FunRec 推荐系统公开课-王树森
Notie: This page will NOT to be updated . (Published on 10th March)
传统推荐系统
一、概述
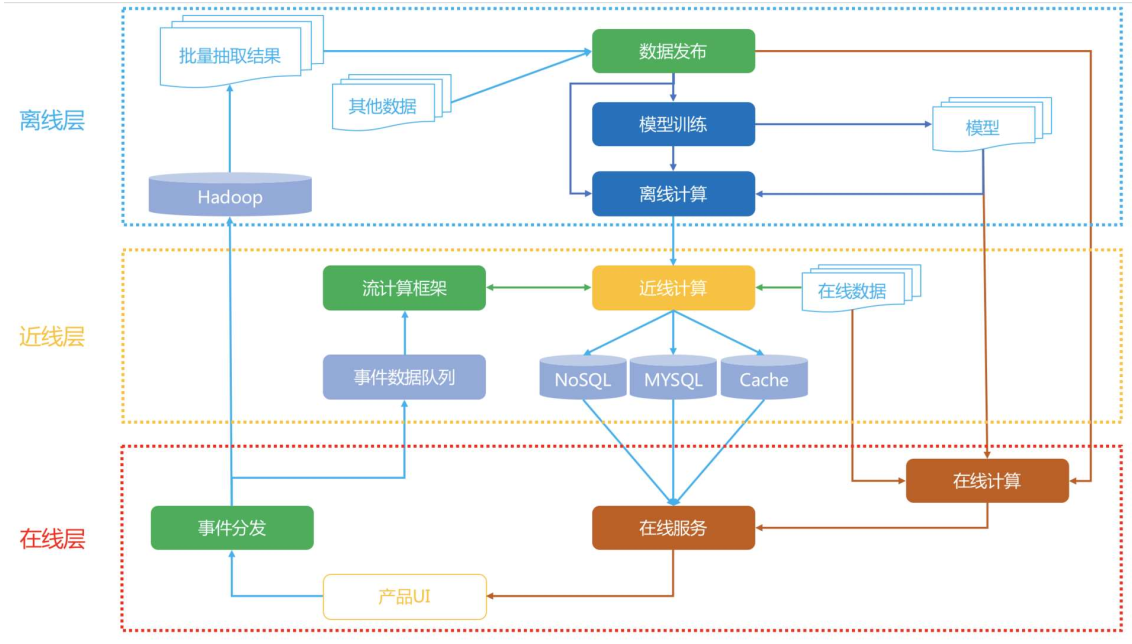
系统架构
离线层 :不用实时数据,不提供实时响应;
数据处理、数据存储;
特征工程、离线特征计算;
离线模型的训练;
近线层 :使用实时数据,不保证实时响应;
特征的事实更新计算
实时训练数据的获取
模型实时训练
在线层 :使用实时数据,保证实时在线服务;
模型在线服务
在线特征快速处理拼接
AB实验或者分流
运筹优化和业务干预
算法架构
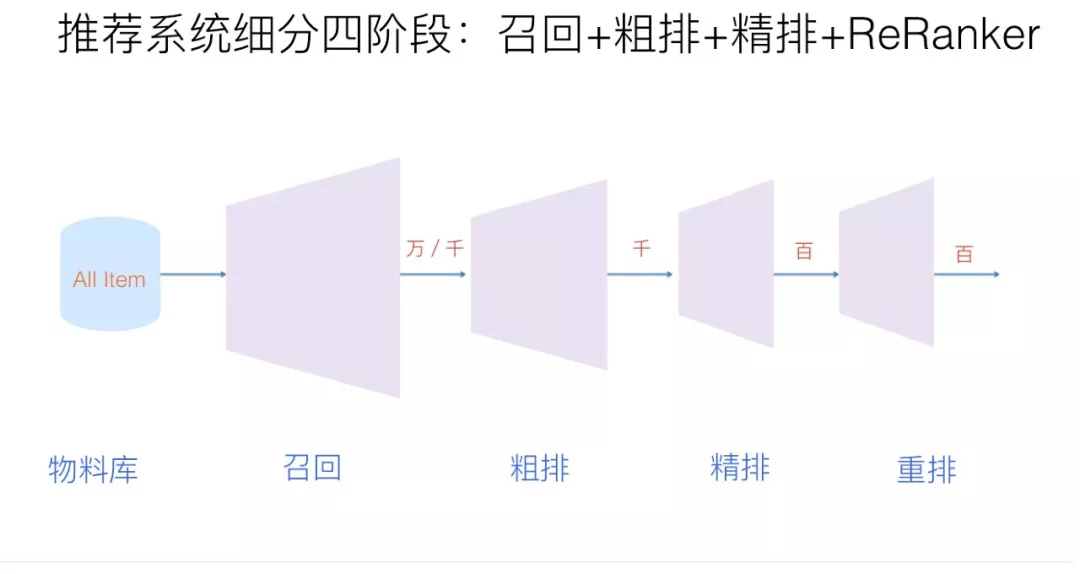
召回 :从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。粗排 :粗拍的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂。精排 :获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。重排 :获取精排的排序结果,基于运营策略、多样性、context上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。混排 :多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
技术栈
特征交叉模型
序列模型
多模态信息融合
多任务学习
强化学习
跨域推荐
工程技术
编程语言 :Python、Java(scala)、C++、sql、shell;机器学习 :Tensorflow/Pytorch、GraphLab/GraphCHI、LGB/Xgboost、SKLearn;数据分析 :Pandas、Numpy、Seaborn、Spark;数据存储:mysql、redis、mangodb、hive、kafka、es、hbase;
相似计算:annoy、faiss、kgraph
流计算:Spark Streaming、Flink
分布式:Hadoop、Spark
二、经典召回模型
(一) 基于协同过滤
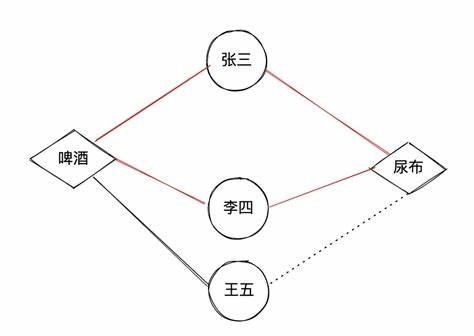
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。基本思想是:根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品 。
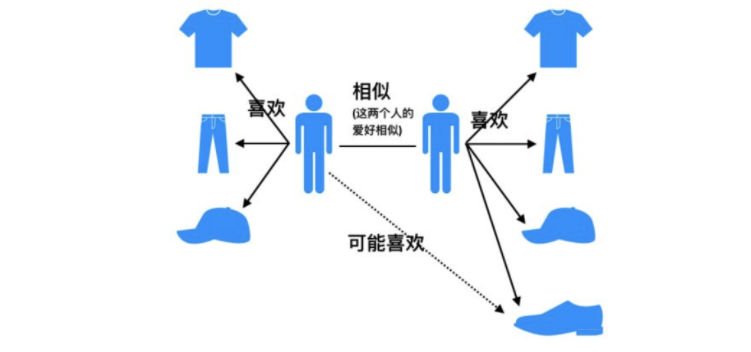
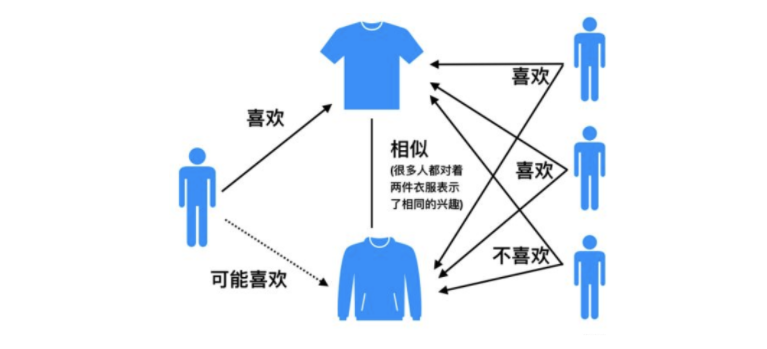
基于用户的协同过滤算法(UserCF):给用户推荐和他兴趣相似的其他用户喜欢的产品。
基于物品的协同过滤算法(ItemCF):给用户推荐和他之前喜欢的物品相似的物品。相似度 。
相似性度量方法
杰卡德(Jaccard)相似系数
s i m u , v = ∣ N ( u ) ∩ N ( v ) ∣ ∣ N ( u ) ∣ ∪ ∣ N ( v ) ∣ sim_{u,v} = \frac{|N(u) \cap N(v)|}{|N(u)| \cup |N(v)|}
s i m u , v = ∣ N ( u ) ∣ ∪ ∣ N ( v ) ∣ ∣ N ( u ) ∩ N ( v ) ∣
余弦相似度
s i m u , v = ∣ N ( u ) ∩ N ( v ) ∣ ∣ N ( u ) ∣ ⋅ ∣ N ( v ) ∣ = cos ( u , v ) = u ⋅ v ∣ u ∣ ⋅ ∣ v ∣ = ∑ i ∈ I r u i ⋅ r v i ∑ i ∈ I r u i 2 ⋅ ∑ i ∈ I r v i 2 sim_{u,v} = \frac{|N(u) \cap N(v)|}{\sqrt{|N(u)|\cdot |N(v)|}} \\
= \cos(u,v) = \frac{u\cdot v}{|u|\cdot |v|} \\
