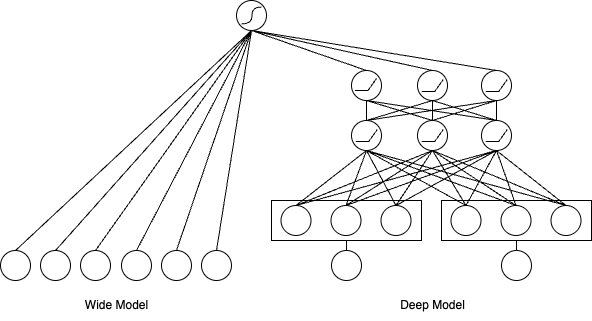
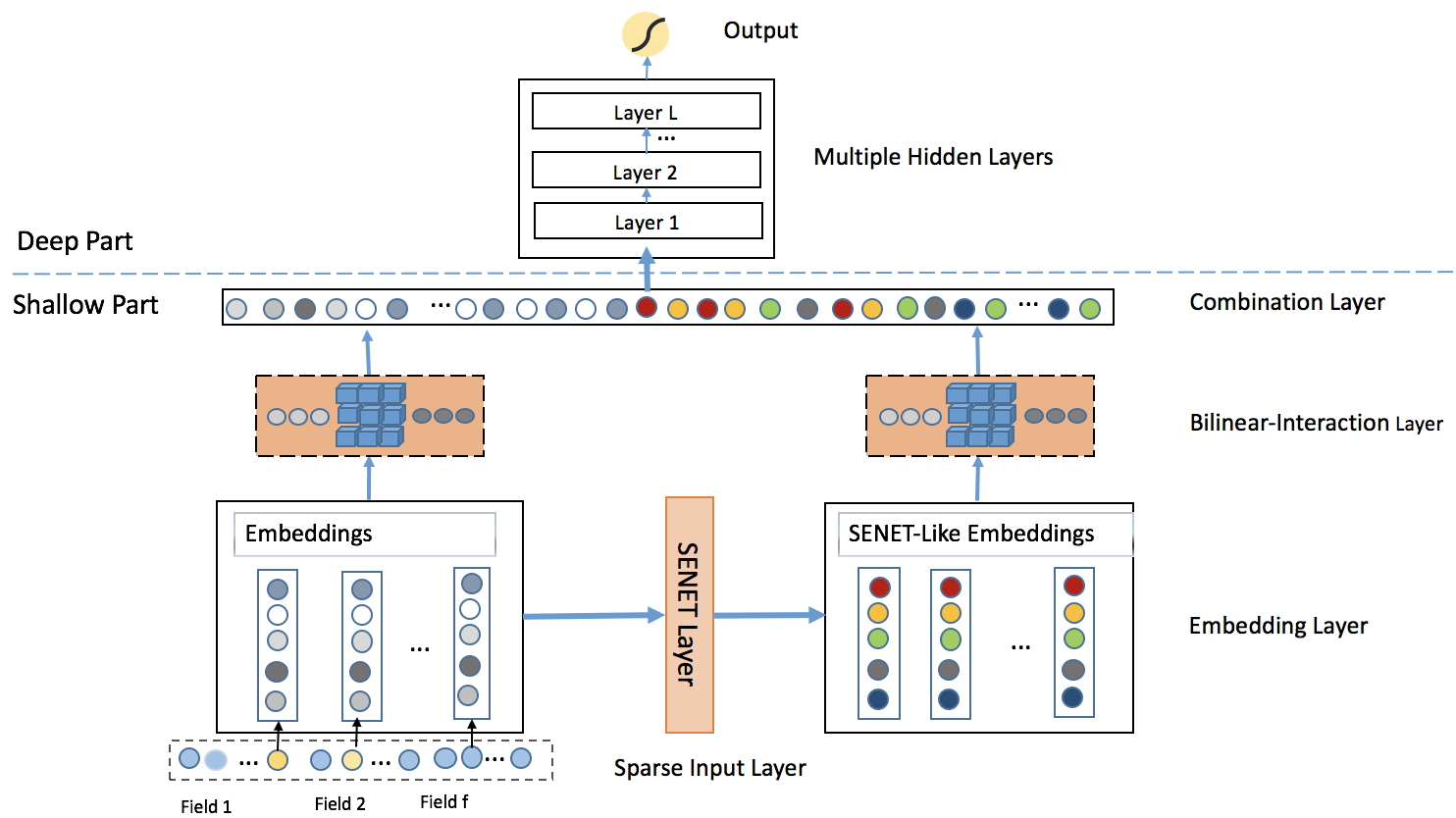
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| python preprocess_ml_hstu.py
数据目录: /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m
输出目录: /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m/processed
================================================================================
MovieLens-1M HSTU data preprocessing - sliding window with timestamps
================================================================================
加载MovieLens-1M数据...
原始数据: 1000209 条评分, 6040 用户, 3706 电影
数据过滤...
过滤前: 1000209 条评分
评分过滤后 (>=3): 836478 条评分
Item过滤后 (>=5次): 835790 条评分
User过滤后 (>=5次): 835789 条评分
过滤后: 6038 用户, 3307 电影
创建词表...
词表大小: 3308 (包含PAD)
构建用户序列...
用户数: 6038
序列长度统计: 平均=138.4, 最小=7, 最大=1924
使用滑动窗口生成训练样本(支持时间戳)...
时间差统计(秒):
平均: 2596220.3
中位数: 1902.0
最小: 1
最大: 89224014
平均(小时): 721.2
平均(天): 30.0
生成样本数: 829751
数据增强倍数: 137.4x
按用户分割数据集...
用户分割: Train=4226, Val=603, Test=1209
样本分割: Train=577594, Val=83977, Test=168180
保存数据...
保存 train 数据到 /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m/processed/train_data.pkl
- seq_tokens: (577594, 200)
- seq_time_diffs: (577594, 200)
- targets: (577594,)
保存 val 数据到 /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m/processed/val_data.pkl
- seq_tokens: (83977, 200)
- seq_time_diffs: (83977, 200)
- targets: (83977,)
保存 test 数据到 /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m/processed/test_data.pkl
- seq_tokens: (168180, 200)
- seq_time_diffs: (168180, 200)
- targets: (168180,)
保存词表到 /data1/wangxincheng/torch-rechub/examples/generative/data/ml-1m/processed/vocab.pkl
================================================================================
预处理完成!
================================================================================
关键改进:
✅ 采用滑动窗口策略,大幅提升数据量
✅ 添加冷启动过滤,提高数据质量
✅ 按用户分割数据,避免数据泄露
✅ 序列长度统计,便于调优
✅ 支持时间戳处理,计算时间差用于时间感知建模
|

 微信支付
微信支付 支付宝
支付宝