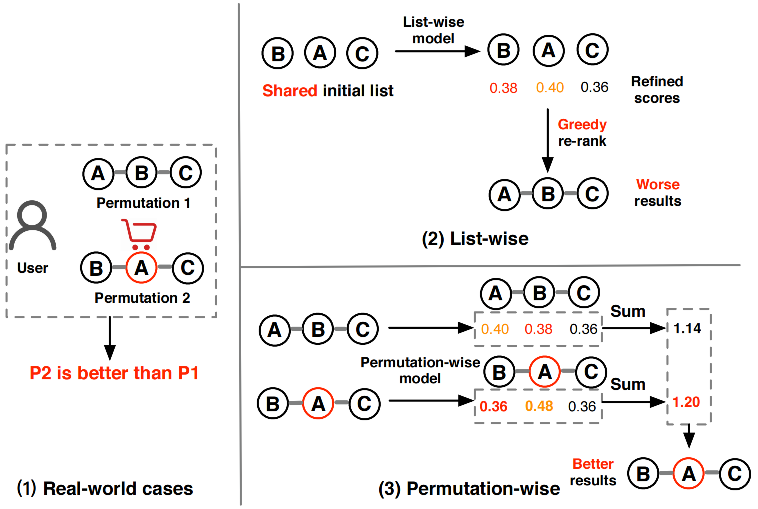
参考
重排(一)贪心重排
贪心算法以其思路直观、计算高效、易于实现的特点,成为重排阶段解决多样性、新颖性等问题的首选策略之一。它们通常不依赖复杂的模型训练,而是基于预先定义的规则或目标函数,通过逐步选择当前最优解(贪心选择)的方式来构建或调整最终推荐列表。本节将深入剖析两种经典的、基于贪心的重排算法:最大边际相关(Maximal Marginal Relevance, MMR) 和 行列式点过程(Determinantal Point Process, DPP)。
1、MMR:最大边际相关
原理
在精排输出的按CTR降序排列的列表中,头部物品往往具有高度相似性(如连续推荐同品类商品或同风格视频)。这种同质化现象直接导致两大问题:
用户体验恶化:用户浏览时产生审美疲劳,兴趣衰减速度加快;
系统效率损失:长尾优质内容曝光不足,平台生态多样性下降。
MMR算法 的核心目标是在保留高相关性物品的前提下,通过主动引入多样性打破同质化,实现“相关性与多样性的帕累托最优”。
MMR通过定义边际收益函数量化物品对列表的增量价值:
M R ( i ) = λ ⋅ Rel ( i ) ⏟ 相关性 − ( 1 − λ ) ⋅ max j ∈ S Sim ( i , j ) ⏟ 多样性惩罚项 MR(i) = \lambda \cdot \underbrace{\text{Rel}(i)}_{\text{相关性}} - (1-\lambda) \cdot \underbrace{\max_{j \in S} \text{Sim}(i,j)}_{\text{多样性惩罚项}}
MR ( i ) = λ ⋅ 相关性 Rel ( i ) − ( 1 − λ ) ⋅ 多样性惩罚项 j ∈ S max Sim ( i , j )
其中:
S S S
Rel ( i ) \text{Rel}(i) Rel ( i ) i i i
Sim ( i , j ) \text{Sim}(i,j) Sim ( i , j ) i i i j j j
λ \lambda λ 0 ≤ λ ≤ 1 0 \leq \lambda \leq 1 0 ≤ λ ≤ 1
λ → 1 \lambda \to 1 λ → 1 λ → 0 \lambda \to 0 λ → 0
当精排候选内容数量太多的时候,可以通过滑动窗口来对齐进行优化,也就是计算相似度的时候不是直接计算所有的相似度,而是计算窗口内的相似度,
M R win ( i ) = λ ⋅ Rel ( i ) − ( 1 − λ ) ⋅ max j ∈ W Sim ( i , j ) ⏟ 窗口多样性惩罚 MR_{\text{win}}(i) = \lambda \cdot \text{Rel}(i) - (1-\lambda) \cdot \underbrace{\max_{j \in W} \text{Sim}(i,j)}_{\text{窗口多样性惩罚}}
M R win ( i ) = λ ⋅ Rel ( i ) − ( 1 − λ ) ⋅ 窗口多样性惩罚 j ∈ W max Sim ( i , j )
其中W ⊆ S W \subseteq S W ⊆ S w w w w = ∣ W ∣ ≪ ∣ S ∣ w = |W| \ll |S| w = ∣ W ∣ ≪ ∣ S ∣
示例
假如有5个待重排的物品,已知精排打分和item之间的两两相似度,重排需要从5个物品中筛选出top3条内容的详细计算流程如下:
假设候选集包含5个商品及其精排分(Rel),相似度矩阵如下:
商品
Rel
A
B
C
D
E
A
0.95
1.0
0.2
0.8
0.1
0.3
B
0.90
0.2
1.0
0.1
0.7
0.4
C
0.85
0.8
0.1
1.0
0.3
0.6
D
0.80
0.1
0.7
0.3
1.0
0.5
E
0.75
0.3
0.4
0.6
0.5
1.0
λ = 0.7 \lambda=0.7 λ = 0.7
初始选择:A (Rel=0.95)
第二轮计算:
1 2 3 4 B: 0.90 - 0.7*max(Sim(A,B)=0.2) = 0.90 - 0.14 = 0.76 C: 0.85 - 0.7*0.8 = 0.85 - 0.56 = 0.29 D: 0.80 - 0.7*0.1 = 0.80 - 0.07 = 0.73 E: 0.75 - 0.7*0.3 = 0.75 - 0.21 = 0.54
选择 B (score=0.76)
第三轮计算(对比当前列表S=[A,B]):
1 2 3 C: 0.85 - 0.7*max(Sim(A,C)=0.8, Sim(B,C)=0.1) = 0.85-0.56=0.29 D: 0.80 - 0.7*max(0.1, 0.7) = 0.80-0.49=0.31 E: 0.75 - 0.7*max(0.3, 0.4) = 0.75-0.28=0.47
