labuladong的算法笔记
章节
(一)
(二)
(三)
(四)
(五)
(六)
(七)
基础 03.01
03.01
03.01
03.01
03.01
03.01
03.01
03.02
03.02
03.02
\
\
\
\
第零章 03.04
03.05
03.06
03.07
03.08
03.09
03.09
03.10
03.11
03.12
03.13
03.13
03.14
\
第一章 03.15
04.08
04.09
04.09
04.10
\
\
\
\
\
\
第二章 \
\
\
\
\
第三章 04.11
04.11
\
第四章 \
\
\
\
\
机试的环境一般是 Dev C++,请自行打开 C++11 语法支持。
打开上方工具 Tools 的编译选项 Compiler Options。
勾选 编译时加入以下命令。填写入 -std=c++11 即可。
前言:标准模板库 STL
数据结构
1. vector
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <vector> vector<int > a; vector<int > a (n) ;vector<int > a (n, 0 ) ;vector<vector<int > b; vector<vector<int > b(n, vector<int >(5, 0)); a.resize(m); a.resize(m, 0); a.assign(n, 0); a[0] = 5; a.push_back(666); a.insert(a.begin() + 2, e); // 插入为第三个元素 a.insert(a.end(), c.begin(), c.end()); // a+c a.erase(a.begin() + 2); // 删除第三个元素 a.clear(); a.size(); a.empty(); a.front(); a.back();
2. stack
1 2 3 4 5 6 7 8 9 10 #include <stack> stack<int > stk; stk.push (4 ); stk.pop (); stk.top (); stk.empty (); stk.size ();
3. queue
1 2 3 4 5 6 7 8 9 10 11 #include <queue> queue<int > Q; Q.push (4 ); Q.pop (); Q.front (); Q.back (); Q.empty (); Q.size ();
4. deque
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <deque> deque<int > DQ; DQ.push_front (e); DQ.push_back (e); DQ.pop_front (); DQ.pop_back (); DQ.front (); DQ.back (); DQ.empty (); DQ.size (); DQ.clear ();
5. unordered_set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <unordered_set> unorder_set<int > Table; Table.insert (e); Table.erase (e); Table.emplace (e); Table.count (e); Table.find (e); Table.empty (); Table.size (); Table.clear (); for (auto &x: Table) cout << x << endl;
6. unordered_map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <unordered_map> unordered_map<string, int > Map; Map["apple" ] = 1 ; Map.insert ({"banana" , 2 }); Map.erase ("apple" ); Map.emplace ("cherry" , 3 ); int e = Map["apple" ];Map.count ("apple" ); Map.find ("apple" ); Map.empty (); Map.size (); Map.clear (); for (auto &x: Map) cout << x.first << x.second << endl;
7. priority_queue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <priority_queue> priority_queue<int > maxHeap; priority_queue<int , vector<int >, less<int >> maxHeap; priority_queue<int , vector<int >, greater<int >> minHeap; maxHeap.push (5 ); maxHeap.pop (); maxHeap.top (); maxHeap.empty (); maxHeap.size (); struct DT { int no; string name; DT (int n, string na): no (n), name (na) {} }; struct Cmp { bool operator () (const DT &a, const DT &b) const return a.no < b.no; } }; priority_queue<DT, vector<DT>, Cmp> maxHeap; maxHeap.push (DT (3 , "Mary" )); maxHeap.push (DT (1 , "Smith" )); maxHeap.push (DT (2 , "John" )); DT std = maxHeap.top (); std.no; std.name; maxHeap.pop (); auto cmp = [](ListNode* a, ListNode* b) { return a->val > b->val; };priority_queue<ListNode*, vector<ListNode*>, decltype (cmp)> minHeap;
8. string
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <string> string s1; s1 = "apple" ; string s2 ("hello" ) ;string s3 (s2) ; string s4 (5 , 'A' ) ; s = s1 + s2; s += "app" ; s1.find ('p' ); s1.find ("le" ); s1.find ("banana" ); s.size (); s.length (); char ch = s[0 ];char ch = s.at (3 );s[5 ] = 'k' ; s2.substr (2 , 3 ); str.insert (5 , "Insert" ); str.erase (5 , 6 ); string s5 = "abcdefg" ; s5.replace (2 , 3 , "AAAAA" ); bool r1 = (s1 == s2); int r2 = s1.compare (s2); for (int i=0 ; i<s.size (); i++) cout << s[i];for (char &c : s) cout << c;string numS = "1234" ; int numI = numS.stoi (numS);double numD = numS.stod (numS);int ai = 34 ;string aiS = to_string (ai); reverse (s.begin (), s.end ()); sort (s.begin (), s.end ()); s.empty (); s.clear ();
9、list
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include <list> list<int > myList; list<int > l2 (n) ; list<int > l3 (n, 8 ) ; list<int > l4 = {1 , 2 , 3 }; list<int > l5 (l4) ;myList.push_back (10 ); myList.push_front (20 ); myList.insert (++myList.begin (), 30 ); myList.pop_back (); myList.pop_front (); myList.erase (myList.begin ()); myList.remove (10 ); myList.clear (); int first = myList.front (); int last = myList.back (); int size = myList.size ();bool isEmpty = myList.empty ();for (auto it = myList.begin (); it != myList.end (); ++it) { cout << *it << " " ; } for (int val : myList) { cout << val << " " ; } for (list<int >::iterator it = myList.begin (); it != myList.end (); ++it) { cout << *it << " " ; } for (list<int >::reverse_iterator rit = myList.rbegin (); rit != myList.rend (); ++rit) { cout << *rit << " " ; } list<int > list1 = {1 , 3 , 5 }; list<int > list2 = {2 , 4 , 6 }; list1.merge (list2); myList.sort (); myList.sort (greater <int >()); myList.unique (); myList.reverse (); list<int > otherList = {7 , 8 , 9 }; myList.splice (myList.end (), otherList);
算法与心得
1. algorithm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <algorithm> swap (vec[0 ], vec[1 ]);sort (vec.begin (), vec.end ()); min (a, b);max (a, b);min ({a, b, c, d});max ({a, b, c, d, e});min_element (vec.begin (), vec.end ());max_element (vec.begin (), vec.end ());#include <numeric> int sum = accumulate (vec.begin (), vec.end (), 0 );bool r = binary_search (vec.begin (), vec.end (), 3 ); auto it = find (vec.begin (), vec.end (), 3 );if (it != vec.end ()) cout << *it << (it-vec.begin ()) << endl;int cnt = count (vec.begin (), vec.end (), 3 );fill (vec.begin (), vec.end (), 0 ); replace (vec.begin (), vec.end (), 3 , 99 ); vector<int > vec2 (vec.size()) ;copy (vec.begin (), vec.end (), vec2.begin ());reverse (vec.begin (), vec.end ());
2. cmath
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <cmath> sqrt (x); cbrt (x); abs (a);fabs (f);labs (l);ceil (a);floor (a);round (a);exp (k); exp2 (k); pow (a, k); log (x); log10 (x); log2 (x); sin (x);cos (x);tan (x);asin (x);acos (x);atan (x);sinh (x);cosh (x);tanh (x);
3. 必备实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int gcd (int a, int b) a = abs (a); b = abs (b); while (b != 0 ) { int temp = b; b = a % b; a = temp; } return a; } int lcm (int a, int b) if (a == 0 || b == 0 ) return 0 ; a = abs (a); b = abs (b); return a * b / gcd (a, b); }
4. 心得操作与失误总结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 for (int i=0 ; i<n; i++){ .... .... while (i+1 <n && nums[i]==nums[i+1 ]) i++; } if (color[i]==color[j]) flag = false ; flag = color[i] != color[j]; Q.front (); Q.pop (); S.top (); S.pop (); vector<vector<int >> G1; vector<vector<bool >> G2; vector<vector<int >> G3; vector<vector<int >> MD; MD.push_back ({1 , 2 , 88 }); MD.push_back ({2 , 2 , 66 }); MD.push_back ({5 , 1 , 99 }); sort (MD.begin (), MD.end (), [](const vector<int >& A, const vector<int >& B){ return A[2 ] < B[2 ]; }); Q.front (); S.top (); PQ.top (); auto cmp = [](const vector<int >& a, const vector<int >& b){ return a[2 ] < b[2 ]; } sort (vc.begin (), vc.end (), cmp);auto cmp = [](const vector<int >& a, const vector<int >& B){ return A[2 ] > B[2 ]; } priority_quque<vector<int >, vector<vector<int >>, decltype (cmp)> PQ; for (int i=0 ; i<=n; i++) dp[i][0 ] = true ;for (int j=0 ; j<=m; j++) dp[0 ][j] = false ;for (int i=0 ; i<=n; i++) dp[i][0 ] = true ;for (int j=1 ; j<=m; j++) dp[0 ][j] = false ;unordered_map<string, int > memo; string key = to_string (i) + ',' + to_string (remain); memo[key] = 88 ; string cur = to_string (i) + ',' + to_string (remain); if (memo.find (cur) != memo.end ()) return memo[cur]; return dp (nums, i+1 , remain-nums[i]) + dp (nums, i+1 , remain+nums[i]);string cur = to_string (i) + ',' + to_string (remain); if (memo.find (cur) != memo.end ()) return memo[cur]; int res = dp (nums, i+1 , remain-nums[i]) + dp (nums, i+1 , remain+nums[i]);memo[cur] = res; return res;
基础:数据结构及排序
(一) 数组(静态、动态)
动态数组底层还是静态数组,只是自动帮我们进行数组空间的扩缩容 ,并把增删查改操作进行了封装,让我们使用起来更方便而已。
(二) 链表(单、双)
略
(三) 变种:环形数组、跳表
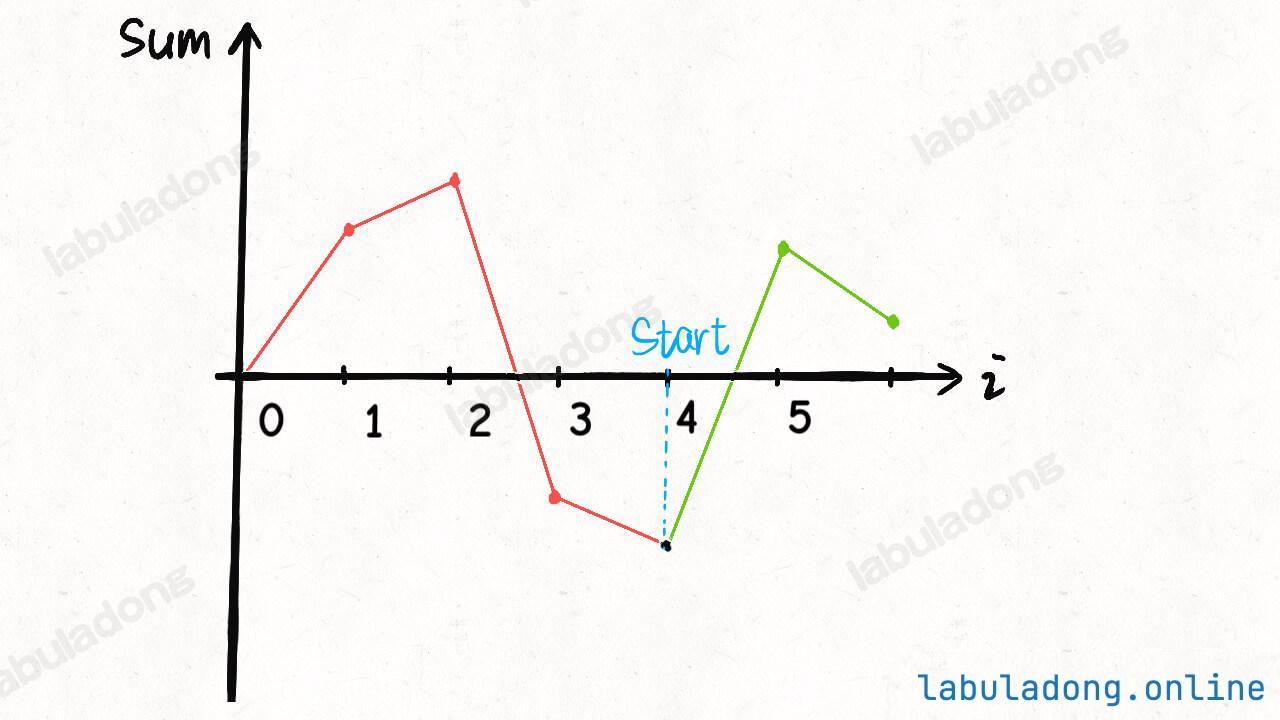
环形数组:
环形数组技巧利用求模(余数)运算,将普通数组变成逻辑上的环形数组,可以让我们用 O ( 1 ) O(1) O ( 1 )
核心原理:环形数组的关键在于,它维护了两个指针 start 和 end,start 指向第一个有效元素的索引,end 指向最后一个有效元素的下一个位置索引。
理论上,你可以随意设计区间的开闭,但一般设计为左闭右开 区间是最方便处理的。因为这样初始化 start = end = 0 时,区间 [0, 0) 中没有元素,但只要让 end 向右移动(扩大)一位,区间 [0, 1) 就包含一个元素 0 了。
跳表
1 2 index 0 1 2 3 4 5 6 7 8 9 node a->b->c->d->e->f->g->h->i->j
如果我们想查询索引为 7 的元素是什么,只能从索引 0 头结点开始往后遍历,直到遍历到索引 7,找到目标节点 h。
而跳表则是这样的:
1 2 3 4 5 indexLevel 0-----------------------8-----10 indexLevel 0-----------4-----------8-----10 indexLevel 0-----2-----4-----6-----8-----10 indexLevel 0--1--2--3--4--5--6--7--8--9--10 nodeLevel a->b->c->d->e->f->g->h->i->j->k
此时,如果我们想查询索引为 7 的元素,可以从最高层索引开始一层一层地往下找,这个搜索过程中,会经过 log N \log N log N O ( log N ) O(\log N) O ( log N )
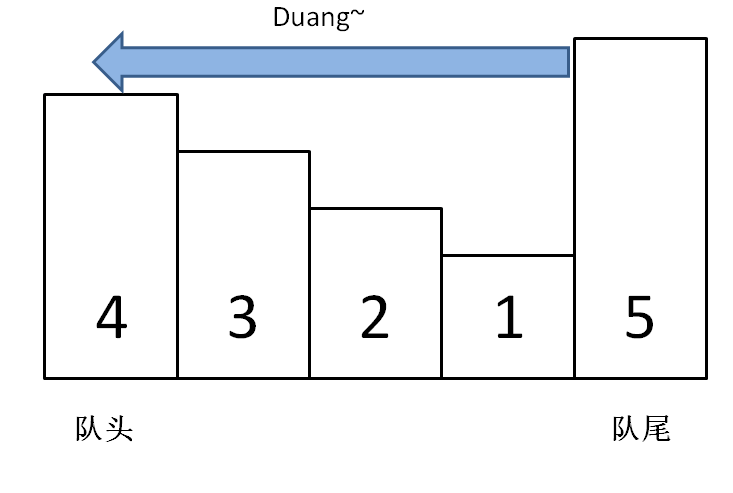
(四) 队列、栈、双端队列
其实队列和栈都是操作受限的数据结构。
队列只能在一端插入元素,另一端删除元素;
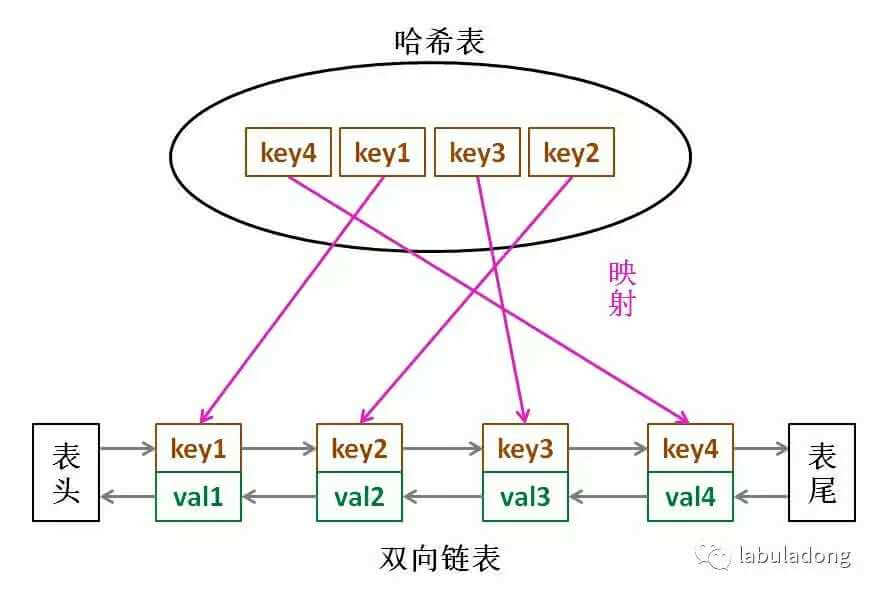
(五) 哈希表、哈希集合、加强哈希表
略
(六) 二叉树
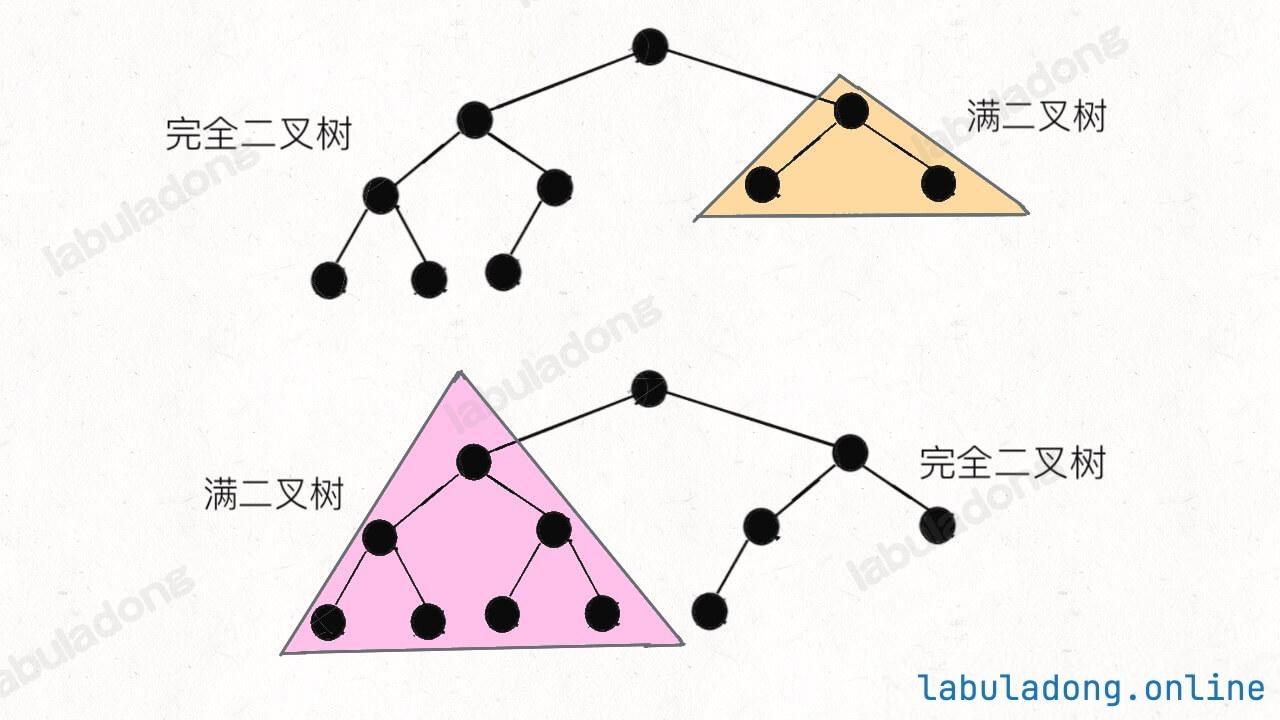
1. 满二叉树
直接看图比较直观,满二叉树就是每一层节点都是满的,整棵树像一个正三角形:
满二叉树有个优势,就是它的节点个数很好算。假设深度为 h h h 2 h − 1 2^h - 1 2 h − 1
2. 完全二叉树
完全二叉树是指,二叉树的每一层的节点都紧凑靠左排列,且除了最后一层,其他每层都必须是满的:
不难发现,满二叉树其实是一种特殊的完全二叉树。
完全二叉树的特点 :由于它的节点紧凑排列,如果从左到右从上到下对它的每个节点编号,那么父子节点的索引存在明显的规律。
这个特点在讲到 二叉堆核心原理 和 线段树核心原理 时会用到:完全二叉树可以用数组来存储,不需要真的构建链式节点 。
完全二叉树还有个比较难发觉的性质:完全二叉树的左右子树也是完全二叉树 。
或者更准确地说应该是:完全二叉树的左右子树中,至少有一棵是满二叉树 。
3. 平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,它的每个节点的左右子树的高度差不超过 1 。
要注意是每个节点,而不仅仅是根节点。
假设平衡二叉树中共有 N N N O ( l o g N ) O(logN) O ( l o g N )
这是非常重要的性质,后面讲到的 红黑树 和 线段树 会利用平衡二叉树的这个性质,保证算法的高效性。
4. 二叉搜索树
二叉搜索树(Binary Search Tree,简称 BST)是一种很常见的二叉树,它的定义是:对于树中的每个节点,其左子树的每个节点 的值都要小于这个节点的值,右子树的每个节点 的值都要大于这个节点的值。你可以简单记为 左小右大 。
BST 是非常常用的数据结构。因为左小右大的特性,可以让我们在 BST 中快速找到某个节点,或者找到某个范围内的所有节点,这是 BST 的优势所在。
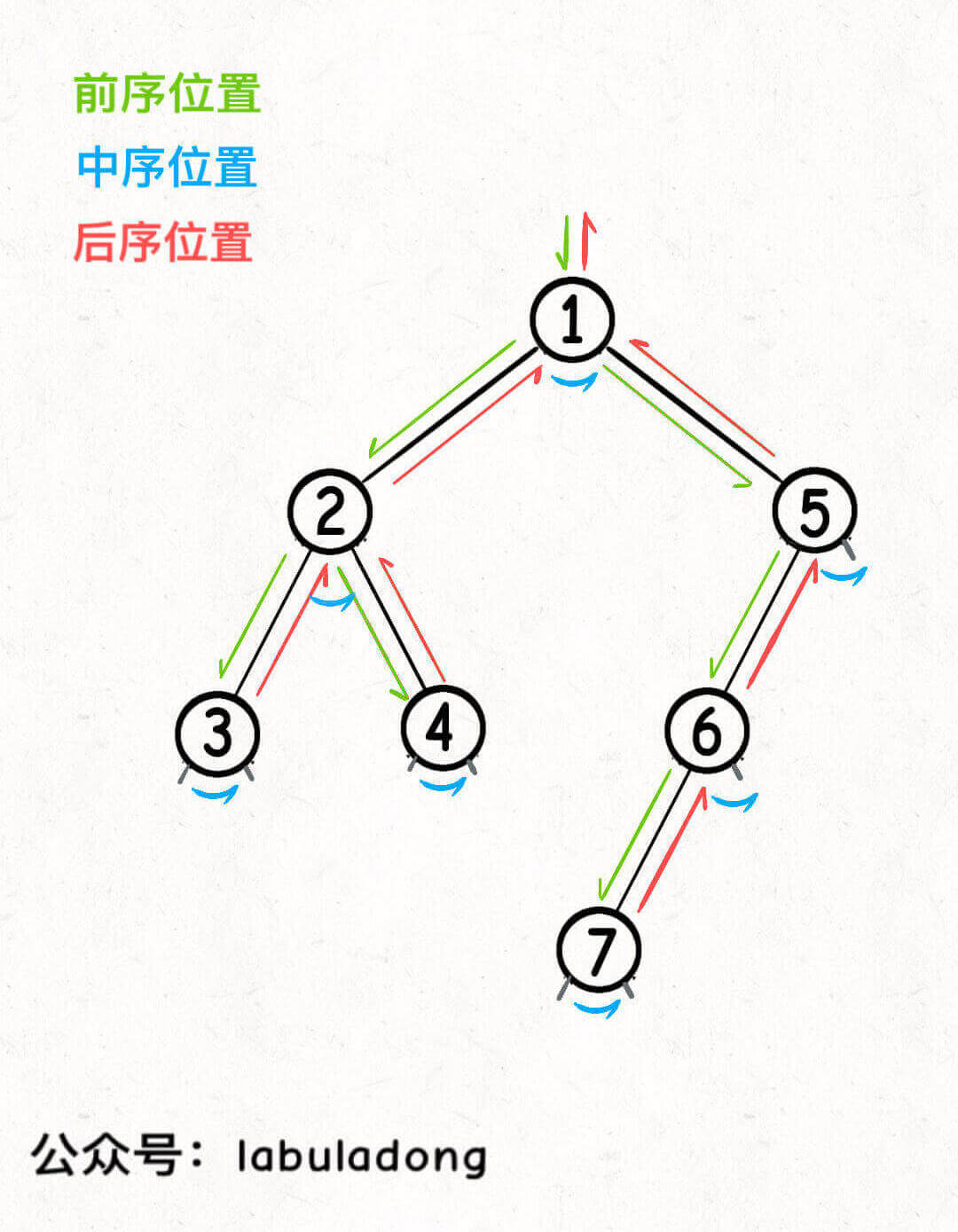
5. 递归遍历(DFS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class TreeNode {public : int val; TreeNode* left; TreeNode* right; TreeNode (int x) : val (x), left (nullptr ), right (nullptr ) {} }; void traverse (TreeNode* root) if (root == nullptr ) { return ; } traverse (root->left); traverse (root->right); }
这个递归遍历节点顺序是固定的 ,务必记住这个顺序,否则你肯定玩不转二叉树结构。
二叉树有前/中/后序三种遍历,会得到三种不同顺序的结果。为啥你这里说递归遍历节点的顺序是固定的呢?
BST 的中序遍历结构有序。
6. 层序遍历(BFS)
二叉树的层序遍历,顾名思义,就是一层一层地遍历二叉树。
这个遍历方式需要借助队列来实现,而且根据不同的需求,主要有三种不同的写法,下面一一列举。
(1)写法一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void levelOrderTraverse (TreeNode* root) if (root == nullptr ) { return ; } std::queue<TreeNode*> q; q.push (root); while (!q.empty ()) { TreeNode* cur = q.front (); q.pop (); std::cout << cur->val << std::endl; if (cur->left != nullptr ) { q.push (cur->left); } if (cur->right != nullptr ) { q.push (cur->right); } } }
知道节点的层数是个常见的需求,比方说让你收集每一层的节点,或者计算二叉树的最小深度等等。
所以这种写法虽然简单,但用的不多,下面介绍的写法会更常见一些。
(2)写法二
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void levelOrderTraverse (TreeNode* root) if (root == nullptr ) { return ; } queue<TreeNode*> q; q.push (root); int depth = 1 ; while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { TreeNode* cur = q.front (); q.pop (); cout << "depth = " << depth << ", val = " << cur->val << endl; if (cur->left != nullptr ) { q.push (cur->left); } if (cur->right != nullptr ) { q.push (cur->right); } } depth++; } }
这个变量 i 记录的是节点 cur 是当前层的第几个,大部分算法题中都不会用到这个变量。
但是注意队列的长度 sz 一定要在循环开始前保存 下来,因为在循环过程中队列的长度是会变化的,不能直接用 q.size() 作为循环条件。
这种写法就可以记录下来每个节点所在的层数,可以解决诸如二叉树最小深度这样的问题,是我们最常用的层序遍历写法。
(3)写法三
既然写法二是最常见的,为啥还有个写法三呢?因为要给后面的进阶内容做铺垫。
回顾写法二,我们每向下遍历一层,就给 depth 加 1,可以理解为每条树枝的权重是 1,二叉树中每个节点的深度,其实就是从根节点到这个节点的路径权重和,且同一层的所有节点,路径权重和都是相同的。
那么假设,如果每条树枝的权重和可以是任意值,现在让你层序遍历整棵树,打印每个节点的路径权重和,你会怎么做?
写法三就是为了解决这个问题,在写法一的基础上添加一个 State 类,让每个节点自己负责维护自己的路径权重和,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class State {public : TreeNode* node; int depth; State (TreeNode* node, int depth) : node (node), depth (depth) {} }; void levelOrderTraverse (TreeNode* root) if (root == nullptr ) { return ; } queue<State> q; q.push (State (root, 1 )); while (!q.empty ()) { State cur = q.front (); q.pop (); cout << "depth = " << cur.depth << ", val = " << cur.node->val << endl; if (cur.node->left != nullptr ) { q.push (State (cur.node->left, cur.depth + 1 )); } if (cur.node->right != nullptr ) { q.push (State (cur.node->right, cur.depth + 1 )); } } }
这样每个节点都有了自己的 depth 变量,是最灵活的,可以满足所有 BFS 算法的需求。
其实你很快就会学到,这种边带有权重的场景属于图结构算法,在之后的 BFS 算法习题集 和 dijkstra 算法 中,才会用到这种写法。
二叉树的遍历方式只有上面两种,也许有其他的写法,但都是表现形式上的差异,本质上不可能跳出上面两种遍历方式。
DFS 算法在寻找所有路径的问题中更常用。
而 BFS 算法在寻找最短路径的问题中更常用。
为什么 BFS 常用来寻找最短路径?
对于 DFS,你能不能在不遍历完整棵树的情况下,提前结束算法?DFS 遍历当然也可以用来寻找最短路径,但必须遍历完所有节点才能得到最短路径 。
对于 BFS,由于 BFS 逐层遍历的逻辑,第一次遇到目标节点时,所经过的路径就是最短路径,算法可能并不需要遍历完所有节点就能提前结束 。
从时间复杂度的角度来看,两种算法在最坏情况下都会遍历所有节点,时间复杂度都是 O ( N ) O(N) O ( N ) 寻找最短路径的问题中,BFS 算法是首选 。
为什么 DFS 常用来寻找所有路径?
(七) 多叉树
二叉树的节点长这样,每个节点有两个子节点。多叉树的节点长这样,每个节点有任意个子节点。就这点区别,其他没了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class TreeNode {public : int val; TreeNode* left; TreeNode* right; TreeNode (int v) : val (v), left (nullptr ), right (nullptr ) {} }; class Node {public : int val; vector<Node*> children; };
森林:森林就是多个多叉树的集合。一棵多叉树其实也是一个特殊的森林。
在并查集算法中,我们会同时持有多棵多叉树的根节点,那么这些根节点的集合就是一个森林。
1. 递归遍历(DFS)
唯一的区别是,多叉树没有了中序位置,因为可能有多个节点嘛,所谓的中序位置也就没什么意义了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void traverse (TreeNode* root) if (root == nullptr ) { return ; } traverse (root->left); traverse (root->right); } void traverse (Node* root) if (root == nullptr ) { return ; } for (Node* child : root->children) { traverse (child); } }
2. 层序遍历(BFS)
多叉树的层序遍历和 二叉树的层序遍历 一样,都是用队列来实现,无非就是把二叉树的左右子节点换成了多叉树的所有子节点。所以多叉树的层序遍历也有三种写法,下面一一列举。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } std::queue<Node*> q; q.push (root); while (!q.empty ()) { Node* cur = q.front (); q.pop (); std::cout << cur->val << std::endl; for (Node* child : cur->children) { q.push (child); } } } #include <iostream> #include <queue> #include <vector> void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } std::queue<Node*> q; q.push (root); int depth = 1 ; while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { Node* cur = q.front (); q.pop (); std::cout << "depth = " << depth << ", val = " << cur->val << std::endl; for (Node* child : cur->children) { q.push (child); } } depth++; } } class State {public : Node* node; int depth; State (Node* node, int depth) : node (node), depth (depth) {} }; void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } std::queue<State> q; q.push (State (root, 1 )); while (!q.empty ()) { State state = q.front (); q.pop (); Node* cur = state.node; int depth = state.depth; std::cout << "depth = " << depth << ", val = " << cur->val << std::endl; for (Node* child : cur->children) { q.push (State (child, depth + 1 )); } } }
。
(八) 二叉树变种
1. 二叉搜索树
二叉搜索树是特殊的 二叉树结构,其主要的实际应用是 TreeMap 和 TreeSet。
对于树中的每个节点,其左子树的每个节点 的值都要小于这个节点的值,右子树的每个节点 的值都要大于这个节点的值。
这个左小右大 的特性,可以让我们在 BST 中快速找到某个节点,或者找到某个范围内的所有节点,这是 BST 的优势所在。
理想的时间复杂度是树的高度 O ( l o g N ) O(logN) O ( l o g N ) O ( N ) O(N) O ( N )
增删改的时间复杂度也是 O ( l o g N ) O(logN) O ( l o g N )
前文说复杂度是树的高度 O ( l o g N ) ( N 为节点总数) O(logN)(N 为节点总数) O ( l o g N ) ( N 为节点总数) 二叉搜索树要是平衡的,也就是左右子树的高度差不能太大 。O ( N ) O(N) O ( N ) O ( N ) O(N) O ( N )
二叉搜索树的性能取决于树的高度,树的高度取决于树的平衡性。 大家熟知的红黑树就是一类自平衡的二叉搜索树,它的平衡性能非常好,但是实现起来比较复杂,这就是完美所需付出的代价。
1 2 3 4 5 7 / \ 4 9 / \ \ 1 5 10
TreeMap/TreeSet 实现原理
它和前文介绍的 哈希表 HashMap 的结构是类似的,都是存储键值对 的,HashMap 底层把键值对存储在一个 table 数组里面,而 TreeMap 底层把键值对存储在一棵二叉搜索树的节点 里面。
至于 TreeSet,它和 TreeMap 的关系正如哈希表 HashMap 和哈希集合 HashSet 的关系一样,说白了就是 TreeMap 的简单封装,所以下面主要讲解 TreeMap 的实现原理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class TreeNode {public : int val; TreeNode* left; TreeNode* right; TreeNode (int x) : val (x), left (nullptr ), right (nullptr ) {} }; template <typename K, typename V>class TreeNode {public : K key; V value; TreeNode<K, V>* left; TreeNode<K, V>* right; TreeNode (K key, V value) : key (key), value (value), left (nullptr ), right (nullptr ) {} };
get 方法其实就类似上面可视化面板中查找目标节点的操作,根据目标 key 和当前节点的 key 比较,决定往左走还是往右走,可以一次性排除掉一半的节点,复杂度是 O ( log N ) O(\log N) O ( log N ) 至于 put, remove, containsKey 方法,其实也是要先利用 get 方法找到目标键所在的节点,然后做一些指针操作,复杂度都是 O ( log N ) O(\log N) O ( log N )
keys 方法返回所有键,且结果有序。可以利用 BST 的中序遍历结果有序的特性。
2. 红黑树
红黑树是自平衡的二叉搜索树,它的树高在任何时候都能保持在 O ( log N ) O(\log N) O ( log N ) O ( log N ) O(\log N) O ( log N )
3. Tire(字典树/前缀树)
Trie 树本质上就是一棵从二叉树衍生出来的多叉树。
Trie 树就是 多叉树结构 的延伸,是一种针对字符串进行特殊优化的数据结构。
Trie 树在处理字符串相关操作时有诸多优势,比如节省公共字符串前缀的内存空间、方便处理前缀操作、支持通配符匹配等。
这里要特别注意,TrieNode 节点本身只存储 val 字段,并没有一个字段来存储字符,字符是通过子节点在父节点的 children 数组中的索引确定的。形象理解就是,Trie 树用树枝 存储字符串(键),用节点 存储字符串(键)对应的数据(值)。所以我在图中把字符标在树枝,键对应的值 val 标在节点上:
1 2 3 4 5 6 template <typename V>struct TrieNode { V val = NULL ; TrieNode<V>* children[256 ] = { NULL }; };
这个 val 字段存储键对应的值,children 数组存储指向子节点的指针。但是和之前的普通多叉树节点不同,TrieNode 中 children 数组的索引是有意义的,代表键中的一个字符。
比如在实际做题时,题目说了只包含字符 a-z,那么你可以把大小改成 26;或者你不想用字符索引来映射,直接用哈希表 HashMap<Character, TrieNode> 也可以,都是一样的效果。
4. 二叉堆
二叉堆是一种能够动态排序的数据结构,是二叉树结构的延伸。
两个核心操作:下沉sink和上浮swim。
主要应用:优先队列priority_queue、堆排序heap_sort。
能够动态排序的数据结构,只有两个:1. 优先队列(底层采用二叉堆实现)2. 二叉搜索树
你可以认为二叉堆是一种特殊的二叉树,这棵二叉树上的任意节点的值,都必须大于等于(或小于等于)其左右子树所有 节点的值。如果是大于等于,我们称之为大顶堆,如果是小于等于,我们称之为小顶堆。
二叉堆可以辅助我们快速找到最大值或最小值。
二叉堆还有个性质:一个二叉堆的左右子堆(子树)也是一个二叉堆 。
应用 1:优先队列
自动排序是有代价的,注意优先级队列 API 的时间复杂度,增删元素 的复杂度是 O ( log N ) 其中 N 是当前二叉堆中的元素个数 O(\log N)其中 N 是当前二叉堆中的元素个数 O ( log N ) 其中 N 是当前二叉堆中的元素个数
标准队列是先进先出的顺序,而二叉堆可以理解为一种会自动排序的队列 ,所以叫做优先级队列感觉也挺贴切的。当然,你也一定要明白,虽然它的 API 像队列,但它的底层原理和二叉树有关,和队列没啥关系 。
以小顶堆为例,向小顶堆中插入 新元素遵循两个步骤:
以小顶堆为例,删除 小顶堆的堆顶元素遵循两个步骤:
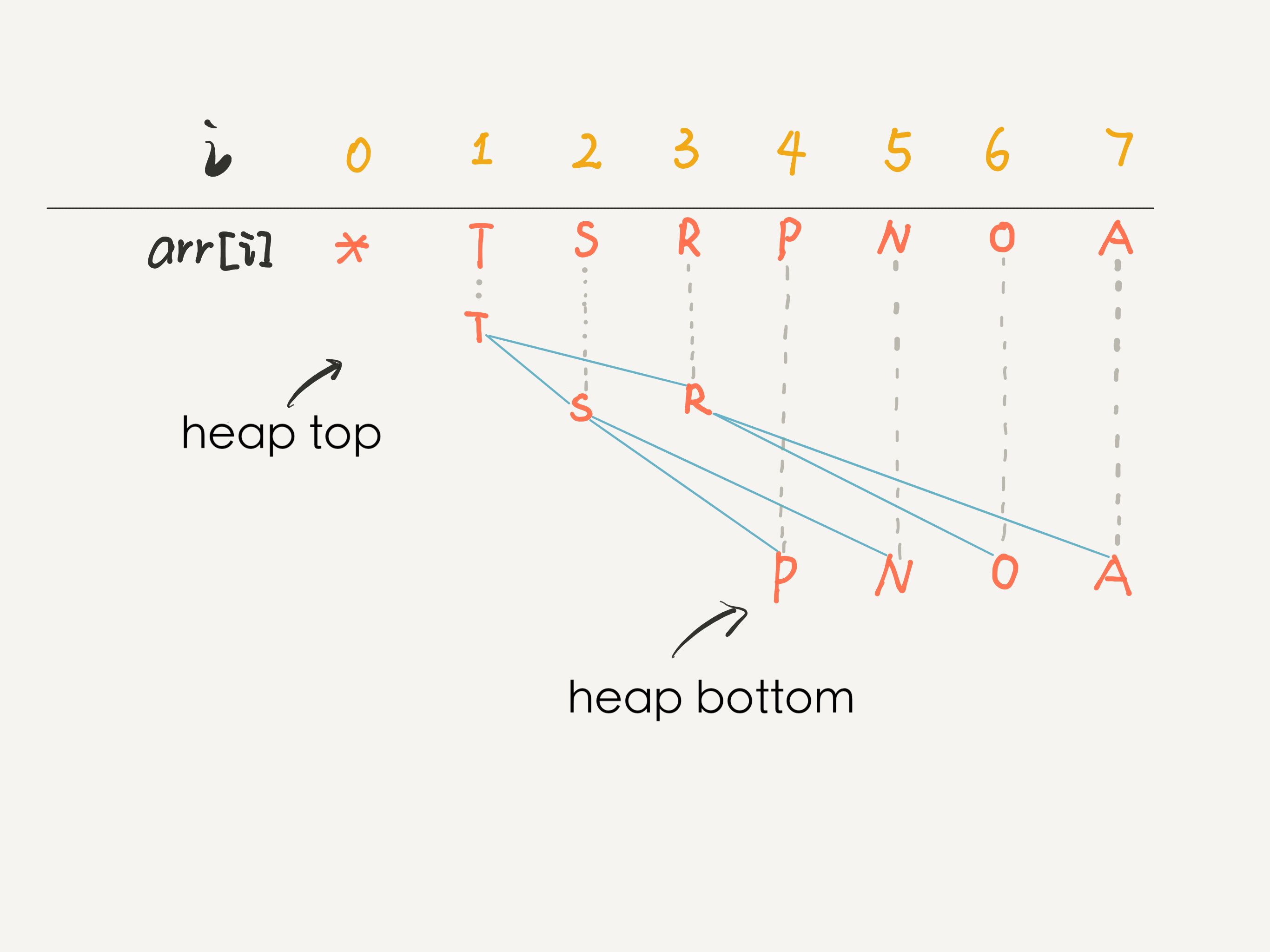
在数组上模拟二叉树: O ( N ) O(N) O ( N ) push 和 pop 方法的时间复杂度退化到 O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 ) 底层最右侧节点 。
完全二叉树是关键:必须是完全二叉树 。
在这个数组中,索引 0 空着不用,就可以根据任意节点的索引计算出父节点或左右子节点的索引:
1 2 3 4 5 6 7 8 9 10 11 12 int parent (int node) return node / 2 ; } int left (int node) return node * 2 ; } int right (int node) return node * 2 + 1 ; }
其实从 0 开始也是可以的,稍微改一改计算公式就行了。
完整实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 #include <iostream> #include <vector> using namespace std;class SimpleMinPQ { vector<int > heap; int size; static int parent (int node) return (node - 1 ) / 2 ; } static int left (int node) return node * 2 + 1 ; } static int right (int node) return node * 2 + 2 ; } void swim (int node) while (node > 0 && heap[parent (node)] > heap[node]) { swap (heap[parent (node)], heap[node]); node = parent (node); } } void sink (int node) while (left (node) < size || right (node) < size) { int min = node; if (left (node) < size && heap[left (node)] < heap[min]) { min = left (node); } if (right (node) < size && heap[right (node)] < heap[min]) { min = right (node); } if (min == node) { break ; } swap (heap[node], heap[min]); node = min; } } public : SimpleMinPQ (int capacity) { heap.resize (capacity); size = 0 ; } int getSize () const return size; } int peek () return heap[0 ]; } void push (int x) heap[size] = x; swim (size); size++; } int pop () int res = heap[0 ]; heap[0 ] = heap[size - 1 ]; size--; sink (0 ); return res; } }; int main () SimpleMinPQ pq (5 ) ; pq.push (3 ); pq.push (2 ); pq.push (1 ); pq.push (5 ); pq.push (4 ); cout << pq.pop () << endl; cout << pq.pop () << endl; cout << pq.pop () << endl; cout << pq.pop () << endl; cout << pq.pop () << endl; return 0 ; }
应用 2:堆排序
它的原理特别简单,就相当于把一个乱序的数组都 push 到一个二叉堆(优先级队列)里面,然后再一个个 pop 出来,就得到了一个有序的数组。
1 2 3 4 5 6 7 8 9 10 11 12 vector<int > heapSort (vector<int >& arr) { vector<int > res (arr.size()) ; MyPriorityQueue pq; for (int x : arr) pq.push (x); for (int i = 0 ; i < arr.size (); i++) res[i] = pq.pop (); return res; }
当然,正常的堆排序算法的代码并不依赖优先级队列,且空间复杂度是 O ( 1 ) O(1) O ( 1 ) push 和 pop 的代码逻辑展开了,再加上直接在数组上原地建堆,这样就不需要额外的空间了。二叉树 是一种逻辑概念 ,并不是说只有 TreeNode 类构造出来的那个结构才是二叉树,其实数组也可以抽象成一棵树,一切分治穷举的思想都可以抽象成一棵树,递归函数的那个递归栈也可以理解成一棵树。
5. 线段树
线段树是二叉树结构的衍生,用于高效解决区间查询和动态修改的问题。
区间查询:O ( log n ) O(\log n) O ( log n )
动态修改单个元素:O ( log n ) O(\log n) O ( log n )
这棵二叉树的叶子节点是数组中的元素,非叶子节点就是索引区间(线段)的汇总信息。
希望对整个区间进行查询,同时支持动态修改元素的场景,是线段树结构的应用场景。
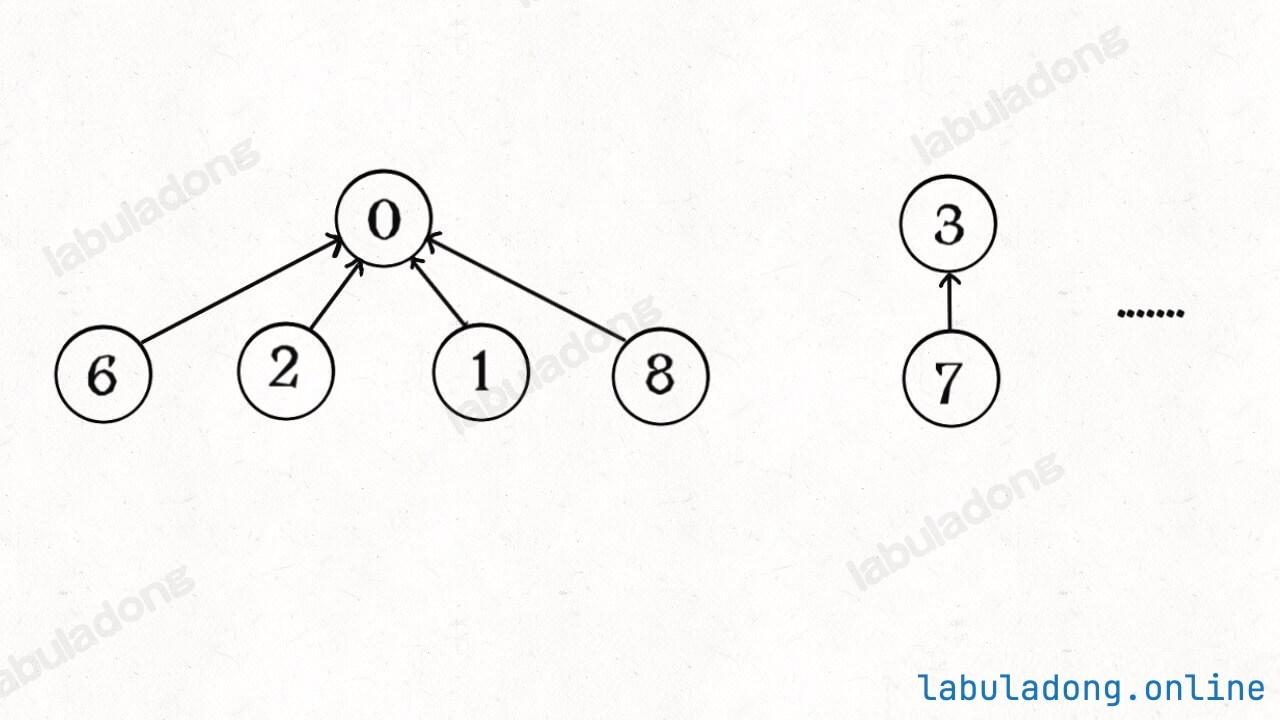
(九) 图论
1. 图结构
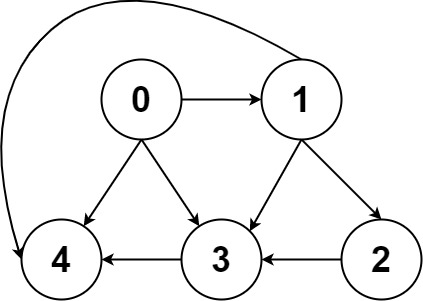
图结构就是 多叉树结构 的延伸。图结构逻辑上由若干节点(Vertex)和边(Edge)构成,我们一般用邻接表、邻接矩阵等方式来存储图。
在树结构中,只允许父节点指向子节点,不存在子节点指向父节点的情况,子节点之间也不会互相链接;而图中没有那么多限制,节点之间可以相互指向,形成复杂的网络结构。
图的逻辑结构:一幅图是由节点 (Vertex) 和边 (Edge) 构成的,逻辑结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Vertex {public : int id; std::vector<Vertex*> neighbors; }; vector<vector<int >> graph; vector<vector<bool >> matrix; class TreeNode {public : int val; std::vector<TreeNode*> children; };
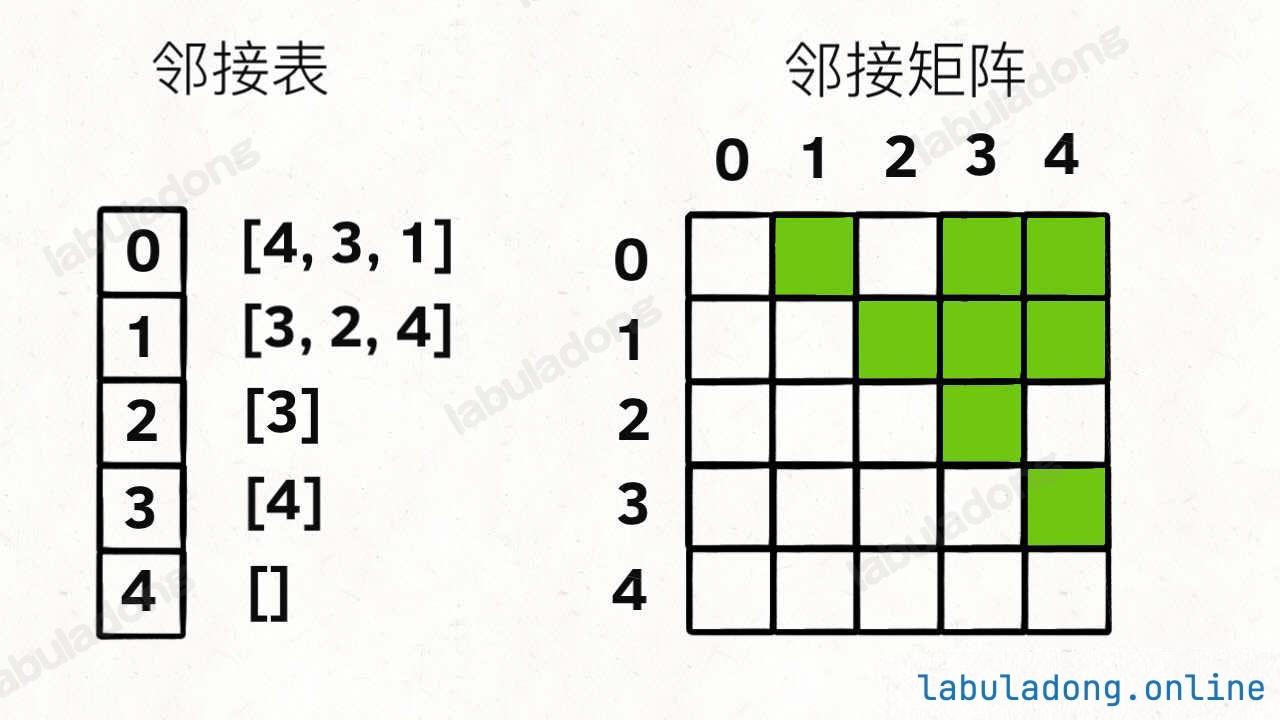
节点类型不是 int 怎么办? 哈希表 ,把实际节点和整数 id 映射起来,然后就可以用邻接表和邻接矩阵存储整数 id 了。对于一幅有 V V V E E E O ( V + E ) O(V+E) O ( V + E ) O ( V 2 ) O(V^2) O ( V 2 ) 邻接表 的使用更多一些。邻接矩阵的最大优势在于,矩阵是一个强有力的数学工具 ,图的一些隐晦性质可以借助精妙的矩阵运算展现出来。不过本文不准备引入数学内容,所以有兴趣的读者可以自行搜索学习。这也是为什么一定要把图节点类型转换成整数 id 的原因 ,不然的话你怎么用矩阵运算呢?