= \frac{\sum_{i\in I}{r_{ui}\cdot r_{vi}}}{\sqrt{\sum_{i\in I}{r_{ui}^2}}\cdot \sqrt{\sum_{i\in I}{r_{vi}^2}}}
s i m u , v = ∣ N ( u ) ∣ ⋅ ∣ N ( v ) ∣ ∣ N ( u ) ∩ N ( v ) ∣ = cos ( u , v ) = ∣ u ∣ ⋅ ∣ v ∣ u ⋅ v = ∑ i ∈ I r u i 2 ⋅ ∑ i ∈ I r v i 2 ∑ i ∈ I r u i ⋅ r v i
皮尔逊相关系数
s i m u , v = ∑ i ∈ I ( r u i − r u ‾ ) ⋅ ( r v i − r v ‾ ) ∑ i ∈ I ( r u i − r u ‾ ) 2 ⋅ ∑ i ∈ I ( r v i − r v ‾ ) 2 sim_{u,v} = \frac{\sum_{i\in I}{(r_{ui} - \overline{r_u})\cdot (r_{vi} - \overline{r_v})}}{\sqrt{\sum_{i\in I}{(r_{ui} - \overline{r_u})^2}}\cdot \sqrt{\sum_{i\in I}{(r_{vi} - \overline{r_v})^2}}}
s i m u , v = ∑ i ∈ I ( r u i − r u ) 2 ⋅ ∑ i ∈ I ( r v i − r v ) 2 ∑ i ∈ I ( r u i − r u ) ⋅ ( r v i − r v )
算法评估
召回率 :在模型召回预测的物品中,预测准确的物品占用户实际喜欢的物品的比例。
R e c a l l = ∑ u ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∣ T ( u ) ∣ 其中, R ( u ) 是推荐给用户 u 的物品, T ( u ) 是用户 u 在测试集上实际喜欢的物品 Recall = \frac{\sum_u{| R(u) \cap T(u) |} }{\sum_u{|T(u)|}}\\
其中,R(u)是推荐给用户u的物品,T(u)是用户u在测试集上实际喜欢的物品
R ec a ll = ∑ u ∣ T ( u ) ∣ ∑ u ∣ R ( u ) ∩ T ( u ) ∣ 其中, R ( u ) 是推荐给用户 u 的物品, T ( u ) 是用户 u 在测试集上实际喜欢的物品
精确率 :推荐的物品中,对用户准确推荐的物品占总物品的比例。
P r e c i s i o n = ∑ u ∣ R ( u ) ∩ T ( u ) ∣ ∑ u ∣ R ( u ) ∣ Precision = \frac{ \sum_u{|R(u) \cap T(u) |} }{ \sum_u{|R(u)|} }
P rec i s i o n = ∑ u ∣ R ( u ) ∣ ∑ u ∣ R ( u ) ∩ T ( u ) ∣
覆盖率 :推荐系统能够推荐出来的物品占总物品集合的比例。覆盖率反映了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能将长尾中的物品推荐给用户。
C o v e r a g e = ∣ ⋃ u ∈ U R ( u ) ∣ ∣ I ∣ 其中, I 是全部物品。 Coverage = \frac{ |\bigcup_{u\in U} R(u)| }{ |I| }\\
其中,I 是全部物品。
C o v er a g e = ∣ I ∣ ∣ ⋃ u ∈ U R ( u ) ∣ 其中, I 是全部物品。
新颖度 :用推荐列表中物品的平均流行度度量推荐结果的新颖度。Music Recommendation and Discovery in the Long Tail
基于用户的协同过滤UserCF
计算用户之间的相似度
计算用户对新物品的评分预测
R u , p = R u ‾ + ∑ s ∈ S w u , s ⋅ ( R s , p − R s ‾ ) ∑ s ∈ S w u , s 其中, w 是用户相似度, R 是用户对物品评分。 R_{u,p} = \overline{R_u} + \frac{\sum_{s\in S}{w_{u,s}\cdot (R_{s,p}-\overline{R_s})}}{\sum_{s\in S}{w_{u,s}}}\\