选择 E (score=0.47)
最终序列: [A, B, E] (对比精排序[A, B, C] 多样性提升37%)
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import copyfrom typing import Any , Callable , Dict , List import numpy as npfrom numpy.linalg import normfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarityclass Item : def __init__ ( self, id : str , rel: float , dense_vector: List [float ] = None , sparse_features: Dict [str , Any ] = None ): self.id = id self.rel = rel self.dense_vector = dense_vector self.sparse_features = sparse_features def MMR_Reranking ( item_pool: List [Item], k: int , lambda_param: float , sim_func: Callable [[Item, Item], float ], window_size: int = None List [Item]: """ 基于最大边际相关(MMR)算法的重排实现,支持滑动窗口优化 参数: item_pool -- 候选物品列表 k -- 最终返回的物品数量 lambda_param -- 相关性与多样性权衡参数 (0-1) sim_func -- 物品相似度计算函数 window_size -- 滑动窗口大小,默认为None(使用所有已选物品) 返回: 重排后的物品列表 """ candidates = copy.deepcopy(item_pool) S = [] if not candidates: return S first_item = max (candidates, key=lambda x: x.rel) S.append(first_item) candidates.remove(first_item) while len (S) < k and candidates: best_score = -float ('inf' ) best_item = None if window_size and len (S) > window_size: window = S[-window_size:] else : window = S for item in candidates: max_sim = max (sim_func(item, s) for s in window) if window else 0 score = lambda_param * item.rel - (1 - lambda_param) * max_sim if score > best_score: best_score = score best_item = item if best_item: S.append(best_item) candidates.remove(best_item) else : break return S def cosine_similarity (x, y ): vec1 = np.array(x.dense_vector) vec2 = np.array(y.dense_vector) return np.dot(vec1, vec2) / (norm(vec1) * norm(vec2)) item_size = 1000 feature_dimension = 100 max_length = 50 test_items = [] for i in range (item_size): rel_score = np.exp(0.01 * np.random.randn() + 0.2 ) dense_vec = np.random.randn(feature_dimension) dense_vec /= norm(dense_vec) item = Item( id =f"item_{i} " , rel=rel_score, dense_vector=dense_vec.tolist() ) test_items.append(item) sim_func = cosine_similarity window_size = 3 lambda_param = 0.7 reranked_items = MMR_Reranking(test_items, 3 , lambda_param, sim_func, window_size) print (f'选择了 {len (reranked_items)} 个物品' )