完整实现(邻接表):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <iostream> #include <vector> #include <stdexcept> using namespace std;class WeightedDigraph {public : struct Edge { int to; int weight; Edge (int to, int weight) { this ->to = to; this ->weight = weight; } }; private : vector<vector<Edge>> graph; public : WeightedDigraph (int n) { graph = vector<vector<Edge>>(n); } void addEdge (int from, int to, int weight) graph[from].emplace_back (to, weight); } void removeEdge (int from, int to) for (auto it = graph[from].begin (); it != graph[from].end (); ++it) { if (it->to == to) { graph[from].erase (it); break ; } } } bool hasEdge (int from, int to) for (const auto & e : graph[from]) { if (e.to == to) { return true ; } } return false ; } int weight (int from, int to) for (const auto & e : graph[from]) { if (e.to == to) { return e.weight; } } throw invalid_argument ("No such edge" ); } const vector<Edge>& neighbors (int v) return graph[v]; } }; int main () WeightedDigraph graph (3 ) ; graph.addEdge (0 , 1 , 1 ); graph.addEdge (1 , 2 , 2 ); graph.addEdge (2 , 0 , 3 ); graph.addEdge (2 , 1 , 4 ); cout << boolalpha << graph.hasEdge (0 , 1 ) << endl; cout << boolalpha << graph.hasEdge (1 , 0 ) << endl; for (const auto & edge : graph.neighbors (2 )) { cout << "2 -> " << edge.to << ", wight: " << edge.weight << endl; } graph.removeEdge (0 , 1 ); cout << boolalpha << graph.hasEdge (0 , 1 ) << endl; return 0 ; }
完整实现(邻接矩阵):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <iostream> #include <vector> class WeightedDigraph {public : struct Edge { int to; int weight; Edge (int to, int weight) : to (to), weight (weight) {} }; WeightedDigraph (int n) { matrix = std::vector<std::vector<int >>(n, std::vector <int >(n, 0 )); } void addEdge (int from, int to, int weight) matrix[from][to] = weight; } void removeEdge (int from, int to) matrix[from][to] = 0 ; } bool hasEdge (int from, int to) return matrix[from][to] != 0 ; } int weight (int from, int to) return matrix[from][to]; } std::vector<Edge> neighbors (int v) { std::vector<Edge> res; for (int i = 0 ; i < matrix[v].size (); i++) { if (matrix[v][i] > 0 ) { res.push_back (Edge (i, matrix[v][i])); } } return res; } private : std::vector<std::vector<int >> matrix; }; int main () WeightedDigraph graph (3 ) ; graph.addEdge (0 , 1 , 1 ); graph.addEdge (1 , 2 , 2 ); graph.addEdge (2 , 0 , 3 ); graph.addEdge (2 , 1 , 4 ); std::cout << std::boolalpha; std::cout << graph.hasEdge (0 , 1 ) << std::endl; std::cout << graph.hasEdge (1 , 0 ) << std::endl; for (const auto & edge : graph.neighbors (2 )) { std::cout << "2 -> " << edge.to << ", weight: " << edge.weight << std::endl; } graph.removeEdge (0 , 1 ); std::cout << graph.hasEdge (0 , 1 ) << std::endl; return 0 ; }
2. 图的遍历
图的遍历就是 多叉树遍历 的延伸,主要遍历方式还是深度优先搜索(DFS)和 广度优先搜索(BFS) 。
唯一的区别是,树结构中不存在环,而图结构中可能存在环 ,所以我们需要标记遍历过的节点 ,避免遍历函数在环中死循环。
遍历图的「节点」和「路径」略有不同,遍历「节点 」时,需要 visited 数组在前序位置 标记节点;遍历图的所有「路径 」时,需要 onPath 数组在前序位置 标记节点,在后序位置 撤销标记。
深度优先搜索(DFS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Node {public : int val; std::vector<Node*> children; }; void traverse (Node* root) if (root == nullptr ) { return ; } std::cout << "visit " << root->val << std::endl; for (auto child : root->children) { traverse (child); } } class Vertex {public : int id; std::vector<Vertex*> neighbors; }; void traverse (Vertex* s, std::vector<bool >& visited) if (s == nullptr ) { return ; } if (visited[s->id]) { return ; } visited[s->id] = true ; std::cout << "visit " << s->id << std::endl; for (auto neighbor : s->neighbors) { traverse (neighbor); } }
(2)遍历所有路径(onPath 数组)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 vector<bool > onPath (graph.size()) ;list<int > path; void traverse (Graph& graph, int src, int dest) if (src < 0 || src >= graph.size ()) { return ; } if (onPath[src]) { return ; } onPath[src] = true ; path.push_back (src); if (src == dest) { cout << "find path: " ; for (int node : path) { cout << node << " " ; } cout << endl; } for (const Edge& e : graph.neighbors (src)) { traverse (graph, e.to, dest); } path.pop_back (); onPath[src] = false ; }
(3)同时使用 visited 和 onPath 数组剪枝 ,提前排除一些不符合条件的路径,从而降低复杂度。
(4)完全不用 visited 和 onPath 数组题目告诉你输入的图结构不包含环 ,那么你就不需要考虑成环的情况了。
广度优先搜索(BFS)
图结构的广度优先搜索其实就是 多叉树的层序遍历 ,无非就是加了一个 visited 数组来避免重复遍历节点 。
理论上 BFS 遍历也需要区分遍历所有「节点」和遍历所有「路径」,但是实际上 BFS 算法一般只用来寻找那条最短路径 ,不会用来求所有路径。
(1)写法一:不记录遍历步数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } std::queue<Node*> q; q.push (root); while (!q.empty ()) { Node* cur = q.front (); q.pop (); std::cout << cur->val << std::endl; for (Node* child : cur->children) { q.push (child); } } } void bfs (const Graph& graph, int s) std::vector<bool > visited (graph.size(), false ) ; std::queue<int > q; q.push (s); visited[s] = true ; while (!q.empty ()) { int cur = q.front (); q.pop (); std::cout << "visit " << cur << std::endl; for (const Edge& e : graph.neighbors (cur)) { if (!visited[e.to]) { q.push (e.to); visited[e.to] = true ; } } } }
(2)写法二:记录遍历步数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } queue<Node*> q; q.push (root); int depth = 1 ; while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { Node* cur = q.front (); q.pop (); cout << "depth = " << depth << ", val = " << cur->val << endl; for (Node* child : cur->children) { q.push (child); } } depth++; } } void bfs (const Graph& graph, int s) vector<bool > visited (graph.size(), false ) ; queue<int > q; q.push (s); visited[s] = true ; int step = 0 ; while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { int cur = q.front (); q.pop (); cout << "visit " << cur << " at step " << step << endl; for (const Edge& e : graph.neighbors (cur)) { if (!visited[e.to]) { q.push (e.to); visited[e.to] = true ; } } } step++; } }
(3)写法三:适配不同权重边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 class State {public : Node* node; int depth; State (Node* node, int depth) : node (node), depth (depth) {} }; void levelOrderTraverse (Node* root) if (root == nullptr ) { return ; } queue<State> q; q.push (State (root, 1 )); while (!q.empty ()) { State state = q.front (); q.pop (); Node* cur = state.node; int depth = state.depth; cout << "depth = " << depth << ", val = " << cur->val << endl; for (Node* child : cur->children) { q.push (State (child, depth + 1 )); } } } class State {public : int node; int weight; State (int node, int weight) : node (node), weight (weight) {} }; void bfs (const Graph& graph, int s) vector<bool > visited (graph.size(), false ) ; queue<State> q; q.push (State (s, 0 )); visited[s] = true ; while (!q.empty ()) { State state = q.front (); q.pop (); int cur = state.node; int weight = state.weight; cout << "visit " << cur << " with path weight " << weight << endl; for (const Edge& e : graph.neighbors (cur)) { if (!visited[e.to]) { q.push (State (e.to, weight + e.weight)); visited[e.to] = true ; } } } }
3. 并查集
并查集 Union Find 是一种二叉树结构的衍生,用于高效解决无向图的连通性 问题。
查询两个节点是否连通:O ( 1 ) O(1) O ( 1 )
合并两个连通分量:O ( 1 ) O(1) O ( 1 )
查询连通分量的个数:O ( 1 ) O(1) O ( 1 )
你单纯去查邻接表/邻接矩阵,只能判断两个节点是否直接 相连,而无法处理这种传递 的连通关系。
如果我们想办法把同一个连通分量的节点 都放到同一棵树 中,把这棵树的根节点 作为这个连通分量的代表,那么我们就可以高效实现上面的操作了。
并查集底层其实是一片森林(若干棵多叉树) ,每棵树代表一个连通分量 :
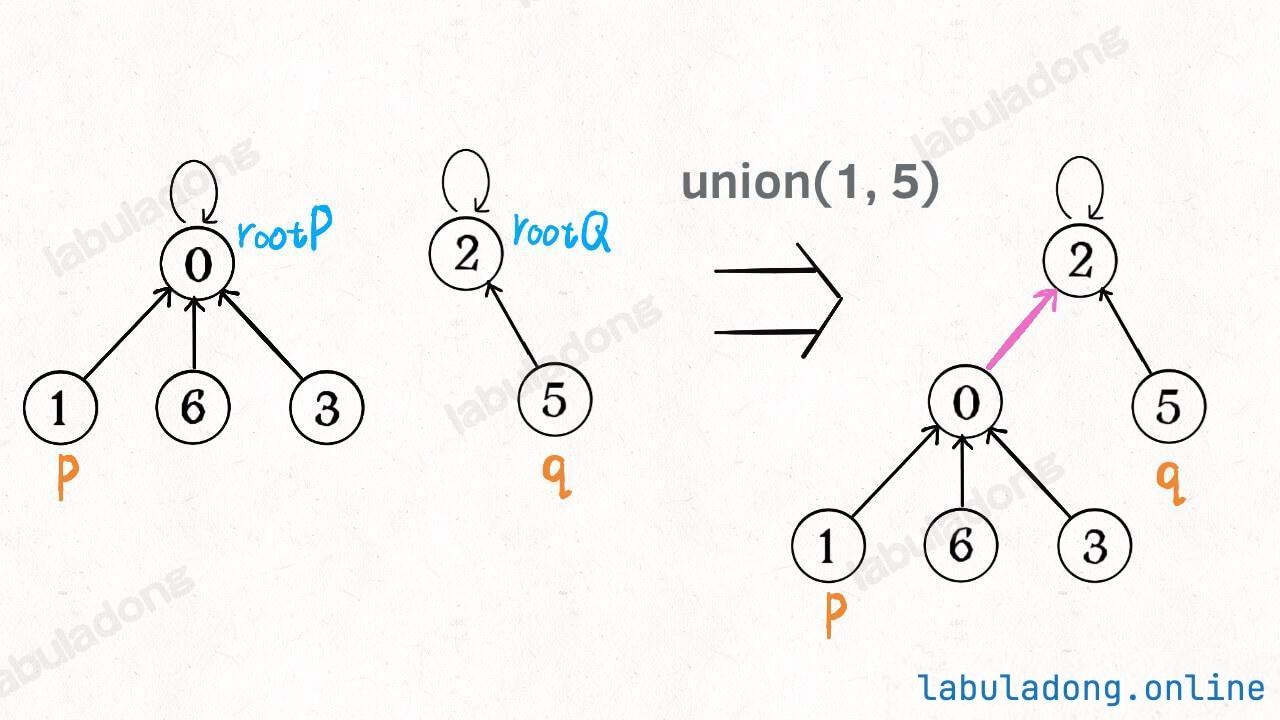
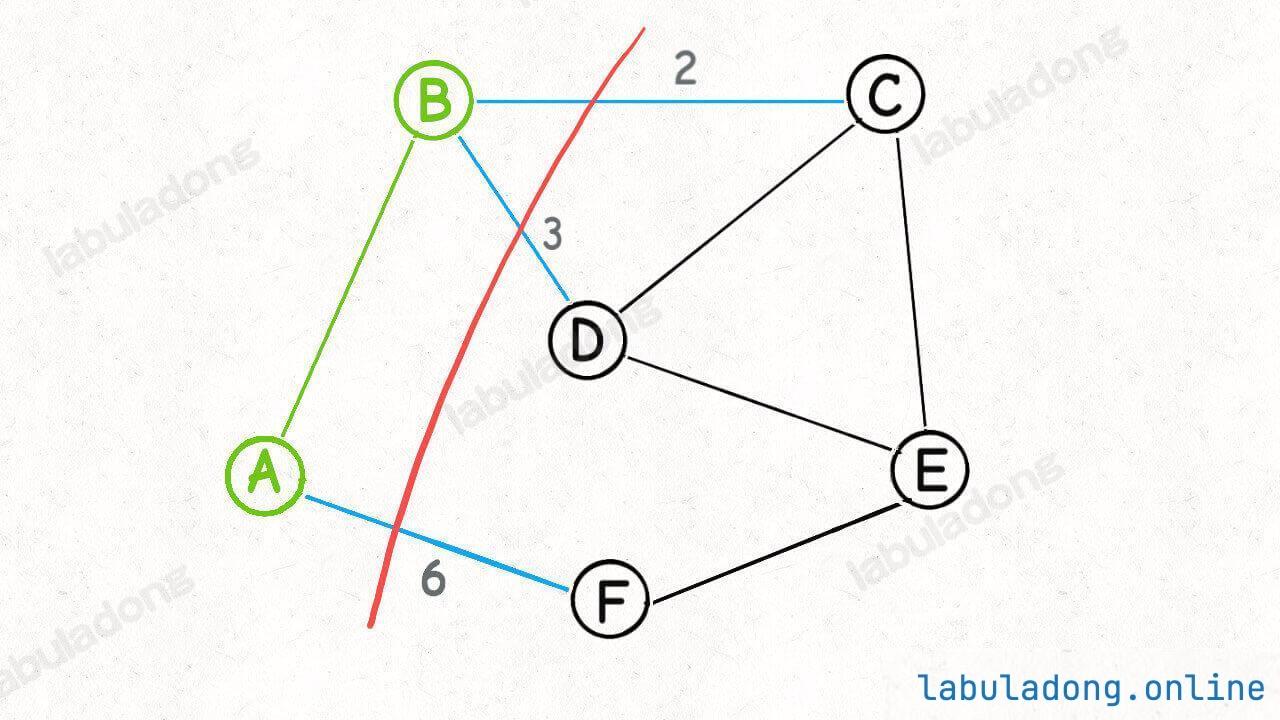
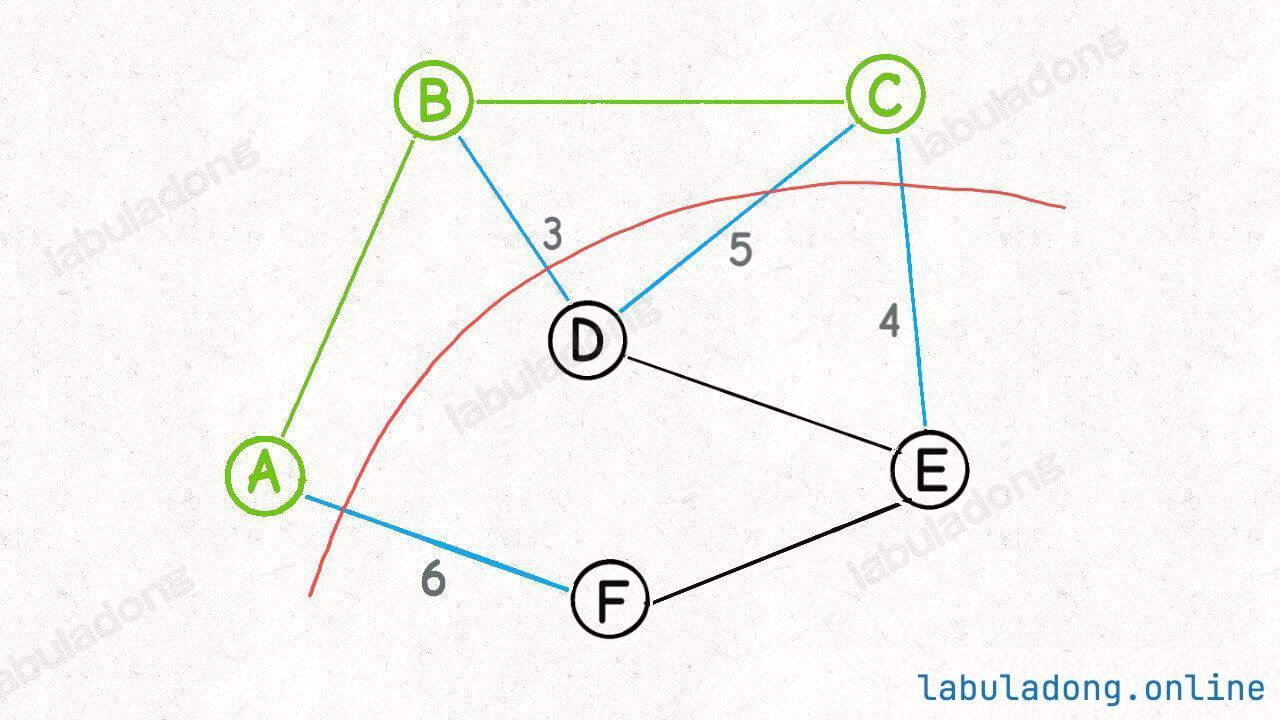
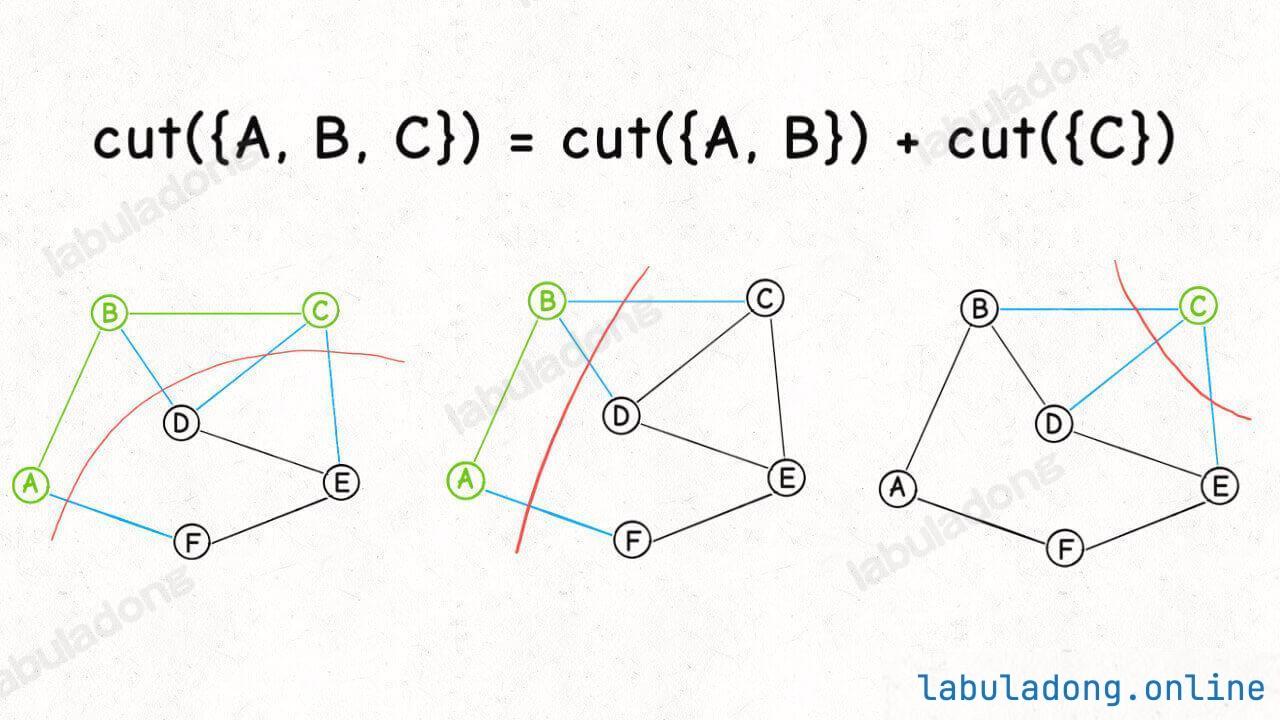
connected(p, q):只需要判断 p 和 q 所在的多叉树的根节点 ,若相同 ,则 p 和 q 在同一棵树中,即连通,否则不连通。count():只需要统计一下总共有多少棵树 ,即可得到连通分量的数量。union(p, q):只需要将 p 节点所在的这棵树的根节点,接入到 q 节点所在的这棵树的根节点下面,即可完成连接操作。注意这里并不是 p, q 两个节点的合并,而是两棵树根节点的合并 。因为 p, q 一旦连通,那么他们所属的连通分量就合并成了同一个更大的连通分量。每个节点其实不在乎自己的子节点是谁 ,只在乎自己的根节点是谁 ,所以一个并查集节点类似于下面这样:
所以并查集算法最终的目标 ,就是要尽可能降低树的高度 ,如果能保持树高为常数,那么上述方法的复杂度就都是 O ( 1 ) O(1) O ( 1 )
(1)权重数组的优化效果union 操作都是将节点个数较多的树接到了节点个数较少的树下面,这就很容易让树高增加,很不明智。一种优化思路是引入一个权重数组,记录以每个节点的为根的树的节点个数,然后在 union 方法中,总是将节点个数较少的树接到节点个数较多的树下面,这样可以保证树尽可能平衡,树高也就不会线性增长。
(2)路径压缩的优化效果O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 )
(十) 十大排序
排序算法的关键指标
时空复杂度
排序稳定性
是否原地排序
1. 选择排序
选择排序是最简单朴素的排序算法,但是时间复杂度较高,且不是稳定排序。其他基础排序算法都是基于选择排序的优化。
每次都去遍历选择最小的元素。
分析:
选择排序算法是个不稳定排序算法,因为每次都要交换最小元素和当前元素的位置,这样可能会改变相同元素的相对位置。
选择排序的时间复杂度和初始数据的有序度完全没有关系,即便输入的是一个已经有序的数组,选择排序的时间复杂度依然是 O ( n 2 ) O(n^2) O ( n 2 )
选择排序的时间复杂度是 O ( n 2 ) O(n^2) O ( n 2 ) n 2 / 2 n^2 / 2 n 2 /2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void sort (vector<int >& nums) int n = nums.size (); int sortedIndex = 0 ; while (sortedIndex < n) { int minIndex = sortedIndex; for (int i = sortedIndex + 1 ; i < n; i++) { if (nums[i] < nums[minIndex]) { minIndex = i; } } int tmp = nums[sortedIndex]; nums[sortedIndex] = nums[minIndex]; nums[minIndex] = tmp; sortedIndex++; } }
2. 冒泡排序(解决稳定)
冒泡算法是对 选择排序 的一种优化,通过交换 nums[sortedIndex] 右侧的逆序对完成排序,是一种稳定 排序算法。
优化的方向就在这里,你不要图省事儿直接把本次查找的最小的直接一次交换到前面;而应该一步一步交换,慢慢到最前面。
这个算法的名字叫做冒泡排序,因为它的执行过程就像从数组尾部向头部冒出水泡,每次都会将最小值顶到正确的位置。
如果一次交换操作都没有进行,说明数组已经有序,可以提前终止算法。
唯一的遗憾是,时间复杂度依然是 O ( n 2 ) O(n^2) O ( n 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void sort (int [] nums) int n = nums.length; int sortedIndex = 0 ; while (sortedIndex < n) { for (int i = n - 1 ; i > sortedIndex; i--) { if (nums[i] < nums[i - 1 ]) { int tmp = nums[i]; nums[i] = nums[i - 1 ]; nums[i - 1 ] = tmp; } } sortedIndex++; } }
3. 插入排序(逆向提高效率)
插入排序是基于 选择排序 的一种优化,将 nums[sortedIndex] 插入到左侧的有序数组中。对于有序度较高的数组,插入排序的效率比较高。
选择排序和冒泡排序是在 nums[sortedIndex..] 中找到最小值,然后将其插入到 nums[sortedIndex] 的位置。
那么我们能不能反过来想,在 nums[0..sortedIndex-1] 这个部分有序的数组中,找到 nums[sortedIndex] 应该插入的位置插入。
这个算法的名字叫做插入排序,它的执行过程就像是打扑克牌时,将新抓到的牌插入到手中已经排好序的牌中。
插入排序的空间复杂度 是 O ( 1 ) O(1) O ( 1 ) 原地 排序算法。时间复杂度 是 O ( n 2 ) O(n^2) O ( n 2 ) n 2 / 2 n^2 / 2 n 2 /2
插入排序是一种稳定 排序,因为只有在 nums[i] < nums[i - 1] 的情况下才会交换元素,所以相同元素的相对位置不会发生改变。
初始有序度越高,效率越高。插入排序的综合性能应该要高于冒泡排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void sort (int [] nums) int n = nums.length; int sortedIndex = 0 ; while (sortedIndex < n) { for (int i = sortedIndex; i > 0 ; i--) { if (nums[i] < nums[i - 1 ]) { int tmp = nums[i]; nums[i] = nums[i - 1 ]; nums[i - 1 ] = tmp; } else { break ; } } sortedIndex++; } }
4. 希尔排序(突破n^2)
希尔排序是基于 插入排序 的简单改进,通过预处理增加数组的局部有序性,突破了插入排序的 O ( N 2 ) O(N^2) O ( N 2 )
希尔排序是不稳定 排序。这个比较容易理解吧,当 h 大于 1 时进行的排序操作,就可能打乱相同元素的相对位置了。
空间复杂度是 O ( 1 ) O(1) O ( 1 ) 原地 排序算法。
希尔排序的时间复杂度是小于 O ( N 2 ) O(N^2) O ( N 2 )
h 有序数组:一个数组是 h 有序的,是指这个数组中任意间隔为 h(或者说间隔元素的个数为 h-1)的元素都是有序的。当一个数组完成排序的时候,其实就是 1 有序数组。
1 2 3 4 5 6 7 8 9 nums: [1, 2, 4, 3, 5, 7, 8, 6, 10, 9, 12, 11] ^--------^--------^---------^ ^--------^--------^---------^ ^--------^--------^----------^ 1--------3--------8---------9 2--------5--------6---------12 4--------7--------10---------11
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void sort (int [] nums) int n = nums.length; int h = 1 ; while (h < n / 2 ) { h = 2 * h; } while (h >= 1 ) { int sortedIndex = h; while (sortedIndex < n) { for (int i = sortedIndex; i >= h; i -= h) { if (nums[i] < nums[i - h]) { int tmp = nums[i]; nums[i] = nums[i - h]; nums[i - h] = tmp; } else { break ; } } sortedIndex++; } h /= 2 ; } }
希尔排序的性能和递增函数的选择 有很大关系,上面的代码中我们使用的递增函数是 2 k − 1 2^k−1 2 k − 1 ( 3 k − 1 ) / 2 (3^k−1)/2 ( 3 k − 1 ) /2 1,4,13,40,121,364...
1 2 3 4 5 6 7 8 9 10 int h = 1 ;while (h < n / 3 ) { h = 3 * h + 1 ; } .... h /= 3 ; ....
5. 快速排序(二叉树前序位置)
快速排序的核心思路需要结合 二叉树的前序遍历 来理解:在二叉树遍历的前序位置将一个元素排好位置,然后递归地将剩下的元素排好位置。
快速排序的思路是:先把一个元素排好序,然后去把剩下的元素排好序。
任意选择一个元素作为切分元素 pivot(一般选择第一个元素)
对数组中的元素进行若干交换操作,将小于 pivot 的元素放到 pivot 的左边,大于 pivot 的元素放到 pivot 的右边(换句话说,其实就是将 pivot 这一个元素排好序 )
递归的去把 pivot 左右两侧的其他元素排好序 。
本质是二叉树的前序遍历,在前序位置将 nums[p] 排好序,然后递归排序左右元素
其中 partition 函数的实现是快速排序的核心,即遍历 nums[lo..hi],将切分点元素 pivot 放到正确的位置,并返回该位置的索引 p。
每层元素总和仍然是 O ( n ) O(n) O ( n ) O ( log n ) O(\log n) O ( log n ) O ( n log n ) O(n\log n) O ( n log n )
快速排序不需要额外的辅助空间,是原地排序算法。递归遍历二叉树时,递归函数的堆栈深度为树的高度,所以空间复杂度是 O ( log n ) O(\log n) O ( log n )
快速排序是不稳定 排序算法,因为在 partition 函数中,不会考虑相同元素的相对位置。
1 2 3 4 5 6 7 8 9 10 11 void sort (int nums[], int lo, int hi) if (lo >= hi) { return ; } int p = partition (nums, lo, hi); sort (nums, lo, p - 1 ); sort (nums, p + 1 , hi); }
6. 归并排序(二叉树后序位置)
归并排序的核心思路需要结合 二叉树的后序遍历 来理解:先利用递归把左右两半子数组排好序,然后在二叉树的后序位置合并 两个有序数组。
归并排序的稳定性取决于 merge 函数的实现,需要用到 双指针技巧 ,是稳定 排序。
每层元素总和仍然是 O ( n ) O(n) O ( n ) O ( log n ) O(\log n) O ( log n ) O ( n log n ) O(n\log n) O ( n log n )
不是原地 排序。归并排序的 merge 函数需要一个额外的数组来辅助进行有序数组的合并操作,消耗 O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void sort (int [] nums, int lo, int hi) if (lo == hi) { return ; } int mid = (lo + hi) / 2 ; sort (nums, lo, mid); sort (nums, mid + 1 , hi); merge (nums, lo, mid, hi); }
7. 堆排序(运用二叉堆)
堆排序是从 二叉堆结构 衍生出来的排序算法,复杂度为 O ( N log N ) O(N\log N) O ( N log N )
堆排序主要分两步,第一步是在待排序数组上原地创建二叉堆 (Heapify),然后进行原地排序 (Sort)。
堆排序是一种不稳定 的排序算法,因为二叉堆本质上是把数组结构抽象成了二叉树结构,在二叉树逻辑结构上的元素交换操作映射回数组上,无法顾及相同元素的相对位置。
分析:
二叉堆(优先级队列)底层是用数组 实现的,但是逻辑上是一棵完全二叉树 ,主要依靠 上浮swim, 下沉sink 方法来维护堆的性质。
优先级队列可以分为小顶堆 和大顶堆 ,小顶堆会将整个堆中最小的元素维护在堆顶,大顶堆会将整个堆中最大的元素维护在堆顶。
优先级队列插入 元素时:首先把元素追加到二叉堆底部 ,然后调用 swim 方法把该元素上浮 到合适的位置,时间复杂度是 O ( log N ) O(\log N) O ( log N )
优先级队列删除 堆顶元素时:首先把堆底的最后一个元素交换到堆顶 作为新的堆顶元素,然后调用 sink 方法把这个新的堆顶元素下沉 到合适的位置,时间复杂度是 O ( log N ) O(\log N) O ( log N )
那么最简单的堆排序算法思路就是直接利用优先级队列,把所有元素塞到优先级队列里面,然后再取出来,就完成排序了。
优先级队列的 push, pop 方法的复杂度都是 O ( log N ) O(\log N) O ( log N ) O ( N log N ) O(N\log N) O ( N log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void sort (int [] nums) SimpleMinPQ pq = new SimpleMinPQ (nums.length); for (int num : nums) { pq.push (num); } for (int i = 0 ; i < nums.length; i++) { nums[i] = pq.pop (); } }
堆排序的两个关键步骤:
原地建堆(Heapify):直接把待排序数组原地变成一个二叉堆。
排序(Sort):将元素不断地从堆中取出,最终得到有序的结果。
时间复杂度,假设 nums 的元素个数为 N:
第一步建堆的过程中,swim 方法的时间复杂度是 O ( log N ) O(\log N) O ( log N ) swim 方法,所以总时间复杂度是 O ( N log N ) O(N\log N) O ( N log N )
第二步排序的过程中,每次 sink 方法的时间复杂度是 O ( log N ) O(\log N) O ( log N ) sink 方法,所以总时间复杂度是 O ( N log N ) O(N\log N) O ( N log N ) O ( N log N ) O(N\log N) O ( N log N )
空间复杂度是 O ( 1 ) O(1) O ( 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 void minHeapSwim (std::vector<int >& heap, int node) while (node > 0 && heap[parent (node)] > heap[node]) { swap (heap, parent (node), node); node = parent (node); } } void minHeapSink (std::vector<int >& heap, int node, int size) while (left (node) < size || right (node) < size) { int min = node; if (left (node) < size && heap[left (node)] < heap[min]) { min = left (node); } if (right (node) < size && heap[right (node)] < heap[min]) { min = right (node); } if (min == node) { break ; } swap (heap, node, min); node = min; } } void maxHeapSwim (std::vector<int >& heap, int node) while (node > 0 && heap[parent (node)] < heap[node]) { swap (heap, parent (node), node); node = parent (node); } } void maxHeapSink (std::vector<int >& heap, int node, int size) while (left (node) < size || right (node) < size) { int max = node; if (left (node) < size && heap[left (node)] > heap[max]) { max = left (node); } if (right (node) < size && heap[right (node)] > heap[max]) { max = right (node); } if (max == node) { break ; } swap (heap, node, max); node = max; } } int parent (int node) return (node - 1 ) / 2 ; } int left (int node) return node * 2 + 1 ; } int right (int node) return node * 2 + 2 ; } void swap (std::vector<int >& heap, int i, int j) int temp = heap[i]; heap[i] = heap[j]; heap[j] = temp; } void sort (std::vector<int >& nums) for (int i = 0 ; i < nums.size (); i++) { maxHeapSwim (nums, i); } int heapSize = nums.size (); while (heapSize > 0 ) { swap (nums, 0 , heapSize - 1 ); heapSize--; maxHeapSink (nums, 0 , heapSize); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void sort (int [] nums) for (int i = 0 ; i < nums.length; i++) { maxHeapSwim (nums, i); } int heapSize = nums.length; while (heapSize > 0 ) { swap (nums, 0 , heapSize - 1 ); heapSize--; maxHeapSink (nums, 0 , heapSize); } }
再优化:对于一个二叉堆来说,其左右子堆(子树)也是一个二叉堆 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void sort (vector<int >& nums) int n = nums.size (); for (int i = n / 2 - 1 ; i >= 0 ; i--) { maxHeapSink (nums, i, n); } int heapSize = n; while (heapSize > 0 ) { swap (nums, 0 , heapSize - 1 ); heapSize--; maxHeapSink (nums, 0 , heapSize); } }
8. 计数排序(新原理)
计数排序的原理比较简单:统计每种元素出现的次数,进而推算出每个元素在排序后数组中的索引位置,最终完成排序。
在它的算法思想中同时看到前面讲的 归并排序 和 计数排序 的影子。
计数排序的时间和空间复杂度都是 O ( n + m a x − m i n ) ,其中 n 是待排序数组长度, m a x − m i n 是待排序数组的元素范围 O(n+max−min),其中 n 是待排序数组长度,max−min 是待排序数组的元素范围 O ( n + ma x − min ) ,其中 n 是待排序数组长度, ma x − min 是待排序数组的元素范围
处理负数和自定义类型:简单映射技巧
非比较排序:计数排序都不需要比较元素的大小,代码中不包含 if (nums[i] > nums[j]) 这样的比较逻辑,那么到底是什么让他能够完成排序呢?答案是,它依靠数组索引的有序性 ,所以不用对元素进行比较。(也因此,不能使用哈希表作为 count计数数组。
计数排序以及后面介绍到的其他非比较排序算法,在特定场景下的时间复杂度是线性 的O ( n ) O(n) O ( n )
9. 桶排序(博采众长)
桶排序算法的核心思想分三步:
将待排序数组中的元素使用映射函数 分配到若干个「桶 」中。
对每个桶 中的元素进行排序 。
最后将这些排好序的桶进行合并 ,得到排序结果。
求模的方法不可行,我们需要用除法向下取整 的方式来将元素分配到桶 中。
对于桶合并可以有多种排序方法:使用插入排序的桶排序、使用递归的桶排序。
桶排序的稳定性主要取决于对每个桶的排序 算法。
空间复杂度是 O ( n + k ) O(n+k) O ( n + k ) O ( n + k ) O(n+k) O ( n + k ) O ( n 2 ) O(n^2) O ( n 2 )
10. 基数排序(Radix Sort)
基数排序是 计数排序 算法的扩展,它的主要思路是对待排序元素的每一位依次进行计数排序。由于计数排序是稳定的,所以对每一位完成计数排序后,所有元素就完成了排序。
基数排序的原理很简单,比方说输入的数组都是三位数 nums = [329, 457, 839, 439, 720, 355, 350],我们先按照个位 数排序,然后按照十位 数排序,然后按照百位 数排序,最终就完成了整个数组的排序。这里面的关键在于,对每一位的排序都必须是稳定排序,否则最终结果就不对了。
使用什么稳定排序比较好?计数排序,复杂度O ( n + 10 ) O(n+10) O ( n + 10 )
位数不同怎么办?前缀补 0
有负数?正数分数分开排序
采用 LSD 算法(Least Significant Digit first,最低位优先)。对应的是 MSD(Most Significant Digit first,最高位优先)
对于 LSD 基数排序,由于对每一位的排序都是稳定的,所以最终的排序结果也是稳定 的。
假设待排序数组长度为 n,最大元素的位数为 m,LSD 计数排序本质上就是执行了 m 次计数排序。前文分析过,计数排序的时空复杂度都是 O ( n + m a x − m i n ) O(n+max−min) O ( n + ma x − min ) m a x − m i n max−min ma x − min 10,可以忽略,所以每次计数排序的时空复杂度都是 O ( n ) O(n) O ( n ) O ( m n ) O(mn) O ( mn ) O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 void radixSortLSD (std::vector<int >& nums) int min = INT_MAX; for (int num : nums) { min = std::min (min, num); } int offset = -min; for (int i = 0 ; i < nums.size (); i++) { nums[i] += offset; } int max = INT_MIN; for (int num : nums) { max = std::max (max, num); } int maxLen = 0 ; while (max > 0 ) { max /= 10 ; maxLen++; } for (int k = 0 ; k < maxLen; k++) { countSort (nums, k); } for (int i = 0 ; i < nums.size (); i++) { nums[i] -= offset; } } void countSort (std::vector<int >& nums, int k) std::vector<int > count (10 , 0 ) ; for (int num : nums) { int digit = (num / static_cast <int >(std::pow (10 , k))) % 10 ; count[digit]++; } for (int i = 1 ; i < count.size (); i++) { count[i] += count[i - 1 ]; } std::vector<int > sorted (nums.size()) ; for (int i = nums.size () - 1 ; i >= 0 ; i--) { int digit = (nums[i] / static_cast <int >(std::pow (10 , k))) % 10 ; sorted[count[digit] - 1 ] = nums[i]; count[digit]--; } for (int i = 0 ; i < nums.size (); i++) { nums[i] = sorted[i]; } }
第零章、核心刷题框架汇总
(零) 万剑归宗
几句话总结一切数据结构和算法:
种种数据结构,皆为数组 (顺序存储)和链表 (链式存储)的变换。
数据结构的关键点在于遍历和访问 ,即增删查改等基本操作。
种种算法,皆为穷举 。
穷举的关键点在于无遗漏和无冗余 。熟练掌握算法框架,可以做到无遗漏;充分利用信息,可以做到无冗余。
鞭辟入里:原文链接
1. 数据结构的存储
队列、栈 这两种数据结构既可以使用链表也可以使用数组实现。用数组实现,就要处理扩容缩容的问题;用链表实现,没有这个问题,但需要更多的内存空间存储节点指针。图结构 的两种存储方式,邻接表就是链表,邻接矩阵就是二维数组。邻接矩阵判断连通性迅速,并可以进行矩阵运算解决一些问题,但是如果图比较稀疏的话很耗费空间。邻接表比较节省空间,但是很多操作的效率上肯定比不过邻接矩阵。哈希表 就是通过散列函数把键映射到一个大数组里。而且对于解决散列冲突的方法,拉链法 需要链表特性,操作简单,但需要额外的空间存储指针;线性探查法 需要数组特性,以便连续寻址,不需要指针的存储空间,但操作稍微复杂些。树结构 ,用数组实现就是「堆」,因为「堆」是一个完全二叉树,用数组存储不需要节点指针,操作也比较简单,经典应用有 二叉堆;用链表实现就是很常见的那种「树」,因为不一定是完全二叉树,所以不适合用数组存储。为此,在这种链表「树」结构之上,又衍生出各种巧妙的设计,比如 二叉搜索树、AVL 树、红黑树、区间树、B 树等等,以应对不同的问题。
综上,数据结构种类很多,甚至你也可以发明自己的数据结构,但是底层存储无非数组或者链表,二者的优缺点如下:
数组 由于是紧凑连续存储,可以随机访问,通过索引快速找到对应元素,而且相对节约存储空间。但正因为连续存储,内存空间必须一次性分配够,所以说数组如果要扩容,需要重新分配一块更大的空间,再把数据全部复制过去,时间复杂度 O(N);而且你如果想在数组中间进行插入和删除,每次必须搬移后面的所有数据以保持连续,时间复杂度 O ( N ) O(N) O ( N )
链表 因为元素不连续,而是靠指针指向下一个元素的位置,所以不存在数组的扩容问题;如果知道某一元素的前驱和后驱,操作指针即可删除该元素或者插入新元素,时间复杂度 O ( 1 ) O(1) O ( 1 )
2. 数据结构的操作
线性 就是 for/while 迭代为代表,非线性 就是递归为代表。
数组 遍历框架,典型的线性迭代结构:
1 2 3 4 5 void traverse (vector<int >& arr) for (int i = 0 ; i < arr.size (); i++) { } }
链表 遍历框架,兼具迭代和递归结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class ListNode { public : int val; ListNode* next; }; void traverse (ListNode* head) for (ListNode* p = head; p != nullptr ; p = p->next) { } } void traverse (ListNode* head) traverse (head->next); }
二叉树 遍历框架,典型的非线性递归遍历结构:
1 2 3 4 5 6 7 8 9 10 11 struct TreeNode { int val; TreeNode* left; TreeNode* right; }; void traverse (TreeNode* root) traverse (root->left); traverse (root->right); }
二叉树框架可以扩展为 N 叉树的遍历框架:
1 2 3 4 5 6 7 8 9 10 11 class TreeNode {public : int val; vector<TreeNode*> children; }; void traverse (TreeNode* root) for (TreeNode* child : root->children) traverse (child); }
图 :N 叉树的遍历又可以扩展为图的遍历,因为图就是好几 N 叉棵树的结合体 。visited 做标记就行了。
3. 算法的本质
4. 穷举的难点
穷举有两个关键难点:无遗漏 、无冗余 。
当你看到一道算法题,可以从这两个维度去思考:
如何穷举?即无遗漏地穷举所有可能解。
如何聪明地穷举?即避免所有冗余的计算,消耗尽可能少的资源求出答案。
后续会有的系列:
数组/单链表系列算法:单指针、双指针、二分搜索、滑动窗口、前缀和、差分数组。
二叉树系列算法:动态规划、回溯(DFS)、层序(BFS)、分治。附加技巧剪枝、备忘录。
图系列算法:二叉树算法的延续。
(一) 双指针(链表)
技巧目录:
1、合并两个有序链表
链接:合并两个有序链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public : ListNode* mergeTwoLists (ListNode* l1, ListNode* l2) { ListNode dummy (-1 ) , *p = &dummy; ListNode *p1 = l1, *p2 = l2; while (p1 != nullptr && p2 != nullptr ) { if (p1->val > p2->val) { p->next = p2; p2 = p2->next; } else { p->next = p1; p1 = p1->next; } p = p->next; } if (p1 != nullptr ) p->next = p1; if (p2 != nullptr ) p->next = p2; return dummy.next; } };
什么时候需要用虚拟头结点?当你需要创造一条新链表 的时候,可以使用虚拟头结点 简化边界情况的处理。
2、单链表的分解
链接:分割链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public : ListNode* partition (ListNode* head, int x) { ListNode* dummy1 = new ListNode (-1 ); ListNode* dummy2 = new ListNode (-1 ); ListNode* p1 = dummy1, *p2 = dummy2; ListNode* p = head; while (p != nullptr ) { if (p->val >= x) { p2->next = p; p2 = p2->next; } else { p1->next = p; p1 = p1->next; } ListNode* temp = p->next; p->next = nullptr ; p = temp; } p1->next = dummy2->next; return dummy1->next; } };
3、合并 k 个有序链表
链接:合并k个有序链表
合并 k 个有序链表的逻辑类似合并两个有序链表,难点在于,如何快速得到 k 个节点中的最小节点,接到结果链表上?优先级队列 这种数据结构,把链表节点放入一个最小堆 ,就可以每次获得 k 个节点中的最小节点 。
优先队列 pq 中的元素个数最多是 k,所以一次 push 或者 pop 方法的时间复杂度是 O ( log k ) O(\log k) O ( log k ) O ( N log k ) 其中 k 是链表的条数, N 是这些链表的节点总数 O(N\log k)其中 k 是链表的条数,N 是这些链表的节点总数 O ( N log k ) 其中 k 是链表的条数, N 是这些链表的节点总数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : ListNode* mergeKLists (vector<ListNode*>& lists) { if (lists.empty ()) return NULL ; ListNode* dumy = new ListNode (); ListNode* p = dumy; auto cmp = [](ListNode* a, ListNode* b){ return a->val > b->val; }; priority_queue<ListNode*, vector<ListNode*>, decltype (cmp)> heap; for (ListNode* t: lists) if (t != NULL ) heap.push (t); while (!heap.empty ()){ ListNode* minp = heap.top (); heap.pop (); p->next = minp; p = p->next; if (minp->next != NULL ) heap.push (minp->next); } p->next = NULL ; return dumy->next; } };
4、单链表的倒数第 k 个节点
那你可能说,假设链表有 n 个节点,倒数第 k 个节点就是正数第 n - k + 1 个节点,不也是一个 for 循环的事儿吗?