其中,w是用户相似度,R 是用户对物品评分。
R u , p = R u + ∑ s ∈ S w u , s ∑ s ∈ S w u , s ⋅ ( R s , p − R s ) 其中, w 是用户相似度, R 是用户对物品评分。
对用户进行物品推荐
基于物品的协同过滤ItemCF
计算物品之间的相似度
由当前对相似物品的评分,来计算对待选物品的评分
权重改进:
对热门物品进行惩罚
控制惩罚力度
w i , j = ∣ N ( i ) ∩ N ( j ) ∣ ∣ N ( i ) ∣ 1 − α ∣ N ( j ) ∣ α w_{i,j} = \frac{ | N(i) \cap N(j) | }{ |N(i)|^{1-\alpha} |N(j)|^{\alpha } }
w i , j = ∣ N ( i ) ∣ 1 − α ∣ N ( j ) ∣ α ∣ N ( i ) ∩ N ( j ) ∣
对活跃用户进行惩罚
w i , j = ∑ u ∈ N ( i ) ∩ N ( j ) 1 log 1 + ∣ N ( u ) ∣ ∣ N ( i ) ∣ 1 − α ∣ N ( j ) ∣ α w_{i,j} = \frac{ \sum_{u\in N(i) \cap N(j)}{ \frac{1}{\log 1 + |N(u)|} } }{ |N(i)|^{1-\alpha} |N(j)|^{\alpha } }
w i , j = ∣ N ( i ) ∣ 1 − α ∣ N ( j ) ∣ α ∑ u ∈ N ( i ) ∩ N ( j ) l o g 1 + ∣ N ( u ) ∣ 1
协同过滤算法存在的问题之一就是泛化能力弱 :
即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
导致的问题是热门物品具有很强的头部效应,容易跟大量物品产生相似,而尾部物品由于特征向量稀疏,导致很少被推荐 。
协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。为了解决这个问题, 同时增加模型的泛化能力。2006年,矩阵分解技术(Matrix Factorization, MF)。
Swing(Graph-based) User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
s ( i , j ) = ∑ u ∈ U i ∩ U j ∑ v ∈ U i ∩ U j w u ⋅ w v ⋅ 1 α + ∣ I u ∩ I v ∣ 用户权重参数 w u = 1 ∣ I u ∣ , w v = 1 ∣ I v ∣ 其中 U i 是点击过物品 i 的用户集, I u 是用户 u 点击过的物品集, α 是平滑系数。 s(i,j) = \sum\limits_{u\in U_i \cap U_j} \sum\limits_{v\in U_i \cap U_j} w_u \cdot w_v \cdot \frac{1}{\alpha + |I_u \cap I_v|}
\\
用户权重参数\quad w_u = \frac{1}{\sqrt{|I_u|}}, \quad w_v = \frac{1}{\sqrt{|I_v|}}
\\
其中U_i 是点击过物品i的用户集,I_u是用户u点击过的物品集, \alpha 是平滑系数。
s ( i , j ) = u ∈ U i ∩ U j ∑ v ∈ U i ∩ U j ∑ w u ⋅ w v ⋅ α + ∣ I u ∩ I v ∣ 1 用户权重参数 w u = ∣ I u ∣ 1 , w v = ∣ I v ∣ 1 其中 U i 是点击过物品 i 的用户集, I u 是用户 u 点击过的物品集, α 是平滑系数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from itertools import combinationsimport pandas as pdalpha = 0.5 top_k = 20 def load_data (train_path ): train_data = pd.read_csv(train_path, sep="\t" , engine="python" , names=["userid" , "itemid" , "rate" ]) print (train_data.head(3 )) return train_data def get_uitems_iusers (train ): u_items = dict () i_users = dict () for index, row in train.iterrows(): u_items.setdefault(row["userid" ], set ()) i_users.setdefault(row["itemid" ], set ()) u_items[row["userid" ]].add(row["itemid" ]) i_users[row["itemid" ]].add(row["userid" ]) print ("使用的用户个数为:{}" .format (len (u_items))) print ("使用的item个数为:{}" .format (len (i_users))) return u_items, i_users def swing_model (u_items, i_users ): item_pairs = list (combinations(i_users.keys(), 2 )) print ("item pairs length:{}" .format (len (item_pairs))) item_sim_dict = dict () for (i, j) in item_pairs: user_pairs = list (combinations(i_users[i] & i_users[j], 2 )) result = 0 for (u, v) in user_pairs: result += 1 / (alpha + list (u_items[u] & u_items[v]).__len__()) if result != 0 : item_sim_dict.setdefault(i, dict ()) item_sim_dict[i][j] = format (result, '.6f' ) return item_sim_dict def save_item_sims (item_sim_dict, top_k, path ): new_item_sim_dict = dict () try : writer = open (path, 'w' , encoding='utf-8' ) for item, sim_items in item_sim_dict.items(): new_item_sim_dict.setdefault(item, dict ()) new_item_sim_dict[item] = dict (sorted (sim_items.items(), key = lambda k:k[1 ], reverse=True )[:top_k]) writer.write('item_id:%d\t%s\n' % (item, new_item_sim_dict[item])) print ("SUCCESS: top_{} item saved" .format (top_k)) except Exception as e: print (e.args) if __name__ == "__main__" : train_data_path = "./ratings_final.txt" item_sim_save_path = "./item_sim_dict.txt" top_k = 10 train = load_data(train_data_path) u_items, i_users = get_uitems_iusers(train) item_sim_dict = swing_model(u_items, i_users) save_item_sims(item_sim_dict, top_k, item_sim_save_path)