运行:
2、DPP:行列式点过程
行列式如何度量多样性
上述MMR原理中可以看出,MMR通过候选内容和已选内容计算两两相似度,贪心的选择一个和已选所有内容相似度最低的内容。这种方式无法捕捉多个物品间的复杂排斥关系(如三个相似物品的冗余效应),而行列式可以实现这一点。为了解释清楚行列式如何度量多样性,下面会花一定的篇幅做详细的介绍。
假设我们通过余弦相似度的方式来计算物品之间的相似度,对于每一个物品都有一个向量表示x i x_i x i X X X S = X T X S=X^TX S = X T X
我们知道矩阵行列式的几何意义表示的是,矩阵列向量张成的超面体的"有向体积"。在矩阵S S S S S S d e t ( S ) = 0 det(S)=0 d e t ( S ) = 0
假如我们有4个物品,对应的标签分别为:a = 科幻动作片 , b = 科幻喜剧片 , c = 古装爱情片 , d = 古装悬疑片 a=\text{科幻动作片},b=\text{科幻喜剧片},c=\text{古装爱情片},d=\text{古装悬疑片} a = 科幻动作片 , b = 科幻喜剧片 , c = 古装爱情片 , d = 古装悬疑片 S t S_t S t a , b , c , d {a,b,c,d} a , b , c , d
S = ( 1 0.9 0.1 0.2 0.9 1 0.1 0.1 0.1 0.1 1 0.8 0.2 0.1 0.8 1 ) S = \begin{pmatrix}
1 & 0.9 & 0.1 & 0.2 \\
0.9 & 1 & 0.1 & 0.1 \\
0.1 & 0.1 & 1 & 0.8 \\
0.2 & 0.1 & 0.8 & 1
\end{pmatrix}
S = 1 0.9 0.1 0.2 0.9 1 0.1 0.1 0.1 0.1 1 0.8 0.2 0.1 0.8 1
分别计算物品 a , b {a,b} a , b b , d {b,d} b , d S a , b S_{a,b} S a , b S b , d S_{b,d} S b , d
S a , b = ( 1 0.9 0.9 1 ) , S_{a,b} = \begin{pmatrix}
1 & 0.9 \\
0.9 & 1
\end{pmatrix},
S a , b = ( 1 0.9 0.9 1 ) ,
S b , d = ( 1 0.1 0.1 1 ) S_{b,d} = \begin{pmatrix}
1 & 0.1 \\
0.1 & 1
\end{pmatrix}
S b , d = ( 1 0.1 0.1 1 )
它们的行列式分别为:
∣ S a , b ∣ = 1 ∗ 1 − 0.9 ∗ 0.9 = 0.19 |S_{a,b}|=1*1-0.9*0.9=0.19 ∣ S a , b ∣ = 1 ∗ 1 − 0.9 ∗ 0.9 = 0.19
∣ S b , d ∣ = 1 ∗ 1 − 0.1 ∗ 0.1 = 0.81 |S_{b,d}|=1*1-0.1*0.1=0.81 ∣ S b , d ∣ = 1 ∗ 1 − 0.1 ∗ 0.1 = 0.81
从行列式的结果可以看出,当相似度矩阵的行列式值较大时,对应物品的多样性越高,反之行列式的值越低,多样性越低。
相关性与多样性融合
在推荐中,相关性和多样性是两个重要的指标。相关性指的是物品之间的相似性,即物品的相关性越高,推荐的结果越相似。在DPP中,通过引入一个半正定的核矩阵L L L L = B T B L=B^TB L = B T B B B B B B B r i r_i r i L i , j L_{i,j} L i , j
L i j = ⟨ B i , B j ⟩ = ⟨ r i f i , r j f j ⟩ = r i r j ⟨ f i , f j ⟩ . \mathbf{L}_{ij} = \langle \mathbf{B}_i, \mathbf{B}_j \rangle = \langle r_i \mathbf{f}_i, r_j \mathbf{f}_j \rangle = r_i r_j \langle \mathbf{f}_i, \mathbf{f}_j \rangle.
L ij = ⟨ B i , B j ⟩ = ⟨ r i f i , r j f j ⟩ = r i r j ⟨ f i , f j ⟩ .