这个解法需要遍历两次链表才能得到出倒数第 k 个节点。
能不能只遍历一次 链表,就算出倒数第 k 个节点?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : ListNode* findFromEnd (ListNode* head, int k) { ListNode* p1 = head; for (int i=0 ; i<k; i++) p1 = p1->next; ListNode* p2 = head; while (p1 != NULL ){ p1 = p1->next; p2 = p2->next; } return p2; } ListNode* removeNthFromEnd (ListNode* head, int n) { ListNode* dummy = new ListNode (); dummy->next = head; ListNode* p = findFromEnd (dummy, n+1 ); p->next = p->next->next; return dummy->next; } };
无论遍历一次链表和遍历两次链表的时间复杂度都是 O ( N ) O(N) O ( N ) 技巧性 。
我们又使用了虚拟头结点的技巧,也是为了防止出现空指针的情况,比如说链表总共有 5 个节点,题目就让你删除倒数第 5 个节点,也就是第一个节点,那按照算法逻辑,应该首先找到倒数第 6 个节点。但第一个节点前面已经没有节点了,这就会出错。
5、单链表的中点
参考:中点
我们让两个指针 slow 和 fast 分别指向链表头结点 head。每当慢指针 slow 前进一步,快指针 fast 就前进两步,这样,当 fast 走到链表末尾时,slow 就指向了链表中点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public : ListNode* middleNode (ListNode* head) { ListNode* slow = head; ListNode* fast = head; while (fast != nullptr && fast->next != nullptr ) { slow = slow->next; fast = fast->next->next; } return slow; } };
6、判断链表是否包含环
参考:判断环
判断链表是否包含环属于经典问题了,解决方案也是用快慢指针:slow 前进一步,快指针 fast 就前进两步。
如果 fast 最终能正常走到链表末尾,说明链表中没有环;
如果 fast 走着走着竟然和 slow 相遇了,那肯定是 fast 在链表中转圈了,说明链表中含有环。
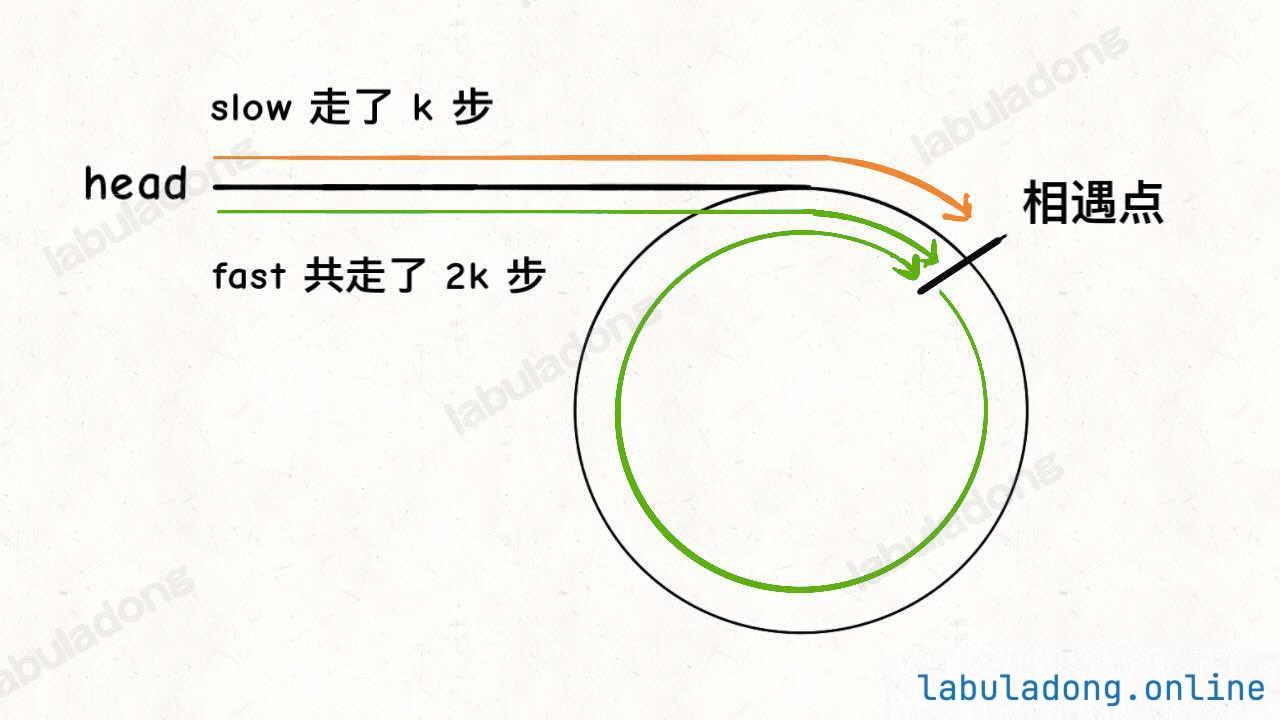
如果链表中含有环,如何计算这个环的起点?
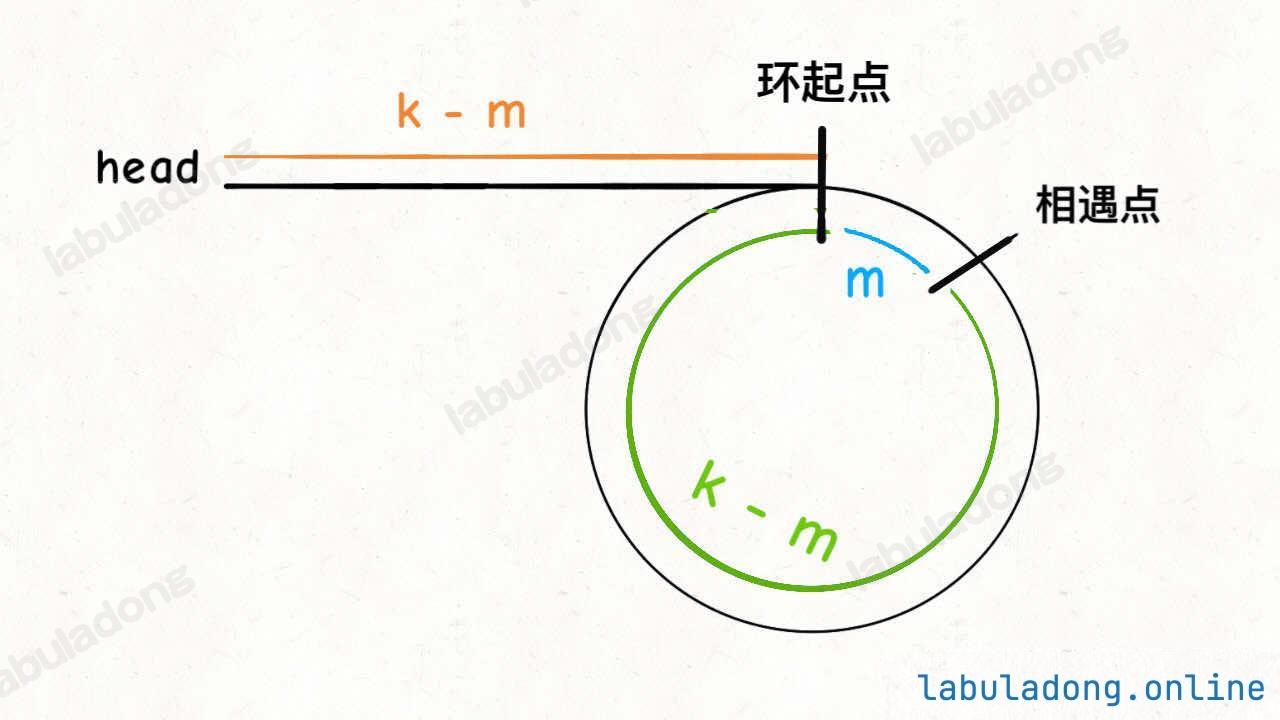
fast 一定比 slow 多走了 k 步,这多走的 k 步其实就是 fast 指针在环里转圈圈,所以 k 的值就是环长度 的「整数倍」。假设相遇点距环的起点的距离为 m,那么结合上图的 slow 指针,环的起点距头结点 head 的距离为 k - m,也就是说如果从 head 前进 k - m 步就能到达环起点。
巧的是,如果从相遇点继续前进 k - m 步,也恰好到达环起点。因为结合上图的 fast 指针,从相遇点开始走 k 步可以转回到相遇点,那走 k - m 步肯定就走到环起点了
所以,只要我们把快慢指针中的任一个重新指向 head,然后两个指针同速前进,k - m 步后一定会相遇,相遇之处就是环的起点了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : ListNode *detectCycle (ListNode *head) { ListNode* slow = head; ListNode* fast = head; while (fast != NULL && fast->next != NULL ){ slow = slow->next; fast = fast->next->next; if (slow == fast) break ; } if (fast == NULL || fast->next == NULL ) return NULL ; slow = head; while (slow != fast){ slow = slow->next; fast = fast->next; } return slow; } };
7、两个链表是否相交
参考:相交
这个题直接的想法可能是用 HashSet 记录一个链表的所有节点 ,然后和另一条链表对比 ,但这就需要额外的空间。
如果不用额外的空间,只使用两个指针,你如何做呢?难点在于,由于两条链表的长度可能不同,两条链表之间的节点无法对应。
如果用两个指针 p1 和 p2 分别在两条链表上前进,并不能同时走到公共节点,也就无法得到相交节点 c1。解决这个问题的关键是,通过某些方式,让 p1 和 p2 能够同时到达相交节点 c1 。所以,我们可以让 p1 遍历完链表 A 之后开始遍历链表 B,让 p2 遍历完链表 B 之后开始遍历链表 A,这样相当于「逻辑上」两条链表接在了一起。如果这样进行拼接,就可以让 p1 和 p2 同时进入公共部分,也就是同时到达相交节点 c1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { ListNode *p1 = headA, *p2 = headB; while (p1 != p2){ if (p1 != NULL ) p1 = p1->next; else p1 = headB; if (p2 != NULL ) p2 = p2->next; else p2 = headA; } return p1; } };
(二) 双指针(数组)
一、快慢指针技巧
原地修改
滑动窗口
二、左右指针的常用算法
1、原地修改
参考:删除有序数组中的重复项
数组问题中比较常见的快慢指针技巧,是让你原地修改数组。
由于数组已经排序,所以重复的元素一定连在一起,找出它们并不难。但如果毎找到一个重复元素就立即原地删除它,由于数组中删除元素涉及数据搬移 ,整个时间复杂度是会达到 O ( N 2 ) O(N^2) O ( N 2 )
们让慢指针 slow 走在后面,快指针 fast 走在前面探路,找到一个不重复的元素就赋值给 slow 并让 slow 前进一步。这样,就保证了 nums[0..slow] 都是无重复的元素,当 fast 指针遍历完整个数组 nums 后,nums[0..slow] 就是整个数组去重之后的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int removeDuplicates (vector<int >& nums) int n = nums.size (); if (n == 0 ) return 0 ; int slow = 0 , fast = 0 ; while (fast < n){ if (nums[fast] != nums[slow]) nums[++slow] = nums[fast]; fast++; } return slow + 1 ; } };
再简单扩展一下,看看力扣第 83 题「删除排序链表中的重复元素」,如果给你一个有序的单链表,如何去重呢?其实和数组去重是一模一样的,唯一的区别是把数组赋值操作变成操作指针而已。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : ListNode* deleteDuplicates (ListNode* head) { if (head == NULL ) return NULL ; ListNode *slow = head, *fast = head; while (fast != NULL ){ if (fast->val != slow->val){ slow->next = fast; slow = slow->next; } fast = fast->next; } slow->next = NULL ; return head; } };
除了让你在有序数组/链表中去重,题目还可能让你对数组中的某些元素进行「原地删除 」。
参考:移除元素
题目要求我们把 nums 中所有值为 val 的元素原地删除,依然需要使用快慢指针技巧:fast 遇到值为 val 的元素,则直接跳过,否则就赋值给 slow 指针,并让 slow 前进一步。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public : int removeElement (vector<int >& nums, int val) int fast = 0 , slow = 0 ; while (fast < nums.size ()){ if (nums[fast] != val) nums[slow++] = nums[fast]; fast++; } return slow; } };
给你输入一个数组 nums,请你原地修改,将数组中的所有值为 0 的元素移到数组末尾。
参考:移动零
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : void moveZeroes (vector<int >& nums) int fast = 0 , slow = 0 ; while (fast < nums.size ()){ if (nums[fast] != 0 ) nums[slow++] = nums[fast]; fast++; } while (slow < nums.size ()) nums[slow++] = 0 ; } };
到这里,原地修改数组的这些题目就已经差不多了。
2、滑动窗口
数组中另一大类快慢指针的题目就是「滑动窗口算法」。在下文 【(三)滑动窗口】给出了滑动窗口的代码框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 int left = 0 , right = 0 ;while (right < nums.size ()){ window.push_back (nums[right]); right++; while (window needs shrink){ window.pop_front (); left++; } }
具体的题目本文就不重复了,这里只强调滑动窗口算法的快慢指针特性:left 指针在后,right 指针在前,两个指针中间的部分就是「窗口 」,算法通过扩大和缩小「窗口 」来解决某些问题。
3、二分查找
在另一篇文章 【二分查找框架详解】 中有详细探讨二分搜索代码的细节问题,这里只写最简单的二分算法,旨在突出它的双指针特性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <vector> using namespace std;int binarySearch (vector<int >& nums, int target) int left = 0 , right = nums.size () - 1 ; while (left <= right) { int mid = (right + left) / 2 ; if (nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1 ; else if (nums[mid] > target) right = mid - 1 ; } return -1 ; }
4、n 数之和
参考:两数之和 II
给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。
只要数组有序,就应该想到双指针技巧。这道题的解法有点类似二分查找,通过调节 left 和 right 就可以调整 sum 的大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : vector<int > twoSum (vector<int >& numbers, int target) { int left = 0 , right = numbers.size ()-1 ; while (left < right){ int sum = numbers[left] + numbers[right]; if (sum == target) return vector<int >{left+1 , right+1 }; else if (sum > target) right--; else left++; } return vector<int >{-1 , -1 }; } };
在另一篇文章 【一个函数秒杀所有nSum问题】 中也运用类似的左右指针技巧给出了 nSum 问题的一种通用思路,本质上利用的也是双指针技巧。
5、反转数组
一般编程语言都会提供 reverse 函数,其实这个函数的原理非常简单,力扣第 344 题「反转字符串」就是类似的需求,让你反转一个 char[] 类型的字符数组,我们直接看代码吧:
参考:反转字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public : void reverseString (vector<char >& s) int left = 0 , right = s.size ()-1 ; while (left < right){ char t = s[left]; s[left] = s[right]; s[right] = t; left++, right--; } } };
关于数组翻转的更多进阶问题,可以参见 【二维数组的花式遍历】。
6、回文串判断
1 2 3 4 5 6 7 8 bool isPalindrome (string s) int left = 0 , right = s.size ()-1 ; while (left < right){ if (s[left] != s[right]) return false ; left++, right--; } return true ; }
提升一点难度,给你一个字符串,让你用双指针技巧从中找出最长的回文串 ?
参考:最长回文子串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : string palindrome (string& s, int l, int r) { while (l>=0 && r<s.size () && s[l]==s[r]) l--, r++; return s.substr (l+1 , r-l-1 ); } string longestPalindrome (string s) { string ans = "" ; for (int i=0 ; i<s.size (); i++){ string s1 = palindrome (s, i, i); string s2 = palindrome (s, i, i+1 ); ans = s1.size () > ans.size () ? s1 : ans; ans = s2.size () > ans.size () ? s2 : ans; } return ans; } };
你应该能发现最长回文子串使用的左右指针和之前题目的左右指针有一些不同:之前的左右指针都是从两端向中间相向而行,而回文子串问题则是让左右指针从中心向两端扩展。不过这种情况也就回文串这类问题会遇到,所以我也把它归为左右指针了。
(三) 滑动窗口
滑动窗口可以归为快慢双指针,一快一慢两个指针前后相随,中间的部分就是窗口。
滑动窗口算法技巧主要用来解决子数组问题,比如让你寻找符合某个条件的最长/最短子数组 。
1、框架概述
如果用暴力解的话,你需要嵌套 for 循环这样穷举所有子数组,时间复杂度是 O ( N 2 ) O(N^2) O ( N 2 )
1 2 3 4 5 for (int i = 0 ; i < nums.size (); i++) { for (int j = i; j < nums.size (); j++) { } }
滑动窗口算法技巧的思路也不难,就是维护一个窗口,不断滑动,然后更新答案,该算法的大致逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 int left = 0 , right = 0 ;while (right < nums.size ()){ window.push_back (nums[right]); right++; while (window needs shrink){ window.pop_front (); left++; } }
基于滑动窗口算法框架写出的代码,时间复杂度是 O ( N ) O(N) O ( N ) for 循环的暴力解法效率高。
为啥是 O ( N ) O(N) O ( N )
简单说,指针 left, right 不会回退(它们的值只增不减),所以字符串/数组中的每个元素都只会进入窗口一次,然后被移出窗口一次。
反观嵌套 for 循环的暴力解法,那个 j 会回退,所以某些元素会进入和离开窗口多次,所以时间复杂度就是 O ( N 2 ) O(N^2) O ( N 2 )
为啥滑动窗口能在 O ( N ) O(N) O ( N )
这个问题本身就是错误的,滑动窗口并不能穷举出所有子串 。要想穷举出所有子串,必须用那个嵌套 for 循环。
然而对于某些题目,并不需要穷举所有子串 ,就能找到题目想要的答案。滑动窗口就是这种场景下的一套算法模板,帮你对穷举过程进行剪枝优化,避免冗余计算。
因为本文的例题大多是子串相关的题目,字符串实际上就是数组,所以我就把输入设置成字符串了。你做题的时候根据具体题目自行变通即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void slidingWindow (string s) auto window = ... int left = 0 , right = 0 ; while (right < s.size ()) { char c = s[right]; window.add (c); right++; ... printf ("window: [%d, %d)\n" , left, right); while (window needs shrink) { char d = s[left]; window.remove (d); left++; ... } } }
框架中两处 ... 表示的更新窗口数据的地方,在具体的题目中,你需要做的就是往这里面填代码逻辑。
2、最小覆盖子串
参考:最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注:对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。如果 s 中存在这样的子串,我们保证它是唯一的答案。
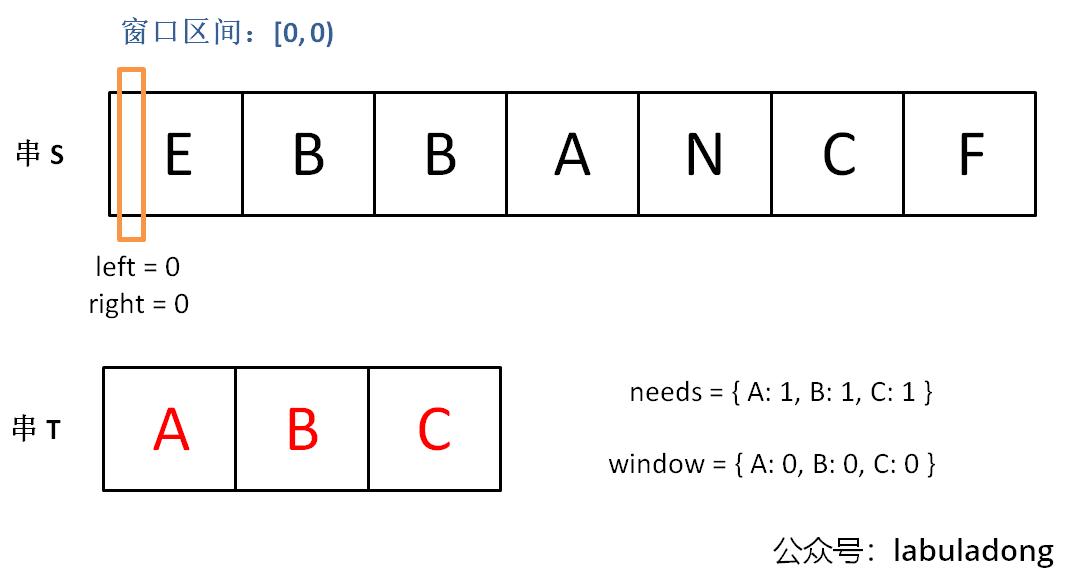
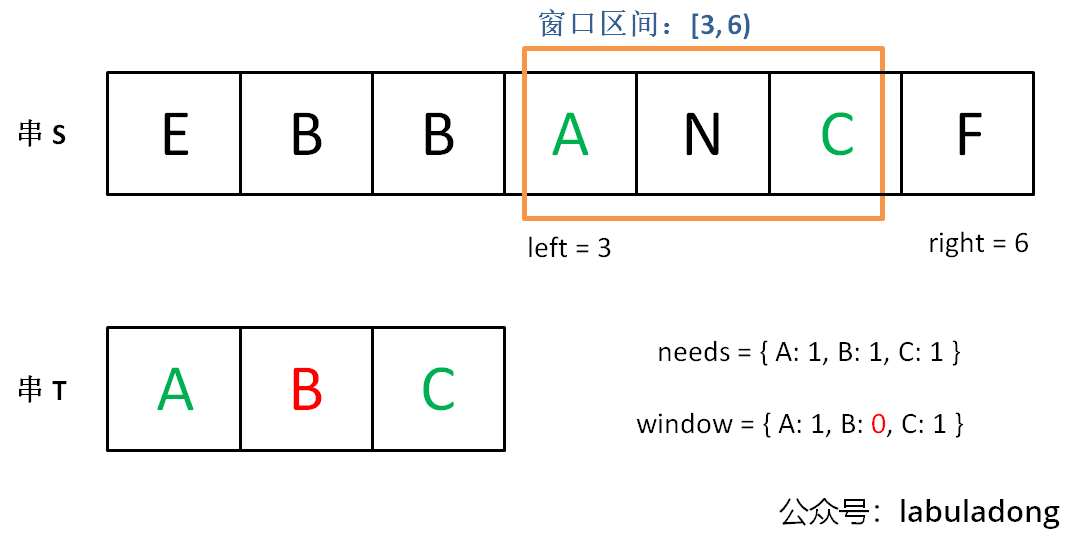
示例:s = "ADOBECODEBANC", t = "ABC""BANC"
滑动窗口算法的思路是这样:
我们在字符串 S 中使用双指针中的左右指针技巧,初始化 left = right = 0,把索引左闭右开区间 [left, right) 称为一个「窗口」。
为什么要「左闭右开 」区间?
理论上你可以设计两端都开或者两端都闭的区间,但设计为左闭右开区间是最方便处理的。
因为这样初始化 left = right = 0 时区间 [0, 0) 中没有元素,但只要让 right 向右移动(扩大)一位,区间 [0, 1) 就包含一个元素 0 了。
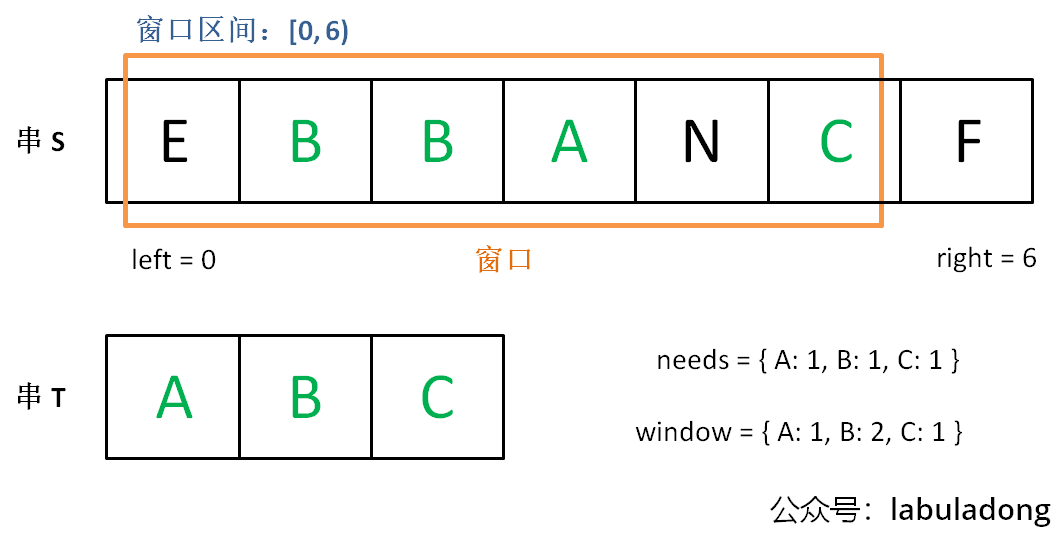
另外,注意:当前窗口长度,就是 right-left,不需要right-left+1的 。
我们先不断地增加 right 指针扩大窗口 [left, right),直到窗口中的字符串符合要求(包含了 T 中的所有字符)。
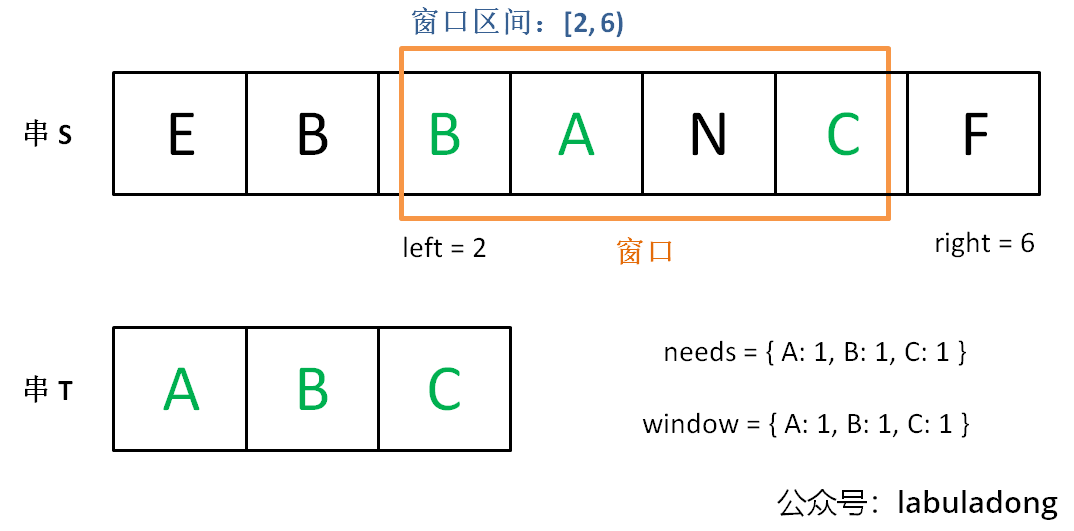
此时,我们停止增加 right,转而不断增加 left 指针缩小窗口 [left, right),直到窗口中的字符串不再符合要求(不包含 T 中的所有字符了)。同时,每次增加 left,我们都要更新一轮结果。
重复第 2 和第 3 步,直到 right 到达字符串 S 的尽头。
这个思路其实也不难,第 2 步相当于在寻找一个「可行解」,然后第 3 步在优化这个「可行解」,最终找到最优解 ,也就是最短的覆盖子串。左右指针轮流前进,窗口大小增增减减,就好像一条毛毛虫,一伸一缩,不断向右滑动,这就是「滑动窗口」这个名字的来历。
现在开始套模板,只需要思考以下几个问题:
什么时候应该移动 right 扩大窗口?窗口加入字符时,应该更新哪些数据?
什么时候窗口应该暂停扩大,开始移动 left 缩小窗口?从窗口移出字符时,应该更新哪些数据?
我们要的结果应该在扩大窗口时还是缩小窗口时进行更新?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public : string minWindow (string s, string t) { int n = s.size (); unordered_map<char , int > need, window; for (char & c: t) need[c]++; int left = 0 , right = 0 ; int valid = 0 ; int start = 0 , len = n+1 ; while (right < n){ char c = s[right]; right++; if (need.count (c)){ window[c]++; if (window[c] == need[c]) valid++; } while (valid == need.size ()){ if (right-left < len){ start = left; len = right-left; } char d = s[left]; left++; if (need.count (d)){ if (window[d] == need[d]) valid--; window[d]--; } } } return len>n ? "" : s.substr (start, len); } };
这里再强调一下,里面的if(window[d] == need[d])用的很妙的,保证了不会多加少加、多减少减。
3、字符串排列
参考:字符串的排列
给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的 排列 (排列是字符串中所有字符的重新排序。)。如果是,返回 true ;否则,返回 false 。换句话说,s1 的排列之一是 s2 的 子串 。
示例1:s1 = "ab" s2 = "eidbaooo"trues2 包含 s1 的排列之一 ("ba").
示例2:s1= "ab" s2 = "eidboaoo"false
相当给你一个 S 和一个 T,请问你 S 中是否存在一个子串,包含 T 中所有字符且不包含其他字符?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : bool checkInclusion (string s1, string s2) int n1 = s1.size (), n2 = s2.size (); unordered_map<char , int > need, window; for (char & c: s1) need[c]++; int valid = 0 ; int left = 0 , right = 0 ; while (right < n2){ char c = s2[right]; right++; if (need.count (c)){ window[c]++; if (window[c] == need[c]) valid++; } if (right-left == n1){ if (valid == need.size ()) return true ; char d = s2[left]; left++; if (need.count (d)){ if (window[d] == need[d]) valid--; window[d]--; } } } return false ; } };
其实,你会发现,若是匹配的小窗是固定长度的,那么里面收缩的条件就是 if 而不是 while,当然你使用 while (right - left >= t.size()) 也是能做的,只不过实际上就只执行一次。
4、找所有字母异位词
参考:找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 (字母异位词是通过重新排列不同单词或短语的字母而形成的单词或短语,并使用所有原字母一次) 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例:s = "cbaebabacd", p = "abc"[0,6]0 的子串是 "cba", 它是 "abc" 的异位词。起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public : vector<int > findAnagrams (string s, string p) { int n = s.size (), m = p.size (); unordered_map<char , int > need, window; for (char &t: p) need[t]++; int valid = 0 ; vector<int > ans; int left = 0 , right = 0 ; while (right < n){ char c = s[right]; right++; if (need.count (c)){ window[c]++; if (window[c] == need[c]) valid++; } if (right-left == m){ if (valid == need.size ()) ans.push_back (left); char d = s[left]; left++; if (need.count (d)){ if (window[d] == need[d]) valid--; window[d]--; } } } return ans; } };
5、最长无重复子串
参考:无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串(连续的非空字符序列) 的长度。
示例:s = "abcabcbb"3"abc",所以其长度为 3。
下面是我的解法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public : int lengthOfLongestSubstring (string s) int n = s.size (); unordered_set<char > window; int ans = 0 ; int left = 0 , right = 0 ; while (right < n){ char c = s[right]; right++; while (window.find (c) != window.end ()){ char d = s[left]; left++; window.erase (d); } if (window.find (c) == window.end ()){ window.insert (c); ans = max (ans, right-left); } } return ans; } };
如若套用前面模版,也可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : int lengthOfLongestSubstring (string s) int n = s.size (); unordered_map<char , int > window; int ans = 0 ; int left = 0 , right = 0 ; while (right < n){ char c = s[right]; right++; window[c]++; while (window[c] > 1 ){ char d = s[left]; left++; window[d]--; } ans = max (ans, right-left); } return ans; } };
你只要能回答出来以下几个问题,就能运用滑动窗口算法:
什么时候应该扩大窗口?
什么时候应该缩小窗口?
什么时候应该更新答案?
更多强化经典题:滑动窗口-强化
将 x 减到 0 的最小操作数 乘积小于 K 的子数组 最大连续1的个数 III 替换后的最长重复字符
建议在第二天来完成。
(四) 二分搜索
1、代码框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int binarySearch (vector<int >& nums, int target) int left = 0 , right = nums.size () - 1 ; while (...) { int mid = left + (right - left) / 2 ; if (nums[mid] == target) { ... } else if (nums[mid] < target) { left = ... } else if (nums[mid] > target) { right = ... } } }
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。
其中 ... 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。
另外提前说明一下,计算 mid 时需要防止溢出,代码中 left + (right - left) / 2 就和 (left + right) / 2 的结果相同,但是有效防止了 left 和 right 太大,直接相加导致溢出的情况。
2、寻找一个数(基本)
参考:二分查找
即搜索一个数,如果存在,返回其索引,否则返回 -1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int search (vector<int >& nums, int target) int left = 0 , right = nums.size ()-1 ; while (left <= right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) return mid; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid-1 ; } return -1 ; } };
分析:[left, right] 两端都闭的区间,这个区间其实就是每次进行搜索的区间 。那么:
while 循环的条件是 <= 而不是 <。因为 [4,4]是有元素的,而[5,4]才没有元素了,就停止。初始化 right 是 n-1,而不是 n。因为初始是 [0,n-1]才是可以搜索的空间,而[0,n]的最后n是不可搜索的。
若是采用 [left,right) 那么你可以分析得到循环结束,应该是 类似[4,4) 也就是 while 用 left < right就结束了。同时初始化应该是 [0,n) 刚好把所有元素包含且不含最后的n。
为什么是 left = mid + 1,right = mid - 1?
明确了「搜索区间 」这个概念,而且本算法的搜索区间是两端都闭的,即 [left, right]。那么当我们发现索引 mid 不是要找的 target 时,下一步应该去搜索哪里呢?当然是去搜索区间 [left, mid-1] 或者区间 [mid+1, right] 对不对?因为 mid 已经搜索过,应该从搜索区间中去除。
此算法有什么缺陷?
比如说给你有序数组 nums = [1,2,2,2,3],target 为 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3,这样的话此算法是无法处理的。
这样的需求很常见,你也许会说,找到一个 target,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的复杂度了。
3、寻找左边界
1 2 3 4 5 6 7 8 9 10 11 12 13 int left_bound (vector<int > &nums, int target) int left = 0 , right = nums.size (); while (left < right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) right = mid; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid; } return left; }
如果 target 不存在,搜索左侧边界的二分搜索返回的索引是大于 target 的最小索引。
举个例子,nums = [2,3,5,7], target = 4,left_bound 函数返回值是 2,因为元素 5 是大于 4 的最小元素。
为什么是 left = mid + 1 和 right = mid?
「搜索区间 」是 [left, right) 左闭右开,所以当 nums[mid] 被检测之后,下一步应该去 mid 的左侧或者右侧区间搜索,即 [left, mid) 或 [mid + 1, right)。
为什么该算法能够搜索左侧边界?
关键在于对于 nums[mid] == target 这种情况的处理是 right = mid;可见,找到 target 时不要立即返回,而是缩小「搜索区间」的上界 right,在区间 [left, mid) 中继续搜索,即不断向左收缩,达到锁定左侧边界的目的。
为什么返回 left 而不是 right?
一样,都可以。终止条件是 left == right。
可以直接拿来写 floor 函数。
1 2 3 4 5 6 7 8 9 10 int floor (vector<int > &nums, int target) return left_bound (nums, target) - 1 ; }
但是,如果非必要,不要自己手写,尽可能用编程语言提供的标准库函数 ,可以节约时间,而且标准库函数的行为在文档里都有明确的说明,不容易出错。
如果想让 target 不存在时返回 -1 其实很简单,在返回的时候额外判断一下 nums[left] 是否等于 target 就行了,如果不等于,就说明 target 不存在。需要注意的是,访问数组索引之前要保证索引不越界
1 2 3 4 5 if (left < 0 || left >= nums.length) return -1 ; return nums[left] == target ? left : -1 ;
提示:其实上面的 if 中 left < 0 这个判断可以省略,因为对于这个算法,left 不可能小于 0,你看这个算法执行的逻辑,left 初始化就是 0,且只可能一直往右走,那么只可能在右侧越界。不过我这里就同时判断了,因为在访问数组索引之前保证索引在左右两端都不越界是一个好习惯,没有坏处。另一个好处是让二分的模板更统一,降低你的记忆成本,因为等会儿寻找右边界的时候也有类似的出界判断。
只要明白了搜索区间 的概念,实际上,可以统一一下,仍然使用左右都闭的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int left_bound (vector<int > &nums, int target) int left = 0 , right = nums.size ()-1 ; while (left <= right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) right = mid-1 ; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid-1 ; } if (left<0 || right>=nums.size ()) return -1 ; return nums[left] == target? left : -1 ; }
4、寻找右边界
先还是看左闭右开的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int right_bound (vector<int > &nums, int target) int left = 0 , right = nums.size (); while (left < right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) left = mid+1 ; else (nums[mid] < target) left = mid+1 ; else (nums[mid] > target) right = mid; } return left-1 ; }
为什么返回 left - 1?为什么不是返回 right?
终止条件是 left == right,所以 left 和 right 是一样的,你非要体现右侧的特点,返回 right - 1 好了。
为什么要减一,这是搜索右侧边界的一个特殊点,关键在锁定右边界时的这个条件判断:left = mid + 1;。
因为我们对 left 的更新必须是 left = mid + 1,就是说 while 循环结束时,nums[left] 一定不等于 target 了,而 nums[left-1] 可能是 target。
至于为什么 left 的更新必须是 left = mid + 1,当然是为了把 nums[mid] 排除出搜索区间,这里就不再赘述。
如果 target 不存在,搜索右侧边界的二分搜索返回的索引是小于target 的最大索引。
比如 nums = [2,3,5,7], target = 4,right_bound 函数返回值是 1,因为元素 3 是小于 4 的最大元素。
统一一下,现在可以改成左右都闭的写法了:left+1 == right 了,那么刚好right = left-1,可以直接换成 right 返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int right_bound (vector<int > &nums, int target) int left = 0 , right = nums.size ()-1 ; while (left <= right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) left = mid+1 ; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid-1 ; } if (right<0 || right>=nums.size ()) return -1 ; return nums[right]==target? right : -1 ; }
现在,你可以去做 在排序数组中查找元素的第一个和最后一个位置
在左右边界的代码中,所有的情况,都是需要变动 mid 的,如mid+1或mid-1,记住 !