Surprise算法
类别 i,j 的相关性:
θ i , j = p ( c i , j ∣ c j ) = ∣ N ( c i , j ) ∣ ∣ N ( c j ) ∣ 其中, c i , j 是购买过 i 类后买 j 类的数量, c j 是购买 j 类的数量。 \theta_{i,j} = p(c_{i,j} | c_j) = \frac{ | N(c_{i,j}) | }{| N(c_j) |}\\
其中,c_{i,j} 是购买过 i类后买j类的数量,c_j 是购买j类的数量。
θ i , j = p ( c i , j ∣ c j ) = ∣ N ( c j ) ∣ ∣ N ( c i , j ) ∣ 其中, c i , j 是购买过 i 类后买 j 类的数量, c j 是购买 j 类的数量。
采用最大相对落点来作为划分阈值。s 1 ( i , j ) = ∑ u ∈ U i ∩ U j 1 1 + ∣ t u i − t u j ∣ ∥ U i ∥ × ∥ U j ∥ 其中 j 属于 i 的相关类,且 j 的购买时间晚于 i 。 s1(i,j) = \frac{\sum\limits_{u\in U_i \cap U_j} \frac{1}{1+|t_{ui}-t_{uj}|} }{ \| U_i \| \times \| U_j \| } \\
其中 j属于i的相关类,且j 的购买时间晚于 i。
s 1 ( i , j ) = ∥ U i ∥ × ∥ U j ∥ u ∈ U i ∩ U j ∑ 1 + ∣ t u i − t u j ∣ 1 其中 j 属于 i 的相关类,且 j 的购买时间晚于 i 。
聚类层面:标签传播算法 s 2 s_2 s 2
Surprise算法通过利用类别信息和标签传播技术解决了用户共同购买图上的稀疏性问题:
s ( i , j ) = w ∗ s 1 ( i , j ) + ( 1 − w ) ∗ s 2 ( i , j ) s(i,j) = w * s1(i,j) + (1-w) * s2(i,j)\\
s ( i , j ) = w ∗ s 1 ( i , j ) + ( 1 − w ) ∗ s 2 ( i , j )
其中,原作者设定超参数权重 w=0.8。
协同过滤算法的特点 :
协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性,仅仅利用了用户与物品的交互信息 就可以实现推荐,是一个可解释性很强, 非常直观的模型。
但是也存在一些问题,处理稀疏矩阵的能力比较弱。
为了使得协同过滤更好处理稀疏矩阵问题,增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型 :
在协同过滤共现矩阵的基础上,使用更稠密的隐向量表示用户和物品。
通过挖掘用户和物品的隐含兴趣和隐含特征,在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
核心思想是通过隐含特征(latent factor)联系用户兴趣和物品(item),基于用户的行为找出潜在的主题和分类,然后对物品进行自动聚类,划分到不同类别/主题(用户的兴趣)。
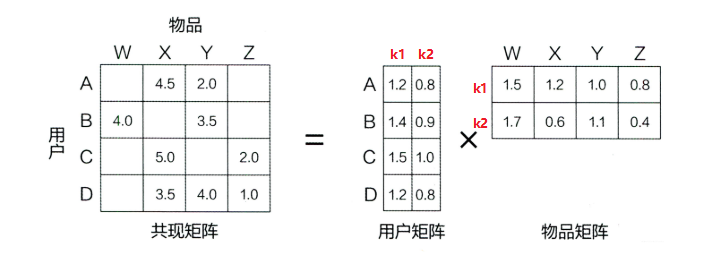
矩阵分解模型 :
基于评分矩阵,将其分解成Q和P两个矩阵乘积的形式(常用的矩阵分解方法有特征值分解EVD或者奇异值分解SVD),获取用户兴趣和物品的隐向量表达。
然后,基于两个分解矩阵去预测某个用户对某个物品的评分了。
最后,基于预测评分去进行物品推荐。
矩阵分解算法将 m×n 维的共享矩阵 R ,分解成 m×k 维的用户矩阵 U 和 k×n 维的物品矩阵 V 相乘的形式。
其中,m 是用户数量,n 是物品数量,k 是隐向量维度,也就是隐含特征个数。
这里的隐含特征没有太好的可解释性,需要模型自己去学习。
一般而言,k 越大隐向量能承载的信息内容越多,表达能力也会更强,但相应的学习难度也会增加。所以,我们需要根据训练集样本的数量去选择合适的数值,在保证信息学习相对完整的前提下,降低模型的学习难度。