其中,⟨ f i , f j ⟩ \langle \mathbf{f}_i, \mathbf{f}_j \rangle ⟨ f i , f j ⟩ i i i j j j S i j S_{ij} S ij L L L
L = Diag ( r ) ⋅ S ⋅ Diag ( r ) \mathbf{L} = \text{Diag}(\mathbf{r}) \cdot \mathbf{S} \cdot \text{Diag}(\mathbf{r})
L = Diag ( r ) ⋅ S ⋅ Diag ( r )
即分别对相似性矩阵的每一行和每一列分别乘以r i r_i r i
在公式推导之前,我们看一个核矩阵的详细构造过程,假设我们有 3 个物品,它们之间的相似度矩阵 S S S
S = [ 1 0.8 0.2 0.8 1 0.6 0.2 0.6 1 ] S = \begin{bmatrix}
1 & 0.8 & 0.2 \\
0.8 & 1 & 0.6 \\
0.2 & 0.6 & 1
\end{bmatrix}
S = 1 0.8 0.2 0.8 1 0.6 0.2 0.6 1
相关性向量 r r r
r = [ 0.9 0.7 0.5 ] r = \begin{bmatrix}
0.9 \\
0.7 \\
0.5
\end{bmatrix}
r = 0.9 0.7 0.5
构建对角阵:
Diag ( r ) = [ 0.9 0 0 0 0.7 0 0 0 0.5 ] \text{Diag}(r) = \begin{bmatrix}
0.9 & 0 & 0 \\
0 & 0.7 & 0 \\
0 & 0 & 0.5
\end{bmatrix}
Diag ( r ) = 0.9 0 0 0 0.7 0 0 0 0.5
计算核矩阵:
L = Diag ( r ) ⋅ S ⋅ Diag ( r ) L = \text{Diag}(r) \cdot S \cdot \text{Diag}(r)
L = Diag ( r ) ⋅ S ⋅ Diag ( r )
首先计算Diag ( r ) ⋅ S \text{Diag}(r) \cdot S Diag ( r ) ⋅ S
Diag ( r ) ⋅ S = [ 0.9 0 0 0 0.7 0 0 0 0.5 ] [ 1 0.8 0.2 0.8 1 0.6 0.2 0.6 1 ] = [ 0.9 0.72 0.18 0.56 0.7 0.42 0.1 0.3 0.5 ] \begin{aligned}
\text{Diag}(r) \cdot S &= \begin{bmatrix}
0.9 & 0 & 0 \\
0 & 0.7 & 0 \\
0 & 0 & 0.5
\end{bmatrix}
\begin{bmatrix}
1 & 0.8 & 0.2 \\
0.8 & 1 & 0.6 \\
0.2 & 0.6 & 1
\end{bmatrix} \\
&=
\begin{bmatrix}
0.9 & 0.72 & 0.18 \\
0.56 & 0.7 & 0.42 \\
0.1 & 0.3 & 0.5
\end{bmatrix}
\end{aligned}
Diag ( r ) ⋅ S = 0.9 0 0 0 0.7 0 0 0 0.5 1 0.8 0.2 0.8 1 0.6 0.2 0.6 1 = 0.9 0.56 0.1 0.72 0.7 0.3 0.18 0.42 0.5
然后计算 ( Diag ( r ) ⋅ S ) ⋅ Diag ( r ) (\text{Diag}(r) \cdot S) \cdot \text{Diag}(r) ( Diag ( r ) ⋅ S ) ⋅ Diag ( r )
( Diag ( r ) ⋅ S ) ⋅ Diag ( r ) = [ 0.9 0.72 0.18 0.56 0.7 0.42 0.1 0.3 0.5 ] [ 0.9 0 0 0 0.7 0 0 0 0.5 ] = [ 0.81 0.504 0.09 0.504 0.49 0.21 0.09 0.21 0.25 ] \begin{aligned}
(\text{Diag}(r) \cdot S) \cdot \text{Diag}(r) &= \begin{bmatrix}
0.9 & 0.72 & 0.18 \\
0.56 & 0.7 & 0.42 \\
0.1 & 0.3 & 0.5
\end{bmatrix}
\begin{bmatrix}
0.9 & 0 & 0 \\
0 & 0.7 & 0 \\
0 & 0 & 0.5
\end{bmatrix} \\
&= \begin{bmatrix}
0.81 & 0.504 & 0.09 \\
0.504 & 0.49 & 0.21 \\
0.09 & 0.21 & 0.25
\end{bmatrix}
\end{aligned}
( Diag ( r ) ⋅ S ) ⋅ Diag ( r ) = 0.9 0.56 0.1 0.72 0.7 0.3 0.18 0.42 0.5 0.9 0 0 0 0.7 0 0 0 0.5 = 0.81 0.504 0.09 0.504 0.49 0.21 0.09 0.21 0.25
构建完核矩阵后,继续 推导,根据行列式的乘法性质可得到:
∣ L ∣ = ∣ Diag ( r ) ∣ ⋅ ∣ S ∣ ⋅ ∣ Diag ( r ) ∣ = ∏ i ∈ R r i 2 ⋅ ∣ S ∣ |L| = |\text{Diag}(r)| \cdot |S| \cdot |\text{Diag}(r)| = \prod_{i \in R} r_{i}^2 \cdot |S|
∣ L ∣ = ∣ Diag ( r ) ∣ ⋅ ∣ S ∣ ⋅ ∣ Diag ( r ) ∣ = i ∈ R ∏ r i 2 ⋅ ∣ S ∣
对于用户u u u R u R_u R u
∣ L R u ∣ = ∏ i ∈ R u r u , i 2 ⋅ ∣ S ∣ |L_{R_u}| = \prod_{i \in R_u} r_{u,i}^2 \cdot |S|
∣ L R u ∣ = i ∈ R u ∏ r u , i 2 ⋅ ∣ S ∣