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution {public : int left_bound (vector<int > &nums, int target) int left = 0 , right = nums.size ()-1 ; while (left <= right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) right = mid-1 ; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid-1 ; } if (left<0 || left>=nums.size ()) return -1 ; return nums[left]==target? left : -1 ; } int right_bound (vector<int > &nums, int target) int left = 0 , right = nums.size ()-1 ; while (left <= right){ int mid = left + (right-left)/2 ; if (nums[mid] == target) left = mid+1 ; else if (nums[mid] < target) left = mid+1 ; else if (nums[mid] > target) right = mid-1 ; } if (right<0 || right>=nums.size ()) return -1 ; return nums[right]==target? right : -1 ; } vector<int > searchRange (vector<int >& nums, int target) { int left = left_bound (nums, target); int right = right_bound (nums, target); return vector<int >{left, right}; } };
二分思维的精髓就是:通过已知信息尽可能多地收缩(折半)搜索空间 ,从而增加穷举效率,快速找到目标。
但实际题目中不会直接让你写二分代码,我会在 【二分查找的运用 】 和 【二分查找的更多习题 】 中进一步讲解如何把二分思维运用到更多算法题中
(五) 递归(一个视角+两种思维)
一个视角是指「树」的视角,两种思维模式是指「遍历」和「分解问题」两种思维模式 。
算法的本质是穷举,递归是一种重要的穷举手段,递归的正确理解方法是从「树 」的角度理解。
编写递归算法,有两种思维模式:一种是通过「遍历 」一遍树得到答案,另一种是通过「分解问题 」得到答案。
1、从树的角度理解递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int fib (int n) if (n < 2 ) { return n; } return fib (n - 1 ) + fib (n - 2 ); } void traverse (TreeNode root) if (root == null) { return ; } traverse (root.left); traverse (root.right); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution {private : vector<vector<int >> ans; vector<int > path; vector<bool > visit; public : vector<vector<int >> permute (vector<int >& nums) { int n = nums.size (); visit.assign (n, false ); backtrack (nums); return ans; } void backtrack (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ if (visit[i]) continue ; path.push_back (nums[i]); visit[i] = true ; backtrack (nums); path.pop_back (); visit[i] = false ; } } };
可以抽象看成:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void backtrack (int [] nums, List<Integer> track) if (track.size () == nums.length) { return ; } for (int i = 0 ; i < nums.length; i++) { backtrack (nums, track); } } void traverse (TreeNode root) if (root == null) { return ; } for (TreeNode child : root.children) { traverse (child); } }
你应该已经感觉到了,「树」结构是一个非常有效的数据结构。把问题抽象成树结构,然后用代码去遍历这棵树 ,就是递归的本质 。
2、编写递归的两种思维模式
上面讲的两道例题中,它们虽然都抽象成了一棵递归树 ,但斐波那契数列 使用的是「分解问题 」的思维模式求解,全排列 使用的是「遍历 」的思维模式求解。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public : int maxDepth (TreeNode* root) if (root == NULL ) return 0 ; return max (maxDepth (root->left), maxDepth (root->right)) + 1 ; } };
遍历的思维模式 无返回值 的遍历函数,在遍历的过程中收集结果 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vector<vector<int >> ans; vector<int > path; void backtrack (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ path.push_back (nums[i]); backtrack (nums); path.pop_back (); } }
再看前面的二叉树的最大深度,实际上遍历整棵树,在遍历的过程更新最大深度,这样当遍历完所有节点时,必然可以求出整棵树的最大深度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {private : int cur = 0 ; int ans = 0 ; public : void traverse (TreeNode* root) if (root == NULL ){ ans = max (ans, cur); return ; } cur++; traverse (root->left); traverse (root->right); cur--; } int maxDepth (TreeNode* root) traverse (root); return ans; } };
参考以下步骤,运用自如地写出递归算法:
首先,这个问题是否可以抽象成一棵树 结构?如果可以,那么就要用递归算法了。
如果要用递归算法,那么就思考「遍历」和「分解问题」这两种思维模式,看看哪种更适合这个问题。
如果用「分解 问题」的思维模式,那么一定要写清楚这个递归函数的定义 是什么,然后利用这个定义来分解问题,利用子问题的答案推导原问题的答案。
如果用「遍历 」的思维模式,那么要用一个无返回值 的递归函数,单纯起到遍历递归树,到达叶节点收集结果 的作用。
「分解问题 」的思维模式就对应着后面要讲解的 动态规划算法 和 分治算法 。
「遍历 」的思维模式就对应着后面要讲解的 DFS/回溯算法 。
在 二叉树习题章节 ,把所有二叉树相关的题目都用这两种思维模式来解一遍。你只要把二叉树玩明白了,这些递归算法就都玩明白了,真的很简单。
(六) 动态规划
动态规划问题的一般形式就是求最值 。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说让你求最长递增子序列呀,最小编辑距离呀等等。
求解动态规划的核心问题是穷举 。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值呗。
只有列出正确的「状态转移方程 」,才能正确地穷举。
是否具备「最优子结构 」: 是否能够通过子问题的最值得到原问题的最值
存在「重叠子问题 」: 需要你使用「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算
动态规划三要素:状态转移方程、最优子结构、重叠子问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def dp (状态1 , 状态2 , ... ): for 选择 in 所有可能的选择: result = 求最值(result, dp(状态1 , 状态2 , ...)) return result dp[0 ][0 ][...] = base case for 状态1 in 状态1 的所有取值: for 状态2 in 状态2 的所有取值: for ... dp[状态1 ][状态2 ][...] = 求最值(选择1 ,选择2. ..)
1、斐波那契数列
参考:509.斐波那契数
斐波那契数列没有求最值,所以严格来说不是动态规划问题。主要是为了体现重叠子问题。
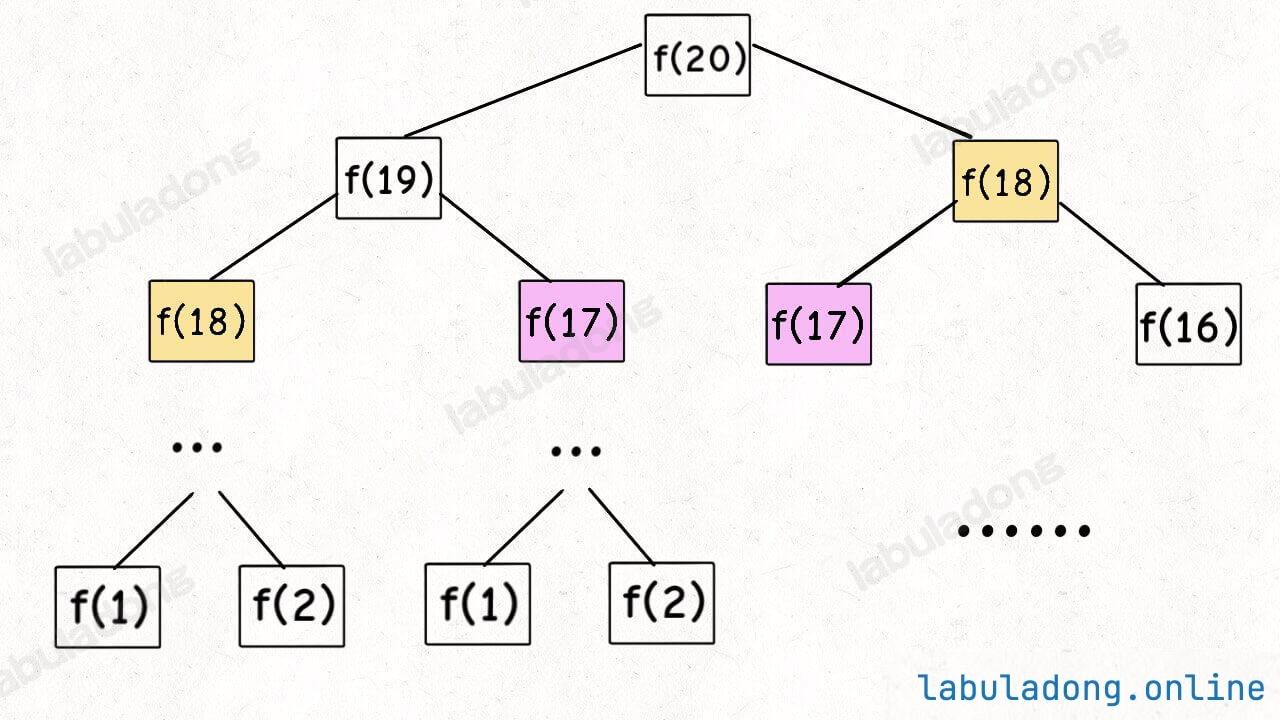
但凡遇到需要递归的问题,最好都画出递归树,这对你分析算法的复杂度,寻找算法低效的原因都有巨大帮助。
二叉树节点总数为指数级别,所以子问题个数为 O ( 2 n ) O(2^n) O ( 2 n ) O ( 1 ) O(1) O ( 1 ) O ( 2 n ) O(2^n) O ( 2 n ) N = 2 h − 1 − 1 N=2^{h-1}-1 N = 2 h − 1 − 1
带备忘录的递归解法
即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。
一般使用一个数组充当这个「备忘录」,当然你也可以使用哈希表(字典),思想都是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {private : vector<int > memo; public : int fib (int n) memo.assign (n+1 , 0 ); return dp (n); } int dp (int n) if (n==0 || n==1 ) return n; if (memo[n]!=0 ) return memo[n]; memo[n] = dp (n-1 ) + dp (n-2 ); return memo[n]; } };
子问题个数为 O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n )
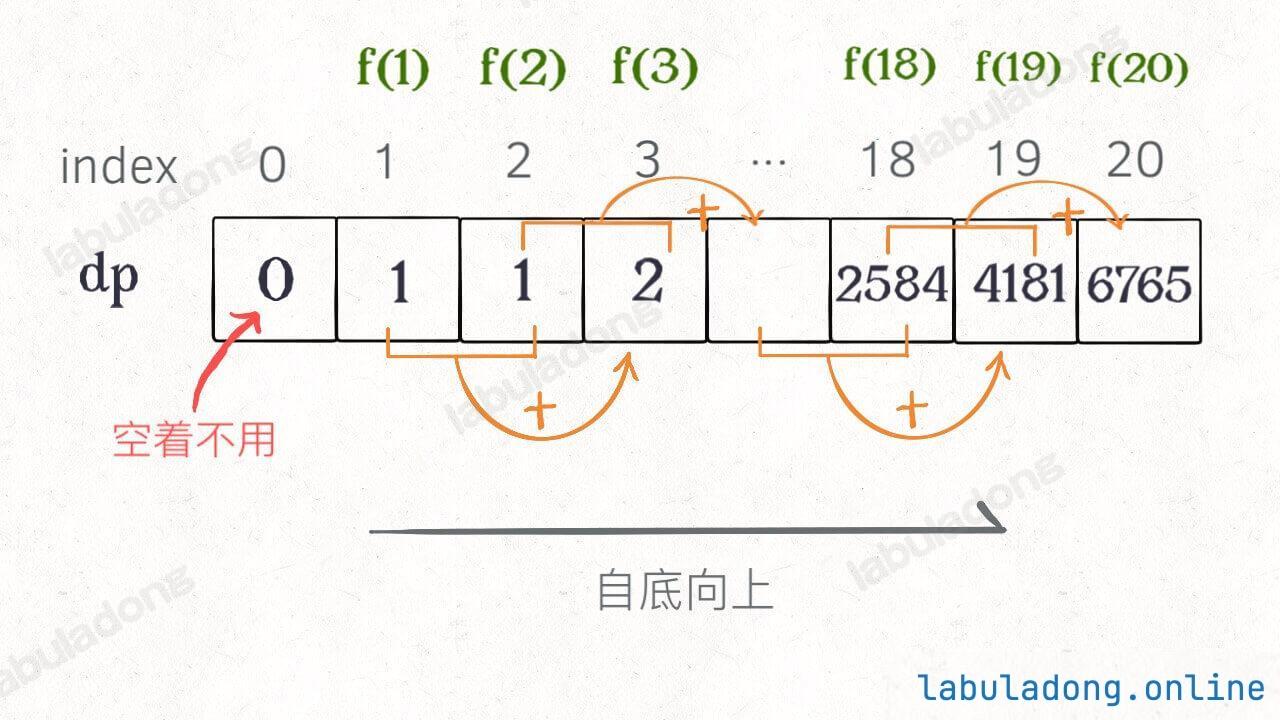
带备忘录的递归 解法的效率已经和迭代的动态规划解法一样了。实际上,这种解法和常见的动态规划解法已经差不多了,只不过这种解法是「自顶向下 」进行「递归 」求解
我们更常见的动态规划 代码是「自底向上 」进行「递推 」求解。
带dp表的动态规划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {private : vector<int > dp; public : int fib (int n) if (n == 0 ) return 0 ; dp.assign (n+1 , 0 ); dp[0 ] = 0 , dp[1 ] = 1 ; for (int i=2 ; i<=n; i++) dp[i] = dp[i-1 ] + dp[i-2 ]; return dp[n]; } };
千万不要看不起暴力解,动态规划问题最困难的就是写出这个暴力解,即状态转移方程 。
只要写出暴力解,优化方法无非是用备忘录或者 DP table,再无奥妙可言。
2、凑零钱
参考:322.零钱兑换
给你 k 种面值的硬币,面值分别为 c1, c2 ... ck,每种硬币的数量无限,再给一个总金额 amount,问你最少需要几枚硬币凑出这个金额,如果不可能凑出,算法返回 -1 。算法的函数签名如下:int coinChange(vector<int>& coins, int amount);
这个问题是动态规划问题,因为它具有「最优子结构 」的。要符合「最优子结构」,子问题间必须互相独立 。
什么是子问题相互独立?
确定「状态 」,也就是原问题和子问题中会变化的变量。
确定「选择 」,也就是导致「状态」产生变化的行为。
明确 dp 函数/数组的定义。
先看直接单纯写出递归:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : int coinChange (vector<int >& coins, int amount) return dp (coins, amount); } int dp (vector<int >& coins, int amount) if (amount == 0 ) return 0 ; if (amount < 0 ) return -1 ; int ans = -1 ; for (int coin: coins){ int subProblem = dp (coins, amount-coin); if (subProblem == -1 ) continue ; if (ans == -1 ) ans = subProblem+1 ; else ans = min (ans, subProblem+1 ); } return ans; } };
这实际上就是暴力计算:
d p ( n ) = { − 1 , n < 0 0 , n = 0 m i n { d p ( n − c o i n ) + 1 ∣ c o i n ∈ c o i n s } n > 0 dp(n) = \begin{cases}
-1,\quad n<0\\
0,\quad n=0\\
min\{ dp(n-coin)+1 \quad | \quad coin\in coins \}\quad n>0
\end{cases}
d p ( n ) = ⎩ ⎨ ⎧ − 1 , n < 0 0 , n = 0 min { d p ( n − co in ) + 1 ∣ co in ∈ co in s } n > 0
画出递归树:
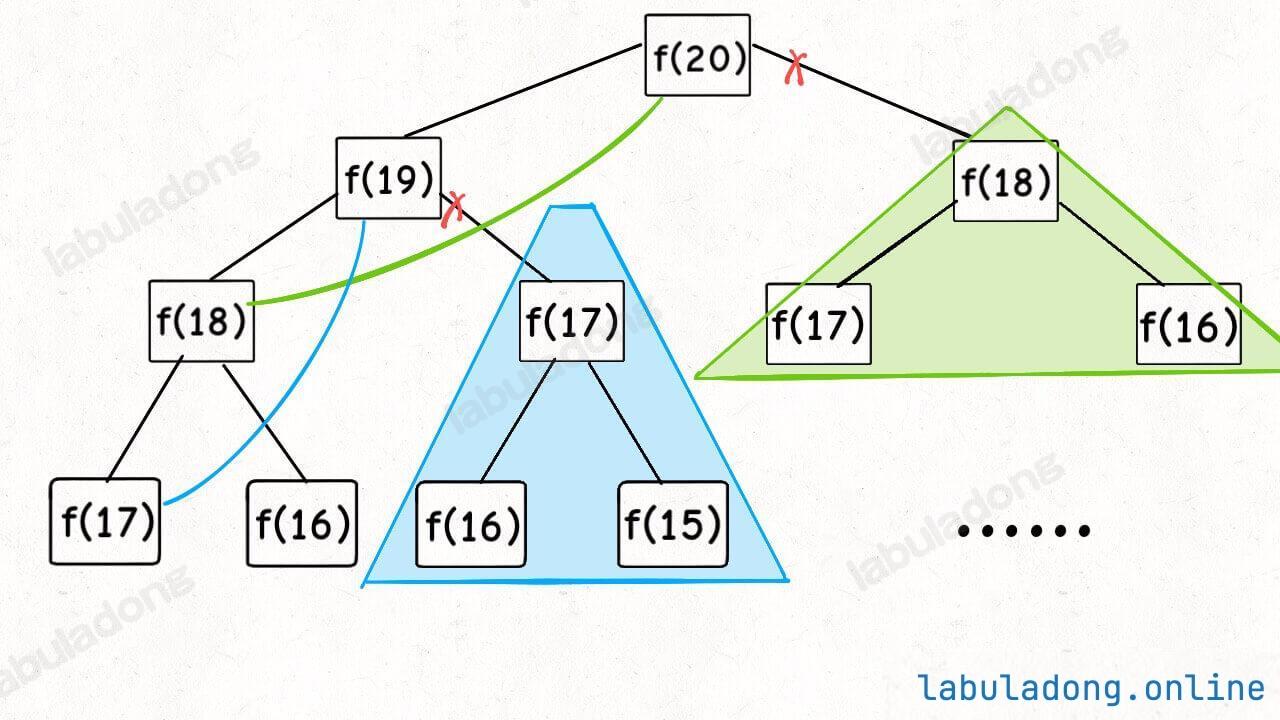
递归算法的时间复杂度分析:子问题总数 x 解决每个子问题所需的时间 。
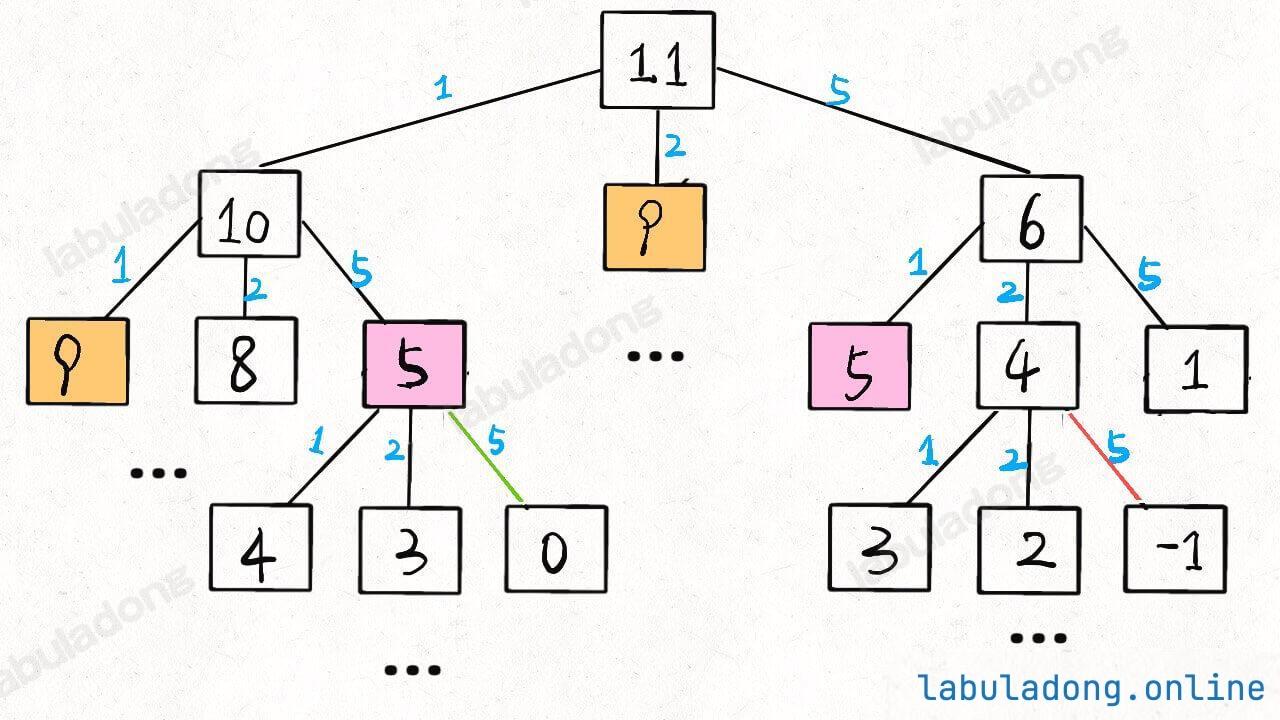
假设目标金额为 n,给定的硬币个数为 k,那么递归树最坏情况下高度为 n(全用面额为 1 的硬币),然后再假设这是一棵满 k 叉树,则节点的总数在 O ( k n ) O(k^n) O ( k n ) for 循环,复杂度为 O ( k ) O(k) O ( k ) O ( k n ) O(k^n) O ( k n )
这个问题其实就解决了,只不过需要消除一下重叠子问题。
带备忘录的递归
计算前,看备忘录是不是计算过。
离开前,在备忘录记下计算结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {private : vector<int > memo; public : int coinChange (vector<int >& coins, int amount) memo.assign (amount+1 , -666 ); return dp (coins, amount); } int dp (vector<int >& coins, int amount) if (amount == 0 ) return 0 ; if (amount < 0 ) return -1 ; if (memo[amount] != -666 ) return memo[amount]; int ans = -1 ; for (int coin: coins){ int subProblem = dp (coins, amount-coin); if (subProblem == -1 ) continue ; if (ans == -1 ) ans = subProblem+1 ; else ans = min (ans, subProblem+1 ); } memo[amount] = ans; return ans; } };
子问题总数不会超过金额数 n,即子问题数目为 O ( n ) O(n) O ( n ) O ( k ) O(k) O ( k ) O ( k n ) O(kn) O ( kn )
带dp的动态规划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {private : vector<int > dp; public : int coinChange (vector<int >& coins, int amount) dp.assign (amount+1 , amount+1 ); dp[0 ] = 0 ; for (int i=1 ; i<=amount; i++){ for (int coin: coins){ if (i-coin < 0 ) continue ; dp[i] = min (dp[i], dp[i-coin]+1 ); } } return dp[amount]>amount? -1 : dp[amount]; } };
为什么凑零钱问题不能用贪心 算法来解?因为想要硬币数最少,那就总是先使用面额大的硬币来凑?
这题不能用贪心,贪心的意思是说,一路按照最优选择选下去,就一定能得到正确答案(专业术语叫做贪心选择性质)。而这道题是不满足贪心选择性质的。你如果无脑选用大额硬币,不一定就能凑出目标金额,即便凑出了,也不一定是最小的数量。
比如要凑8块,有1,4,5面值的钱,贪心就是【5,1,1,1】,正确答案是【4,4】
那么这时候你就要尝试其他较小的金额了,所以说到底还是得暴力穷举所有情况,需要用递归进行暴力穷举。通过观察暴力穷举解法代码,我们发现这道题存在最优子结构和重叠子问题,所以逐步优化写出了带备忘录的递归穷举解法(动态规划)。
注意上面这个思考过程,从暴力穷举 算法开始,逐步尝试各种优化 方法。至于「贪心」「动态规划」这种名词,只不过是对不同优化过程的代称罢了。
计算机解决问题其实没有任何特殊的技巧,它唯一的解决办法就是穷举,穷举所有可能性。算法设计无非就是先思考「如何穷举」,然后再追求「如何聪明地穷举」。
列出状态转移方程 ,就是在解决「如何穷举 」的问题。
备忘录、DP table 就是在追求「如何聪明地穷举 」。
(七) 回溯(DFS)
其实回溯算法和我们常说的 DFS 算法基本可以认为是同一种算法,它们的细微差异在之后章节说明。
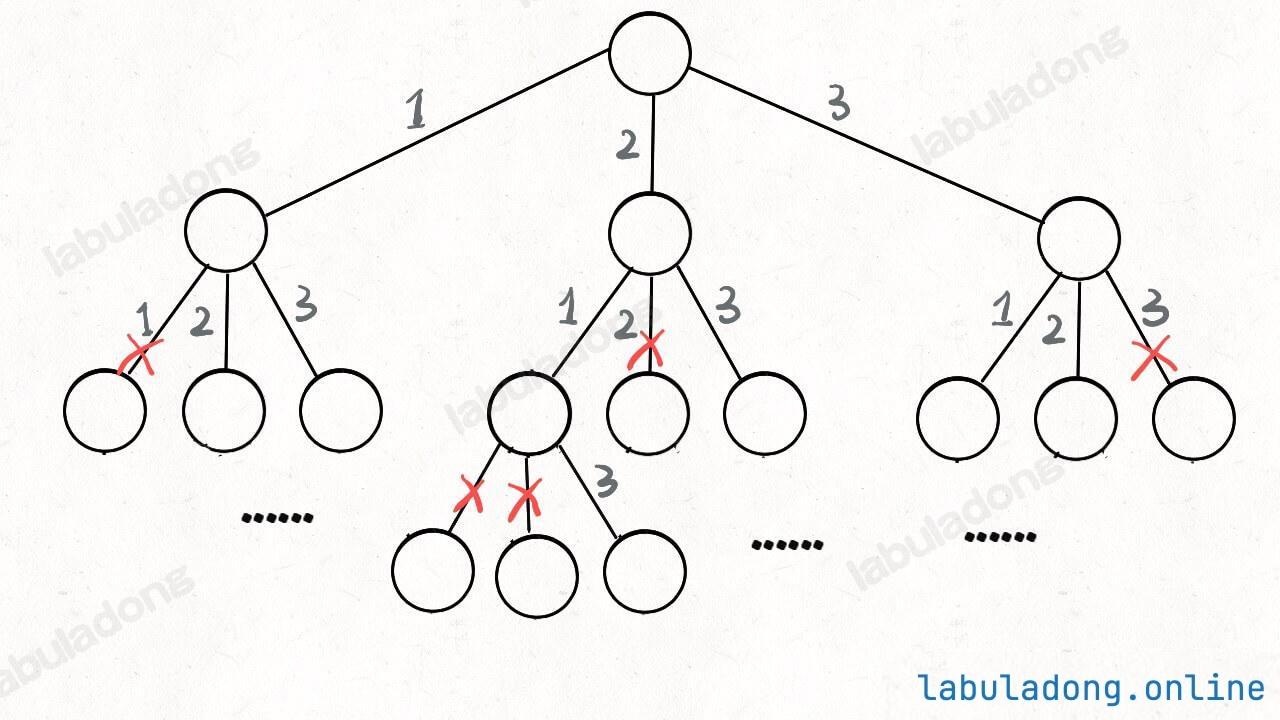
抽象地说,解决一个回溯 问题,实际上就是遍历一棵决策树 的过程,树的每个叶子节点存放着一个合法答案 。你把整棵树遍历一遍,把叶子节点上的答案都收集起来,就能得到所有的合法答案。
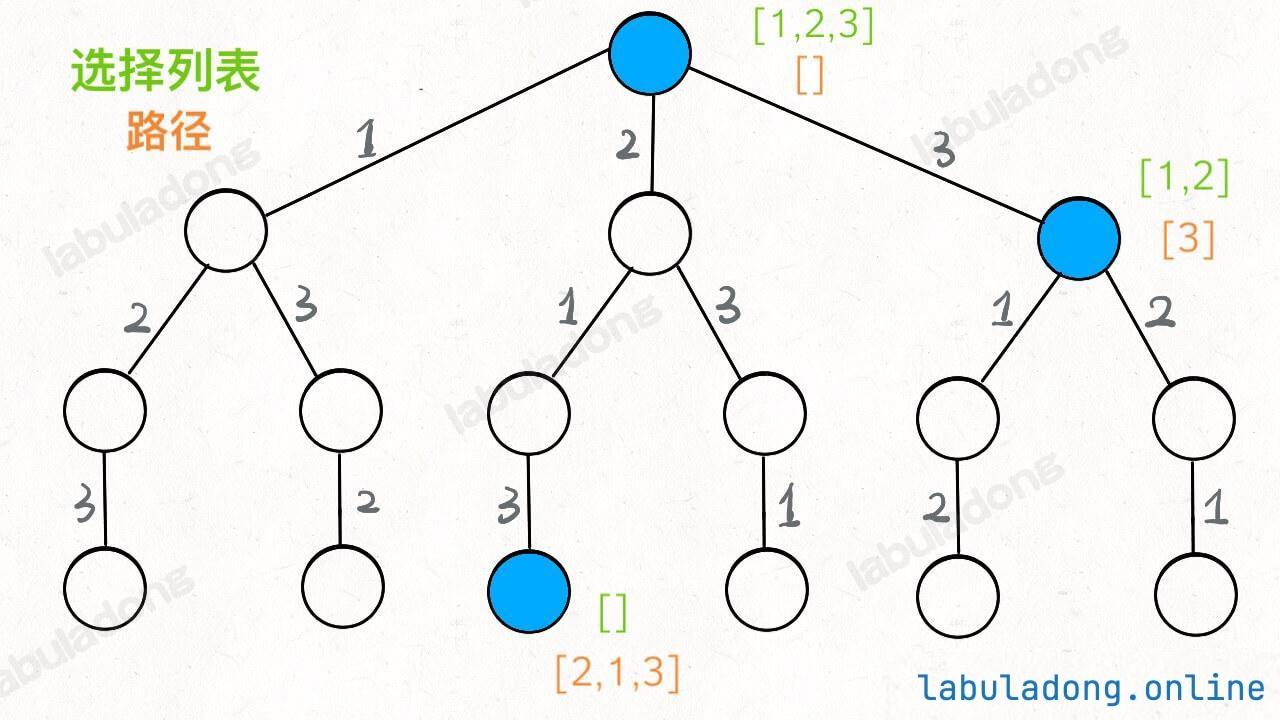
站在回溯树的一个节点上,你只需要思考 3 个问题:
路径 :也就是已经做出的选择。选择列表 :也就是你当前可以做的选择。结束条件 :也就是到达决策树底层,无法再做选择的条件。
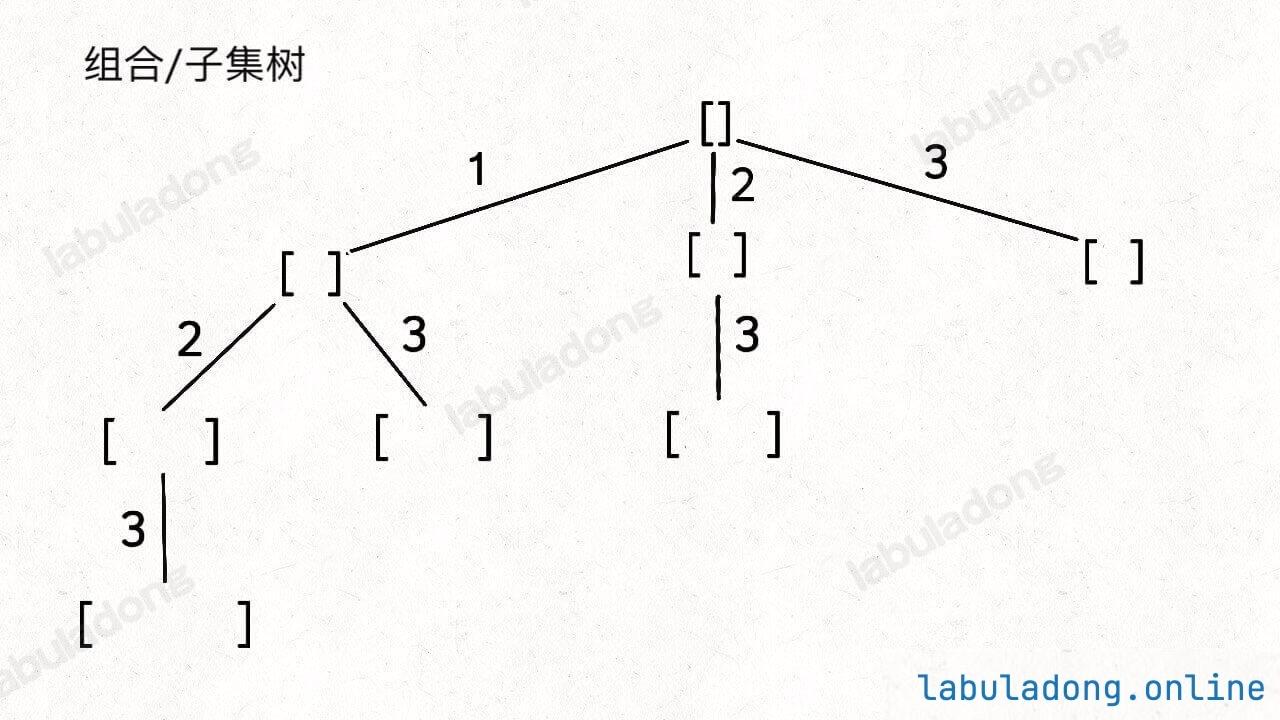
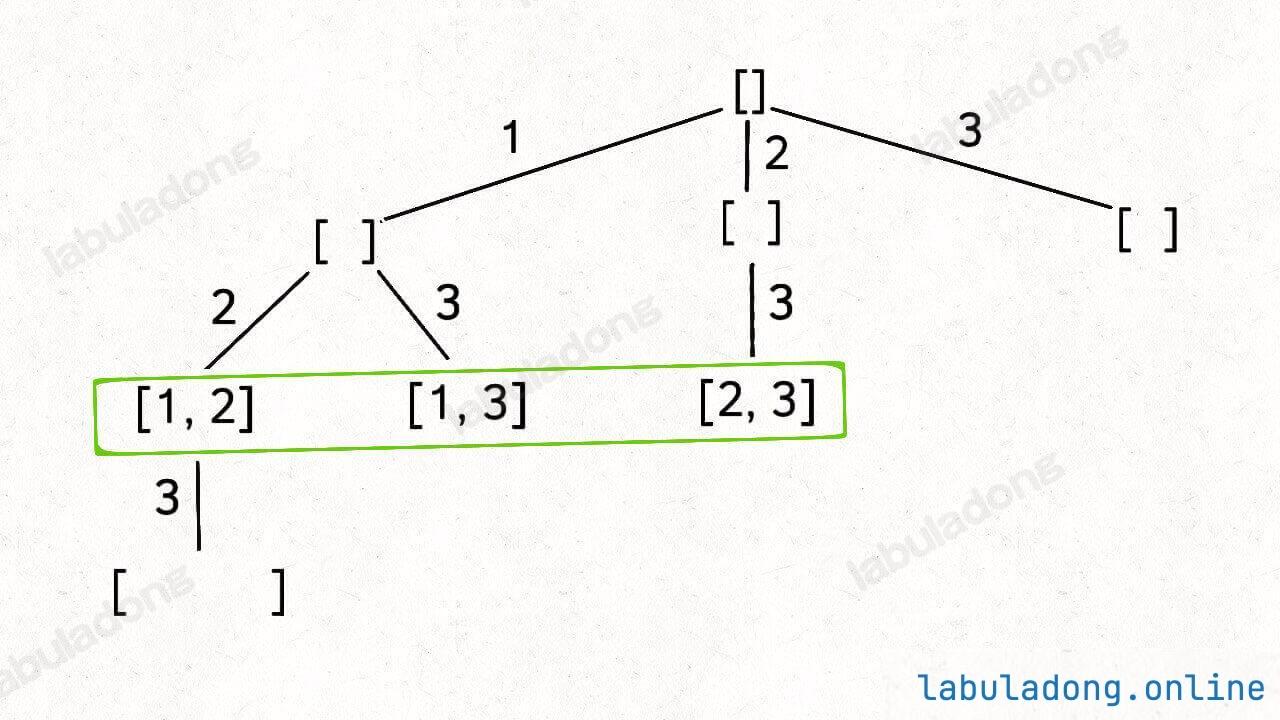
1 2 3 4 5 6 7 8 9 10 result = [] def backtrack (路径, 选择列表 ): if 满足结束条件: result.add(路径) return for 选择 in 选择列表: 做选择 backtrack(路径, 选择列表) 撤销选择
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」 。
1、全排列
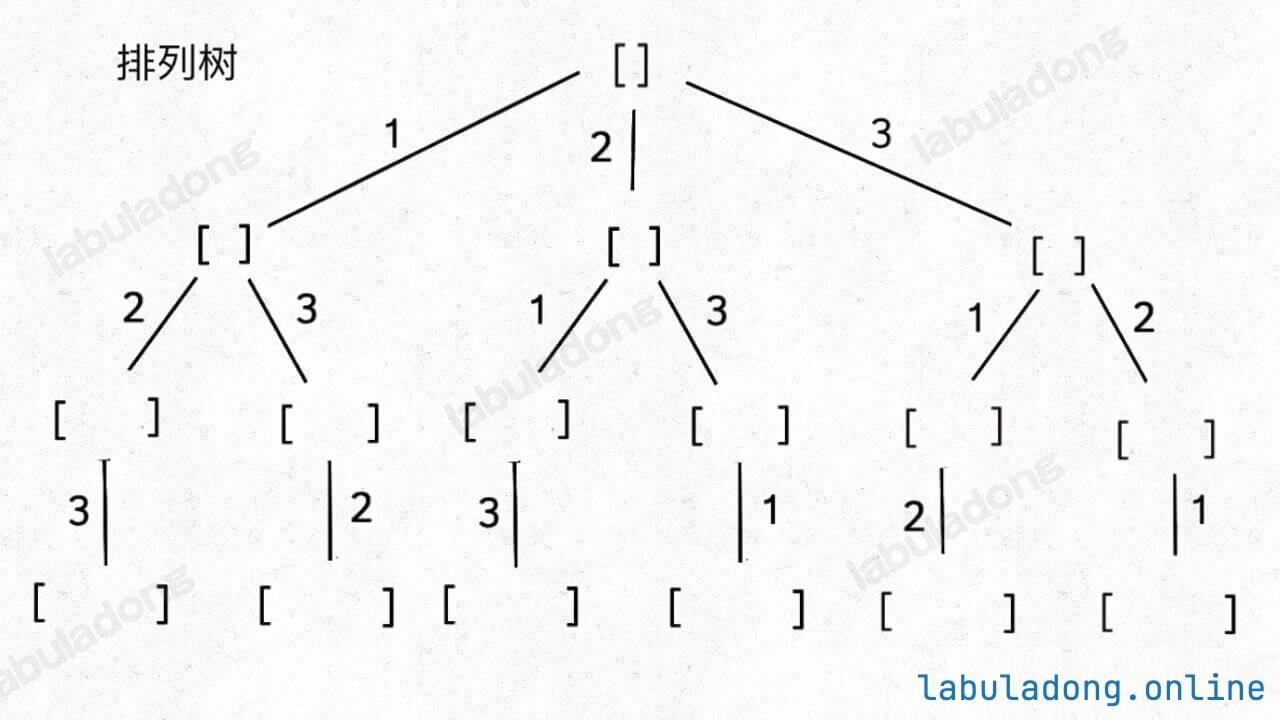
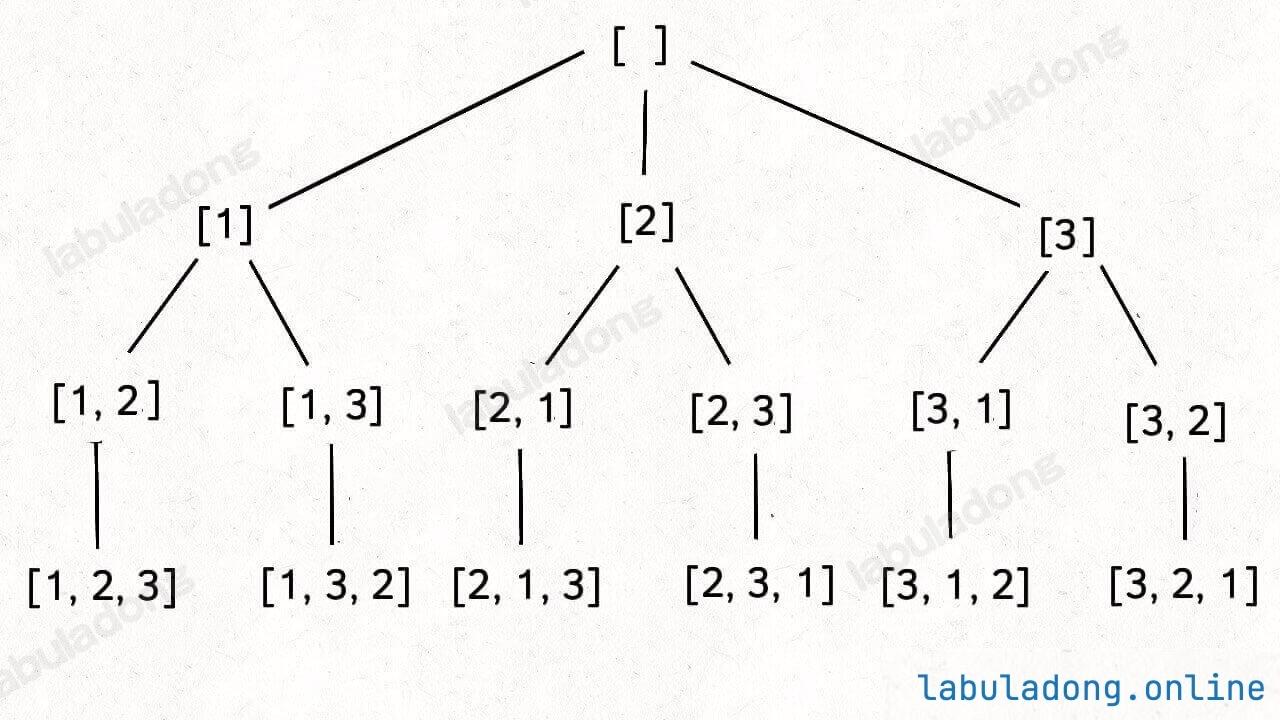
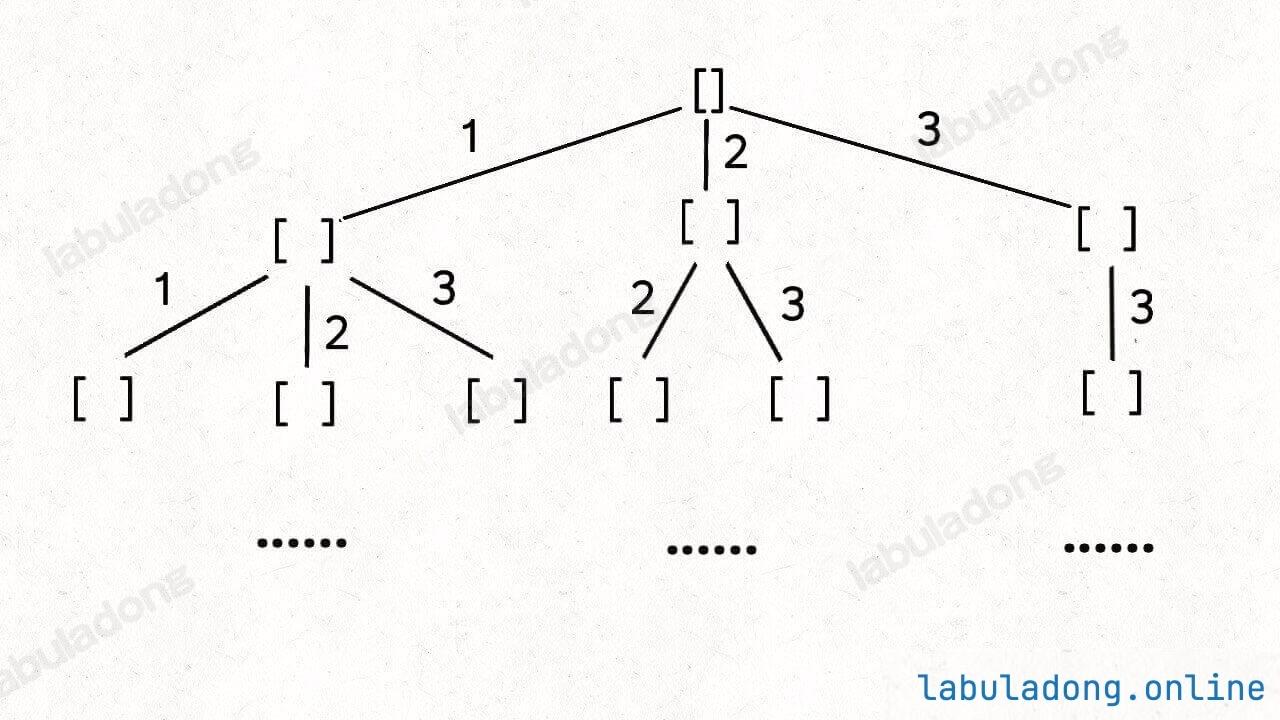
参考:46.全排列
我们这次讨论的全排列问题不包含重复的数字,包含重复数字的扩展场景在之后章节。
框架:
1 2 3 4 5 6 7 void traverse(TreeNode* root) { for (TreeNode* child : root->childern) { // 前序位置需要的操作 traverse(child); // 后序位置需要的操作 } }
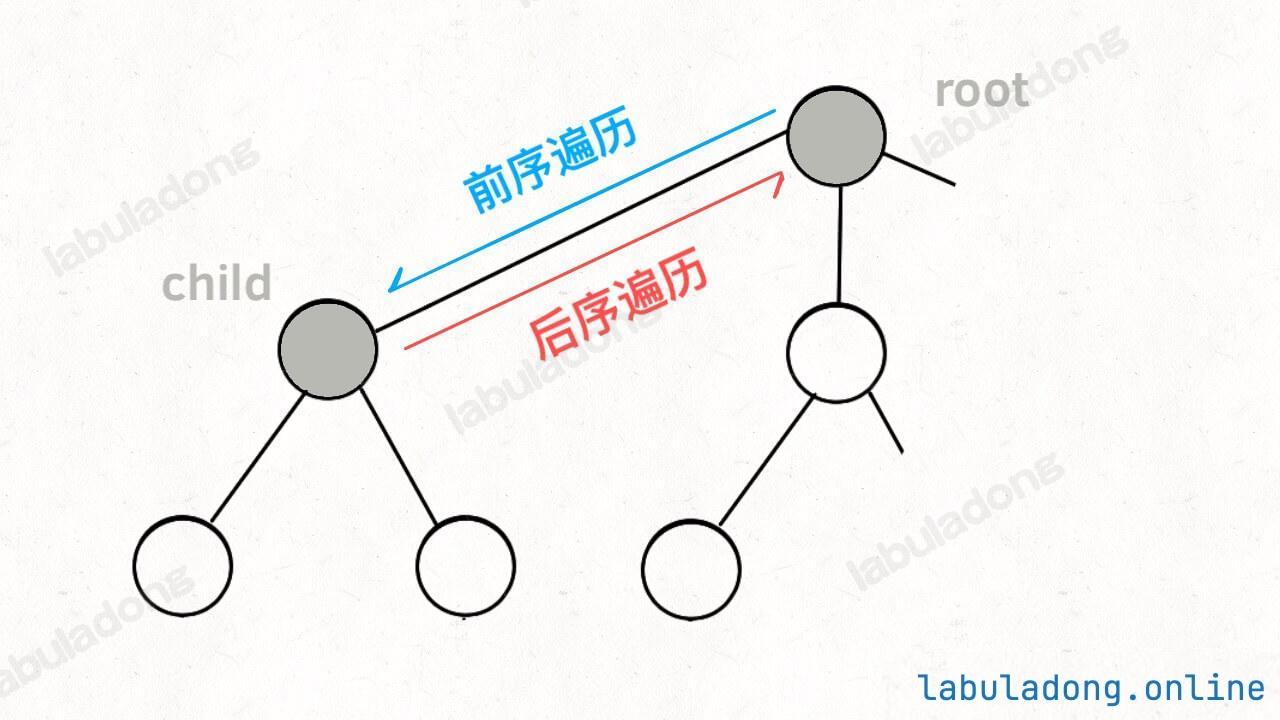
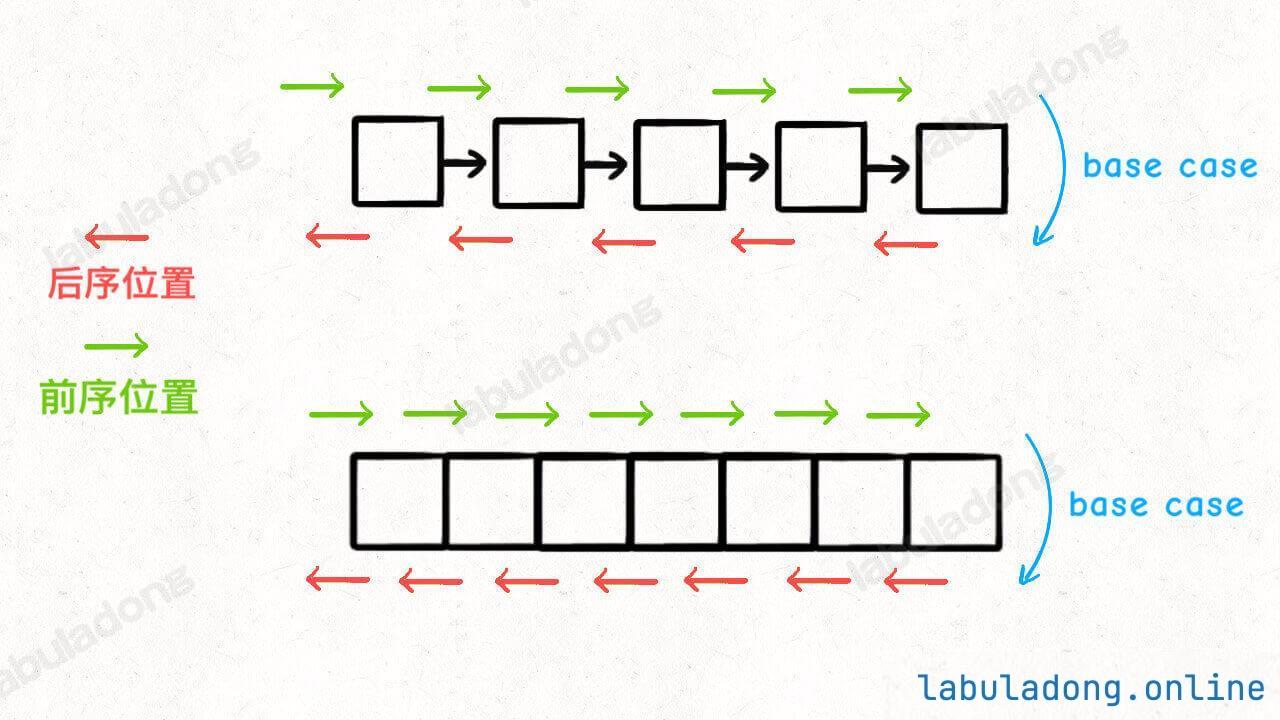
疑问:多叉树 DFS 遍历框架的前序位置和后序位置应该在 for 循环外面,并不应该是在 for 循环里面呀?为什么在回溯算法中跑到 for 循环里面了?解答回溯/DFS 算法的若干疑问 会具体讲解,这里可以暂且忽略这个问题。
前序和后序只是两个很有用的时间点:
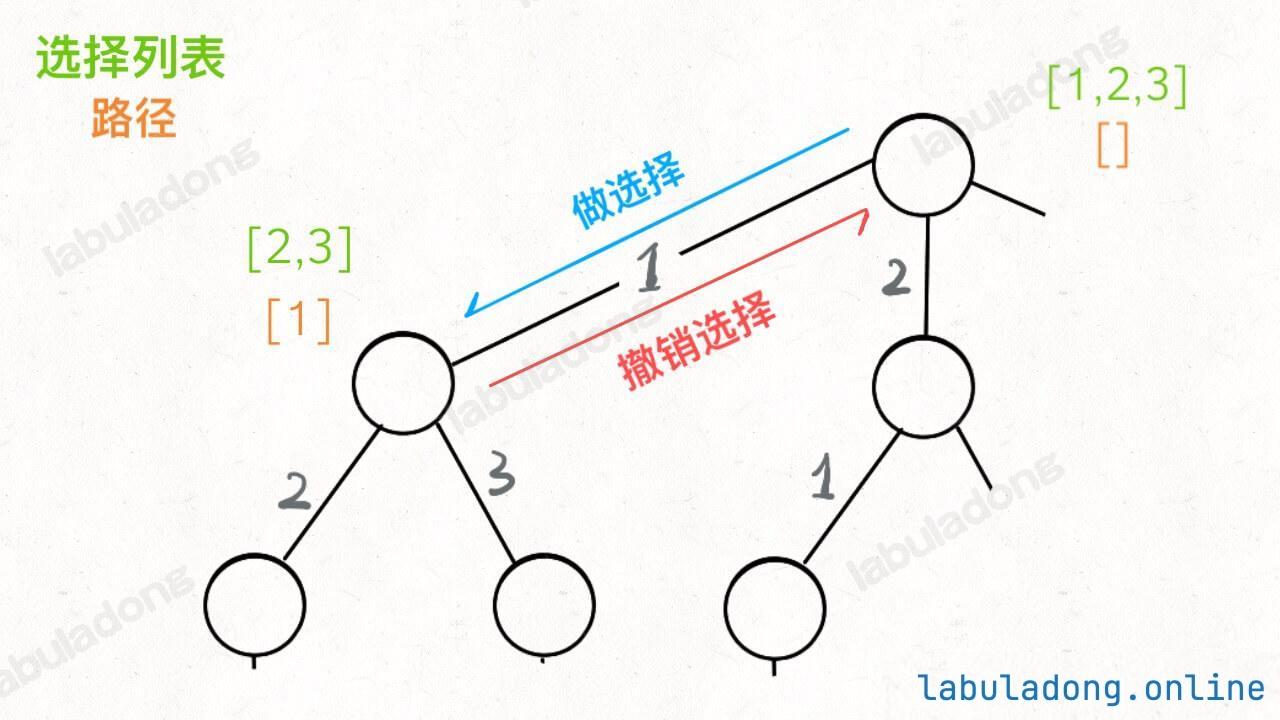
1 2 3 4 5 6 7 8 for 选择 in 选择列表: 将该选择从选择列表移除 路径.add(选择) backtrack(路径, 选择列表) 路径.remove(选择) 将该选择再加入选择列表
好的,直接看一下完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {private : vector<vector<int >> ans; vector<int > path; vector<bool > visit; public : vector<vector<int >> permute (vector<int >& nums) { visit.assign (nums.size (), false ); backtrace (nums); return ans; } void backtrace (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ if (visit[i]) continue ; path.push_back (nums[i]); visit[i] = true ; backtrace (nums); path.pop_back (); visit[i] = false ; } } };
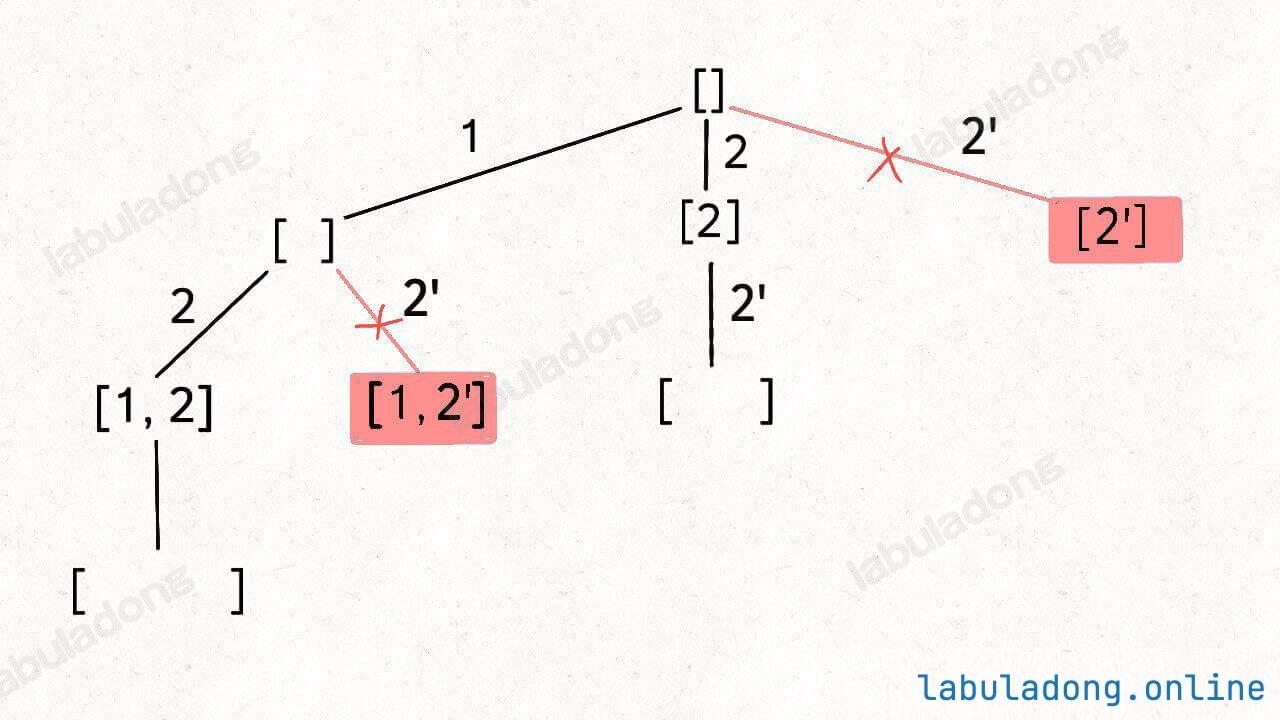
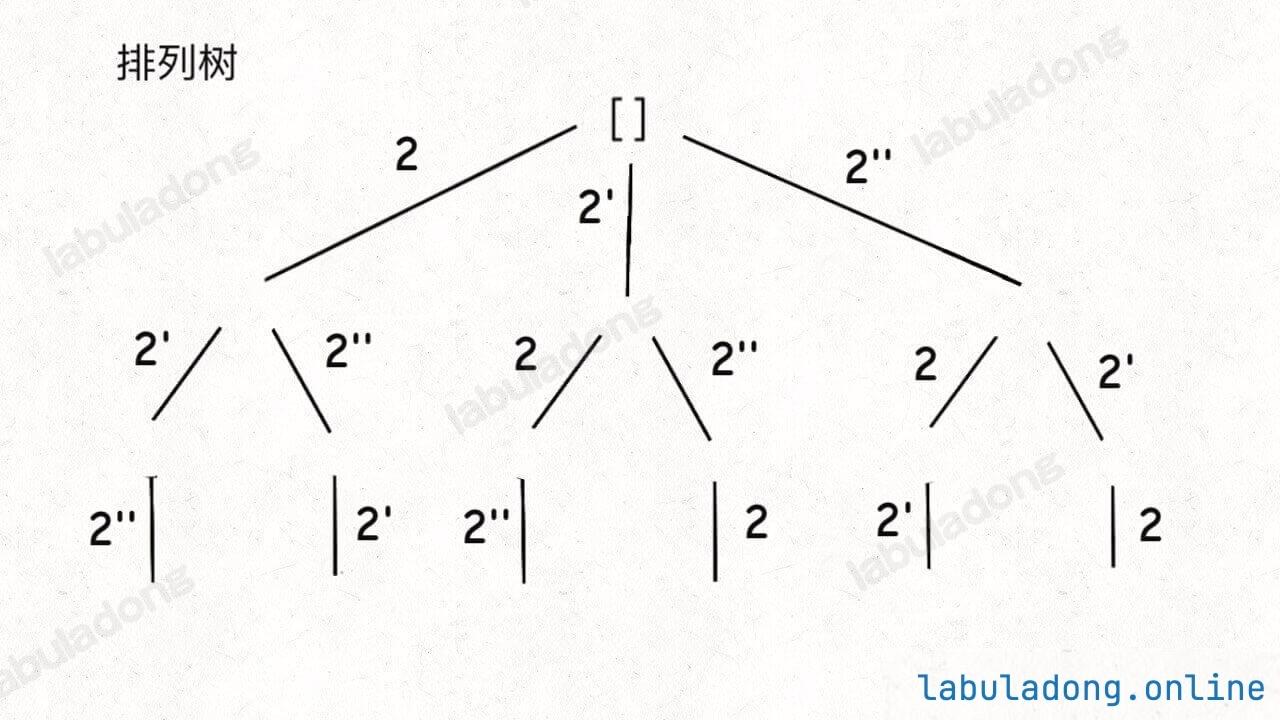
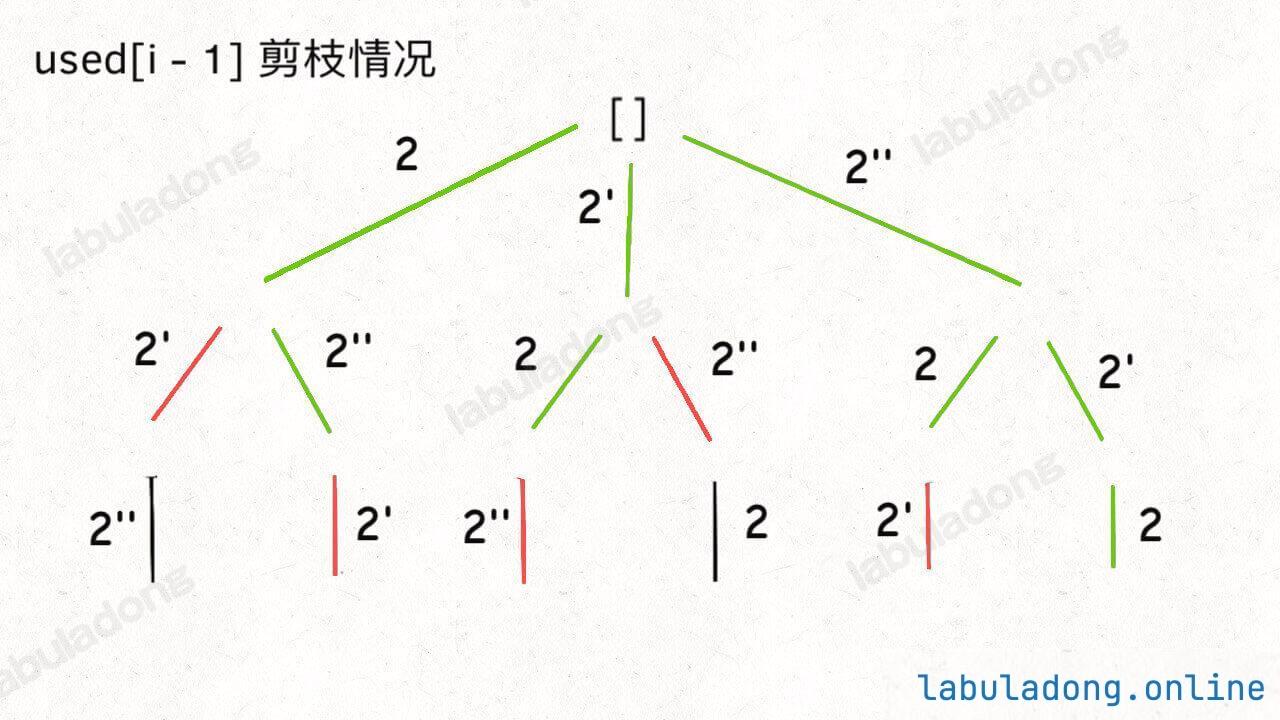
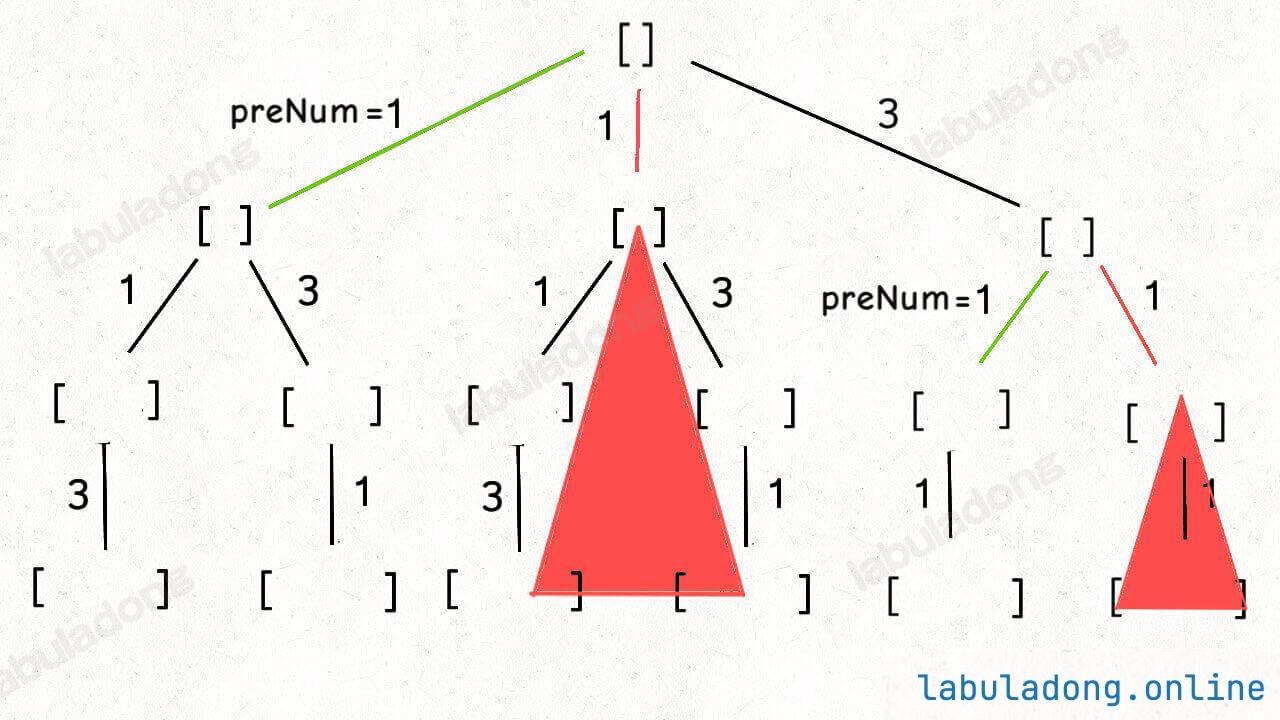
稍微做了些变通,没有显式记录「选择列表」,而是通过 used 数组排除已经存在 track 中的元素,从而推导出当前的选择列表:
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O ( N ! ) O(N!) O ( N !) N! 种全排列结果。回溯算法就是纯暴力穷举,复杂度一般都很高 。二叉树心法(纲领篇) 你将看到动态规划和回溯算法更深层次的区别和联系。
(八) BFS
DFS/回溯 算法的本质就是递归遍历一棵穷举树(多叉树),而多叉树的递归遍历又是从二叉树的递归遍历衍生出来的。所以我说 DFS/回溯算法的本质是二叉树的递归遍历 。BFS 算法的本质就是遍历一幅图 。而图的遍历算法其实就是多叉树的遍历算法加了个 visited 数组防止死循环;多叉树的遍历算法又是从二叉树遍历算法衍生出来的。所以我说 BFS 算法的本质就是二叉树的层序遍历 。
1、算法框架
在前文图的数据结构里面,已经讲解了有三种写法,这里使用第二种。
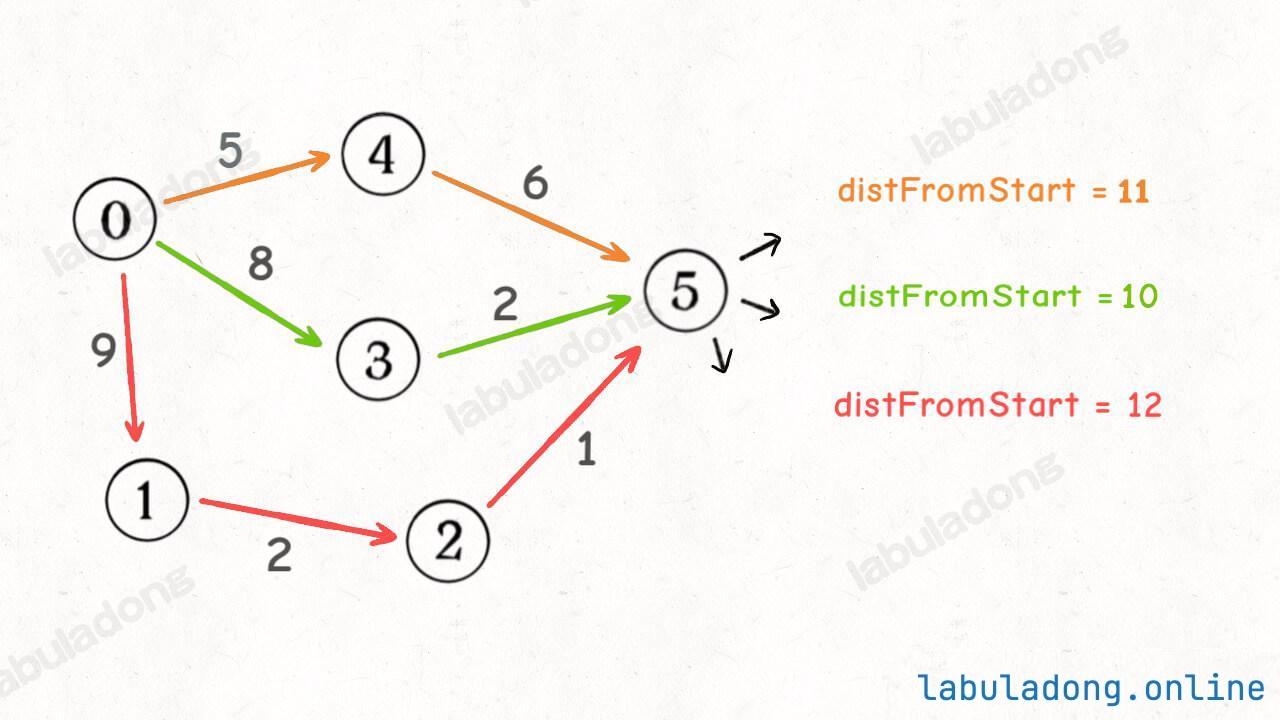
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 int bfs (const Graph& graph, int s, int target) vector<bool > visited (graph.size(), false ) ; queue<int > q; q.push (s); visited[s] = true ; int step = 0 ; while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { int cur = q.front (); q.pop (); cout << "visit " << cur << " at step " << step << endl; if (cur == target) { return step; } for (int to : neighborsOf (cur)) { if (!visited[to]) { q.push (to); visited[to] = true ; } } } step++; } return -1 ; }
2、滑动谜题
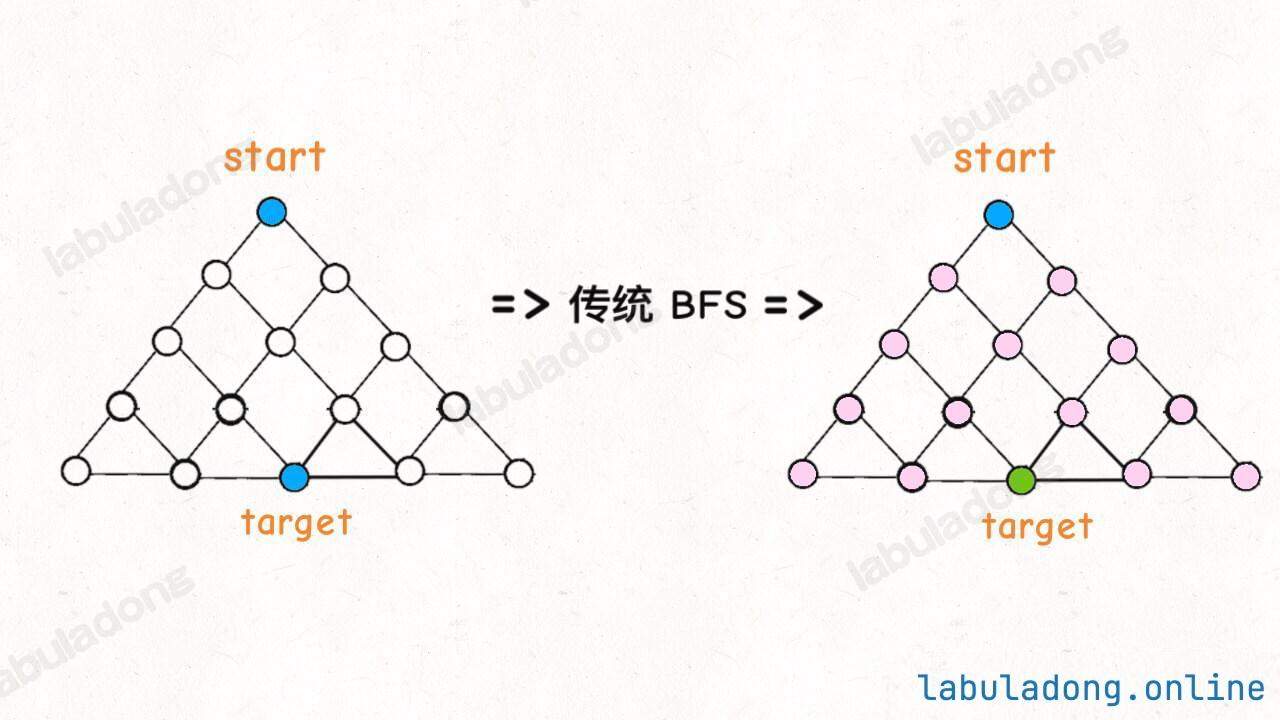
参考:773.滑动谜题
给你一个 2x3 的滑动拼图,用一个 2x3 的数组 board 表示。拼图中有数字 0~5 六个数,其中数字 0 就表示那个空着的格子,你可以移动其中的数字,当 board 变为 [[1,2,3],[4,5,0]] 时,赢得游戏。-1。board = [[4,1,2],[5,0,3]],算法应该返回 5:board = [[1,2,3],[5,4,0]],则算法返回 -1,因为这种局面下无论如何都不能赢得游戏。