之后进行评分预测:
P r e f e r e n c e ( u , i ) = r u , i = p u T q i = ∑ k = 1 K p u , k q i , k Preference(u,i) = r_{u,i} = p_u^T q_i = \sum\limits_{k=1}^{K} p_{u,k} q_{i,k}
P re f ere n ce ( u , i ) = r u , i = p u T q i = k = 1 ∑ K p u , k q i , k
FunkSVD
把求解上面两个矩阵的参数问题转换成一个最优化问题, 可以通过训练集里面的观察值利用最小化来学习用户矩阵和物品矩阵。
min q ∗ , p ∗ 1 2 ∑ ( u , i ) ∈ K ( r u i − p u T q i ) 2 + λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 ) \min\limits_{q^* ,p^*}\frac{1}{2} \sum\limits_{(u,i)\in K} (r_{ui} - p_u^Tq_i)^2 + \lambda (\| p_u \|^2 + \| q_i \|^2)
q ∗ , p ∗ min 2 1 ( u , i ) ∈ K ∑ ( r u i − p u T q i ) 2 + λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 )
BiasSVD
min q ∗ , p ∗ 1 2 ∑ ( u , i ) ∈ K ( r u i − ( μ + b u + b i + p u T q i ) ) 2 + λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 + b u 2 + b i 2 ) \min\limits_{q^* ,p^*}\frac{1}{2} \sum\limits_{(u,i)\in K} (r_{ui} - (\mu +b_u +b_i + p_u^Tq_i))^2 + \lambda (\| p_u \|^2 + \| q_i \|^2 + b_u^2 + b_i^2)
q ∗ , p ∗ min 2 1 ( u , i ) ∈ K ∑ ( r u i − ( μ + b u + b i + p u T q i ) ) 2 + λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 + b u 2 + b i 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import randomimport mathclass BiasSVD (): def __init__ (self, rating_data, F=5 , alpha=0.1 , lmbda=0.1 , max_iter=100 ): self.F = F self.P = dict () self.Q = dict () self.bu = dict () self.bi = dict () self.mu = 0 self.alpha = alpha self.lmbda = lmbda self.max_iter = max_iter self.rating_data = rating_data for user, items in self.rating_data.items(): self.P[user] = [random.random() / math.sqrt(self.F) for x in range (0 , F)] self.bu[user] = 0 for item, rating in items.items(): if item not in self.Q: self.Q[item] = [random.random() / math.sqrt(self.F) for x in range (0 , F)] self.bi[item] = 0 def train (self ): cnt, mu_sum = 0 , 0 for