两边取对数,得到:
log ∣ L R u ∣ = ∑ i ∈ R u log r u , i 2 + log ∣ S ∣ \begin{aligned}
\log |L_{R_u}| = \sum_{i \in R_u} \log r_{u,i}^2 + \log |S|
\end{aligned}
log ∣ L R u ∣ = i ∈ R u ∑ log r u , i 2 + log ∣ S ∣
其中:
第一项只跟"相关性"有关,越相关 r u , i 2 r_{u,i}^2 r u , i 2
第二项 log ∣ S ∣ \log |S| log ∣ S ∣
经过上述的简单推到,我们会发现DPP最终优化的目标也变成了类似MMR的相关性和多样性的线形组合。所以在实际应用时会通过一个超参θ \theta θ
log ∣ L R u ∣ = θ ∑ i ∈ R u log r u , i 2 + ( 1 − θ ) log ∣ S ∣ \log |L_{R_u}| = \theta \sum_{i \in R_u} \log r_{u,i}^2 + (1-\theta) \log |S|
log ∣ L R u ∣ = θ i ∈ R u ∑ log r u , i 2 + ( 1 − θ ) log ∣ S ∣
贪心求解过程
上述介绍了相似矩阵的行列式可以度量多样性,通过核矩阵可以融合相关性和多样性,下面继续来看一下贪心求解的过程。重排从物品候选列表中选择一个子集,使得log ∣ L R u ∣ \log |L_{R_u}| log ∣ L R u ∣
DPP是一种性能较高的概率模型,能将复杂的概率计算转换成简单的行列式计算,通过核矩阵的行列式计算每一个子集的概率,这一筛选过程就是行列式点过程的最大后验概率推断MAP(maximum a posteriori inference),行列式点过程的MAP求解是一个复杂的过程,Hulu的论文中提出了一种改进的贪心算法能够快速求解。
这一求解过程简单来说就是每次从候选集中贪心地选择一个能使边际收益(Marginal Gain)最大的商品加入到最终的结果子集中,直到满足停止条件为止,即每次选择物品j j j Y g Y_g Y g Y g Y_g Y g j j j
j = arg max i ∈ Z ∖ Y g log det ( L Y g ∪ { i } ) − log det ( L Y g ) j = \arg\max_{i \in Z \setminus Y_g} \log\det(\mathbf{L}_{Y_g \cup \{i\}}) - \log\det(\mathbf{L}_{Y_g})
j = arg i ∈ Z ∖ Y g max log det ( L Y g ∪ { i } ) − log det ( L Y g )
由于L L L d e t ( L Y g ) > 0 det(L_{Y_g}) > 0 d e t ( L Y g ) > 0 d e t ( L Y g ) det(L_{Y_g}) d e t ( L Y g ) L Y g = V V T L_{Y_g}=VV^T L Y g = V V T V V V
对于新加入的物品i i i L Y g ∪ { i } \mathbf{L}_{Y_g \cup \{i\}} L Y g ∪ { i } L Y g L_{Y_g} L Y g i i i i i i L Y g ∪ { i } \mathbf{L}_{Y_g \cup \{i\}} L Y g ∪ { i }
L Y g ∪ { i } = [ L Y g L Y g , i L i , Y g L i i ] = [ V 0 c i d i ] [ V 0 c i d i ] ⊤ = [ V V ⊤ V c i ⊤ c i V ⊤ c i c i ⊤ + d i 2 ] \mathbf{L}_{Y_g \cup \{i\}} = \begin{bmatrix} \mathbf{L}_{Y_g} & \mathbf{L}_{Y_g,i} \\ \mathbf{L}_{i,Y_g} & \mathbf{L}_{ii} \end{bmatrix} = \begin{bmatrix} \mathbf{V} & \mathbf{0} \\ \mathbf{c}_i & d_i \end{bmatrix} \begin{bmatrix} \mathbf{V} & \mathbf{0} \\ \mathbf{c}_i & d_i \end{bmatrix}^\top = \begin{bmatrix} V V^\top & V c_i^\top \\[4pt] c_i V^\top & c_i c_i^\top+ d_i^2 \end{bmatrix}
L Y g ∪ { i } = [ L Y g L i , Y g L Y g , i L ii ] = [ V c i 0 d i ] [ V c i 0 d i ] ⊤ = [ V V ⊤ c i V ⊤ V c i ⊤ c i c i ⊤ + d i 2 ]
其中:
V \mathbf{V} V Y g Y_g Y g
L Y g , i \mathbf{L}_{Y_g,i} L Y g , i L \mathbf{L} L Y g Y_g Y g i i i
L i i L_{ii} L ii L \mathbf{L} L i i i r i r i ⟨ f i , f i ⟩ = r i 2 r_i r_i \langle \mathbf{f}_i, \mathbf{f}_i \rangle=r_i^2 r i r i ⟨ f i , f i ⟩ = r i 2
此外,行向量c i c_i c i d i d_i d i
V c i ⊤ = L Y g , i \mathbf{V} \mathbf{c}_i^\top = \mathbf{L}_{Y_g,i}
V c i ⊤ = L Y g , i
d i 2 = L i i − ∥ c i ∥ 2 2 . d_i^2 = \mathbf{L}_{ii} - \|\mathbf{c}_i\|_2^2.