抽象出来的图结构也是会包含环的,所以需要一个 visited 数组记录已经走过的节点,避免成环导致死循环。
注意,此时是整张图的状态完全和之前一样了才是成环了,所以visited的索引,应该是一整张图的状态。但二维数组这种可变数据结构是无法直接加入哈希集合的。
再用一点技巧,想办法把二维数组转化成一个不可变类型才能存到哈希集合中。常见的解决方案是把二维数组序列化成一个字符串 ,这样就可以直接存入哈希集合了。
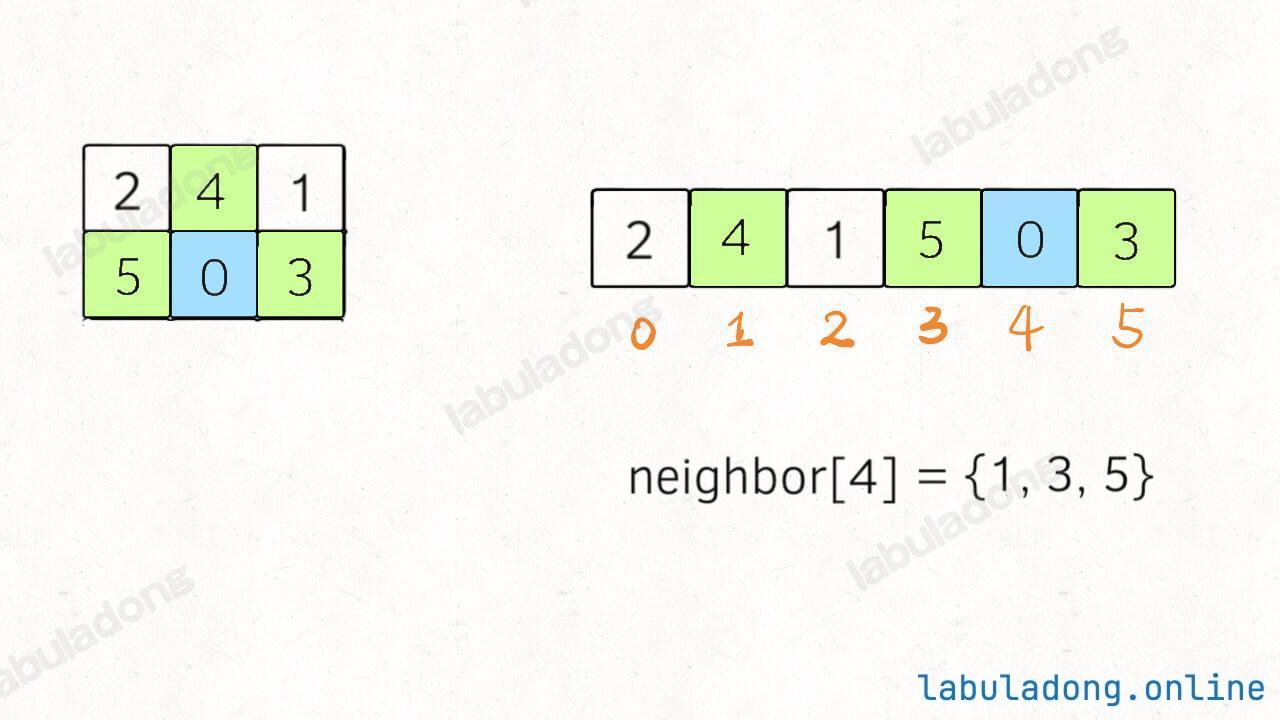
其中比较有技巧性的点在于,二维数组有「上下左右 」的概念,压缩成一维的字符串后后,还怎么把数字 0 和上下左右的数字进行交换?对于这道题,题目说输入的数组大小都是 2 x 3,所以我们可以直接手动写出来这个映射:
1 2 3 4 5 6 7 8 9 int map[6 ][3 ] = { {1 , 3 }, {0 , 2 , 4 }, {1 , 5 }, {0 , 4 }, {1 , 3 , 5 }, {2 , 4 } }
这个映射的含义就是,在一维字符串中,索引 i 在二维数组中的的相邻索引为 neighbor[i] :
如果是 m x n 的二维数组,怎么办?e 在一维数组中的索引为 i,那么 e 的左右相邻元素在一维数组中的索引就是 i - 1 和 i + 1,而 e 的上下相邻元素在一维数组中的索引就是 i - n 和 i + n,其中 n 为二维数组的列数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vector<vector<int >> generateNeighborTable (int m, int n){ vector<vector<int >> map (m*n); for (int i=0 ; i<m*n; i++){ vector<int > one; if (i%n != 0 ) one.push_back (i-1 ); if (i%n != n-1 ) one.puhs_back (i+1 ); if (i-n >= 0 ) one.push_back (i-n); if (i+n < m*n) one.push_back (i+n); map[i] = one; } return map; }
好的,至此,解法已经出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Solution {private : string target = "123450" ; unordered_set<string> visit; vector<vector<int >> map = { {1 , 3 }, {0 , 2 , 4 }, {1 , 5 }, {0 , 4 }, {1 , 3 , 5 }, {2 , 4 } }; public : int slidingPuzzle (vector<vector<int >>& board) string start = "000000" ; int m = board.size (), n = board[0 ].size (); for (int i=0 ; i<m; i++) for (int j=0 ; j<n; j++) start[i*n+j] = board[i][j] + '0' ; queue<string> Q; Q.push (start); visit.insert (start); int step = 0 ; while (!Q.empty ()){ int sz = Q.size (); for (int i=0 ; i<sz; i++){ string cur = Q.front (); Q.pop (); if (cur == target) return step; for (string next: getNeighbor (cur)){ if (visit.count (next)) continue ; Q.push (next); visit.insert (next); } } step++; } return -1 ; } vector<string> getNeighbor (string cur) { vector<string> all; int zero = cur.find ('0' ); for (int idx: map[zero]){ string next = cur; next[zero] = cur[idx]; next[idx] = cur[zero]; all.push_back (next); } return all; } };
你会发现,这里对于 visit 只有 insert 并没有 erase,因为并不会回滚,我们是 BFS,广度优先遍历不存在回滚状态。
3、解开密码锁的最少次数
参考:752.打开转盘锁
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。'0000' ,一个代表四个拨轮的数字的字符串。deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。target 代表可以解锁的数字,你需要给出解锁需要的最小旋转次数,如果无论如何不能解锁,返回 -1 。
示例1:deadends = ["8888"], target = "0009"1"0000" -> "0009"。
示例2:deadends = ["0201","0101","0102","1212","2002"], target = "0202"6"0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202"。注意 "0000" -> "0001" -> "0002" -> "0102" -> "0202" 这样的序列是不能解锁的,因为当拨动到 “0102” 时这个锁就会被锁定。
千万不要陷入细节,尝试去想各种具体的情况。要知道算法的本质就是穷举 ,我们直接从 “0000” 开始暴力穷举,把所有可能的拨动情况都穷举出来,难道还怕找不到最少的拨动次数么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Solution {private : unordered_set<string> visit; unordered_set<string> dead; public : int openLock (vector<string>& deadends, string target) for (string state: deadends) dead.insert (state); queue<string> Q; Q.push ("0000" ); int step = 0 ; while (!Q.empty ()){ int sz = Q.size (); for (int i=0 ; i<sz; i++){ string cur = Q.front (); Q.pop (); if (cur == target) return step; if (dead.count (cur)) continue ; for (string next : getNeighbors (cur)){ if (visit.count (next)) continue ; Q.push (next); visit.insert (next); } } step++; } return -1 ; } vector<string> getNeighbors (string cur) { vector<string> all; char map[10 ][2 ] = { {'9' ,'1' }, {'0' ,'2' }, {'1' ,'3' },{'2' ,'4' }, {'3' ,'5' }, {'4' ,'6' }, {'5' ,'7' }, {'6' ,'8' },{'7' ,'9' }, {'8' ,'0' } }; for (int i=0 ; i<4 ; i++){ string next = cur; next[i] = map[cur[i]-'0' ][0 ]; all.push_back (next); next[i] = map[cur[i]-'0' ][1 ]; all.push_back (next); } return all; } };
注:这里对于死亡状态的处理,也可以在准备入队的时候就直接不入队。各有利弊。
4、双向 BFS 优化
下面再介绍一种 BFS 算法的优化思路:双向 BFS,可以提高 BFS 搜索的效率。
双向 BFS 就是从标准的 BFS 算法衍生出来的:传统的 BFS 框架是从起点开始向四周扩散,遇到终点时停止 ;而双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止 。
图示中的树形结构,如果终点在最底部,按照传统 BFS 算法的策略,会把整棵树的节点都搜索一遍,最后找到 target;而双向 BFS 其实只遍历了半棵树就出现了交集,也就是找到了最短距离。
当然从 Big O 表示法分析算法复杂度的话,这两种 BFS 在最坏情况下都可能遍历完所有节点,所以理论时间复杂度都是 O ( N ) O(N) O ( N ) 实际运行中双向 BFS 确实会更快 一些。
双向 BFS 的局限性:你必须知道终点 在哪里,才能使用双向 BFS 进行优化。
以密码锁为例,这里直接给代码,不再讲解,实际上考试和竞赛,就用上述的代码就行。这里的优化,只需要知道有这么一个思路,在面试时可以讲出来就行,不追求代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class Solution {public : int openLock (vector<string>& deadends, string target) unordered_set<string> deads (deadends.begin(), deadends.end()) ; if (deads.count ("0000" )) return -1 ; if (target == "0000" ) return 0 ; unordered_set<string> q1; unordered_set<string> q2; unordered_set<string> visited; int step = 0 ; q1.insert ("0000" ); visited.insert ("0000" ); q2.insert (target); visited.insert (target); while (!q1.empty () && !q2.empty ()) { step++; unordered_set<string> newQ1; for (const string& cur : q1) { for (const string& neighbor : getNeighbors (cur)) { if (q2.count (neighbor)) { return step; } if (!visited.count (neighbor) && !deads.count (neighbor)) { newQ1.insert (neighbor); visited.insert (neighbor); } } } q1 = newQ1; if (q1.size () > q2.size ()) { swap (q1, q2); } } return -1 ; } string plusOne (string s, int j) { if (s[j] == '9' ) s[j] = '0' ; else s[j] += 1 ; return s; } string minusOne (string s, int j) { if (s[j] == '0' ) s[j] = '9' ; else s[j] -= 1 ; return s; } vector<string> getNeighbors (string s) { vector<string> neighbors; for (int i = 0 ; i < 4 ; i++) { neighbors.push_back (plusOne (s, i)); neighbors.push_back (minusOne (s, i)); } return neighbors; } };
双向 BFS 还是遵循 BFS 算法框架的,但是有几个细节区别:
不再使用队列存储元素,而是改用 哈希集合,方便快速判两个集合是否有交集 。
调整了 return step 的位置。因为双向 BFS 中不再是简单地判断是否到达终点,而是判断两个集合是否有交集,所以要在计算出邻居节点时就进行判断。
还有一个优化点,每次都保持 q1 是元素数量较小的集合,这样可以一定程度减少搜索次数。
不过话说回来,无论传统 BFS 还是双向 BFS,无论做不做优化,从 Big O 衡量标准来看,时间复杂度都是一样的 ,只能说双向 BFS 是一种进阶技巧,算法运行的速度会相对快一点,掌握不掌握其实都无所谓。
(九) 二叉树系列
二叉树解题的思维模式分两类:
是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历 」的思维模式。
是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题 」的思维模式。一个二叉树节点 ,它需要做什么事情 ?需要在什么时候(前/中/后序位置)做 ?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
算法
思想
关注点
操作位置
区别
动态规划
分解
整个子树
后序位置
\
回溯
遍历(递归)
树枝(边)
\
做选择、撤销选择在for循环里面
DFS
遍历(递归)
节点
\
做选择、撤销选择在for循环外面
BFS
遍历(迭代)
节点
\
\
1、二叉树的重要性、深入理解前中后序
举个例子,比如两个经典排序算法 快速排序 和 归并排序,对于它俩,你有什么理解?
如果你告诉我,快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后序遍历 ,那么我就知道你是个算法高手了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void sort (vector<int >& nums, int lo, int hi) int p = partition (nums, lo, hi); sort (nums, lo, p - 1 ); sort (nums, p + 1 , hi); } void sort (vector<int >& nums, int lo, int hi) if (hi <= lo) return ; int mid = lo + (hi - lo) / 2 ; sort (nums, lo, mid); sort (nums, mid + 1 , hi); merge (nums, lo, mid, hi); }
旨在说明,二叉树的算法思想的运用广泛,甚至可以说,只要涉及递归,都可以抽象成二叉树的问题。
1、你理解的二叉树的前中后序遍历是什么,仅仅是三个顺序不同的 List 吗?
2、请分析,后序遍历有什么特殊之处?
3、请分析,为什么多叉树没有中序遍历?
1 2 3 4 5 6 7 8 9 10 void traverse (TreeNode* root) if (root == nullptr ) { return ; } traverse (root->left); traverse (root->right); }
先不管所谓前中后序,单看 traverse 函数,你说它在做什么事情?其实它就是一个能够遍历二叉树所有节点的一个函数,和你遍历数组或者链表本质上没有区别:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void traverse (vector<int >& arr) for (int i = 0 ; i < arr.size (); i++) { } } void traverse (vector<int >& arr, int i) if (i == arr.size ()) { return ; } traverse (arr, i + 1 ); } struct ListNode { int val; ListNode *next; }; void traverse (ListNode* head) for (ListNode* p = head; p != nullptr ; p = p->next) { } } void traverse (ListNode* head) if (head == nullptr ) { return ; } traverse (head->next); }
单链表和数组的遍历可以是迭代的,也可以是递归的,二叉树这种结构无非就是二叉链表,它没办法简单改写成 for 循环的迭代形式,所以我们遍历二叉树一般都使用递归形式。你也注意到了,只要是递归形式的遍历,都可以有前序位置和后序位置,分别在递归之前和递归之后。
所谓前序位置 ,就是刚进入一个节点(元素)的时候 ,后序位置 就是即将离开一个节点(元素)的时候 ,那么进一步,你把代码写在不同位置,代码执行的时机也不同:
比如说,如果让你倒序打印 一条单链表上所有节点的值,你怎么搞?实现方式当然有很多,但如果你对递归的理解足够透彻,可以利用后序位置来操作:
1 2 3 4 5 6 7 8 9 void traverse (ListNode* head) if (head == nullptr ) { return ; } traverse (head->next); cout << head->val << endl; }
本质上是利用递归的堆栈 帮你实现了倒序遍历的效果。
前序位置的代码在刚刚进入一个二叉树节点的时候执行;节点 的三个特殊时间点 。唯一一次左子树切换右子树 ,而多叉树节点可能有很多子节点,会多次切换子树去遍历,所以多叉树节点没有「唯一」的中序遍历位置 。
二叉树的所有问题,就是让你在前中后序位置注入巧妙的代码逻辑,去达到自己的目的,你只需要单独思考每一个节点应该做什么,其他的不用你管,抛给二叉树遍历框架,递归会在所有节点上做相同的操作 。
2、两种解题思路
二叉树题目的递归解法可以分两类思路,遍历 一遍二叉树得出答案,分解 问题计算出答案,回溯 算法核心框架 和 动态规划 核心框架。
二叉树的最大深度这个问题来举例:
遍历思路 :所谓最大深度就是根节点到「最远」叶子节点的最长路径上的节点数。遍历一遍二叉树,用一个外部变量记录每个节点所在的深度,取最大值就可以得到最大深度。分解思路 :一棵二叉树的最大深度可以通过子树的最大深度推导出来。
那么我们再回头看看最基本的二叉树前中后序遍历 ,就比如力扣第 144 题「二叉树的前序遍历 」,让你计算前序遍历结果。
普通解法,就是遍历思想 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public : vector<int > res; vector<int > preorderTraversal (TreeNode* root) { traverse (root); return res; } void traverse (TreeNode* root) if (root == nullptr ) { return ; } res.push_back (root->val); traverse (root->left); traverse (root->right); } };
能否改成分解思想 ?一棵二叉树的前序遍历结果 = 根节点 + 左子树的前序遍历结果 + 右子树的前序遍历结果 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : vector<int > preorderTraversal (TreeNode* root) { vector<int > res; if (root == nullptr ) { return res; } res.push_back (root->val); vector<int > left = preorderTraversal (root->left); res.insert (res.end (), left.begin (), left.end ()); vector<int > right = preorderTraversal (root->right); res.insert (res.end (), right.begin (), right.end ()); return res; } };
综上,遇到一道二叉树的题目时的通用思考过程是:是否可以通过遍历一遍二叉树得到答案 ?如果可以,用一个 traverse 函数配合外部变量来实现。是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案 ?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值。无论使用哪一种思维模式,你都要明白二叉树的每一个节点需要做什么,需要在什么时候(前中后序)做 。
小题狂练-二叉树系列
3、后序位置的特殊之处
先简单说下前序和中序:
前序位置本身其实没有什么特别的性质,之所以你发现好像很多题都是在前序位置写代码,实际上是因为我们习惯把那些对前中后序位置不敏感的代码写在前序位置罢了。
中序位置主要用在 BST(二叉搜索树) 场景中,你完全可以把 BST 的中序遍历认为是遍历有序数组。
仔细观察,前中后序位置的代码,能力依次增强 。
前序位置的代码只能从函数参数中获取父节点传递来的数据 。
中序位置的代码不仅可以获取参数数据,还可以获取到左子树通过函数返回值 传递回来的数据。
后序位置的代码最强,不仅可以获取参数数据,还可以同时获取到左右子树通过函数返回值 传递回来的数据。
所以,某些情况下把代码移到后序位置效率最高;有些事情,只有后序位置的代码能做 。
举些具体的例子来感受下它们的能力区别。现在给你一棵二叉树,我问你两个简单的问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 void traverse (TreeNode* root, int level) if (root == nullptr ) { return ; } printf ("Node %d at level %d" , root->val, level); traverse (root->left, level + 1 ); traverse (root->right, level + 1 ); } traverse (root, 1 );
第二题:
1 2 3 4 5 6 7 8 9 10 11 12 13 int count (TreeNode* root) if (root == nullptr ) { return 0 ; } int leftCount = count (root->left); int rightCount = count (root->right); printf ("节点 %p 的左子树有 %d 个节点,右子树有 %d 个节点" , root, leftCount, rightCount); return leftCount + rightCount + 1 ; }
一个节点在第几层,你从根节点遍历过来的过程就能顺带记录,用递归函数的参数就能传递下去;而以一个节点为根的整棵子树有多少个节点,你必须遍历完子树之后才能数清楚,然后通过递归函数的返回值拿到答案。一旦你发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了 。
543.二叉树的直径
所谓二叉树的「直径」长度,就是任意两个结点之间的路径长度(经过的连线数量)。最长「直径」并不一定要穿过根结点。
解决这题的关键在于,每一条二叉树的「直径」长度,就是一个节点的左右子树的最大深度之和 。
先看下面的解法,或许你会觉得奇怪:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {public : int maxDiameter = 0 ; int diameterOfBinaryTree (TreeNode* root) traverse (root); return maxDiameter; } private : void traverse (TreeNode* root) if (root == nullptr ) { return ; } int leftMax = maxDepth (root->left); int rightMax = maxDepth (root->right); int myDiameter = leftMax + rightMax; maxDiameter = max (maxDiameter, myDiameter); traverse (root->left); traverse (root->right); } int maxDepth (TreeNode* root) if (root == nullptr ) { return 0 ; } int leftMax = maxDepth (root->left); int rightMax = maxDepth (root->right); return 1 + max (leftMax, rightMax); } };
这里实际上是使用前序遍历来做题,你会觉得奇怪,是前序位置还没得到子树的深度情况,不得不去调用递归函数获得数据。而后再对子树进行遍历。时间复杂度也高达 O ( n 2 ) O(n^2) O ( n 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {private : int ans = 0 ; public : int diameterOfBinaryTree (TreeNode* root) maxDeep (root); return ans; } int maxDeep (TreeNode* root) if (root == NULL ) return 0 ; int ld = maxDeep (root->left); int rd = maxDeep (root->right); ans = max (ans, ld+rd); return max (ld+1 , rd+1 ); } };
思考题:请你思考一下,运用后序遍历的题目使用的是「遍历」的思路还是「分解问题」的思路 ?