user, items in self.rating_data.items(): for item, rui in items.items(): mu_sum, cnt = mu_sum + rui, cnt + 1 self.mu = mu_sum / cnt for step in range (self.max_iter): for user, items in self.rating_data.items(): for item, rui in items.items(): rhat_ui = self.predict(user, item) e_ui = rui - rhat_ui self.bu[user] += self.alpha * (e_ui - self.lmbda * self.bu[user]) self.bi[item] += self.alpha * (e_ui - self.lmbda * self.bi[item]) for k in range (0 , self.F): self.P[user][k] += self.alpha * (e_ui * self.Q[item][k] - self.lmbda * self.P[user][k]) self.Q[item][k] += self.alpha * (e_ui * self.P[user][k] - self.lmbda * self.Q[item][k]) self.alpha *= 0.1 def predict (self, user, item ): return sum (self.P[user][f] * self.Q[item][f] for f in range (0 , self.F)) + self.bu[user] + self.bi[ item] + self.mu def loadData (): rating_data={1 : {'A' : 5 , 'B' : 3 , 'C' : 4 , 'D' : 4 }, 2 : {'A' : 3 , 'B' : 1 , 'C' : 2 , 'D' : 3 , 'E' : 3 }, 3 : {'A' : 4 , 'B' : 3 , 'C' : 4 , 'D' : 3 , 'E' : 5 }, 4 : {'A' : 3 , 'B' : 3 , 'C' : 1 , 'D' : 5 , 'E' : 4 }, 5 : {'A' : 1 , 'B' : 5 , 'C' : 5 , 'D' : 2 , 'E' : 1 } } return rating_data rating_data = loadData() basicsvd = BiasSVD(rating_data, F=10 ) basicsvd.train() for item in ['E' ]: print (item, basicsvd.predict(1 , item))
(二) 基于向量
待学习…
(三) 基于图
待学习…
(四) 基于序列
待学习…
(五) 基于树模型
待学习…
三、经典排序模型
(一) GBDT+LR
待学习…
(二) 特征交叉
待学习…
(三) Wide&Deep系列
待学习…
(四) 序列模型
待学习…
(五) 多任务学习
待学习…
四、推荐系统实战
待学习…
五、推荐系统面经
待学习…
最新调研
一、看着落地的
论文
来源
公司
关键词
做法
ab 收益
tune方式
KAR RecSys’24
华为
item llm+user llm
- 让 LLM 总结item得到item emb
音乐推荐 涨了播放量
frozen
LEARN AAAI’25
快手
ItemLLM+user decoder
- item LLM 固定,输入item特征得到item emb
广告 cvr+收入
frozen
BAHE SIGIR’24
蚂蚁
预先计算原子用户行为
- LLMs 的预训练浅层提取来原子用户行为的 emb,并存进离线 db
广告ctr+cpm
FFT上层 LLM
BEQUE WWW’24
阿里
SFT+离线模拟+PRO
query 重写任务,SFT 得到一个 LLM,将其预测的若干个候选 rewrites 通过 offline system的feedback 得到排序,再通过 PRO 算法再 tune LLM