d i 2 = L ii − ∥ c i ∥ 2 2 .
因此,c i c_i c i d i d_i d i
c i T = V T L Y g , i c_i^T = V^T \mathbf{L}_{Y_g,i} c i T = V T L Y g , i
d i = L i i − ∥ c i ∥ 2 2 d_i = \sqrt{\mathbf{L}_{ii} - \|\mathbf{c}_i\|_2^2} d i = L ii − ∥ c i ∥ 2 2
根据 公式,我们有Cholesky分解的分块形式:
L Y g ∪ { i } = [ L Y g L Y g , i L i , Y g L i i ] = [ V 0 c i d i ] [ V 0 c i d i ] T \mathbf{L}_{Y_g \cup \{i\}} = \begin{bmatrix} \mathbf{L}_{Y_g} & \mathbf{L}_{Y_g,i} \\ \mathbf{L}_{i,Y_g} & \mathbf{L}_{ii} \end{bmatrix} = \begin{bmatrix} \mathbf{V} & \mathbf{0} \\ \mathbf{c}_i & d_i \end{bmatrix} \begin{bmatrix} \mathbf{V} & \mathbf{0} \\ \mathbf{c}_i & d_i \end{bmatrix}^T
L Y g ∪ { i } = [ L Y g L i , Y g L Y g , i L ii ] = [ V c i 0 d i ] [ V c i 0 d i ] T
设 M = [ V 0 c i d i ] \mathbf{M} = \begin{bmatrix} \mathbf{V} & \mathbf{0} \\ \mathbf{c}_i & d_i \end{bmatrix} M = [ V c i 0 d i ]
L Y g ∪ { i } = M M T \mathbf{L}_{Y_g \cup \{i\}} = \mathbf{M}\mathbf{M}^T
L Y g ∪ { i } = M M T
根据矩阵行列式的性质:
det ( L Y g ∪ { i } ) = det ( M M T ) = det ( M ) ⋅ det ( M T ) = det ( M ) 2 \det(\mathbf{L}_{Y_g \cup \{i\}}) = \det(\mathbf{M}\mathbf{M}^T) = \det(\mathbf{M}) \cdot \det(\mathbf{M}^T) = \det(\mathbf{M})^2
det ( L Y g ∪ { i } ) = det ( M M T ) = det ( M ) ⋅ det ( M T ) = det ( M ) 2
由于 M \mathbf{M} M
det ( M ) = det ( V ) ⋅ det ( d i ) = det ( V ) ⋅ d i \det(\mathbf{M}) = \det(\mathbf{V}) \cdot \det(d_i) = \det(\mathbf{V}) \cdot d_i
det ( M ) = det ( V ) ⋅ det ( d i ) = det ( V ) ⋅ d i
因此:
det ( L Y g ∪ { i } ) = det ( M ) 2 = ( det ( V ) ⋅ d i ) 2 = det ( V ) 2 ⋅ d i 2 \det(\mathbf{L}_{Y_g \cup \{i\}}) = \det(\mathbf{M})^2 = (\det(\mathbf{V}) \cdot d_i)^2 = \det(\mathbf{V})^2 \cdot d_i^2
det ( L Y g ∪ { i } ) = det ( M ) 2 = ( det ( V ) ⋅ d i ) 2 = det ( V ) 2 ⋅ d i 2
而由于 L Y g = V V T \mathbf{L}_{Y_g} = \mathbf{V}\mathbf{V}^T L Y g = V V T
det ( L Y g ) = det ( V V T ) = det ( V ) 2 \det(\mathbf{L}_{Y_g}) = \det(\mathbf{V}\mathbf{V}^T) = \det(\mathbf{V})^2
det ( L Y g ) = det ( V V T ) = det ( V ) 2
最终得到:
det ( L Y g ∪ { i } ) = det ( L Y g ) ⋅ d i 2 \det(\mathbf{L}_{Y_g \cup \{i\}}) = \det(\mathbf{L}_{Y_g}) \cdot d_i^2
det ( L Y g ∪ { i } ) = det ( L Y g ) ⋅ d i 2
因此,det ( L Y g ∪ { i } ) \det(\mathbf{L}_{\mathbf{Y}_g \cup \{i\}}) det ( L Y g ∪ { i } )
det ( L Y g ∪ { i } ) = det ( L Y g ) ⋅ det ( d i 2 ) = det ( L Y g ) ⋅ d i 2 \det(\mathbf{L}_{\mathbf{Y}_g \cup \{i\}}) = \det(\mathbf{L}_{\mathbf{Y}_g}) \cdot \det(d_i^2) = \det(\mathbf{L}_{\mathbf{Y}_g}) \cdot d_i^2
det ( L Y g ∪ { i } ) = det ( L Y g ) ⋅ det ( d i 2 ) = det ( L Y g ) ⋅ d i 2
再将det ( L Y g ∪ { i } ) \det(\mathbf{L}_{\mathbf{Y}_g \cup \{i\}}) det ( L Y g ∪ { i } ) eq-dpp-marginal-gain 可得:
j = arg max i ∈ Z ∖ Y g log ( d i 2 ) . j = \arg\max_{i \in Z \setminus Y_g} \log(d_i^2).
j = arg i ∈ Z ∖ Y g max log ( d i 2 ) .
如果上式得解,即可以得到L Y k ∪ { j } L_{Y_k \cup \{j\}} L Y k ∪ { j }
L Y k ∪ { j } = [ V 0 c j d j ] [ V 0 c j d j ] T L_{Y_k \cup \{j\}} = \begin{bmatrix}
V & 0 \\
c_j & d_j
\end{bmatrix}
\begin{bmatrix}
V & 0 \\
c_j & d_j
\end{bmatrix}^T
L Y k ∪ { j } = [ V c j 0 d j ] [ V c j 0 d j ] T
按照上述的思路,如果c j c_j c j d j d_j d j Y g Y_g Y g i i i c i ′ c_i' c i ′ d i ′ d_i' d i ′
[ V 0 c j d j ] c i T = L Y g ∪ { j } , i = [ L Y g , i L j , i ] \begin{bmatrix}
V & 0 \\
c_j & d_j
\end{bmatrix}
c_i^T = \mathbf{L}_{Y_g \cup \{j\}, i} = \begin{bmatrix}
\mathbf{L}_{Y_g, i} \\
\mathbf{L}_{j,i}
\end{bmatrix}
[ V c j 0 d j ] c i T = L Y g ∪ { j } , i = [ L Y g , i L j , i ]
即(详细推导不展开):
c i ′ = [ c i ( L j i − ⟨ c j , c i ⟩ ) / d j ] = [ c i e i ] c_i' = [c_i \quad (L_{ji} - \langle c_j, c_i \rangle)/d_j] = [c_i \quad e_i]
c i ′ = [ c i ( L ji − ⟨ c j , c i ⟩) / d j ] = [ c i e i ]
d i 2 = L i i − ∥ c i ∥ 2 2 = L i i − ∥ c i ∥ 2 2 − c i 2 = d i 2 − c i 2 d_i^2 = L_{ii} - \|c_i\|_2^2 = L_{ii} - \|c_i\|_2^2 - c_i^2 = d_i^2 - c_i^2
d i 2 = L ii − ∥ c i ∥ 2 2 = L ii − ∥ c i ∥ 2 2 − c i 2 = d i 2 − c i 2
当 d i ′ d_i' d i ′ j = arg max i ∈ Z ∖ Y g log ( d i 2 ) j = \arg\max_{i \in Z \setminus Y_g} \log(d_i^2) j = arg max i ∈ Z ∖ Y g log ( d i 2 ) Y g Y_g Y g
最终贪心算法的算法流程如下
初始化:
c i = [ ] , d i 2 = L i i , j = arg max i ∈ Z log ( d i 2 ) , Y g = { j } \mathbf{c}_i = [], d_i^2 = \mathbf{L}_{ii}, j = \arg\max_{i \in Z} \log(d_i^2), Y_g = \{j\} c i = [ ] , d i 2 = L ii , j = arg max i ∈ Z log ( d i 2 ) , Y g = { j }
迭代:
当停止条件不满足时,执行以下步骤:
对于每个 i ∈ Z ∖ Y g i \in Z \setminus Y_g i ∈ Z ∖ Y g
计算 e i = ( L j i − ⟨ c j , c i ⟩ ) / d j \mathbf{e}_i = (\mathbf{L}_{ji} - \langle \mathbf{c}_j, \mathbf{c}_i \rangle) / d_j e i = ( L ji − ⟨ c j , c i ⟩) / d j
更新 c i = [ c i e i ] , d i 2 = d i 2 − e i 2 \mathbf{c}_i = [\mathbf{c}_i \quad \mathbf{e}_i], d_i^2 = d_i^2 - \mathbf{e}_i^2 c i = [ c i e i ] , d i 2 = d i 2 − e i 2
选择 j = arg max i ∈ Z ∖ Y g log ( d i 2 ) j = \arg\max_{i \in Z \setminus Y_g} \log(d_i^2) j = arg max i ∈ Z ∖ Y g log ( d i 2 ) Y g = Y g ∪ { j } Y_g = Y_g \cup \{j\} Y g = Y g ∪ { j }
返回:返回 Y g Y_g Y g