4、以树的视角看动归/回溯/DFS算法的区别和联系
动归/DFS/回溯算法都可以看做二叉树问题的扩展,只是它们的关注点不同:
动态规划 算法属于分解 问题(分治)的思路,它的关注点在整棵「子树 」。回溯 算法属于遍历 的思路,它的关注点在节点间的「树枝 」。DFS 算法属于遍历 的思路,它的关注点在单个「节点 」。
此外,两个遍历的区别在于:回溯算法和 DFS 算法代码中「做选择 」和「撤销选择 」的位置不同 。for 循环外面 ;for 循环里面 。
例子1:分解思路(动态规划)
1 2 3 4 5 6 7 8 9 10 11 12 int count (TreeNode* root) if (root == nullptr ) { return 0 ; } int leftCount = count (root->left); int rightCount = count (root->right); return leftCount + rightCount + 1 ; }
这就是动态规划分解问题的思路,它的着眼点永远是结构相同的整个子问题 ,类比到二叉树上就是「子树 」。
1 2 3 4 int fib (int N) if (N == 1 || N == 2 ) return 1 ; return fib (N - 1 ) + fib (N - 2 ); }
例子2:遍历思路(回溯)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void traverse (TreeNode* root) if (root == nullptr ) return ; printf ("从节点 %s 进入节点 %s" , root, root->left); traverse (root->left); printf ("从节点 %s 回到节点 %s" , root->left, root); printf ("从节点 %s 进入节点 %s" , root, root->right); traverse (root->right); printf ("从节点 %s 回到节点 %s" , root->right, root); } class Node {public : int val; std::vector<Node*> children; }; void traverse (Node* root) if (root == NULL ) return ; for (Node* child : root->children) { std::cout << "从节点 " << root->val << " 进入节点 " << child->val << std::endl; traverse (child); std::cout << "从节点 " << child->val << " 回到节点 " << root->val << std::endl; } }
你看,这就是回溯算法遍历的思路,它的着眼点永远是在节点之间移动的过程 ,类比到二叉树上就是「树枝 」。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void backtrack (int [] nums) for (int i = 0 ; i < nums.length; i++) { used[i] = true ; track.addLast (nums[i]); backtrack (nums); track.removeLast (); used[i] = false ; } }
例子3:遍历思路(DFS)
1 2 3 4 5 6 7 void traverse (TreeNode* root) if (root == nullptr ) return ; root->val++; traverse (root->left); traverse (root->right); }
你看,这就是 DFS 算法遍历的思路,它的着眼点永远是在单一的节点上 ,类比到二叉树上就是处理每个「节点 」。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void dfs (int [][] grid, int i, int j) int m = grid.length, n = grid[0 ].length; if (i < 0 || j < 0 || i >= m || j >= n) { return ; } if (grid[i][j] == 0 ) { return ; } grid[i][j] = 0 ; dfs (grid, i + 1 , j); dfs (grid, i, j + 1 ); dfs (grid, i - 1 , j); dfs (grid, i, j - 1 ); }
综上,动态规划关注整棵「子树」,回溯算法关注节点间的「树枝」,DFS 算法关注单个「节点」 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void dfs (Node* root) if (!root) return ; printf ("enter node %s\n" , root->val.c_str ()); for (Node* child : root->children) { dfs (child); } printf ("leave node %s\n" , root->val.c_str ()); } void backtrack (Node* root) if (!root) return ; for (Node* child : root->children) { printf ("I'm on the branch from %s to %s\n" , root->val.c_str (), child->val.c_str ()); backtrack (child); printf ("I'll leave the branch from %s to %s\n" , child->val.c_str (), root->val.c_str ()); } }
看到了吧,你回溯算法必须把「做选择」和「撤销选择」的逻辑放在 for 循环里面,否则怎么拿到「树枝」的两个端点 ?
5、层序遍历
二叉树题型主要是用来培养递归思维的,而层序遍历属于迭代遍历。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void levelTraverse (TreeNode* root) if (root == nullptr ) return ; queue<TreeNode*> q; q.push (root); while (!q.empty ()) { int sz = q.size (); for (int i = 0 ; i < sz; i++) { TreeNode* cur = q.front (); q.pop (); if (cur->left != nullptr ) { q.push (cur->left); } if (cur->right != nullptr ) { q.push (cur->right); } } } }
这里面 while 循环和 for 循环分管从上到下和从左到右的遍历:
BFS 算法框架 就是从二叉树的层序遍历 扩展出来的,常用于求无权图的最短路径问题。
拓展:玩的足够花的话,会有各种方法实现层序遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public : vector<vector<int >> res; vector<vector<int >> levelTraverse (TreeNode* root) { if (root == nullptr ) { return res; } traverse (root, 0 ); return res; } void traverse (TreeNode* root, int depth) if (root == nullptr ) { return ; } if (res.size () <= depth) { res.push_back (vector<int > {}); } res[depth].push_back (root->val); traverse (root->left, depth + 1 ); traverse (root->right, depth + 1 ); } };
这种思路从结果上说确实可以得到层序遍历结果,但其本质还是二叉树的前序遍历,或者说 DFS 的思路,而不是层序遍历,或者说 BFS 的思路。因为这个解法是依赖前序遍历自顶向下、自左向右的顺序特点得到了正确的结果。抽象点说,这个解法更像是从左到右的「列序遍历」,而不是自顶向下的「层序遍历」 。所以对于计算最小距离的场景,这个解法完全等同于 DFS 算法,没有 BFS 算法的性能的优势。
第二个花活:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution {private : vector<vector<int >> res; public : vector<vector<int >> levelTraverse (TreeNode* root) { if (root == NULL ) { return res; } vector<TreeNode*> nodes; nodes.push_back (root); traverse (nodes); return res; } void traverse (vector<TreeNode*>& curLevelNodes) if (curLevelNodes.empty ()) { return ; } vector<int > nodeValues; vector<TreeNode*> nextLevelNodes; for (TreeNode* node : curLevelNodes) { nodeValues.push_back (node->val); if (node->left != NULL ) { nextLevelNodes.push_back (node->left); } if (node->right != NULL ) { nextLevelNodes.push_back (node->right); } } res.push_back (nodeValues); traverse (nextLevelNodes); } };
这个 traverse 函数很像递归遍历单链表的函数,其实就是把二叉树的每一层抽象理解成单链表的一个节点进行遍历 。相较上一个递归解法,这个递归解法是自顶向下的「层序遍历」,更接近 BFS 的奥义,可以作为 BFS 算法的递归实现扩展一下思维。
问:最后,不懂什么时候要新增traverse函数,什么时候直接用题目给的原函数递归。比如二叉树的直径,解法是需要新增一个递归函数maxDepth。我尝试直接递归原函数diameterOfBinaryTree,但行不通?操作外部变量 ,题目最终要的答案是那个外部变量 ,而不是 maxDepth 的返回值 。所以这种情况下只能新建一个函数 。如果题目要的答案恰好是你函数的返回值,那么你才可以直接用原函数递归。
(十) 排列、组合、子集(回溯)
无论是排列、组合还是子集问题,简单说无非就是让你从序列 nums 中以给定规则取若干元素,主要有以下几种变体:
形式一、元素无重不可复选 ,即 nums 中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。nums = [2,3,6,7],和为 7 的组合应该只有 [7]。
形式二、元素有重不可复选 ,即 nums 中的元素有可能存在重复,每个元素最多只能被使用一次。
形式三、元素无重可复选 ,即 nums 中的元素都是唯一的,每个元素可以被使用若干次。
当然,也可以说有第四种形式,即元素可重可复选。但既然元素可复选,那又何必存在重复元素呢?元素去重之后就等同于形式三 ,所以这种情况不用考虑。target 且元素个数为 k 的组合,那这么一来又可以衍生出一堆变体。无论形式怎么变化,其本质就是穷举所有解 ,而这些解呈现树形结构 ,所以合理使用回溯算法框架 ,稍改代码框架即可把这些问题一网打尽。
记住如下子集问题和排列问题的回溯树:
首先,组合问题和子集问题其实是等价的 ,这个后面会讲;至于之前说的三种变化 形式,无非是在这两棵树上剪掉或者增加 一些树枝罢了。
1、子集(元素无重不可复选)
参考:78.子集
给你一个无重复元素的数组 nums,其中每个元素最多使用一次,请你返回 nums 的所有子集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {private : vector<vector<int >> ans; vector<int > path; public : vector<vector<int >> subsets (vector<int >& nums) { backtrace (nums, 0 ); return ans; } void backtrace (vector<int >& nums, int start) ans.push_back (path); for (int i=start; i<nums.size (); i++){ path.push_back (nums[i]); backtrace (nums, i+1 ); path.pop_back (); } } };
我们通过保证元素之间的相对顺序不变来防止出现重复的子集。
2、组合(元素无重不可复选)
如果你能够成功的生成所有无重子集,那么你稍微改改代码就能生成所有无重组合了。nums = [1,2,3] 中拿 2 个元素形成所有的组合,你怎么做?稍微想想就会发现,大小为 2 的所有组合,不就是所有大小为 2 的子集嘛。所以我说组合和子集是一样的:大小为 k 的组合就是大小为 k 的子集 。77.组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
反映到代码上,只需要稍改 base case,控制算法仅仅收集第 k 层节点的值 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {private : vector<vector<int >> ans; vector<int > path; public : vector<vector<int >> combine (int n, int k) { backtrace (n, k, 1 ); return ans; } void backtrace (int n, int k, int start) if (path.size () == k){ ans.push_back (path); return ; } for (int i=start; i<=n; i++){ path.push_back (i); backtrace (n, k, i+1 ); path.pop_back (); } } };
3、排列(元素无重不可复选)
就是全排列问题,前面讲过。46.全排列
给定一个不含重复数字的数组 nums,返回其所有可能的全排列。used 数组标记已经在路径上的元素避免重复选择,然后收集所有叶子节点上的值,就是所有全排列的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {private : vector<vector<int >> ans; vector<int > path; vector<bool > used; public : vector<vector<int >> permute (vector<int >& nums) { used.assign (nums.size (), false ); backtrace (nums); return ans; } void backtrace (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ if (used[i]) continue ; path.push_back (nums[i]); used[i] = true ; backtrace (nums); path.pop_back (); used[i] = false ; } } };
但如果题目不让你算全排列,而是让你算元素个数为 k 的排列 ,怎么算?backtrack 函数的 base case,仅收集第 k 层的节点值即可。
4、子集/组合(元素有重不可复选)
参考:90.子集II
给你一个整数数组 nums,其中可能包含重复元素,请你返回该数组所有可能的子集。
比如输入 nums = [1,2,2],你应该输出:[ [],[1],[2],[1,2],[2,2],[1,2,2] ]
可以看到,[2] 和 [1,2] 这两个结果出现了重复,所以我们需要进行剪枝,如果一个节点有多条值相同的树枝相邻,则只遍历第一条,剩下的都剪掉,不要去遍历:相同的元素靠在一起 ,如果发现 nums[i] == nums[i-1],则跳过 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {private : vector<vector<int >> ans; vector<int > path; public : vector<vector<int >> subsetsWithDup (vector<int >& nums) { sort (nums.begin (), nums.end ()); backtrace (nums, 0 ); return ans; } void backtrace (vector<int >& nums, int start) ans.push_back (path); for (int i=start; i<nums.size (); i++){ if (i>start && nums[i] == nums[i-1 ]) continue ; path.push_back (nums[i]); backtrace (nums, i+1 ); path.pop_back (); } } };
组合问题和子集问题是等价的 ,下面看:40.组合总和II
给你输入 candidates 和一个目标和 target,从 candidates 中找出中所有和为 target 的组合。candidates 可能存在重复元素,且其中的每个数字最多只能使用一次。
说这是一个组合问题,其实换个问法就变成子集问题了:请你计算 candidates 中所有和为 target 的子集。
只要额外用一个 trackSum 变量记录回溯路径上的元素和,然后将 base case 改一改即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {private : vector<vector<int >> ans; vector<int > path; int curSum = 0 ; public : vector<vector<int >> combinationSum2 (vector<int >& candidates, int target) { sort (candidates.begin (), candidates.end ()); backtrace (candidates, target, 0 ); return ans; } void backtrace (vector<int >& candidates, int target, int start) if (curSum >= target){ if (curSum == target) ans.push_back (path); return ; } for (int i=start; i<candidates.size (); i++){ if (i>start && candidates[i] == candidates[i-1 ]) continue ; path.push_back (candidates[i]); curSum += candidates[i]; backtrace (candidates, target, i+1 ); path.pop_back (); curSum -= candidates[i]; } } };
5、排列(元素有重不可复选)
参考:47.全排列II
给你输入一个可包含重复数字的序列 nums,请你写一个算法,返回所有可能的全排列。
比如输入 nums = [1,2,2],函数返回:[ [1,2,2],[2,1,2],[2,2,1] ]
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {private : vector<vector<int >> ans; vector<int > path; vector<bool > used; public : vector<vector<int >> permuteUnique (vector<int >& nums) { used.assign (nums.size (), false ); sort (nums.begin (), nums.end ()); backtrace (nums); return ans; } void backtrace (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ if (used[i]) continue ; if (i>0 && nums[i] == nums[i-1 ] && !used[i-1 ]) continue ; path.push_back (nums[i]); used[i] = true ; backtrace (nums); path.pop_back (); used[i] = false ; } } };
比如 [1,2,2'] 和 [1,2',2] 应该只被算作同一个排列,但被算作了两个不同的排列。保证相同元素在排列中的相对位置保持不变 。
如果 nums = [1,2,2',2''],我只要保证重复元素 2 的相对位置固定,比如说 2 -> 2' -> 2'',也可以得到无重复的全排列结果。仔细思考,应该很容易明白其中的原理:标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的 ;而如果固定相同元素形成的序列顺序,当然就避免了重复 。
那么反映到代码上,你注意看这个剪枝逻辑:
1 2 3 4 5 6 if (i > 0 && nums[i] == nums[i - 1 ] && !used[i - 1 ]) { continue ; }
当出现重复元素时,比如输入 nums = [1,2,2',2''],2' 只有在 2 已经被使用的情况下才会被选择,同理,2'' 只有在 2' 已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定 。
这里拓展一下,如果你把上述剪枝逻辑中的 !used[i - 1] 改成 used[i - 1],其实也可以通过所有测试用例,但效率会有所下降,这是为什么呢?之所以这样修改不会产生错误,是因为这种写法相当于维护了 2'' -> 2' -> 2 的相对顺序,最终也可以实现去重的效果。nums = [2,2',2''],产生的回溯树如下:backtrack 函数遍历过的路径,红色树枝代表剪枝逻辑的触发,那么 !used[i - 1] 这种剪枝逻辑得到的回溯树长这样:used[i - 1] 这种剪枝逻辑得到的回溯树如下:
排列去重,也有读者提出别的剪枝思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution {private : vector<vector<int >> ans; vector<int > path; vector<bool > used; public : vector<vector<int >> permuteUnique (vector<int >& nums) { used.assign (nums.size (), false ); sort (nums.begin (), nums.end ()); backtrace (nums); return ans; } void backtrace (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } int preNum = 666 ; for (int i=0 ; i<nums.size (); i++){ if (used[i]) continue ; if (nums[i] == preNum) continue ; path.push_back (nums[i]); used[i] = true ; preNum = nums[i]; backtrace (nums); path.pop_back (); used[i] = false ; } } };
6、子集/组合(元素无重可复选)
参考:39.组合总和
给你一个无重复元素的整数数组 candidates 和一个目标和 target,找出 candidates 中可以使数字和为目标数 target 的所有组合。candidates 中的每个数字可以无限制重复被选取。
输入 candidates = [1,2,3], target = 3,算法应该返回:[ [1,1,1],[1,2],[3] ]
想解决这种类型的问题,也得回到回溯树上,我们不妨先思考思考,标准的子集/组合问题是如何保证不重复使用元素的?backtrack 递归时输入的参数 start。
这个 i 从 start 开始,那么下一层回溯树就是从 start + 1 开始,从而保证 nums[start] 这个元素不会被重复使用:
那么反过来,如果我想让每个元素被重复使用,我只要把 i + 1 改成 i 即可,这相当于给之前的回溯树添加了一条树枝,在遍历这棵树的过程中,一个元素可以被无限次使用:这棵回溯树会永远生长下去 ,所以我们的递归函数需要设置合适的 base case 以结束算法,即路径和大于 target 时就没必要再遍历下去了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {private : vector<vector<int >> ans; vector<int > path; int curSum = 0 ; public : vector<vector<int >> combinationSum (vector<int >& candidates, int target) { backtrace (candidates, target, 0 ); return ans; } void backtrace (vector<int >& candidates, int target, int start) if (curSum >= target){ if (curSum == target) ans.push_back (path); return ; } for (int i=start; i<candidates.size (); i++){ path.push_back (candidates[i]); curSum += candidates[i]; backtrace (candidates, target, i); path.pop_back (); curSum -= candidates[i]; } } };
7、排列(元素无重可复选)
参考:力扣上没有题目直接 考察这个场景,可以用46.全排列 来自己测试输入输出。
我们不妨先想一下,nums 数组中的元素无重复且可复选的情况下,会有哪些排列?
比如输入 nums = [1,2,3],那么这种条件下的全排列共有 3 3 = 27 3^3 = 27 3 3 = 27
1 2 3 4 5 [ [1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3], [2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3], [3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3] ]
标准的全排列算法利用 used 数组进行剪枝,避免重复使用同一个元素。直接放飞自我 ,去除所有 used 数组的剪枝逻辑就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {private : vector<vector<int >> ans; vector<int > path; public : vector<vector<int >> permute (vector<int >& nums) { backtrace (nums); return ans; } void backtrace (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i=0 ; i<nums.size (); i++){ path.push_back (nums[i]); backtrace (nums); path.pop_back (); } } };
8、最后总结
题型
重复说明
是否要sort
保证非重复性的关键点
收集结果的时机
收集位置
子集
无重复,不复选
No
按顺序控制下一层 start=i+1
每一个节点都收集
前序位置
组合
无重复,不复选
No
按顺序控制下一层 start=i+1
达到k大小的节点收集
前序位置
排列
无重复,不复选
No
使用 used 记录防复用
到达叶子节点(n大小)才收集
前序位置
子集/组合
有重复,不复选
Yes
按顺序控制下一层start=i+1 + 相同元素排一起
达到题目要求的节点才收集
前序位置
排列
有重复,不复选
Yes
使用 used 记录防复用 + 相同元素排一起
到达叶子节点(n 大小)才收集
前序位置
子集/组合
无重复,可复选
No
改 start = i 即可复用,注意控制结束
达到题目要求的节点才收集
前序位置
排列
无重复,可复选
No
不用used 即可,放飞自我
到达叶子节点(n大小)才收集
前序位置
形式一、元素无重不可复选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 void backtrack (vector<int >& nums, int start) if (meet the conditions){ ans.push_back (path); } for (int i = start; i < nums.size (); i++) { track.push_back (nums[i]); backtrack (nums, i + 1 ); track.pop_back (); } } void backtrack (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i = 0 ; i < nums.size (); i++) { if (used[i]) continue ; used[i] = true ; path.push_back (nums[i]); backtrack (nums); path.pop_back (); used[i] = false ; } }
形式二、元素有重不可复选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 sort (nums.begin (), nums.end ());void backtrack (vector<int >& nums, int start) if (meet the conditions){ ans.push_back (path); } for (int i = start; i < nums.size (); i++) { if (i > start && nums[i] == nums[i - 1 ]) continue ; path.push_back (nums[i]); backtrack (nums, i + 1 ); path.pop_back (); } } sort (nums.begin (), nums.end ());void backtrack (vector<int >& nums, vector<bool >& used) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i = 0 ; i < nums.size (); i++) { if (used[i]) continue ; if (i > 0 && nums[i] == nums[i - 1 ] && !used[i - 1 ]) continue ; path.push_back (nums[i]); used[i] = true ; backtrack (nums, used); path.pop_back (); used[i] = false ; } }
形式三、元素无重可复选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void backtrack (vector<int >& nums, int start) if (meet the conditions){ ans.push_back (path); } for (int i = start; i < nums.size (); i++) { path.push_back (nums[i]); backtrack (nums, i); path.pop_back (); } } void backtrack (vector<int >& nums) if (path.size () == nums.size ()){ ans.push_back (path); return ; } for (int i = 0 ; i < nums.size (); i++) { path.push_back (nums[i]); backtrack (nums); path.pop_back (); } }
只要从树的角度思考,这些问题看似复杂多变,实则改改 base case 就能解决 。
后面,还会在球盒模型:回溯算法穷举的两种视角 中进一步解说回溯。
(十一) 贪心算法
举个简单的例子,就能直观的展现贪心算法了。
比方说现在有两种钞票,面额分为为 1 元和 100 元,每种钞票的数量无限,但现在你只能选择 10 张,请问你应该如何选择,才能使得总金额最大?
那你肯定会说,这还用问么?肯定是 10 张全拿 100 元的钞票,共计 1000 元,这就是最优策略,但凡犹豫一秒就是傻瓜。
你这么说,也对,也不对。说你对,因为这确实是最优解法,没毛病。说你不对,是因为这个解法暴露的是你只想捞钱的本质 (¬‿¬) ,跳过了算法的产生、优化过程,不符合计算机思维。
那计算机就要提问了,一切算法的本质是穷举 ,现在你还没有穷举出所有可能的解法,凭什么说这就是最优解呢?按照算法思维,这个问题的本质是做 10 次选择,每次选择有两种可能,分别是 1 元和 100 元,一共有 2 10 2^{10} 2 10
1 2 3 4 5 6 7 8 9 10 11 12 int findMax (int n) if (n == 0 ) return 0 ; int result1 = 1 + findMax (n - 1 ); int result2 = 100 + findMax (n - 1 ); return Math.max (result1, result2); }
findMax(n - 1) 的值肯定都一样,那么 100 + findMax(n - 1) 必然大于 1 + findMax(n - 1),因此可以进行优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int findMax (int n) if (n == 0 ) return 0 ; int result = 100 + findMax (n - 1 ); return result; } int findMax (int n) int result = 0 ; for (int i = 0 ; i < n; i++) { result += 100 ; } return result; } int findMax (int n) return 100 * n; }
这就是贪心算法,复杂度从 O ( 2 n ) O(2^n) O ( 2 n ) O ( 1 ) O(1) O ( 1 )
1、贪心选择性质
作为对比,我们稍微改一改题目:amount,请问你最少需要多少张钞票才能凑出这个金额?
为了方便讲解,本文开头的最大金额问题我们称为「问题一」,这里的最少钞票数量问题我们称为「问题二」。
我们是如何解决问题二的?首先也是抽象出递归树,写出指数级别的暴力穷举算法,然后发现了重叠子问题,于是用备忘录消除重叠子问题,这就是标准的动态规划算法的求解过程,不能再优化了。
所以,这两个问题到底有什么区别?区别在于,问题二没有贪心选择性质,而问题一有 。
贪心选择性质 就是说能够通过局部最优解直接 推导出全局最优解。
对于问题一,局部最优解就是每次都选择 100 元,因为 100 > 1;对于问题二,局部最优解也是每次都选择 100 元,因为每张面额尽可能大,所需的钞票数量就能尽可能少。但区别在于,问题一中每一次选择的局部最优解组合起来就是全局最优解 ,而问题二中不是 。
贪心选择性质 vs 最优子结构
动态规划:问题必须要有「最优子结构」性质。
贪心算法:问题必须要有「贪心选择」性质。所有子问题的最优解 都求出来了,然后我可以基于这些子问题的最优解推导出原问题的最优解 。一些局部最优 的选择策略,就能直接知道哪个子问题的解是最优的了,且这个局部最优解可以推导出原问题的最优解。此时此刻我就能知道,不需要等到所有子问题的解算出来才知道 。
所以贪心算法的效率一般都比较高,因为它不需要遍历完整的解空间。
2、例题实战
参考:55.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。true ;否则,返回 false 。
输入:nums = [2,3,1,1,4]true
注意题目说 nums[i] 表示可以跳跃的最大长度,不是固定长度。假设 nums[i] = 3,意味着你可以在索引 i 往前跳 1 步、2 步或 3 步。
我们先思考暴力穷举解法吧,如何穷举所有可能的跳跃路径?你心里的那棵多叉树画出来了没有?假设 N 为 nums 的长度,这道题相当于做 N 次选择,每次选择有 nums[i] 种选项,想要穷举所有的跳跃路径,就是一棵高度为 N 的多叉树,每个节点有 nums[i] 个子节点。
这个算法本质上还是穷举了所有可能的选择,可以走动态规划那一套流程进行优化,但是这里我们先不急,可以再仔细想想,这个问题有没有贪心选择性质?
这里面有个细节,比方说你现在站在 nums[i] = 3 的位置,你可以跳到 i+1, i+2, i+3 三个位置,此时你真的需要分别跳过去,然后递归求解子问题 dp(i+1), dp(i+2), dp(i+3),最后通过子问题的答案来决定 dp(i) 的结果吗?i+1, i+2, i+3 三个候选项,它们谁能走得最远,你就选谁,准没错。
i+1 能走到的最远距离是 i+1+nums[i+1]i+2 能走到的最远距离是 i+2+nums[i+2]i+3 能走到的最远距离是 i+3+nums[i+3]
这就是贪心选择 性质,通过局部最优解就能推导全局最优解 ,不需要等到递归计算出所有子问题的答案才能做选择 。
1 2 3 4 5 6 7 8 9 10 11 class Solution {public : bool canJump (vector<int >& nums) int farthest = 0 ; for (int i=0 ; i<=farest && i<nums.size (); i++) farthest = max (farthest, i+nums[i]); return farthest >= nums.size ()-1 ; } };
参考:45.跳跃游戏II
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:0 <= j <= nums[i]i + j < nnums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
输入: nums = [2,3,1,1,4]2
暴力穷举肯定也是可以做的,就类似上面的那道题,只不过修改一下 dp 数组的定义,返回值从 boolean 改成 int,表示最少需要跳跃的次数就行了。
1 2 3 4 5 6 7 int dp (int nums[], int p) if (p >= nums.length - 1 ) { return 0 ; }
动态规划做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : vector<int > memo; int jump (vector<int >& nums) int n = nums.size (); memo = vector <int >(n, n); return dp (nums, 0 ); } int dp (vector<int >& nums, int p) int n = nums.size (); if (p >= n - 1 ) { return 0 ; } if (memo[p] != n) { return memo[p]; } int steps = nums[p]; for (int i = 1 ; i <= steps; i++) { int subProblem = dp (nums, p + i); memo[p] = min (memo[p], subProblem + 1 ); } return memo[p]; } };
这个解法已经通过备忘录消除了冗余计算,时间复杂度是 递归深度 x 每次递归需要的时间复杂度,即 O ( N 2 ) O(N^2) O ( N 2 )
所以进一步的优化就只能是贪心算法了,我们要仔细思考是否存在贪心选择性质,是否能够通过局部最优解推导全局最优解,避免全量穷举所有的可能解。
和上面的题目是一样的优化思路:我们真的需要递归地计算出每一个子问题的结果,然后求最值吗?其实不需要。
上图这种情况,我们站在索引 0 的位置,可以向前跳 1,2 或 3 步,你说应该选择跳多少呢?
肯定是跳到索引 2 位置的,为什么?因为 2 的选择很多啊,你 3 能去的地方,我 2 都可以去。
这就是贪心选择性质,我们不需要真的递归穷举出所有选择的具体结果来比较求最值,而只需要每次选择那个最有潜力的局部最优解,最终就能得到全局最优解 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution {public : int jump (vector<int >& nums) int n = nums.size (); int end = 0 , farthest = 0 ; int steps = 0 ; for (int i=0 ; i<n-1 ; i++){ farthest = max (farthest, i+nums[i]); if (i == end){ steps++; end = farthest; } } return steps; } }; class Solution {public : int jump (vector<int >& nums) int n = nums.size (); if (n == 1 ) return 0 ; int steps = 0 ; int cur = 0 , best = 0 ; for (int i=0 ; i<=cur+nums[cur] && i<n; i++){ if (cur+nums[cur] >= n-1 ){ steps++; break ; } best = i+nums[i] > best+nums[best] ? i : best; if (i == cur+nums[cur]){ cur = best; steps++; } } return steps; } };
时间复杂度是 O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 )
3、贪心算法的解题步骤
贪心算法的关键在于问题是否具备贪心选择性质 ,所以只能具体问题具体分析,没办法抽象出一套固定的算法模板或者思维模式 ,判断一道题是否是贪心算法。
经验是,没必要刻意地识别一道题是否具备贪心选择性质 。你只需时刻记住,算法的本质是穷举 ,遇到任何题目都要先想暴力穷举 思路,穷举的过程中如果存在冗余计算 ,就用备忘录优化 掉。
如果提交结果还是超时 ,那就说明不需要穷举所有的解空间就能求出最优解,这种情况下肯定需要用到贪心算法 。你可以仔细观察题目,是否可以提前排除掉一些不合理的选择,是否可以直接 通过局部最优解推导全局最优解。
(十二) 分治算法
分治思想和分治算法不一样。
1、分治思想
广义的分治思想是一个宽泛的概念,本站教程中也经常称之为「分解问题的思路 」。
分治思想就是把一个问题分解成若干个子问题,然后分别解决这些子问题,最后合并子问题的解得到原问题的解,这种思想广泛存在于递归算法中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int fib (int n) if (n == 0 || n == 1 ) { return n; } return fib (n - 1 ) + fib (n - 2 ); } int count (TreeNode root) if (root == null) { return 0 ; } int leftCount = count (root.left); int rightCount = count (root.right); return leftCount + rightCount + 1 ; }
动态规划算法 属不属于分治思想?
前面讲过,递归算法只有两种思路,一种是遍历的思路,另一种是分解问题的思路(分治思想)。
「分治思想」占据了递归算法的半壁江山 ,那么当我们说「分治算法」的时候,具体是指什么呢?是不是可以说上面列举的这些递归算法都是「分治算法」呢?其实不是的。
2、分治算法
狭义的分治算法也是运用分治思想的递归算法,但它有一个特征,是上面列举的算法所不具备的:把问题分解后进行求解,相比于不分解直接求解,时间复杂度更低 。分治算法 」。
上面列举的算法,它们本身就只能分解求解,不存在「直接求解」的解法,所以只说它们运用了分治思想,不说它们是分治算法。
比如 桶排序算法 ,桶排序的思路是把待排序数组分成若干个桶,然后对每个桶分别进行插入排序,最后把所有有序桶合并,这样时间复杂度能降到 O ( n ) O(n) O ( n ) 插入排序 的复杂度是 O ( n 2 ) O(n^2) O ( n 2 ) O ( n ) O(n) O ( n )
那么这里面是什么道理,为什么分而治之的复杂度更低呢 ?如果把所有问题都分而治之,是不是都能得到更低的复杂度呢?
3、无效的分治
理论上讲,很多算法都可以用分解问题的思路改写成递归算法,但大部分情况下这种改写是无意义的。
求一个数组的和,这个算法的时间复杂度是 O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 )
1 2 3 4 5 6 7 int getSum (int [] nums) int sum = 0 ; for (int i = 0 ; i < nums.length; i++) { sum += nums[i]; } return sum; }
完全可以用分解问题的思路把这个问题改写成递归算法:
1 2 3 4 5 6 7 8 9 int getSum2 (int [] nums, int start) if (start == nums.length) { return 0 ; } return nums[start] + getSum2 (nums, start + 1 ); }
递归树的形态类似一条链表,高度为 O ( n ) O(n) O ( n ) start + 1,所以递归树退化成了链表。O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int getSum3 (int [] nums, int start, int end) if (start == end) { return nums[start]; } int mid = start + (end - start) / 2 ; int leftSum = getSum3 (nums, start, mid); int rightSum = getSum3 (nums, mid + 1 , end); return leftSum + rightSum; }
getSum2 算法的递归树退化成了链表,堆栈(树高)的空间复杂度是 O ( n ) O(n) O ( n ) getSum3 算法从中间二分,递归树就是一个较为平衡的二叉树,所以堆栈(树高)的空间复杂度是 O ( log n ) O(\log n) O ( log n ) O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n ) O ( 1 ) O(1) O ( 1 ) O ( n ) O(n) O ( n )
综上,这两种分治算法改写都属于无效的分治,没有降低时间复杂度,反而由于递归而增加了空间复杂度。O ( n ) O(n) O ( n ) O ( n ) O(n) O ( n )
分治的思想是广泛存在的 ,几乎所有算法都可以改写成递归分治的形式。
分治思想不等于高效 。不要听到 XX 算法就觉得高大上,很多时候,改写成分治解法并不能带来什么实际的好处,甚至可能增加空间复杂度,因为递归调用需要堆栈空间。
3、用二分的方式进行分治可以将递归树的深度从 O ( n ) O(n) O ( n ) O ( l o g n ) O(logn) O ( l o g n ) 。对于上面这个元素求和的例子,无论怎么分治都不如原解法高效,但可以看出二分的分治方式是确实有助于减少递归树的高度。
4、有效的分治
参考:23.合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
示例 1:lists = [[1,4,5],[1,3,4],[2,6]][1,1,2,3,4,4,5,6]
在 单链表双指针技巧汇总 中,我介绍的解法是利用 优先级队列 这种数据结构对链表节点进行动态排序,这种解法的时间复杂度是 O ( N log k ) O(N\log k) O ( N log k ) O ( k ) O(k) O ( k ) k 代表链表的条数,N 代表 k 条链表节点的总数,在本文中,我们不再依赖额外的数据结构,而是直接用分治算法解决这个问题,时间复杂度依然是 O ( N log k ) O(N\log k) O ( N log k )
先看简单的。21.合并 2 个升序列表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
输入:l1 = [1,2,4], l2 = [1,3,4][1,1,2,3,4,4]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : ListNode* mergeTwoLists (ListNode* l1, ListNode* l2) { ListNode dummy (-1 ) , *p = &dummy; ListNode *p1 = l1, *p2 = l2; while (p1 != nullptr && p2 != nullptr ) { if (p1->val > p2->val) { p->next = p2; p2 = p2->next; } else { p->next = p1; p1 = p1->next; } p = p->next; } if (p1 != nullptr ) { p->next = p1; } if (p2 != nullptr ) { p->next = p2; } return dummy.next; } };
时间复杂度 O ( l 1 + l 2 ) O(l1+l2) O ( l 1 + l 2 )
下面我们来思考如何合并 k 个有序链表。mergeTwoLists 函数把 k 个链表两两合并,都合并到第一个链表上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ListNode mergeKLists (ListNode[] lists) { if (lists.length == 0 ) { return null; } ListNode l0 = lists[0 ]; for (int i = 1 ; i < lists.length; i++) { l0 = mergeTwoLists (l0, lists[i]); } return l0; } ListNode mergeTwoLists (ListNode l1, ListNode l2) { }
但是,链表 l 0 l_0 l 0 l 1 l_1 l 1 k−1 次,l 2 l_2 l 2 k−2 次,以此类推,最后一条链表 l k − 1 l_{k−1} l k − 1 1 次。越靠前的链表被重复遍历的次数越多,这就是这个算法低效的原因 。我们只要减少这种重复,就能提高算法的效率。
1 2 3 4 5 6 7 8 9 10 11 ListNode mergeKLists2 (ListNode[] lists, int start) { if (start == lists.length - 1 ) { return lists[start]; } ListNode subProblem = mergeKLists2 (lists, start + 1 ); return mergeTwoLists (lists[start], subProblem); }
这就和前面的 getSum2 很像。递归树的形态类似一个单链表,高度为 O ( k ) O(k) O ( k ) 重复的次数取决于树高 ,上面这个算法的递归树很不平衡,导致递归树退化成链表,树高变为 O ( k ) O(k) O ( k ) 如果能让递归树尽可能地平衡,就能减小树高,进而减少链表的重复遍历次数,提高算法的效率 。getSum3 函数的思路,把链表从中间分成两部分,分别递归合并为有两个序链表,最后再将这两部分合并成一个有序链表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ListNode mergeKLists3 (ListNode[] lists, int start, int end) { if (start == end) { return lists[start]; } int mid = start + (end - start) / 2 ; ListNode left = mergeKLists3 (lists, start, mid); ListNode right = mergeKLists3 (lists, mid + 1 , end); return mergeTwoLists (left, right); }
该算法的时间复杂度相当于是把 k 条链表分别遍历 O ( log k ) O(\log k) O ( log k ) k 条链表的元素总数是 N N N O ( N log k ) O(N\log k) O ( N log k ) O ( log k ) O(\log k) O ( log k ) O ( k ) O(k) O ( k )
5、总结
分治思想在递归算法中是广泛存在的,甚至一些非递归算法,都可以强行改写成分治递归的形式,但并不是所有算法都能用分治思想提升效率。
把递归算法抽象成递归树,如果递归树节点的时间复杂度和树的深度相关,那么使用分治思想对问题进行二分,就可以使递归树尽可能平衡,进而优化总的时间复杂度 。反之,如果递归树节点的时间复杂度和树的深度无关,那么使用分治思想就没有意义,反而可能引入额外的空间复杂度。
getSum 函数即便改为递归形式,每个递归节点做的事情无非就是一些加减运算,所以递归节点的时间复杂度总是 O ( 1 ) O(1) O ( 1 ) 而 mergeKLists 函数中,每个递归节点都需要合并两个链表,这两个链表是子节点返回的,其长度和递归树的高度相关,所以使用分治思想可以优化时间复杂度。
(十三) 时空复杂度分析
本文会篇幅较长,会涵盖如下几点:
1、利用时间复杂度反推解题思路,减少试错时间。
1、复杂度反推解题
你应该在开始写代码之前就留意题目给的数据规模 ,因为复杂度分析可以避免你在错误的思路上浪费时间,有时候它甚至可以直接告诉你这道题用什么算法。举例来说吧,比如一个题目给你输入一个数组,其长度能够达到 1 0 6 10^6 1 0 6 O ( N 2 ) O(N^2) O ( N 2 ) O ( N log N ) O(N\log N) O ( N log N ) O ( N ) O(N) O ( N ) O ( N 2 ) O(N^2) O ( N 2 ) 1 0 1 2 10^12 1 0 1 2 O ( N log N ) O(N\log N) O ( N log N ) O ( N ) O(N) O ( N ) 对数组进行排序处理、前缀和、双指针、一维 dp 等等 ,从这些思路切入就比较靠谱。嵌套 for 循环、二维 dp、回溯算法 这些思路,基本可以直接排除掉了。
举个更直接的例子,如果你发现题目给的数据规模很小,比如数组长度 N N N 20 20 20 暴力穷举 算法。最优解就是指数/阶乘级别 的复杂度。你放心用回溯算法 招呼它就行了,不用想别的算法了。
2、编码失误导致异常
这些错误会产生预期之外的时间消耗,拖慢你的算法运行,甚至导致超时。
编码失误
原因
解决办法
使用了标准输出
标准输出属于 I/O 操作,会很大程度上拖慢你的算法代码运行
输出语句注释掉
错误地传参数
尤其是函数是递归函数时,错误地传值几乎必然导致超时或超内存
传引用
接口对象的底层实现不明
Java 会有,C++不用管
自己创建
3、Big O 表示法
Big O 记号的数学定义:
O ( g ( n ) ) = { f ( n ) : 存在正常量 c 和 n 0 ,使得对所有 n ≥ n 0 ,有 0 ≤ f ( n ) ≤ c ∗ g ( n ) } O(g(n)) = \{ f(n): 存在正常量 c 和 n_0,使得对所有 n \geq n_0,有 0 \leq f(n) \leq c*g(n) \}
O ( g ( n )) = { f ( n ) : 存在正常量 c 和 n 0 ,使得对所有 n ≥ n 0 ,有 0 ≤ f ( n ) ≤ c ∗ g ( n )}
常用的这个符号 O O O 函数的集合 ,比如 O ( n 2 ) O(n^2) O ( n 2 ) g ( n ) = n 2 g(n) = n^2 g ( n ) = n 2 派生出来的一个函数集合 。
只保留增长速率最快的项,其他的项可以省略。
Big O 记号表示复杂度的「上界」。
4、算法分析
数据结构:一般看平均时间复杂度,而不是最坏时间复杂度。
非递归算法:正常计算即可。
递归算法:
递归算法的时间复杂度 = 递归树的节点个数 x 每个节点的时间复杂度递归算法的空间复杂度 = 递归树的高度 + 算法申请的存储空间
5、最后总结
复杂度分析是一种技术工具,我们应该灵活运用这个工具,辅助我们又快又好地写出解法代码。
Big O 标记代表一个函数的集合,用它表示时空复杂度时代表一个上界,所以如果你和别人算的复杂度不一样,可能你们都是对的,只是精确度不同罢了。
时间复杂度的分析不难,关键是你要透彻理解算法到底干了什么事。非递归算法中嵌套循环的复杂度依然可能是线性的;数据结构 API 需要用平均时间复杂度衡量性能;递归算法本质是遍历递归树,时间复杂度取决于递归树中节点的个数(递归次数)和每个节点的复杂度(递归函数本身的复杂度)。
第一章、经典数据结构算法
(一) 链表
参考题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : ListNode* deleteDuplicates (ListNode* head) { ListNode *dummy1 = new ListNode (101 ); ListNode *dummy2 = new ListNode (); ListNode *p1 = dummy1, *p2 = dummy2; ListNode *p = head; while (p != NULL ){ if ((p->next != NULL && p->val == p->next->val) || (p->val == p1->val)){ p1->next = p; p1 = p1->next; p = p->next; p1->next = NULL ; } else { p2->next = p; p2 = p2->next; p = p->next; p2->next = NULL ; } } return dummy2->next; } };
可以先做附:204.计算质数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public : int countPrimes (int n) vector<bool > F (n, true ) ; for (int i=2 ; i*i<n; i++) if (F[i]){ for (int j=i*i; j<n; j+=i) F[j] = false ; } int cnt = 0 ; for (int i=2 ; i<n; i++) if (F[i]) cnt++; return cnt; } };
本题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : int nthUglyNumber (int n) vector<int > ugly (n) ; int p2 = 0 , p3 = 0 , p5 = 0 ; int r2 = 1 , r3 = 1 , r5 = 1 ; int p = 0 ; while (p < n){ int minR = min ({r2, r3, r5}); ugly[p] = minR; p++; if (minR == r2){ r2 = ugly[p2] * 2 ; p2++; } if (minR == r3){ r3 = ugly[p3] * 3 ; p3++; } if (minR == r5){ r5 = ugly[p5] * 5 ; p5++; } } return ugly[n-1 ]; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : int kthSmallest (vector<vector<int >>& matrix, int k) int m = matrix.size (), n = matrix[0 ].size (); auto cmp = [](const vector<int >& a, const vector<int >& b){ return a[0 ] > b[0 ]; }; priority_queue<vector<int >, vector<vector<int >>, decltype (cmp)> minHeap; for (int i=0 ; i<m; i++) minHeap.push ({matrix[i][0 ], i, 0 }); int ans; while (k>0 ){ vector<int > cur = minHeap.top (); minHeap.pop (); ans = cur[0 ]; int i = cur[1 ], j = cur[2 ]; if (j+1 < matrix[i].size ()) minHeap.push ({matrix[i][j+1 ], i, j+1 }); k--; } return ans; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : vector<vector<int >> kSmallestPairs (vector<int >& nums1, vector<int >& nums2, int k) { int n1 = nums1.size (), n2 = nums2.size (); auto cmp = [](const vector<int >& a, const vector<int >& b){ return a[0 ] > b[0 ]; }; priority_queue<vector<int >, vector<vector<int >>, decltype (cmp)> minHeap; for (int i=0 ; i<n1; i++) minHeap.push ({nums1[i]+nums2[0 ], i, 0 }); vector<vector<int >> ans; while (k > 0 ){ vector<int > cur = minHeap.top (); minHeap.pop (); int i = cur[1 ], j = cur[2 ]; ans.push_back ({nums1[i], nums2[j]}); if (j+1 < nums2.size ()) minHeap.push ({nums1[i]+nums2[j+1 ], i, j+1 }); k--; } return ans; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) { ListNode* dummy = new ListNode (); ListNode *p1 = l1, *p2 = l2; ListNode* p = dummy; int carry = 0 ; while (p1 || p2){ int res = carry; if (p1) res += p1->val, p1 = p1->next; if (p2) res += p2->val, p2 = p2->next; ListNode *cur = new ListNode (res % 10 ); p->next = cur; p = p->next; carry = res / 10 ; } if (carry){ ListNode *cur = new ListNode (carry); cur->next = NULL ; p->next = cur; } return dummy->next; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution {public : ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) { stack<int > stk1; ListNode *p1 = l1; while (p1){ stk1.push (p1->val); p1 = p1->next; } stack<int > stk2; ListNode *p2 = l2; while (p2){ stk2.push (p2->val); p2 = p2->next; } stack<int > ans; int carry = 0 ; while (!stk1.empty () || !stk2.empty ()){ int res = carry; if (!stk1.empty ()){ int a = stk1.top (); stk1.pop (); res += a; } if (!stk2.empty ()){ int b = stk2.top (); stk2.pop (); res += b; } ans.push (res % 10 ); carry = res / 10 ; } if (carry) ans.push (carry); ListNode *dummy = new ListNode (); ListNode *p = dummy; while (!ans.empty ()){ ListNode *r = new ListNode (ans.top ()); r->next = NULL ; ans.pop (); p->next = r; p = p->next; } return dummy->next; } };
7、方法:花式反转链表
反转整个单链表206.反转链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : ListNode* reverseList (ListNode* head) { if (head == nullptr || head->next == nullptr ) { return head; } ListNode *pre, *cur, *nxt; pre = nullptr ; cur = head; nxt = head->next; while (cur != nullptr ) { cur->next = pre; pre = cur; cur = nxt; if (nxt != nullptr ) { nxt = nxt->next; } } return pre; } };
reverseList(1->2->3->4) = reverseList(2->3->4) -> 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public : ListNode* reverseList (ListNode* head) { if (head == NULL || head->next == NULL ) return head; ListNode *second = head->next; ListNode *last = reverseList (second); second->next = head; head->next = NULL ; return last; } };
值得一提的是,递归操作链表并不高效。O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 ) O ( N ) O(N) O ( N )
反转链表前 N 个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ListNode* reverseN (ListNode* head, int n) { if (head == nullptr || head->next == nullptr ) { return head; } ListNode *pre, *cur, *nxt; pre = nullptr ; cur = head; nxt = head->next; while (n > 0 ) { cur->next = pre; pre = cur; cur = nxt; if (nxt != nullptr ) { nxt = nxt->next; } n--; } head->next = cur; return pre; }
递归写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode* successor = nullptr ; ListNode* reverseN (ListNode* head, int n) { if (n == 1 ) { successor = head->next; return head; } ListNode* last = reverseN (head->next, n - 1 ); head->next->next = head; head->next = successor; return last; }
反转链表的一部分92. 反转链表 II
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public : ListNode* reverseBetween (ListNode* head, int m, int n) { if (m == 1 ) { return reverseN (head, n); } ListNode *pre = head; for (int i = 1 ; i < m - 1 ; i++) { pre = pre->next; } pre->next = reverseN (pre->next, n - m + 1 ); return head; } ListNode* reverseN (ListNode* head, int n) { if (head == nullptr || head->next == nullptr ) { return head; } ListNode *pre, *cur, *nxt; pre = nullptr ; cur = head; nxt = head->next; while (n > 0 ) { cur->next = pre; pre = cur; cur = nxt; if (nxt != nullptr ) { nxt = nxt->next; } n--; } head->next = cur; return pre; } };
递归写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : ListNode* successor = nullptr ; ListNode* reverseN (ListNode* head, int n) { if (n == 1 ) { successor = head->next; return head; } ListNode* last = reverseN (head->next, n - 1 ); head->next->next = head; head->next = successor; return last; } ListNode* reverseBetween (ListNode* head, int m, int n) { if (m == 1 ) { return reverseN (head, n); } head->next = reverseBetween (head->next, m - 1 , n - 1 ); return head; } };
K 个一组反转链表25. K 个一组翻转链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution {public : ListNode* reverseKGroup (ListNode* head, int k) { if (head == nullptr ) return nullptr ; ListNode *a, *b; a = b = head; for (int i = 0 ; i < k; i++) { if (b == nullptr ) return head; b = b->next; } ListNode *newHead = reverseN (a, k); a->next = reverseKGroup (b, k); return newHead; } ListNode* reverseN (ListNode* head, int n) { if (head == nullptr || head->next == nullptr ) { return head; } ListNode *pre, *cur, *nxt; pre = nullptr ; cur = head; nxt = head->next; while (n > 0 ) { cur->next = pre; pre = cur; cur = nxt; if (nxt != nullptr ) { nxt = nxt->next; } n--; } head->next = cur; return pre; } };
8、方法:回文链表判断
参考:234.回文链表
寻找 回文串的核心思想是从中心向两端扩展判断 回文串,双指针技巧从两端向中间逼近即可那么对于回文链表,怎么办?