电商搜索gmv + 单量
FFT
二、看着没落地的
论文
来源
公司
关键词
做法
tune方式
SLIM WWW’24
蚂蚁
蒸馏推荐理由
- 输入用户行为历史,大 LLM(gpt)产出的推荐利用
FFT
LLM-CF CIKM’24
快手
基于 CoT数据集做 RAG
- 拿推荐数据对 llama2 做 sft,再用 CoT 的prompt 让llama2 对user+item+label 产出一个推理过程,并通过bge得到emb,构建一个 CoT 数据集
FFT
ILM \
google
2阶训练+q-fromer
- phase1: 表示学习,交替训练两类表示学习(item-text表示学习,item-item表示学习)
frozen
EmbSum RecSys’24
meta
LLM摘要+t5 encoder
- 行为历丢给 LLM 产出摘要,对应的 hidden states 给 decoder 自回归
frozen
Agent4Ranking \
百度
agent rewrite+bert ranking
querry 重写任务,多个人群当成多个agent,每个通过多轮对话产出一个rewrite,再合在一起经过 bert+mmoe 计算 robust 损失+accuracy 损失
frozen
三、纯学术界
论文
来源
关键词
做法
tune 方式
Llama4Rec \
prompt增强+数据增强,finetune
- prompt 增强:在 prompt 里引入推荐模型的信息;
FFT
SAGCN TOIS’25
分 aspect打标、构图+gcn
- LLM 为用户评论打标,确定 aspect;
frozen
CUP \
LLM 总结+bert双塔
把用户的一堆历史评论扔给 chatgpt,让它总结出 128 个 token,然后丟给双塔 bert,另一个塔是 item 的描述,freeze bert 底层,只 tune 上层
frozen
LLaMA-E \
gpt 扩展 instruct
instruction formulating 为写 300 个种子指令,让 gpt 作为teacher,对 300个种子指令进行扩展,并由领域专家评估后,去重并保证质量,得到120k个指令作为训练集,再用 lora 去 instruct tuning
lora
EcomGPT AAAI’24
一系列电商任务FFT BLOOMZ
设置一系列的 task(100 多个 task)来 finetune BLOOMZ,包括命名实体识别、描述生成、对话 intent 提取等
FFT
ONCE WSDM’24
闭源 LLM 总结、
闭源LLM 输出文本(user profiler、content summarizer、personalized content generator),给开源 LLM 得到 user 表示,item 过开源 LLM 得到 item 表示,二者内积学 ctr
lora 训开源
Agent4Rec SIGIR’24
多智能体系统模拟交互,产出推荐样本
先训一个推荐模型,然后构建一个多智能体系统,模拟和这个推荐模型交互,产出新的样本给推荐模型做数据增强
仅训推荐模型,
RecPrompt CIKM’24
两个 LLM 迭代出最佳prompt
给一个初始 prompt,让LLM1 得到推荐结果,拿一个 monitor 衡量这个结果和 ground truth 的 mrr/ndcg,再用另一个 LLM 产出更好的 prompt 给第一个LLM 用,如此迭代,得到一个 best prompt
frozen
PO4ISR SIGIR’24
反思原因并refine/augment 地迭代出最优的prompt
给初始 prompt,收集 error case 让模型反思原因并 refine 出新的prompt,再 augment 出另一个 prompt,并 UCB 选出最好的prompt,如此迭代
frozen
TransRec KDD’24
受限生成
- 将一个 item 表示成 3 部分:id+titletattr,设计三种对应的instruct-tuning 任务;
lora
四、最前沿进展