pos_emb_trainable, pos_initializer, sequence_pooling - linear_logits: 是否加上线性项(默认 True) Returns: (model, None, None): 排序模型返回单一主模型 """ task_name_list = model_config.get( "task_names" , ["is_click" , "long_view" , "is_like" ] ) domain_group_name = model_config.get("domain_group_name" , "domain" ) num_experts = model_config.get("num_experts" , 4 ) view_dim = model_config.get("view_dim" , 32 ) scenario_dim = model_config.get("scenario_dim" , 16 ) meta_tower_depth = model_config.get("meta_tower_depth" , 3 ) meta_unit_depth = model_config.get("meta_unit_depth" , 3 ) meta_unit_shared = model_config.get("meta_unit_shared" , True ) activation = model_config.get("activation" , "leaky_relu" ) dropout = model_config.get("dropout" , 0.2 ) l2_reg = model_config.get("l2_reg" , 1e-5 ) positon_agg_func = model_config.get("positon_agg_func" , "concat" ) pos_emb_trainable = model_config.get("pos_emb_trainable" , True ) pos_initializer = model_config.get("pos_initializer" , "glorot_uniform" ) sequence_pooling = model_config.get("sequence_pooling" , "mean" ) use_linear_logits = model_config.get("linear_logits" , True ) input_layer_dict = build_input_layer(feature_columns) group_embedding_feature_dict = build_group_feature_embedding_table_dict( feature_columns, input_layer_dict, prefix="embedding/" ) first_input_tensor = next (iter (input_layer_dict.values())) task_embedding_layers = [ TaskEmbedding(view_dim, name=f"task_emb_{i} " ) for i in range (len (task_name_list)) ] task_embedding_list = [layer(first_input_tensor) for layer in task_embedding_layers] if "user" in group_embedding_feature_dict: user_embeddings = concat_group_embedding(group_embedding_feature_dict, "user" ) elif "dnn" in group_embedding_feature_dict: user_embeddings = concat_group_embedding(group_embedding_feature_dict, "dnn" ) else : user_embeddings = tf.keras.layers.Lambda( lambda x: tf.zeros((tf.shape(x)[0 ], view_dim)) )(first_input_tensor) expert_inputs = ( concat_group_embedding(group_embedding_feature_dict, "dnn" ) if "dnn" in group_embedding_feature_dict else user_embeddings ) transformer_input_dict = group_embedding_feature_dict.get("mha" , {}) if domain_group_name in group_embedding_feature_dict: domain_group = group_embedding_feature_dict[domain_group_name] if isinstance (domain_group, list ) and len (domain_group) > 0 : domain_input = domain_group[0 ] elif isinstance (domain_group, dict ) and len (domain_group) > 0 : domain_input = list (domain_group.values())[0 ] else : domain_input = None else : domain_input = None if ( domain_input is not None and len (domain_input.shape) == 3 and domain_input.shape[1 ] == 1 ): domain_embeddings = tf.keras.layers.Lambda(lambda x: tf.squeeze(x, axis=1 ))( domain_input ) elif domain_input is not None : domain_embeddings = domain_input else : domain_embeddings = tf.keras.layers.Lambda( lambda x: tf.zeros((tf.shape(x)[0 ], view_dim)) )(first_input_tensor) mha_output_list = [] for feat_name, transformer_input in transformer_input_dict.items(): fc = [x for x in feature_columns if x.name == feat_name][0 ] position_embedding = PositionEncodingLayer( dims=transformer_input.shape[-1 ], max_len=fc.max_len, trainable=pos_emb_trainable, initializer=pos_initializer, )(transformer_input) if positon_agg_func == "sum" : transformer_input = tf.keras.layers.Add()( [transformer_input, position_embedding] ) elif positon_agg_func == "concat" : transformer_input = tf.keras.layers.Concatenate(axis=-1 )( [transformer_input, position_embedding] ) transformer_output = tf.keras.layers.MultiHeadAttention( num_heads=1 , key_dim=16 , value_dim=16 , dropout=0.2 , )(transformer_input, transformer_input, transformer_input) if sequence_pooling == "mean" : transformer_output = tf.keras.layers.Lambda( lambda x: tf.reduce_mean(x, axis=1 ) )(transformer_output) mha_output_list.append(transformer_output) mha_output = None if len (mha_output_list) != 0 : mha_output = concat_func(mha_output_list, axis=-1 ) expert_inputs = tf.concat([expert_inputs, mha_output], axis=-1 ) print ("mha shape" , mha_output.shape) scenario_inputs = [domain_embeddings, user_embeddings] scenario_views = DNNs( [scenario_dim], activation=activation, name="dnn/scenario_mlp" )(tf.concat(scenario_inputs, axis=-1 )) expert_views = [] for i in range (num_experts): expert_view = DNNs( [view_dim], activation=activation, dropout_rate=dropout, name=f"dnn/expert_{i} _mlp" , )(expert_inputs) expert_views.append(expert_view) expert_views = tf.stack(expert_views, axis=1 ) attention_shared_meta_unit = None tower_shared_meta_unit = None if meta_unit_shared: attention_shared_meta_unit = MetaUnit( meta_unit_depth, activation, dropout, l2_reg, name="dnn/attention_shared_meta_unit" , ) tower_shared_meta_unit = MetaUnit( meta_unit_depth, activation, dropout, l2_reg, name="dnn/tower_shared_meta_unit" , ) linear_logit = None if use_linear_logits: linear_logit = get_linear_logits(input_layer_dict, feature_columns) output_list = [] for i, task_name in enumerate (task_name_list): task_embedding = task_embedding_list[i] task_views = DNNs( [view_dim], activation=activation, dropout_rate=dropout, name=f"dnn/{task_name} _mlp" , )(task_embedding) meta_attention = MetaAttention( meta_unit=attention_shared_meta_unit, num_layer=meta_unit_depth, activation=activation, dropout=dropout, l2_reg=l2_reg, name=f"dnn/meta_attention_{task_name} " , ) attention_output = meta_attention([expert_views, task_views, scenario_views]) meta_tower = MetaTower( meta_unit=tower_shared_meta_unit, num_layer=meta_tower_depth, meta_unit_depth=meta_unit_depth, activation=activation, dropout=dropout, l2_reg=l2_reg, name=f"dnn/meta_tower_{task_name} " , ) tower_output = meta_tower([attention_output, scenario_views]) tower_output = tf.keras.layers.Flatten()(tower_output) tower_logit = PredictLayer(as_logit=True , name=f"{task_name} /tower_logit" )( tower_output ) if use_linear_logits: tower_logit = tf.keras.layers.Add()([tower_logit, linear_logit]) tower_logit = tf.keras.layers.Flatten(name=f"{task_name} /tower_logit_flat" )( tower_logit ) prediction = PredictLayer(name=f"task_{task_name} _output" )(tower_logit) output_list.append(prediction) model = tf.keras.Model(inputs=list (input_layer_dict.values()), outputs=output_list) return model, None , None
性能对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 pepnet: +----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+ | auc_is_click | auc_is_like | auc_long_view | auc_macro | gauc_is_click | gauc_is_like | gauc_long_view | gauc_macro | val_user_is_click | val_user_is_like | val_user_long_view | +================+===============+=================+=============+=================+================+==================+==============+=====================+====================+======================+ | 0.6741 | 0.6116 | 0.7002 | 0.662 | 0.6322 | 0.6048 | 0.6575 | 0.6315 | 217 | 131 | 217 | +----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+ apg: +--------+--------+------------+ | auc | gauc | val_user | +========+========+============+ | 0.6583 | 0.6284 | 217 | +--------+--------+------------+ m2m: +----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+ | auc_is_click | auc_is_like | auc_long_view | auc_macro | gauc_is_click | gauc_is_like | gauc_long_view | gauc_macro | val_user_is_click | val_user_is_like | val_user_long_view | +================+===============+=================+=============+=================+================+==================+==============+=====================+====================+======================+ | 0.6699 | 0.5704 | 0.6798 | 0.64 | 0.6213 | 0.6205 | 0.6319 | 0.6246 | 217 | 131 | 217 | +----------------+---------------+-----------------+-------------+-----------------+----------------+------------------+--------------+---------------------+--------------------+----------------------+

 微信支付
微信支付 支付宝
支付宝