思考做法
链表兼具递归结构,树结构不过是链表的衍生 。那么,链表其实也可以有前序遍历和后序遍历 ,借助二叉树后序遍历的思路,不需要显式反转原始链表也可以倒序遍历链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void traverse (TreeNode* root) traverse (root->left); traverse (root->right); } void traverse (ListNode* head) traverse (head->next); }
比如说:
1 2 3 4 5 6 7 void traverse (ListNode* head) if (head == NULL ) return ; traverse (head->next); cout << head->val << endl; }
本题做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : ListNode* left; ListNode* right; bool res = true ; bool isPalindrome (ListNode* head) left = head; traverse (head); return res; } void traverse (ListNode* right) if (right == nullptr ) { return ; } traverse (right->next); if (left->val != right->val) { res = false ; } left = left->next; } };
这么做的核心逻辑是什么呢?实际上就是把链表节点放入一个栈,然后再拿出来,这时候元素顺序就是反的 ,只不过我们利用的是递归函数的堆栈而已。
优化空间复杂度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : bool isPalindrome (ListNode* head) ListNode* slow, *fast; slow = fast = head; while (fast != nullptr && fast->next != nullptr ) { slow = slow->next; fast = fast->next->next; } if (fast != nullptr ) slow = slow->next; ListNode* left = head; ListNode* right = reverse (slow); while (right != nullptr ) { if (left->val != right->val) return false ; left = left->next; right = right->next; } return true ; } ListNode* reverse (ListNode* head) { ListNode* pre = nullptr , *cur = head; while (cur != nullptr ) { ListNode* next = cur->next; cur->next = pre; pre = cur; cur = next; } return pre; } };
这种解法虽然高效,但破坏了输入链表的原始结构,能不能避免这个瑕疵呢?
其实这个问题很好解决,关键在于得到p, q这两个指针位置。只要在函数 return 之前加一段代码即可恢复原先链表顺序:p->next = reverse(q);
(二) 数组
1、双指针的七道题
有序数组去重,原地修改 :快慢指针移除val元素,原地修改 :快慢指针滑动窗口,背下框架
二分查找:左右指针
两数之和 :左右指针反转数组 :左右指针最长回文串判断 :核心子函数是中心向两端扩散的左右指针
只要数组有序,就应该想到双指针技巧。
全部代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 T1: class Solution {public : ListNode* deleteDuplicates (ListNode* head) { if (head == NULL ) return NULL ; ListNode *slow = head, *fast = head; while (fast != NULL ){ if (fast->val != slow->val){ slow->next = fast; slow = slow->next; } fast = fast->next; } slow->next = NULL ; return head; } }; T2: class Solution {public : int removeElement (vector<int >& nums, int val) int fast = 0 , slow = 0 ; while (fast < nums.size ()){ if (nums[fast] != val) nums[slow++] = nums[fast]; fast++; } return slow; } }; T5: class Solution {public : vector<int > twoSum (vector<int >& numbers, int target) { int left = 0 , right = numbers.size ()-1 ; while (left < right){ int sum = numbers[left] + numbers[right]; if (sum == target) return vector<int >{left+1 , right+1 }; else if (sum > target) right--; else left++; } return vector<int >{-1 , -1 }; } }; T6: class Solution {public : void reverseString (vector<char >& s) int left = 0 , right = s.size ()-1 ; while (left < right){ char t = s[left]; s[left] = s[right]; s[right] = t; left++, right--; } } }; T7: class Solution {public : string palindrome (string& s, int l, int r) { while (l>=0 && r<s.size () && s[l]==s[r]) l--, r++; return s.substr (l+1 , r-l-1 ); } string longestPalindrome (string s) { string ans = "" ; for (int i=0 ; i<s.size (); i++){ string s1 = palindrome (s, i, i); string s2 = palindrome (s, i, i+1 ); ans = s1.size () > ans.size () ? s1 : ans; ans = s2.size () > ans.size () ? s2 : ans; } return ans; } };
2、二维数组的花式遍历
反转字符串的单词 旋转数组 矩阵螺旋遍历 生成螺旋矩阵
全部代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 T1: class Solution {public : string reverseWords (string s) { reverse (s.begin (), s.end ()); string ans; stack<char > STK; for (char c : s){ if (c == ' ' ){ if (!STK.empty ()){ while (!STK.empty ()){ ans += STK.top (); STK.pop (); } ans += ' ' ; } } else { STK.push (c); } } while (!STK.empty ()){ ans += STK.top (); STK.pop (); } if (ans[ans.size ()-1 ] == ' ' ) ans = ans.substr (0 , ans.size ()-1 ); return ans; } }; T2: class Solution {public : void rotate (vector<vector<int >>& matrix) int n = matrix.size (); for (int i=0 ; i<n; i++) for (int j=i; j<n; j++) swap (matrix[i][j], matrix[j][i]); for (auto &row : matrix) reverse (row.begin (), row.end ()); } }; T3: class Solution {private : vector<int > ans; public : vector<int > spiralOrder (vector<vector<int >>& matrix) { int m = matrix.size (), n = matrix[0 ].size (); int direct = 0 ; int minR = 0 , minC = 0 , maxR = m-1 , maxC = n-1 ; int i = 0 , j = 0 ; while (ans.size () < m*n){ ans.push_back (matrix[i][j]); if (direct == 0 ){ if (j < maxC) j++; else { direct = (direct+1 ) % 4 ; minR++; i++; } } else if (direct == 1 ){ if (i < maxR) i++; else { direct = (direct+1 ) % 4 ; maxC--; j--; } } else if (direct == 2 ){ if (j > minC) j--; else { direct = (direct+1 ) % 4 ; maxR--; i--; } } else if (direct == 3 ){ if (i > minR) i--; else { direct = (direct+1 ) % 4 ; minC++; j++; } } } return ans; } }; T4: class Solution {public : vector<vector<int >> generateMatrix (int n) { vector<vector<int >> M (n, vector <int >(n)); int top = 0 , bottom = n-1 ; int left = 0 , right = n-1 ; int num = 1 ; while (num <= n*n){ if (top <= bottom){ for (int i=left; i<=right; i++){ M[top][i] = num; num++; } top++; } if (left <= right){ for (int i=top; i<=bottom; i++){ M[i][right] = num; num++; } right--; } if (top <= bottom){ for (int i=right; i>=left; i--){ M[bottom][i] = num; num++; } bottom--; } if (left <= right){ for (int i=bottom; i>=top; i--){ M[i][left] = num; num++; } left++; } } return M; } };
3、团灭 nSum 问题
这类 nSum 问题就是给你输入一个数组 nums 和一个目标和 target,让你从 nums 选择 n 个数,使得这些数字之和为 target。
2Sum
先排序(若无序)
再左右指针法nums 中可能有多对儿元素之和都等于 target,请你的算法返回所有和为 target 的元素对儿,其中不能出现重复。
3Sum
排序
固定第一个数(注意别重复)
第二三个数字,调用 2Sum 完成 target-num1
4Sum
排序
固定第一个数字(注意别重复)
第二三四个数字,调用 3Sum 完成 target-num1
100Sum? 仍然用4Sum 举例
最外层排序,
然后调用 nSum,执行如下:
base case 是 2Sum
其余,固定一个数字,求 n-1 Sum
问:如果就是希望返回原下标,而阻碍我们第一步排序,怎么办?
问:这不就是子集问题吗?直接回溯法不行吗?
全部代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 T1: class Solution {public : vector<int > twoSum (vector<int >& numbers, int target) { sort (numbers.begin (), numbers.end ()); int l = 0 , r = numbers.size () - 1 ; while (l < r){ int sum = numbers[l] + numbers[r]; if (sum == target) return vector<int >{l+1 , r+1 }; else if (sum > target) r--; else if (sum < target) l++; } return vector<int >{-1 , -1 }; } }; T1-泛化题型: vector<vector<int >> twoSumTarget (vector<int >& nums, int target) { sort (nums.begin (), nums.end ()); int lo = 0 , hi = nums.size () - 1 ; vector<vector<int >> res; while (lo < hi) { int sum = nums[lo] + nums[hi]; int left = nums[lo], right = nums[hi]; if (sum < target) { while (lo < hi && nums[lo] == left) lo++; } else if (sum > target) { while (lo < hi && nums[hi] == right) hi--; } else { res.push_back ({left, right}); while (lo < hi && nums[lo] == left) lo++; while (lo < hi && nums[hi] == right) hi--; } } return res; } T2: class Solution {public : vector<vector<int >> threeSum (vector<int >& nums) { return threeSum (nums, 0 ); } vector<vector<int >> threeSum (vector<int >& nums, int target){ sort (nums.begin (), nums.end ()); int n = nums.size (); vector<vector<int >> ans; for (int i=0 ; i<n; i++){ vector<vector<int >> tuples = twoSum (nums, i+1 , target-nums[i]); for (auto &tuple : tuples){ tuple.insert (tuple.begin (), nums[i]); ans.push_back (tuple); } while (i+1 <n && nums[i]==nums[i+1 ]) i++; } return ans; } private : vector<vector<int >> twoSum (vector<int > &nums, int start, int target){ int n = nums.size (); vector<vector<int >> ans; int l = start, r = n-1 ; while (l < r){ int sum = nums[l] + nums[r]; int lnum = nums[l], rnum = nums[r]; if (sum == target){ ans.push_back ({lnum, rnum}); while (l<r && nums[l]==lnum) l++; while (l<r && nums[r]==rnum) r--; } else if (sum > target) r--; else if (sum < target) l++; } return ans; } }; T3: class Solution {public : vector<vector<int >> fourSum (vector<int >& nums, int target) { sort (nums.begin (), nums.end ()); int n = nums.size (); vector<vector<int >> ans; for (int i=0 ; i<n; i++){ auto tuples = threeSum (nums, i+1 , target-nums[i]); for (auto &tuple : tuples){ tuple.insert (tuple.begin (), nums[i]); ans.push_back (tuple); } while (i+1 <n && nums[i]==nums[i+1 ]) i++; } return ans; } private : vector<vector<int >> threeSum (vector<int >& nums, int start, long target){ int n = nums.size (); vector<vector<int >> ans; for (int i=start; i<n; i++){ auto tuples = twoSum (nums, i+1 , target-nums[i]); for (auto &tuple : tuples){ tuple.insert (tuple.begin (), nums[i]); ans.push_back (tuple); } while (i+1 <n && nums[i]==nums[i+1 ]) i++; } return ans; } vector<vector<int >> twoSum (vector<int >& nums, int start, long target){ int n = nums.size (); vector<vector<int >> ans; int l = start, r = n-1 ; while (l < r){ int sum = nums[l] + nums[r]; int lnum = nums[l], rnum = nums[r]; if (sum > target) r--; else if (sum < target) l++; else { ans.push_back ({lnum, rnum}); while (l<r && nums[l]==lnum) l++; while (l<r && nums[r]==rnum) r--; } } return ans; } }; T4:(这里仍然用 4 Sum 举例) class Solution {public : vector<vector<int >> fourSum (vector<int >& nums, int target) { sort (nums.begin (), nums.end ()); return nSumTarget (nums, 4 , 0 , target); } private : vector<vector<int >> nSumTarget (vector<int >& nums, int n, int start, long target) { int sz = nums.size (); vector<vector<int >> res; if (n < 2 || sz < n) return res; if (n == 2 ) { int lo = start, hi = sz - 1 ; while (lo < hi) { int sum = nums[lo] + nums[hi]; int left = nums[lo], right = nums[hi]; if (sum < target) { while (lo < hi && nums[lo] == left) lo++; } else if (sum > target) { while (lo < hi && nums[hi] == right) hi--; } else { res.push_back ({left, right}); while (lo < hi && nums[lo] == left) lo++; while (lo < hi && nums[hi] == right) hi--; } } } else { for (int i = start; i < sz; i++) { vector<vector<int >> sub = nSumTarget (nums, n - 1 , i + 1 , target - nums[i]); for (vector<int >& arr : sub) { arr.push_back (nums[i]); res.push_back (arr); } while (i < sz - 1 && nums[i] == nums[i + 1 ]) i++; } } return res; } };
4、前缀和数组
一维数组:区域和检索 二维数组:区域和检索
注意:
第一个局限性:使用前缀和技巧的前提是原数组 nums 不会发生变化。
第二个局限性:前缀和技巧只适用于存在逆运算的场景。(如求最大值,后续会用线段树来解决)
全部代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 T1: class NumArray {private : vector<int > preSum; public : NumArray (vector<int >& nums) { int n = nums.size (); preSum.resize (n+1 ); preSum[0 ] = 0 ; for (int i=0 ; i<n; i++) preSum[i+1 ] = preSum[i] + nums[i]; } int sumRange (int left, int right) return preSum[right+1 ] - preSum[left]; } }; T2: class NumMatrix {private : vector<vector<int >> preSum; public : NumMatrix (vector<vector<int >>& matrix) { int m = matrix.size (), n = matrix[0 ].size (); preSum.resize (m+1 , vector <int >(n+1 , 0 )); for (int i=0 ; i<m; i++) for (int j=0 ; j<n; j++) preSum[i+1 ][j+1 ] = preSum[i][j+1 ] + preSum[i+1 ][j] - preSum[i][j] + matrix[i][j]; } int sumRegion (int row1, int col1, int row2, int col2) int Ai = row1, Aj = col1; int Bi = row2+1 , Bj = col2+1 ; return preSum[Bi][Bj] + preSum[Ai][Aj] - preSum[Ai][Bj] - preSum[Bi][Aj]; } };
5、差分数组
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减。
区间加法 航班预定统计 拼车
问题:
第一个问题,想要使用查分数组技巧,必须创建一个长度和区间长度一样的差分数组 diff。
第二个问题,前缀和技巧可以快速进行区间查询,查分数组可以快速进行区间增减。能不能把他俩结合起来,既可以快速进行区间增减,又可以随时进行区间查询?线段树 这种数据结构,它可以在 O ( log N ) O(\log N) O ( log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 T1: class Solution {public : vector<int > getModifiedArray (int length, vector<vector<int >>& updates) { vector<int > nums (length, 0 ) ; Difference df (nums) ; for (const auto & update : updates) { int i = update[0 ]; int j = update[1 ]; int val = update[2 ]; df.increment (i, j, val); } return df.result (); } class Difference { vector<int > diff; public : Difference (const vector<int >& nums) { assert (!nums.empty ()); diff.resize (nums.size ()); diff[0 ] = nums[0 ]; for (size_t i = 1 ; i < nums.size (); ++i) { diff[i] = nums[i] - nums[i - 1 ]; } } void increment (int i, int j, int val) diff[i] += val; if (j + 1 < diff.size ()) { diff[j + 1 ] -= val; } } vector<int > result () { vector<int > res (diff.size()) ; res[0 ] = diff[0 ]; for (size_t i = 1 ; i < diff.size (); ++i) { res[i] = res[i - 1 ] + diff[i]; } return res; } }; }; T2: class Solution {public : vector<int > corpFlightBookings (vector<vector<int >>& bookings, int n) { vector<int > nums (n, 0 ) ; Difference df (nums) ; for (auto booking : bookings) df.add (booking[0 ]-1 , booking[1 ]-1 , booking[2 ]); return df.result (); } private : class Difference { vector<int > diff; public : Difference (const vector<int > &nums){ diff.resize (nums.size ()); diff[0 ] = nums[0 ]; for (int i=1 ; i<nums.size (); i++) diff[i] = nums[i] - nums[i-1 ]; } void add (int i, int j, int val) diff[i] += val; if (j+1 < diff.size ()) diff[j+1 ] -= val; } vector<int > result () { vector<int > ans (diff.size(), 0 ) ; ans[0 ] = diff[0 ]; for (int i=1 ; i<diff.size (); i++) ans[i] = ans[i-1 ] + diff[i]; return ans; } }; }; T3: class Solution {public : bool carPooling (vector<vector<int >>& trips, int capacity) vector<int > nums (1001 , 0 ) ; Difference df (nums) ; for (auto &trip : trips) df.add (trip[1 ], trip[2 ]-1 , trip[0 ]); auto res = df.result (); for (int i=0 ; i<res.size (); i++) if (res[i] > capacity) return false ; return true ; } private : class Difference { vector<int > diff; public : Difference (const vector<int > &nums){ diff.resize (nums.size ()); diff[0 ] = nums[0 ]; for (int i=1 ; i<nums.size (); i++) diff[i] = nums[i] - nums[i-1 ]; } void add (int i, int j, int val) diff[i] += val; if (j+1 < diff.size ()) diff[j+1 ] -= val; } vector<int > result () { vector<int > ans (diff.size()) ; ans[0 ] = diff[0 ]; for (int i=1 ; i<diff.size (); i++) ans[i] = ans[i-1 ] + diff[i]; return ans; } }; };
6、滑动窗口延伸:Rabin Karp 字符匹配算法
下面是滑动窗口的框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void slidingWindow (string s) auto window = ... int left = 0 , right = 0 ; while (right < s.size ()) { char c = s[right]; window.add (c); right++; ... printf ("window: [%d, %d)\n" , left, right); while (window needs shrink) { char d = s[left]; window.remove (d); left++; ... } } }
先看,你是如何:
在最低位添加一个数字
在最高位删除一个数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int number = 8264 ;int R = 10 ;int appendVal = 3 ;number = R * number + appendVal; int number = 8264 ;int R = 10 ;int removeVal = 8 ;int L = 4 ;number = number - removeVal * Math.pow (R, L-1 );
寻找重复子序列 Rabin-Karp 字符串匹配 O ( N ) O(N) O ( N )
进制采用 R = 256(因为编码字符 ASCII 共 256 个)
长度看模式串的长度 L = pat.size()
为解决数字过大,采用取余(模一个大素数1658598167)
为解决哈希冲突,要进一步直接对比字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 T1-1 : class Solution {public : vector<string> findRepeatedDnaSequences (string s) { unordered_set<string> seen; unordered_set<string> ans; for (int i=0 ; i+9 <s.size (); i++){ string ts = s.substr (i, 10 ); if (seen.find (ts) != seen.end ()) ans.insert (ts); else seen.insert (ts); } return vector <string>(ans.begin (), ans.end ()); } }; T1-2 : class Solution {public : vector<string> findRepeatedDnaSequences (string s) { vector<int > nums = s2Nums (s); unordered_set<int > seen; unordered_set<string> ans; int R = 4 , L = 10 ; int RL = pow (R, L-1 ); int l = 0 , r = 0 ; int cur = 0 ; while (r < nums.size ()){ cur = cur*R + nums[r]; r++; if (r-l == L){ if (seen.find (cur) != seen.end ()) ans.insert (s.substr (l, L)); else seen.insert (cur); cur = cur - nums[l]*RL; l++; } } return vector <string>(ans.begin (), ans.end ()); } vector<int > s2Nums (const string &s) { vector<int > nums (s.size()) ; for (int i=0 ; i<s.size (); i++){ switch (s[i]){ case 'A' : nums[i] = 0 ; break ; case 'C' : nums[i] = 1 ; break ; case 'G' : nums[i] = 2 ; break ; case 'T' : nums[i] = 3 ; break ; } } return nums; } }; T2: int rabinKarp (string txt, string pat) int L = pat.length (); int R = 256 ; long Q = 1658598167 ; long RL = 1 ; for (int i = 1 ; i <= L - 1 ; i++) { RL = (RL * R) % Q; } long patHash = 0 ; for (int i = 0 ; i < pat.length (); i++) { patHash = (R * patHash + pat.at (i)) % Q; } long windowHash = 0 ; int left = 0 , right = 0 ; while (right < txt.length ()) { windowHash = ((R * windowHash) % Q + txt.at (right)) % Q; right++; if (right - left == L) { if (windowHash == patHash) { if (pat.compare (txt.substr (left, L)) == 0 ) { return left; } } windowHash = (windowHash - (txt.at (left) * RL) % Q + Q) % Q; left++; } } return -1 ; }
7、二分搜索思维
注意:下面都采用 ”左闭右开 “ 的区间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int left_bound (vector<int >& nums, int target) if (nums.size () == 0 ) return -1 ; int left = 0 , right = nums.size (); while (left < right) { int mid = left + (right - left) / 2 ; if (nums[mid] == target) { right = mid; } else if (nums[mid] < target) { left = mid + 1 ; } else if (nums[mid] > target) { right = mid; } } return left; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int right_bound (vector<int >& nums, int target) if (nums.size () == 0 ) return -1 ; int left = 0 , right = nums.size (); while (left < right) { int mid = left + (right - left) / 2 ; if (nums[mid] == target) { left = mid + 1 ; } else if (nums[mid] < target) { left = mid + 1 ; } else if (nums[mid] > target) { right = mid; } } return left - 1 ; }
下面看如何把二分搜索进行泛化:x,一个关于 x 的函数 f(x),以及一个目标值 target。同时,x, f(x), target 还要满足以下条件:
f(x) 必须是在 x 上的单调函数(单调增单调减都可以)。题目是让你计算满足约束条件 f(x) == target 时的 x 的值。int f(int x, vector<int>& nums) { return nums[x]; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int f (int x, int nums[]) return nums[x]; } int left_bound (int nums[], int length, int target) if (length == 0 ) return -1 ; int left = 0 , right = length; while (left < right) { int mid = left + (right - left) / 2 ; if (f (mid, nums) == target) { right = mid; } else if (f (mid, nums) < target) { left = mid + 1 ; } else if (f (mid, nums) > target) { right = mid; } } return left; }
下面就是做题:
875. 爱吃香蕉的珂珂
抽象出 y = f(k) 表示以速度 k 吃所需的总时间,注意 f 单调递减。
二分查找出左边界即可。
1011. 在 D 天内送达包裹的能力
抽象出 y = f(cap) 表示运载能力 cap 下的所需天数,注意 f 单调递减。
二分查找左边界。
410. 分割数组的最大值
抽象出 y = f(sum) 表示当最大和不能超过 sum 时,所分成的子数组个数。注意 f 单调递减。
二分查找左边界。
总结来说,如果发现题目中存在单调关系 ,就可以尝试使用二分搜索 的思路来解决。搞清楚单调性和二分搜索的种类,通过分析和画图,就能够写出最终的代码。
全部代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 T1: class Solution {public : int minEatingSpeed (vector<int >& piles, int h) int maxK = *max_element (piles.begin (), piles.end ()); int l = 1 , r = maxK+1 ; while (l < r){ int mid = l + (r-l)/2 ; int y = f (mid, piles); if (y == h) r = mid; else if (y < h) r = mid; else if (y > h) l = mid+1 ; } return l; } int f (int k, const vector<int >& piles) int sum = 0 ; for (int num : piles) sum += num/k + (num%k != 0 ); return sum; } }; T2: class Solution {public : int shipWithinDays (vector<int >& weights, int days) int maxCap = accumulate (weights.begin (), weights.end (), 0 ); int l = 1 , r = maxCap+1 ; while (l < r){ int mid = l + (r-l)/2 ; int y = f (mid, weights); if (y == days) r = mid; else if (y > days) l = mid+1 ; else if (y < days) r = mid; } return l; } int f (int cap, const vector<int >& weights) int cnt = 0 , sum = 0 ; for (const int &w : weights){ if (w > cap) return INT_MAX; if (sum+w <= cap) sum += w; else cnt++, sum = w; } if (sum) cnt++; return cnt; } }; T3: class Solution {public : int splitArray (vector<int >& nums, int k) int maxSum = accumulate (nums.begin (), nums.end (), 0 ); int l = 0 , r = maxSum+1 ; while (l < r){ int mid = l + (r-l)/2 ; int y = f (mid, nums); if (y == k) r = mid; else if (y < k) r = mid; else if (y > k) l = mid+1 ; } return l; } int f (int sum, const vector<int >& nums) int cnt = 0 , curSum = 0 ; for (const int &num : nums){ if (num > sum) return INT_MAX; if (curSum + num <= sum) curSum += num; else cnt++, curSum = num; } if (curSum) cnt++; return cnt; } };
8、带权随机选择算法
根据权重数组 w 生成前缀和数组 preSum。
生成一个取值在 preSum 之内的随机数,用二分搜索算法寻找大于等于这个随机数的最小元素索引。
最后对这个索引减一(因为前缀和数组有一位索引偏移),就可以作为权重数组的索引,即最终答案:
丢出的随机数 target 应该是范围 [1, lastPreSum]
二分搜索大于等于的左边界
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {private : vector<int > preSum; mt19937 gen; uniform_int_distribution<> dis; public : Solution (vector<int >& w) { int n = w.size (); preSum.resize (n+1 ); preSum[0 ] = 0 ; for (int i=0 ; i<n; i++) preSum[i+1 ] = preSum[i] + w[i]; dis = uniform_int_distribution<>(1 , preSum[n]); } int pickIndex () int target = dis (gen); return left_bound (target) - 1 ; } int left_bound (int target) int l = 0 , r = preSum.size (); while (l < r){ int mid = l + (r-l)/2 ; int y = preSum[mid]; if (y == target) r = mid; else if (y > target) r = mid; else if (y < target) l = mid+1 ; } return l; } };
9、田忌赛马决策算法
参考:870. 优势洗牌
注意:节约的策略是没问题的,但是没有必要。这也是本题有趣的地方,需要绕个脑筋急转弯:
我们暂且把田忌的一号选手称为 T1,二号选手称为 T2,齐王的一号选手称为 Q1。
如果 T2 能赢 Q1,你试图保存己方实力,让 T2 去战 Q1,把 T1 留着是为了对付谁?
显然,你担心齐王还有战力大于 T2 的马,可以让 T1 去对付。
但是你仔细想想,现在 T2 已经是可以战胜 Q1 的,Q1 可是齐王的最快的马耶,齐王剩下的那些马里,怎么可能还有比 T2 更强的马?
所以,没必要节约,最后我们得出的策略就是:将齐王和田忌的马按照战斗力排序,然后按照排名一一对比。如果田忌的马能赢,那就比赛,如果赢不了,那就换个垫底的来送人头,保存实力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : vector<int > advantageCount (vector<int >& nums1, vector<int >& nums2) { int n = nums1.size (); vector<pair<int , int >> pairs2; for (int i=0 ; i<n; i++) pairs2.push_back ({nums2[i], i}); sort (pairs2.begin (), pairs2.end (), greater<pair<int , int >>()); sort (nums1.begin (), nums1.end (), greater <int >()); vector<int > ans (n) ; int l = 0 , r = n-1 ; for (auto &p2 : pairs2){ int num2 = p2.first; int i = p2.second; if (nums1[l] > num2) ans[i] = nums1[l], l++; else ans[i] = nums1[r], r--; } return ans; } };
(三) 队列、栈
1、队列与栈的互相实现
用栈实现队列O ( 1 ) O(1) O ( 1 )
用队列实现栈O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 )
本质上是需要实现两个功能就行,top/front和 pop就行,因为只有这两个操作是对外显示状态的。
栈实现队列比较巧妙,下图只给出这个的图解和代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <stack> class MyQueue {private : std::stack<int > s1, s2; public : MyQueue () { } void push (int x) s1.push (x); } int peek () if (s2.empty ()) while (!s1.empty ()) { s2.push (s1.top ()); s1.pop (); } return s2.top (); } int pop () peek (); int poppedValue = s2.top (); s2.pop (); return poppedValue; } bool empty () return s1.empty () && s2.empty (); } };
2、单调栈
栈(stack)是很简单的一种数据结构,先进后出的逻辑顺序,符合某些问题的特点,比如说函数调用栈。单调栈实际上就是栈,只是利用了一些巧妙的逻辑,使得每次新元素入栈后,栈内的元素都保持有序(单调递增或单调递减)。
听起来有点像堆(heap)?不是的,单调栈用途不太广泛,只处理一类典型的问题,比如「下一个更大元素」,「上一个更小元素」等。
模版
输入一个数组 nums,请你返回一个等长的结果数组,结果数组中对应索引存储着下一个更大元素,如果没有更大的元素,就存 -1。
输入一个数组 nums = [2,1,2,4,3]
你返回数组 [4,2,4,-1,-1]
抽象思考:把数组的元素想象成并列站立的人,元素大小想象成人的身高。O ( n ) O(n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > calculateGreaterElement (vector<int >& nums) { int n = nums.size (); vector<int > res (n) ; stack<int > S; for (int i=n-1 ; i>=0 ; i--){ while (!S.empty () && nums[i] >= S.top ()) S.pop (); res[i] = S.empty ()? -1 : S.top (); S.push (nums[i]); } return res; }
496. 下一个更大元素 I
直接把 nums2 的全部元素都完成单调栈,存储答案在哈希表
然后根据 nums1 去查表即可。
739. 每日温度
仍然是单调栈即可
注意存储的是下标(因为答案是问几天之后)
环形数组:503. 下一个更大元素 II [2,1,2,4,3]你应该返回 [4,2,4,-1,4],因为拥有了环形属性,最后一个元素 3 绕了一圈后找到了比自己大的元素 4。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 T2: class Solution {public : vector<int > nextGreaterElement (vector<int >& nums1, vector<int >& nums2) { int n2 = nums2.size (); unordered_map<int , int > TB; stack<int > S; for (int i=n2-1 ; i>=0 ; i--){ while (!S.empty () && nums2[i] >= S.top ()) S.pop (); TB[nums2[i]] = S.empty () ? -1 : S.top (); S.push (nums2[i]); } int n1 = nums1.size (); vector<int > ans (n1) ; for (int i=0 ; i<n1; i++) ans[i] = TB[nums1[i]]; return ans; } }; T3: class Solution {public : vector<int > dailyTemperatures (vector<int >& temperatures) { int n = temperatures.size (); stack<int > S; vector<int > ans (n) ; for (int i=n-1 ; i>=0 ; i--){ while (!S.empty () && temperatures[i] >= temperatures[S.top ()]) S.pop (); ans[i] = S.empty () ? 0 : S.top ()-i; S.push (i); } return ans; } }; T4: class Solution {public : vector<int > nextGreaterElements (vector<int >& nums) { int n = nums.size (); stack<int > S; vector<int > ans (n) ; for (int i=2 *n-1 ; i>=0 ; i--){ while (!S.empty () && nums[i%n] >= S.top ()) S.pop (); ans[i%n] = S.empty () ? -1 : S.top (); S.push (nums[i%n]); } return ans; } };
3、单调队列
给你一个数组 window,已知其最值为 A,如果给 window 中添加一个数 B,那么比较一下 A 和 B 就可以立即算出新的最值;但如果要从 window 数组中减少一个数,就不能直接得到最值了,因为如果减少的这个数恰好是 A,就需要遍历 window 中的所有元素重新寻找新的最值。
这个场景很常见,但不用单调队列似乎也可以,比如 优先级队列(二叉堆) 就是专门用来动态寻找最值的,我创建一个大(小)顶堆,不就可以很快拿到最大(小)值了吗?如果单纯地维护最值的话,优先级队列很专业,队头元素就是最值。但优先级队列无法满足标准队列结构「先进先出 」的时间顺序,因为优先级队列底层利用二叉堆对元素进行动态排序,元素的出队顺序是元素的大小顺序,和入队的先后顺序完全没有关系。
现在需要一种新的队列结构,既能够维护队列元素「先进先出 」的时间顺序,又能够正确维护队列中所有元素的最值 ,这就是「单调队列」结构。
「单调队列」这个数据结构主要用来辅助解决滑动窗口 相关的问题。
前文 滑动窗口核心框架 把滑动窗口算法作为双指针技巧的一部分进行了讲解,但有些稍微复杂的滑动窗口问题不能只靠两个指针来解决,需要上更先进的数据结构。
参考:239. 滑动窗口最大值
1 2 3 4 5 6 7 8 9 10 11 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
核心:实现单调队列
「单调队列」的核心思路和「单调栈」类似,push 方法依然在队尾添加元素,但是要把前面比自己小的元素都删掉。
可以想象,加入数字的大小代表人的体重,体重大的会把前面体重不足的压扁,直到遇到更大的量级才停住。
注意,虽然说下面的 push 有 while 循环,但是时间复杂度是常数级,因为每一个元素只会操作一次。整个代码全部执行完,也才只有每个元素操作一次,即整个解法的时间复杂度是 O ( n ) O(n) O ( n )
那么push 时间复杂度是 O ( k ) O(k) O ( k )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class MonoQueue {private : deque<int > DQ; public : void push (int num) while (!DQ.empty () && num > DQ.back ()) DQ.pop_back (); DQ.push_back (num); } void pop (int num) if (num == DQ.front ()) DQ.pop_front (); } int max () return DQ.front (); } }; class Solution {public : vector<int > maxSlidingWindow (vector<int >& nums, int k) { int n = nums.size (); MonoQueue MQ; vector<int > ans; for (int i=0 ; i<=k-2 ; i++) MQ.push (nums[i]); for (int i=k-1 ; i<n; i++){ MQ.push (nums[i]); ans.push_back (MQ.max ()); MQ.pop (nums[i-k+1 ]); } return ans; } };
拓展延伸
本文给出的 MonotonicQueue 类只实现了 max 方法,你是否能够再额外添加一个 min 方法,在 O ( 1 ) O(1) O ( 1 )
本文给出的 MonotonicQueue 类的 pop 方法还需要接收一个参数,这不那么优雅,而且有悖于标准队列的 API,请你修复这个缺陷。
请你实现 MonotonicQueue 类的 size 方法,返回单调队列中元素的个数(注意,由于每次 push 方法都可能从底层的 q 列表中删除元素,所以 q 中的元素个数并不是单调队列的元素个数)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 template <typename E>class MonotonicQueue {public : void push (E elem) E pop () ; int size () E max () ; E min () ; };
(四) 二叉树
二叉树解题的思维模式分两类:
是否可以通过遍历一遍二叉树得到答案 ?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历 」的思维模式。是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案 ?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题 」的思维模式。
无论使用哪种思维模式,你都需要思考:它需要做什么事情 ?需要在什么时候(前/中/后序位置)做 ?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
二叉树很重要,算法高手会说:快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后序遍历 。
二叉树的所有问题,就是让你在前中后序位置注入巧妙的代码逻辑,去达到自己的目的,你只需要单独思考每一个节点应该做什么,其他的不用你管,抛给二叉树遍历框架,递归会在所有节点上做相同的操作 。
二叉树题目的递归解法可以分两类思路,第一类是遍历一遍二叉树得出答案,第二类是通过分解问题计算出答案,这两类思路分别对应着 回溯算法核心框架 和 动态规划核心框架 。
动归/DFS/回溯算法都可以看做二叉树问题的扩展,只是它们的关注点不同:
动态规划算法属于分解问题(分治)的思路,它的关注点在整棵「子树」。
回溯算法属于遍历的思路,它的关注点在节点间的「树枝」。
DFS 算法属于遍历的思路,它的关注点在单个「节点」。
1、二叉树心法(思路篇)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public : TreeNode* invertTree (TreeNode* root) { traverse (root); return root; } void traverse (TreeNode* root) if (root == NULL ) return ; TreeNode* tmp = root->left; root->left = root->right; root->right = tmp; traverse (root->left); traverse (root->right); } }; class Solution {public : TreeNode* invertTree (TreeNode* root) { TreeNode* ans = invert (root); return ans; } TreeNode* invert (TreeNode* root) { if (root == NULL ) return NULL ; TreeNode* l = invert (root->left); TreeNode* r = invert (root->right); root->left = r; root->right = l; return root; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : Node* connect (Node* root) { levelTraverse (root); return root; } void levelTraverse (Node* root) queue<Node*> Q; if (root) Q.push (root); while (!Q.empty ()){ int sz = Q.size (); Node* pre = NULL ; for (int i=0 ; i<sz; i++){ Node* a = Q.front (); Q.pop (); if (a->left) Q.push (a->left); if (a->right) Q.push (a->right); if (pre) pre->next = a; pre = a; } pre->next = NULL ; } } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public : void flatten (TreeNode* root) if (root == NULL ) return ; flatten (root->left); flatten (root->right); TreeNode *l = root->left; TreeNode *r = root->right; root->left = NULL ; root->right = l; TreeNode* p = root; while (p->right) p = p->right; p->right = r; } };
2、二叉树心法(构造篇)
(五) 二叉树强化
待完成…
(六) 二叉树拓展
待完成…
(七) 经典数据结构设计
1、LRU 算法
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
参考:146. LRU 缓存
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表 LinkedHashMap。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 class Node {public : int key, val; Node* next, *prev; Node (int k, int v) : key (k), val (v), next (nullptr ), prev (nullptr ) {} }; class DoubleList {private : Node* head; Node* tail; int size; public : DoubleList () { head = new Node (0 , 0 ); tail = new Node (0 , 0 ); head->next = tail; tail->prev = head; size = 0 ; } void addLast (Node* x) x->prev = tail->prev; x->next = tail; tail->prev->next = x; tail->prev = x; size++; } void remove (Node* x) x->prev->next = x->next; x->next->prev = x->prev; size--; } Node* removeFirst () { if (head->next == tail) return nullptr ; Node* first = head->next; remove (first); return first; } int getSize () return size; } }; class LRUCache {private : unordered_map<int , Node*> map; DoubleList cache; int cap; public : LRUCache (int capacity) { this ->cap = capacity; } int get (int key) if (!map.count (key)) { return -1 ; } makeRecently (key); return map[key]->val; } void put (int key, int val) if (map.count (key)) { deleteKey (key); addRecently (key, val); return ; } if (cap == cache.getSize ()) { removeLeastRecently (); } addRecently (key, val); } void makeRecently (int key) Node* x = map[key]; cache.remove (x); cache.addLast (x); } void addRecently (int key, int val) Node* x = new Node (key, val); cache.addLast (x); map[key] = x; } void deleteKey (int key) Node* x = map[key]; cache.remove (x); map.erase (key); } void removeLeastRecently () Node* deletedNode = cache.removeFirst (); int deletedKey = deletedNode->key; map.erase (deletedKey); } };
2、LFU 算法
LFU 算法的淘汰策略是 Least Frequently Used,也就是每次淘汰那些使用次数最少的数据。
从实现难度上来说,LFU 算法的难度大于 LRU 算法。
LFU 算法相当于是把数据按照访问频次进行排序,这个需求恐怕没有那么简单,而且还有一种情况,如果多个数据拥有相同的访问频次,我们就得删除最早插入的那个数据。也就是说 LFU 算法是淘汰访问频次最低的数据,如果访问频次最低的数据有多条,需要淘汰最旧的数据。
参考类似题目:895. 最大频率栈
解决方案:
使用一个 HashMap 存储 key 到 val 的映射,就可以快速计算 get(key)。1 unordered_map<int , int > keyToVal;
使用一个 HashMap 存储 key 到 freq 的映射,就可以快速操作 key 对应的 freq。1 unordered_map<int , int > keyToFreq;
如果在容量满了的时候进行插入,则需要将 freq 最小的 key 删除,如果最小的 freq 对应多个 key,则删除其中最旧的那一个。
需要 freq 到 key 的映射,用来找到 freq 最小的 key。
freq 对 key 是一对多的关系,即一个 freq 对应一个 key 的列表。用一个变量 minFreq 来记录当前最小的 freq。
希望 freq 对应的 key 的列表是存在时序的。
希望能够快速删除 key 列表中的任何一个 key,因为如果频次为 freq 的某个 key 被访问,那么它的频次就会变成 freq+1,就应该从 freq 对应的 key 列表中删除,加到 freq+1 对应的 key 的列表中。
1 2 unordered_map<int , unordered_set<int >> freqToKeys; int minFreq = 0 ;
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 class LFUCache { std::unordered_map<int , int > keyToVal; std::unordered_map<int , int > keyToFreq; std::unordered_map<int , std::list<int >> freqToKeys; int minFreq; int cap; public : LFUCache (int capacity) { this ->cap = capacity; this ->minFreq = 0 ; } int get (int key) if (keyToVal.find (key) == keyToVal.end ()) { return -1 ; } increaseFreq (key); return keyToVal[key]; } void put (int key, int val) if (this ->cap <= 0 ) return ; if (keyToVal.find (key) != keyToVal.end ()) { keyToVal[key] = val; increaseFreq (key); return ; } if (keyToVal.size () >= this ->cap) { removeMinFreqKey (); } keyToVal[key] = val; keyToFreq[key] = 1 ; freqToKeys[1 ].push_back (key); this ->minFreq = 1 ; } private : void removeMinFreqKey () auto & keyList = freqToKeys[this ->minFreq]; int deletedKey = keyList.front (); keyList.pop_front (); if (keyList.empty ()) { freqToKeys.erase (this ->minFreq); } keyToVal.erase (deletedKey); keyToFreq.erase (deletedKey); } void increaseFreq (int key) int freq = keyToFreq[key]; keyToFreq[key] = freq + 1 ; auto & oldList = freqToKeys[freq]; oldList.remove (key); freqToKeys[freq + 1 ].push_back (key); if (oldList.empty ()) { freqToKeys.erase (freq); if (freq == this ->minFreq) { this ->minFreq++; } } } };
3、随机集合、黑名单随机数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class RandomizedSet {private : vector<int > nums; unordered_map<int , int > valToIndex; public : RandomizedSet () { srand ((unsigned )time (NULL )); } bool insert (int val) if (valToIndex.count (val)) { return false ; } valToIndex[val] = nums.size (); nums.push_back (val); return true ; } bool remove (int val) if (!valToIndex.count (val)) { return false ; } int index = valToIndex[val]; int lastElement = nums.back (); valToIndex[lastElement] = index; swap (nums[index], nums.back ()); nums.pop_back (); valToIndex.erase (val); return true ; } int getRandom () int randomIndex = rand () % nums.size (); return nums[randomIndex]; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {private : int sz; unordered_map<int , int > mapping; public : Solution (int N, vector<int >& blacklist) { sz = N - blacklist.size (); unordered_set<int > blackSet; for (int & b : blacklist){ blackSet.insert (b); } int last = N - 1 ; for (int & b : blacklist){ if (b >= sz) continue ; while (blackSet.count (last)>0 ) { last--; } mapping[b] = last; last--; } } int pick () int index = rand () % sz; if (mapping.count (index) > 0 ){ return mapping[index]; } return index; } };
4、TreeMap 与 TreeSet
5、基本线段树
链式实现与数组实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class SegmentNode { int l, r; int mergeValue; SegmentNode left = null, right = null; } class SegmentTree { SegmentNode root; }
因为线段树是一种近似于完全二叉树的结构,所以也可以用数组来存储线段树,不需要真的使用 SegmentNode 构建树结构,我们不妨称这种实现方式为线段树的数组实现:
1 2 3 4 5 6 7 class SegmentTree { int [] tree; }
链式更容易理解,数组的更抽象但效率更高,实际应用中,直接采用数组的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 #include <functional> #include <iostream> #include <stdexcept> #include <vector> class SegmentNode {public : int l, r; int mergeVal; SegmentNode* left; SegmentNode* right; SegmentNode (int mergeVal, int l, int r) : mergeVal (mergeVal), l (l), r (r), left (nullptr ), right (nullptr ) {} }; class SegmentTree {private : SegmentNode* root; std::function<int (int , int )> merger; SegmentNode* build (const std::vector<int >& nums, int l, int r) { if (l == r) { return new SegmentNode (nums[l], l, r); } int mid = l + (r - l) / 2 ; SegmentNode* left = build (nums, l, mid); SegmentNode* right = build (nums, mid + 1 , r); SegmentNode* node = new SegmentNode (merger (left->mergeVal, right->mergeVal), l, r); node->left = left; node->right = right; return node; } void update (SegmentNode* node, int index, int value) if (node->l == node->r) { node->mergeVal = value; return ; } int mid = node->l + (node->r - node->l) / 2 ; if (index <= mid) { update (node->left, index, value); } else { update (node->right, index, value); } node->mergeVal = merger (node->left->mergeVal, node->right->mergeVal); } int query (SegmentNode* node, int qL, int qR) if (qL > qR) { throw std::invalid_argument ("Invalid query range" ); } if (node->l == qL && node->r == qR) { return node->mergeVal; } int mid = node->l + (node->r - node->l) / 2 ; if (qR <= mid) { return query (node->left, qL, qR); } else if (qL > mid) { return query (node->right, qL, qR); } else { return merger ( query (node->left, qL, mid), query (node->right, mid + 1 , qR) ); } } public : SegmentTree (const std::vector<int >& nums, std::function<int (int , int )> merger) : merger (merger) { root = build (nums, 0 , nums.size () - 1 ); } void update (int index, int value) update (root, index, value); } int query (int qL, int qR) return query (root, qL, qR); } }; int main () std::vector<int > arr = {1 , 3 , 5 , 7 , 9 }; SegmentTree st (arr, [](int a, int b) { return a + b; }) ; std::cout << st.query (1 , 3 ) << std::endl; st.update (2 , 10 ); std::cout << st.query (1 , 3 ) << std::endl; return 0 ; }
下面看数组实现线段树:
这里我们也把数组的索引 0 作为根节点,那么对于索引为 i 的节点,它的左子节点索引为 2*i+1,右子节点索引为 2*i+2。
数组实现线段树和数组实现二叉堆有一个重要不同:n n n 4 n 4n 4 n n n n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <iostream> #include <vector> #include <functional> #include <stdexcept> class ArraySegmentTree { std::vector<int > tree; int n; std::function<int (int , int )> merger; void build (const std::vector<int >& nums, int l, int r, int rootIndex) if (l == r) { tree[rootIndex] = nums[l]; return ; } int mid = l + (r - l) / 2 ; int leftRootIndex = leftChild (rootIndex); int rightRootIndex = rightChild (rootIndex); build (nums, l, mid, leftRootIndex); build (nums, mid + 1 , r, rightRootIndex); tree[rootIndex] = merger (tree[leftRootIndex], tree[rightRootIndex]); } void update (int l, int r, int rootIndex, int index, int value) if (l == r) { tree[rootIndex] = value; return ; } int mid = l + (r - l) / 2 ; if (index <= mid) { update (l, mid, leftChild (rootIndex), index, value); } else { update (mid + 1 , r, rightChild (rootIndex), index, value); } tree[rootIndex] = merger (tree[leftChild (rootIndex)], tree[rightChild (rootIndex)]); } int query (int l, int r, int rootIndex, int qL, int qR) if (qL == l && r == qR) { return tree[rootIndex]; } int mid = l + (r - l) / 2 ; int leftRootIndex = leftChild (rootIndex); int rightRootIndex = rightChild (rootIndex); if (qR <= mid) { return query (l, mid, leftRootIndex, qL, qR); } else if (qL > mid) { return query (mid + 1 , r, rightRootIndex, qL, qR); } else { return merger (query (l, mid, leftRootIndex, qL, mid), query (mid + 1 , r, rightRootIndex, mid + 1 , qR)); } } int leftChild (int pos) return 2 * pos + 1 ; } int rightChild (int pos) return 2 * pos + 2 ; } public : ArraySegmentTree (const std::vector<int >& nums, std::function<int (int , int )> mergeFunc) : n (nums.size ()), merger (mergeFunc) { tree.resize (4 * n); build (nums, 0 , n - 1 , 0 ); } void update (int index, int value) update (0 , n - 1 , 0 , index, value); } int query (int qL, int qR) if (qL < 0 || qR >= n || qL > qR) { throw std::invalid_argument ("Invalid range: [" + std::to_string (qL) + ", " + std::to_string (qR) + "]" ); } return query (0 , n - 1 , 0 , qL, qR); } }; int main () std::vector<int > arr = {1 , 3 , 5 , 7 , 9 }; ArraySegmentTree st (arr, [](int a, int b) { return a + b; }) ; std::cout << st.query (1 , 3 ) << std::endl; st.update (2 , 10 ); std::cout << st.query (1 , 3 ) << std::endl; return 0 ; }
6、动态线段树
7、懒更新线段树
8、Tire 树
9、朋友圈时间线算法
10、考场座位分配算法
11、计算器的设计
12、两个二叉堆实现中位数算法
13、数组去重问题
(八) 图
1、有向图:环检测与拓扑排序
进行拓扑排序之前,先要确保图中没有环。
图的「逆后序遍历」顺序,就是拓扑排序的结果。
参考:207. 课程表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution {private : vector<vector<int >> G; vector<bool > visit; bool flag = true ; vector<bool > onPath; public : bool canFinish (int numCourses, vector<vector<int >>& prerequisites) int n = prerequisites.size (); G.resize (numCourses); for (int i=0 ; i<n; i++){ int from = prerequisites[i][1 ]; int to = prerequisites[i][0 ]; G[from].push_back (to); } visit.resize (numCourses, false ); onPath.resize (numCourses, false ); for (int i=0 ; i<numCourses && flag; i++) traverse (i); return flag; } void traverse (int start) if (!flag) return ; if (onPath[start]){ flag = false ; return ; } if (visit[start]) return ; visit[start] = true ; onPath[start] = true ; for (int nxt : G[start]) traverse (nxt); onPath[start] = false ; } };
拓扑排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Solution {private : vector<vector<int >> G; vector<bool > visit; vector<bool > onPath; bool flag = true ; vector<int > ans; public : vector<int > findOrder (int numCourses, vector<vector<int >>& prerequisites) { int n = prerequisites.size (); G.resize (numCourses); for (int i=0 ; i<n; i++){ int from = prerequisites[i][0 ]; int to = prerequisites[i][1 ]; G[from].push_back (to); } visit.resize (numCourses, false ); onPath.resize (numCourses, false ); for (int i=0 ; i<numCourses && flag; i++) traverse (i); if (!flag) return vector<int >{}; return ans; } void traverse (int start) if (!flag) return ; if (onPath[start]){ flag = false ; return ; } if (visit[start]) return ; visit[start] = true ; onPath[start] = true ; for (int i : G[start]) traverse (i); onPath[start] = false ; ans.push_back (start); } };
实际上,上述两个都是 DFS 算法,其实也可以改换思想,写 BFS 的方法:
主要是记录所有的节点的入度,同时记录下有多少元素曾经入栈cnt。
先把所有入度为 0 的压入栈 Q
再依次取出栈顶元素 e 操作,所有 e 的指向元素的入度减一,若减到 0 了则入栈 Q
最终栈空,查看cnt == nodeNum 就是答案。
对于拓扑排序,实际上就只需要记录下入栈顺序就是答案:ans[cnt] = e 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Solution {public : bool canFinish (int numCourses, vector<vector<int >>& prerequisites) vector<int >* graph = buildGraph (numCourses, prerequisites); vector<int > indegree (numCourses) ; for (auto & edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; indegree[to]++; } queue<int > q; for (int i = 0 ; i < numCourses; i++) { if (indegree[i] == 0 ) { q.push (i); } } int count = 0 ; while (!q.empty ()) { int cur = q.front (); q.pop (); count++; for (int next : graph[cur]) { indegree[next]--; if (indegree[next] == 0 ) { q.push (next); } } } return count == numCourses; } vector<int >* buildGraph (int n, vector<vector<int >>& edges) { vector<vector<int >> graph (numCourses); for (int i = 0 ; i < numCourses; i++) { graph[i] = vector <int >(); } for (auto & edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; graph[from].push_back (to); } return graph; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class Solution {public : vector<int > findOrder (int numCourses, vector<vector<int >>& prerequisites) { vector<vector<int >> graph = buildGraph (numCourses, prerequisites); vector<int > indegree (numCourses) ; for (vector<int > edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; indegree[to]++; } queue<int > q; for (int i = 0 ; i < numCourses; i++) { if (indegree[i] == 0 ) { q.push (i); } } vector<int > res (numCourses) ; int count = 0 ; while (!q.empty ()) { int cur = q.front (); q.pop (); res[count] = cur; count++; for (int next : graph[cur]) { indegree[next]--; if (indegree[next] == 0 ) { q.push (next); } } } if (count != numCourses) { return {}; } return res; } private : vector<vector<int >> buildGraph (int n, vector<vector<int >>& edges) { vector<vector<int >> graph (numCourses); for (int i = 0 ; i < numCourses; i++) { graph[i] = vector <int >(); } for (auto & edge : prerequisites) { int from = edge[1 ], to = edge[0 ]; graph[from].push_back (to); } return graph; } };
2、名流问题
参考:997. 找到小镇的法官
参考:277. 搜寻名人
给你 n 个人的社交关系(你知道任意两个人之间是否认识),然后请你找出这些人中的「名人」。
这个节点没有一条指向其他节点的有向边;且其他所有节点都有一条指向这个节点的有向边。
这里的第一个题目是可以直接这样做的,但是第二个就不行了!