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import copyimport mathimport timefrom typing import Any , Callable , Dict , List import numpy as npclass Item : def __init__ ( self, id : str , rel: float , dense_vector: List [float ] = None , sparse_features: Dict [str , Any ] = None ) -> None : self.id = id self.rel = rel self.dense_vector = dense_vector self.sparse_features = sparse_features def DPP_Reranking ( item_pool: List [Item], k: int , kernel_matrix: np.ndarray, epsilon: float = 1E-10 ) -> List [Item]: """ 基于行列式点过程(DPP)的贪心重排实现 参数: item_pool -- 候选物品列表 k -- 最终返回的物品数量 kernel_matrix -- 核矩阵,融合了相关性和多样性 epsilon -- 数值稳定性阈值 返回: 重排后的物品列表 """ candidates = copy.deepcopy(item_pool) item_size = len (candidates) if not candidates or k <= 0 : return [] cis = np.zeros((k, item_size)) di2s = np.copy(np.diag(kernel_matrix)) selected_items = [] selected_item_idx = np.argmax(di2s) selected_items.append(selected_item_idx) while len (selected_items) < k and len (selected_items) < item_size: k_current = len (selected_items) - 1 ci_optimal = cis[:k_current, selected_item_idx] di_optimal = math.sqrt(di2s[selected_item_idx]) elements = kernel_matrix[selected_item_idx, :] eis = (elements - np.dot(ci_optimal, cis[:k_current, :])) / di_optimal cis[k_current, :] = eis di2s -= np.square(eis) selected_item_idx = np.argmax(di2s) if di2s[selected_item_idx] < epsilon: break selected_items.append(selected_item_idx) result = [candidates[idx] for idx in selected_items] return result def create_kernel_matrix ( item_pool: List [Item], sim_func: Callable [[Item, Item], float ] """ 构建DPP核矩阵,融合相关性和多样性 参数: item_pool -- 候选物品列表 sim_func -- 物品相似度计算函数 返回: 核矩阵 L = diag(r) * S * diag(r) """ n = len (item_pool) relevance_scores = np.array([item.rel for item in item_pool]) similarity_matrix = np.zeros((n, n)) for i in range (n): for j in range (n): if i == j: similarity_matrix[i, j] = 1.0 else : similarity_matrix[i, j] = sim_func(item_pool[i], item_pool[j]) kernel_matrix = ( relevance_scores.reshape((n, 1 )) * similarity_matrix * relevance_scores.reshape((1 , n)) ) return kernel_matrix item_size = 1000 feature_dimension = 100 max_length = 50 test_items = [] for i in range (item_size): rel_score = np.exp(0.01 * np.random.randn() + 0.2 ) dense_vec = np.random.randn(feature_dimension) dense_vec /= np.linalg.norm(dense_vec) item = Item( id =f"item_{i} " , rel=rel_score, dense_vector=dense_vec.tolist() ) test_items.append(item) def cosine_similarity_func (item1: Item, item2: Item ) -> float : vec1 = np.array(item1.dense_vector) vec2 = np.array(item2.dense_vector) return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) print ('开始构建核矩阵...' )kernel_matrix = create_kernel_matrix(test_items, cosine_similarity_func) print ('核矩阵生成完成!' )t = time.time() result = DPP_Reranking(test_items, max_length, kernel_matrix) print ('算法运行时间: ' + '\t' + "{0:.4e}" .format (time.time() - t))print (f'选择了 {len (result)} 个物品' )
运行:
1 2 3 4 开始构建核矩阵... 核矩阵生成完成! 算法运行时间: 3.9285e-02 选择了 50 个物品

 微信支付
微信支付 支付宝
支付宝