力扣第 277 题「搜寻名人」就是这个经典问题,不过并不是直接把邻接矩阵传给你 ,而是只告诉你总人数 n,同时提供一个 API knows 来查询人和人之间的社交关系。很明显,knows API 本质上还是在访问邻接矩阵。
bool knows(int i, int j);能够返回 i 是否认识 j
暴力
优化 1
优化 2
注意:它保证了人群中最多有一个名人 。
对于情况一,cand 认识 other,所以 cand 肯定不是名人,排除。因为名人不可能认识别人。
对于情况二,other 认识 cand,所以 other 肯定不是名人,排除。
对于情况三,他俩互相认识,肯定都不是名人,可以随便排除一个。
对于情况四,他俩互不认识,肯定都不是名人,可以随便排除一个。因为名人应该被所有其他人认识。只要观察任意两个之间的关系,就至少能确定一个人不是名人 。(优化1)
进一步优化:理解上面的优化解法,其实可以不需要额外的空间解决这个问题。(优化 2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 T1暴力: class Solution {public : int findCelebrity (int n) for (int cand = 0 ; cand < n; cand++) { int other; for (other = 0 ; other < n; other++) { if (cand == other) continue ; if (knows (cand, other) || !knows (other, cand)) { break ; } } if (other == n) { return cand; } } return -1 ; } }; T2优化 1 : class Solution {public : int findCelebrity (int n) if (n == 1 ) return 0 ; queue<int > q; for (int i = 0 ; i < n; i++) { q.push (i); } while (q.size () >= 2 ) { int cand = q.front (); q.pop (); int other = q.front (); q.pop (); if (knows (cand, other) || !knows (other, cand)) { q.push (other); } else { q.push (cand); } } int cand = q.front (); for (int other = 0 ; other < n; other++) { if (other == cand) { continue ; } if (!knows (other, cand) || knows (cand, other)) { return -1 ; } } return cand; } }; T3优化 2 : class Solution {public : int findCelebrity (int n) int cand = 0 ; for (int other = 1 ; other < n; other++) { if (!knows (other, cand) || knows (cand, other)) { cand = other; } else { } } for (int other = 0 ; other < n; other++) { if (cand == other) continue ; if (!knows (other, cand) || knows (cand, other)) { return -1 ; } } return cand; } };
3、二分图判定
二分图的定义:二分图的顶点集可分割为两个互不相交的子集,图中每条边依附的两个顶点都分属于这两个子集,且两个子集内的顶点不相邻。
说白了就是遍历一遍图,一边遍历一边染色,看看能不能用两种颜色给所有节点染色,且相邻节点的颜色都不相同 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class Solution {private : bool flag = true ; vector<int > color; public : bool isBipartite (vector<vector<int >>& graph) int n = graph.size (); color.resize (n); for (int i=0 ; i<n && flag; i++) if (color[i]==0 ){ color[i] = 1 ; dfs (graph, i); } return flag; } void dfs (vector<vector<int >>& G, int start) if (!flag) return ; for (int i : G[start]){ if (color[i]==0 ){ color[i] = color[start]==1 ? 2 : 1 ; dfs (G, i); } else { if (color[i] == color[start]) flag = false ; } } } }; class Solution {private : bool flag = true ; vector<int > color; public : bool isBipartite (vector<vector<int >>& graph) int n = graph.size (); color.resize (n); for (int i=0 ; i<n && flag; i++) if (color[i]==0 ){ color[i] = 1 ; bfs (graph, i); } return flag; } void bfs (vector<vector<int >>& G, int start) if (!flag) return ; queue<int > Q; Q.push (start); while (!Q.empty () && flag){ int cur = Q.front (); Q.pop (); for (int i : G[cur]){ if (color[i]==0 ){ color[i] = color[cur]==1 ? 2 : 1 ; Q.push (i); } else { if (color[i]==color[cur]) flag = false ; } } } } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution {private : bool flag = true ; vector<int > color; vector<vector<int >> G; public : bool possibleBipartition (int n, vector<vector<int >>& dislikes) color.resize (n, 0 ); G.resize (n); for (auto &p : dislikes){ int a = p[0 ]-1 , b = p[1 ]-1 ; G[a].push_back (b); G[b].push_back (a); } for (int i=0 ; i<n && flag; i++){ if (color[i] == 0 ){ color[i] = 1 ; dfs (i); } } return flag; } void dfs (int start) if (!flag) return ; for (int i : G[start]){ if (color[i]==0 ){ color[i] = color[start]==1 ? 2 : 1 ; dfs (i); } else { if (color[i]==color[start]) flag = false ; } } } };
4、Union-Find 并查集
并查集(Union-Find)算法是一个专门针对「动态连通性」的算法。
动态连通性
我们使用森林(若干棵树)来表示图的动态连通性,用数组来具体实现这个森林。
怎么用森林来表示连通性呢?我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上。
如果节点 p 和 q 连通的话,它们一定拥有相同的根节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class UF { int count; vector<int > parent; public : UF (int n) { this ->count = n; parent.resize (n); for (int i = 0 ; i < n; i++) parent[i] = i; } int find (int x) while (parent[x] != x) x = parent[x]; return x; } void union_ (int p, int q) int rootP = find (p); int rootQ = find (q); if (rootP == rootQ) return ; parent[rootP] = rootQ; count--; } bool connected (int p, int q) int rootP = find (p); int rootQ = find (q); return rootP == rootQ; } int count () return count; } };
由于可能不太平衡,每个树可能会退化成为一个链表,那么时间复杂度都是 O ( n ) O(n) O ( n )
下面是平衡性优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class UF {private : int count; vector<int > parent; vector<int > size; public : UF (int n) { count = n; parent.resize (n); size.resize (n); for (int i = 0 ; i < n; i++) { parent[i] = i; size[i] = 1 ; } } void union_ (int p, int q) int rootP = find (p); int rootQ = find (q); if (rootP == rootQ) return ; if (size[rootP] > size[rootQ]) { parent[rootQ] = rootP; size[rootP] += size[rootQ]; } else { parent[rootP] = rootQ; size[rootQ] += size[rootP]; } count--; } };
树的高度大致在 log N \log N log N find , union , connected 的时间复杂度都下降为 O ( log N ) O(\log N) O ( log N )
下面,还可以进行路径压缩:
这样每个节点的父节点就是整棵树的根节点,find 就能以 O ( 1 ) O(1) O ( 1 ) connected 和 union 复杂度都下降为 O ( 1 ) O(1) O ( 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class UF {private : int _count; vector<int > parent; public : UF (int n) { _count = n; parent.resize (n); for (int i = 0 ; i < n; i++) { parent[i] = i; } } void union_ (int p, int q) int rootP = find (p); int rootQ = find (q); if (rootP == rootQ) return ; parent[rootQ] = rootP; _count--; } bool connected (int p, int q) int rootP = find (p); int rootQ = find (q); return rootP == rootQ; } int find (int x) if (parent[x] != x) { parent[x] = find (parent[x]); } return parent[x]; } int count () return _count; } };
Union-Find 算法的复杂度可以这样分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class UnionFind {private : int count; vector<int > parent; public : UnionFind (int n){ count = n; parent.resize (n); for (int i=0 ; i<n; i++) parent[i] = i; } int find (int a) if (parent[a] != a) parent[a] = find (parent[a]); return parent[a]; } void union_ (int a, int b) int ap = find (a); int bp = find (b); if (ap != bp){ parent[ap] = bp; count--; } } bool connected (int a, int b) int ap = find (a); int bp = find (b); return ap == bp; } int size () return count; } }; class Solution {public : int findCircleNum (vector<vector<int >>& isConnected) int n = isConnected.size (); UnionFind UF (n) ; for (int i=0 ; i<n; i++) for (int j=i; j<n; j++) if (isConnected[i][j]) UF.union_ (i, j); return UF.size (); } };
更多参考题:
5、Kruskal MST最小生成树(并查集+排序贪心)
最小生成树算法主要有 Prim 算法(普里姆算法)和 Kruskal 算法(克鲁斯卡尔算法)两种,这两种算法虽然都运用了贪心思想,但从实现上来说差异还是蛮大的。
最小生成树
先说「树」和「图」的根本区别:树不会包含环,图可以包含环 。
如果一幅图没有环,完全可以拉伸成一棵树的模样。说的专业一点,树就是「无环连通图」 。
生成树 是含有图中所有顶点的「无环连通子图」。那么最小生成树很好理解了,所有可能的生成树中,权重和最小的那棵生成树就叫「最小生成树 」。
Kruskal 算法的一个难点是保证生成树的合法性,因为在构造生成树的过程中,你首先得保证生成的那玩意是棵树(不包含环)对吧,那么 Union-Find 算法就是帮你干这个事儿的。
参考:261. 以图判树
给你输入编号从 0 到 n-1 的 n 个结点,和一个无向边列表 edges(每条边用节点二元组表示),请你判断输入的这些边组成的结构是否是一棵树。
我们可以思考一下,什么情况下加入一条边会使得树变成图(出现环) ?
对于添加的这条边,如果该边的两个节点本来就在同一连通分量里,那么添加这条边会产生环;
反之,如果该边的两个节点不在同一连通分量里,则添加这条边不会产生环。
判断两个节点是否连通(是否在同一个连通分量中)就是 Union-Find 算法的拿手绝活。
Kruskal 算法mst,你要保证这些边:
包含图中的所有节点。
形成的结构是树结构(即不存在环)。
权重和最小。将所有边按照权重从小到大排序,从权重最小的边开始遍历,如果这条边和 mst 中的其它边不会形成环,则这条边是最小生成树的一部分,将它加入 mst 集合;否则,这条边不是最小生成树的一部分,不要把它加入 mst 集合 。
参考:1135. 最低成本联通所有城市
参考:1584. 连接所有点的最小费用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class UnionFind {private : int count; vector<int > parent; public : UnionFind (int n){ count = n; parent.resize (n); for (int i=0 ; i<n; i++) parent[i] = i; } int find (int a) if (parent[a] != a) parent[a] = find (parent[a]); return parent[a]; } void union_ (int a, int b) int ap = find (a); int bp = find (b); if (ap != bp){ parent[ap] = bp; count--; } } bool connected (int a, int b) int ap = find (a); int bp = find (b); return ap == bp; } int size () return count; } }; class Solution {public : int minCostConnectPoints (vector<vector<int >>& points) int n = points.size (); vector<vector<int >> edges; for (int i=0 ; i<n; i++){ for (int j=i+1 ; j<n; j++){ int d = abs (points[i][0 ]-points[j][0 ]) + abs (points[i][1 ]-points[j][1 ]); edges.push_back ({i, j, d}); } } sort (edges.begin (), edges.end (), [](const vector<int >& A, const vector<int >& B){ return A[2 ] < B[2 ]; }); UnionFind UF (n) ; int mst = 0 ; for (auto e : edges){ int i = e[0 ], j = e[1 ], d = e[2 ]; if (!UF.connected (i, j)){ UF.union_ (i, j); mst += d; } if (UF.size () == 1 ) break ; } return mst; } };
Kruskal 算法,主要的难点是利用 Union-Find 并查集算法向最小生成树中添加边,配合排序的贪心思路,从而得到一棵权重之和最小的生成树。O ( E + V ) O(E+V) O ( E + V ) O ( E log E + E ) O(E\log E + E) O ( E log E + E )
6、Prim MST最小生成树(BFS+切分贪心)
Kruskal 和 Prim 都是最小生成树的算法,两种算法的时间复杂度是一样的。会使用一个即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 class Solution {public : int minCostConnectPoints (vector<vector<int >>& points) int n = points.size (); vector<list<vector<int >>> graph = buildGraph (n, points); return Prim (graph).weightSum (); } private : vector<list<vector<int >>> buildGraph (int n, vector<vector<int >>& points) { vector<list<vector<int >>> graph (n); for (int i = 0 ; i < n; i++) { for (int j = i + 1 ; j < n; j++) { int xi = points[i][0 ], yi = points[i][1 ]; int xj = points[j][0 ], yj = points[j][1 ]; int weight = abs (xi - xj) + abs (yi - yj); graph[i].push_back ({i, j, weight}); graph[j].push_back ({j, i, weight}); } } return graph; } }; class Prim {private : priority_queue<vector<int >, vector<vector<int >>, function<bool (vector<int >, vector<int >)>> pq; vector<bool > inMST; int weightSum_ = 0 ; vector<list<vector<int >>> graph; public : Prim (vector<list<vector<int >>>& graph) : graph (graph), pq ([](vector<int > a, vector<int > b) { return a[2 ] > b[2 ]; }) { int n = graph.size (); this ->inMST.resize (n, false ); inMST[0 ] = true ; cut (0 ); while (!pq.empty ()) { vector<int > edge = pq.top (); pq.pop (); int to = edge[1 ]; int weight = edge[2 ]; if (inMST[to]) { continue ; } weightSum_ += weight; inMST[to] = true ; cut (to); } } void cut (int s) for (auto & edge : graph[s]) { int to = edge[1 ]; if (inMST[to]) { continue ; } pq.push (edge); } } int weightSum () return weightSum_; } bool allConnected () for (bool connected : inMST) { if (!connected) { return false ; } } return true ; } };
总时间复杂度:O ( E log E ) O(E\log E) O ( E log E )
7、Dijkstra 单源最短路径
Dijkstra 算法是一种用于计算图中单源最短路径的算法,本质上是一个经过特殊改造的 BFS 算法,改造点有两个:
使用 优先级队列,而不是普通队列进行 BFS 算法。
添加了一个备忘录,记录起点到每个可达节点的最短路径权重和。
注意:
distTo[id] 永远维护到达 id 节点的最小距离。而 State 里面那个 distFromStart,维护的是 State.id 这个节点入队时 距离起点的距离。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class State {public : int id; int distFromStart; State (int i, int d): id (i), distFromStart (d) {} }; auto cmp = [](const State& a, const State& b){ return a.distFromStart > b.distFromStart; }; class Solution {private : vector<int > distTo; priority_queue<State, vector<State>, decltype (cmp)> PQ; vector<vector<int >> G; public : int networkDelayTime (vector<vector<int >>& times, int n, int k) G.resize (n, vector <int >(n, INT_MAX)); for (int i=0 ; i<times.size (); i++){ int from = times[i][0 ]-1 , to = times[i][1 ]-1 ; G[from][to] = times[i][2 ]; } distTo.resize (n, INT_MAX); distTo[k-1 ] = 0 ; PQ.push (State (k-1 , 0 )); while (!PQ.empty ()){ State cur = PQ.top (); PQ.pop (); int cid = cur.id, cdist = cur.distFromStart; if (cdist > distTo[cid]) continue ; for (int v=0 ; v<n; v++){ if (G[cid][v] != INT_MAX){ int path = cdist + G[cid][v]; if (path < distTo[v]){ distTo[v] = path; PQ.push (State (v, path)); } } } } int maxT = *max_element (distTo.begin (), distTo.end ()); return maxT==INT_MAX ? -1 : maxT; } };
第二章、经典暴力搜索算法
(一) DFS、回溯
待完成…
(二) BFS
待完成…
第三章、经典动态规划算法
(一) 基本技巧
待完成…
(二) 子序列类型
待完成…
(三) 背包类型
总结:
问题
dp 定义
0-1背包
dp[i][j] 表示在前 i 个物品、背包容量 j 时,能够达到的最大价值
子集背包
dp[i][j] 表示在前 i 个物品、凑成 j 大小,能否完成
完全背包
dp[i][j] 表示在前 i 个物品、凑成 j 大小,能有多少种
三个的递推公式分别如下:d p [ i ] [ j ] = m a x ( d p [ i − 1 ] [ j ] , d p [ i − 1 ] [ j − W t [ i − 1 ] ] + V a l [ i − 1 ] ) dp[i][j]\ =\ max(dp[i-1][j],\ \ dp[i-1][j-Wt[i-1]]+Val[i-1]) d p [ i ] [ j ] = ma x ( d p [ i − 1 ] [ j ] , d p [ i − 1 ] [ j − W t [ i − 1 ]] + Va l [ i − 1 ]) d p [ i ] [ j ] = d p [ i − 1 ] [ j ] ∣ ∣ d p [ i − 1 ] [ j − n u m s [ i − 1 ] ] dp[i][j]\ =\ dp[i-1][j]\ \ ||\ \ dp[i-1][j-nums[i-1]] d p [ i ] [ j ] = d p [ i − 1 ] [ j ] ∣∣ d p [ i − 1 ] [ j − n u m s [ i − 1 ]] d p [ i ] [ j ] = d p [ i − 1 ] [ j ] + d p [ i ] [ j − n u m s [ i − 1 ] ] dp[i][j]\ =\ dp[i-1][j]\ +\ dp[i][j-nums[i-1]] d p [ i ] [ j ] = d p [ i − 1 ] [ j ] + d p [ i ] [ j − n u m s [ i − 1 ]] i刚刚计算的信息!
1、0-1 背包
背包问题的 dp 数组定义:dp[i][w] 的定义如下:对于前 i 个物品,当前背包的容量为 w,这种情况下可以装的最大价值是 dp[i][w]。
比如说,如果 dp[3][5] = 6,其含义为:对于给定的一系列物品中,若只从前 3 个物品中选择,当背包容量为 5 时,最多可以装下的价值为 6。
最终答案就是 dp[N][W]
base case 就是 dp[0][..] = dp[..][0] = 0
1 2 3 4 5 6 7 8 9 10 11 int [][] dp[N+1 ][W+1 ]dp[0 ][..] = 0 dp[..][0 ] = 0 for i in [1. .N]: for w in [1. .W]: dp[i][w] = max ( dp[i-1 ][w], dp[i-1 ][w - wt[i-1 ]] + val[i-1 ] ) return dp[N][W]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int zeroOneBag (vector<int >& Wt, vector<int >& Val, int cap) int n = Wt.size (); vector<vector<int >> dp (n+1 , vector <int >(cap+1 , 0 )); for (int i=0 ; i<=n; i++) dp[i][0 ] = 0 ; for (int i=0 ; i<=cap; i++) dp[0 ][i] = 0 ; for (int i=1 ; i<=n; i++){ for (int w=1 ; w<=cap; w++){ if (Wt[i-1 ] > w) dp[i][w] = dp[i-1 ][w]; else dp[i][w] = max ( dp[i-1 ][w], dp[i-1 ][w-Wt[i-1 ]] + Val[i-1 ] ) } } return dp[n][cap]; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : int maxTotalReward (vector<int >& rewardValues) int n = rewardValues.size (); sort (rewardValues.begin (), rewardValues.end ()); int m = 2 * rewardValues[n-1 ] - 1 ; vector<vector<bool >> dp (n+1 , vector <bool >(m+1 , false )); for (int i=0 ; i<=n; i++) dp[i][0 ] = true ; for (int j=1 ; j<=m; j++) dp[0 ][j] = false ; for (int i=1 ; i<=n; i++){ for (int j=1 ; j<=m; j++){ int jd = j - rewardValues[i-1 ]; if (jd >= 0 && rewardValues[i-1 ] > jd) dp[i][j] = dp[i-1 ][j] || dp[i-1 ][jd]; else dp[i][j] = dp[i-1 ][j]; } } int ans = 0 ; for (int j=0 ; j<=m; j++) if (dp[n][j]) ans = j; return ans; } };
2、子集背包
参考:416. 分割等和子集
输入一个只包含正整数的非空数组 nums,请你写一个算法,判断这个数组是否可以被分割成两个子集,使得两个子集的元素和相等。
为什么说是背包问题?sum / 2 的背包和 N 个物品,每个物品的重量为 nums[i]。现在让你装物品,是否存在一种装法,能够恰好将背包装满?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : bool canPartition (vector<int >& nums) int sum = accumulate (nums.begin (), nums.end (), 0 ); if (sum%2 ) return false ; int n = nums.size (); int m = sum/2 ; vector<vector<bool >> dp (n+1 , vector <bool >(m+1 , false )); for (int i=0 ; i<=n; i++) dp[i][0 ] = true ; for (int j=1 ; j<=m; j++) dp[0 ][j] = false ; for (int i=1 ; i<=n; i++){ for (int j=1 ; j<=m; j++){ int ok = j-nums[i-1 ]; if (ok>=0 ) dp[i][j] = dp[i-1 ][j] || dp[i-1 ][ok]; else dp[i][j] = dp[i-1 ][j]; } } return dp[n][m]; } };
注意到 dp[i][j] 都是通过上一行 dp[i-1][..] 转移过来的,之前的数据都不会再使用了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public : bool canPartition (vector<int >& nums) int sum = accumulate (nums.begin (), nums.end (), 0 ); if (sum%2 ) return false ; int n = nums.size (); int m = sum/2 ; vector<bool > dp (m+1 , false ) ; dp[0 ] = true ; for (int i=1 ; i<=n; i++){ for (int j=m; j>=0 ; j--){ int ok = j-nums[i-1 ]; if (ok>=0 ) dp[j] = dp[j] || dp[ok]; } } return dp[m]; } };
3、完全背包
参考:518. 零钱兑换 II
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
有一个背包,最大容量为 amount,有一系列物品 coins,每个物品的重量为 coins[i],每个物品的数量无限。请问有多少种方法,能够把背包恰好装满?
暴力:实际上无非需要多次选用硬币。
优化:但是只需要修改一处,就可以不用浪费遍历,你要做的只是利用前面已经用过这个新硬币的结果!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 暴力: class Solution {public : int change (int amount, vector<int >& coins) int n = coins.size (); vector<vector<long long >> dp (n+1 , vector <long long >(amount+1 , 0 )); for (int i=0 ; i<=n; i++) dp[i][0 ] = 1 ; for (int j=1 ; j<=amount; j++) dp[0 ][j] = 0 ; for (int i=1 ; i<=n; i++){ for (int j=1 ; j<=amount; j++){ int coin = coins[i-1 ]; for (int ok=j; ok >= 0 ; ok-=coin) dp[i][j] += dp[i-1 ][ok]; } } return dp[n][amount]; } }; 优化: class Solution {public : int change (int amount, vector<int >& coins) int n = coins.size (); vector<vector<int >> dp (n+1 , vector <int >(amount+1 , 0 )); for (int i=0 ; i<=n; i++) dp[i][0 ] = 1 ; for (int j=1 ; j<=amount; j++) dp[0 ][j] = 0 ; for (int i=1 ; i<=n; i++){ for (int j=1 ; j<=amount; j++){ int ok = j-coins[i-1 ]; if (ok >= 0 ) dp[i][j] = dp[i-1 ][j] + dp[i][ok]; else dp[i][j] = dp[i-1 ][j]; } } return dp[n][amount]; } };
4、目标和
我们前文经常说回溯算法和递归算法有点类似,有的问题如果实在想不出状态转移方程,尝试用回溯算法暴力解决也是一个聪明的策略,总比写不出来解法强。
参考:494. 目标和
给你一个非负整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 '+' 或 '-' ,然后串联起所有整数,可以构造一个 表达式 :
例如,nums = [2, 1] ,可以在 2 之前添加 ‘+’ ,在 1 之前添加 ‘-’ ,然后串联起来得到表达式 “+2-1” 。
显然可以使用回溯法,就是每层选择就行了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 回溯法: class Solution {private : int ans = 0 ; public : int findTargetSumWays (vector<int >& nums, int target) backtrace (nums, target, 0 ); return ans; } void backtrace (vector<int >& nums, int remain, int k) if (k == nums.size ()){ if (remain == 0 ) ans++; return ; } remain -= nums[k]; backtrace (nums, remain, k+1 ); remain += nums[k]; remain += nums[k]; backtrace (nums, remain, k+1 ); remain -= nums[k]; } };
动态规划之所以比暴力算法快,是因为动态规划技巧消除了重叠子问题。回溯算法遍历递归树的过程中,也有可能出现相同的子树,我们也可以提前识别并避免重复遍历这些子树,从而提高效率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {private : unordered_map<string, int > memo; public : int findTargetSumWays (vector<int >& nums, int target) return dp (nums, 0 , target); } int dp (vector<int >& nums, int i, int remain) if (i == nums.size ()){ if (remain == 0 ) return 1 ; else return 0 ; } string cur = to_string (i) + ',' + to_string (remain); if (memo.find (cur) != memo.end ()) return memo[cur]; int res = dp (nums, i+1 , remain-nums[i]) + dp (nums, i+1 , remain+nums[i]); memo[cur] = res; return res; } };
其实,这个问题可以转化为一个子集划分问题,而子集划分问题又是一个典型的背包问题。动态规划总是这么玄学,让人摸不着头脑……
首先,如果我们把 nums 划分成两个子集 A 和 B,分别代表分配 + 的数和分配 - 的数,那么他们和 target 存在如下关系:
1 2 3 4 sum(A) - sum(B) = target sum(A) = target + sum(B) sum(A) + sum(A) = target + sum(B) + sum(A) 2 * sum(A) = target + sum(nums)
综上,可以推出 sum(A) = (target + sum(nums)) / 2,也就是把原问题转化成:nums 中存在几个子集 A,使得 A 中元素的和为 (target + sum(nums)) / 2?
变成背包问题的标准形式:sum,现在给你 N 个物品,第 i 个物品的重量为 nums[i - 1](注意 1 <= i <= N),每个物品只有一个,请问你有几种不同的方法能够恰好装满这个背包?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : int findTargetSumWays (vector<int >& nums, int target) int sum = accumulate (nums.begin (), nums.end (), 0 ); int TS = target + sum; if (TS<0 || TS%2 ) return 0 ; else return subNum (nums, TS/2 ); } int subNum (vector<int >& nums, int target) int n = nums.size (); vector<vector<int >> dp (n+1 , vector <int >(target+1 , 0 )); dp[0 ][0 ] = 1 ; for (int i=1 ; i<=n; i++){ for (int j=0 ; j<=target; j++){ int ok = j-nums[i-1 ]; if (ok >= 0 ) dp[i][j] = dp[i-1 ][j] + dp[i-1 ][ok]; else dp[i][j] = dp[i-1 ][j]; } } return dp[n][target]; } };
(四) 游戏类型
待完成…
(五) 贪心类型
1、解题框架
请见前文:第零章-贪心算法
什么是贪心算法呢?贪心算法可以认为是动态规划算法的一个特例,相比动态规划,使用贪心算法需要满足更多的条件(贪心选择性质),但是效率比动态规划要高。
比如说一个算法问题使用暴力解法需要指数级时间,如果能使用动态规划消除重叠子问题,就可以降到多项式级别的时间,如果满足贪心选择性质,那么可以进一步降低时间复杂度,达到线性级别的。
什么是贪心选择性质呢,简单说就是:每一步都做出一个局部最优的选择,最终的结果就是全局最优。注意哦,这是一种特殊性质,其实只有一部分问题拥有这个性质。
2、老司机加油算法
参考:134. 加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
解法 1:暴力把每个站点试一遍N 2 N^2 N 2
解法 2:画图,把每过一站的实际变化计算出来 change[i] = gas[i]-cost[i]。那我们就是希望找到一个位置,是一直是正数的即可。那就是在最低点开始!
解法 3:贪心。如果选择站点 i 作为起点,走到站点 j 时发现变负数了,那么 i 和 j 中间的任意站点 k 都不可能作为起点,因为他们走到 j 都会变成负数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 T1: class Solution {public : int canCompleteCircuit (vector<int >& gas, vector<int >& cost) int n = gas.size (); int ans = -1 ; for (int i=0 ; i<n; i++){ int cur = 0 ; for (int j=0 ; j<n; j++){ int p = (i+j)%n; cur += gas[p] - cost[p]; if (cur < 0 ) break ; } if (cur >= 0 ) return i; } return -1 ; } }; T2: class Solution {public : int canCompleteCircuit (vector<int >& gas, vector<int >& cost) int n = gas.size (); int sum = 0 ; int low = -1 , lowSum = INT_MAX; for (int i=0 ; i<n; i++){ sum += gas[i] - cost[i]; if (sum <= lowSum){ low = (i+1 )%n; lowSum = sum; } } if (sum < 0 ) return -1 ; else return low; } }; T3: class Solution {public : int canCompleteCircuit (vector<int >& gas, vector<int >& cost) int n = gas.size (); int sum = 0 ; for (int i=0 ; i<n; i++) sum += gas[i] - cost[i]; if (sum < 0 ) return -1 ; int start = 0 ; int startSum = 0 ; for (int i=0 ; i<n; i++){ startSum += gas[i] - cost[i]; if (startSum < 0 ){ start = i+1 ; startSum = 0 ; } } return start % n; } };
3、区间调度问题
参考:435. 无重叠区间
给你很多形如 [start, end] 的闭区间,请你设计一个算法,算出这些区间中最多有几个互不相交的区间。
做法:按照结束时间排序,然后依次筛选。
区间问题肯定按照区间的起点或者终点进行排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 auto cmp = [](const vector<int >&a, const vector<int >& b){ return a[1 ] < b[1 ]; }; class Solution {public : int eraseOverlapIntervals (vector<vector<int >>& intervals) int n = intervals.size (); if (n == 0 ) return 0 ; sort (intervals.begin (), intervals.end (), cmp); int ans = 1 ; int curEnd = intervals[0 ][1 ]; for (int i=1 ; i<n; i++){ if (intervals[i][0 ] >= curEnd){ ans++; curEnd = intervals[i][1 ]; } } return n - ans; } };
下面两种写法,实际上是一样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 auto cmp = [](const vector<int >& a, const vector<int >& b){ return a[0 ] < b[0 ]; }; class Solution {public : int findMinArrowShots (vector<vector<int >>& points) int n = points.size (); sort (points.begin (), points.end (), cmp); int cnt = 1 ; int curEnd = points[0 ][1 ]; for (int i=1 ; i<n; i++){ int s = points[i][0 ], e = points[i][1 ]; if (s <= curEnd){ curEnd = min (curEnd, e); } else { cnt++; curEnd = e; } } return cnt; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 auto cmp = [](const vector<int >& a, const vector<int >& b){ return a[1 ] < b[1 ]; }; class Solution {public : int findMinArrowShots (vector<vector<int >>& points) int n = points.size (); sort (points.begin (), points.end (), cmp); int cnt = 1 ; int end = points[0 ][1 ]; for (int i=1 ; i<n; i++){ if (points[i][0 ] > end){ cnt++; end = points[i][1 ]; } } return cnt; } };
4、扫描线技巧-安排会议室
首先,差分数组是可以解决这个问题的,就是把每个时间都看做一个点,给每个区间进行加+1,最后看哪个点的数字最大,就是所需要的会议室数量了。
这个方法所需要的数组太大了,下面看别的方法。
基于差分数组的思路,我们可以推导出一种更高效,更优雅的解法。
我们首先把这些会议的时间区间进行投影:红色的点代表每个会议的开始时间点,绿色的点代表每个会议的结束时间点。
现在假想有一条带着计数器的线,在时间线上从左至右进行扫描,每遇到红色 的点,计数器 count 加一,每遇到绿色 的点,计数器 count 减一。count 的值,count 的最大值,就是需要申请的会议室数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : int minMeetingRooms (vector<Interval> &intervals) int n = intervals.size (); vector<int > start (n) ; vector<int > end (n) ; for (int i=0 ; i<n; i++){ start[i] = intervals[i].start; end[i] = intervals[i].end; } sort (start.begin (), start.end ()); sort (end.begin (), end.end ()); int ans = 0 ; int cnt = 0 ; int i = 0 , j = 0 ; while (i<n && j<n){ if (start[i] < end[j]){ cnt++; i++; } else { cnt--; j++; } ans = max (ans, cnt); } return ans; } };
5、视频剪辑
这题的细节问题,卡得我叫苦不迭。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 auto cmp = [](const vector<int >& a, const vector<int >& b){ if (a[0 ] == b[0 ]) return a[1 ] > b[1 ]; else return a[0 ] < b[0 ]; }; class Solution {public : int videoStitching (vector<vector<int >>& clips, int time) int n = clips.size (); sort (clips.begin (), clips.end (), cmp); if (clips[0 ][0 ] > 0 ) return -1 ; int cnt = 0 ; int curEnd = 0 ; int nxtEnd = 0 ; int i = 0 ; while (i<n && clips[i][0 ]<=curEnd){ while (i<n && clips[i][0 ]<=curEnd){ nxtEnd = max (nxtEnd, clips[i][1 ]); i++; } cnt++; curEnd = nxtEnd; if (curEnd >= time) return cnt; } return -1 ; } };
第四章、其他常见算法技巧
(一) 数学运算技巧
待完成…
(二) 经典面试题
待完成…