
精排(二)特征交叉
参考
精排(二)特征交叉
前面我们讲了Wide & Deep模型,它把记忆能力和泛化能力结合起来。不过Wide部分有个问题:需要人工设计交叉特征,比如“用户年龄×商品类别”这样的组合。这种手工设计的方式不仅费时费力,还很难覆盖所有有用的特征组合。
既然手工设计这么麻烦,那能不能让模型自己学会做特征交叉呢?这就是本节要讨论的核心问题。我们会按照两条技术路线来看:先从简单的二阶交叉开始,然后到更复杂的高阶交叉,最后看看怎么让交叉变得更个性化和自适应。
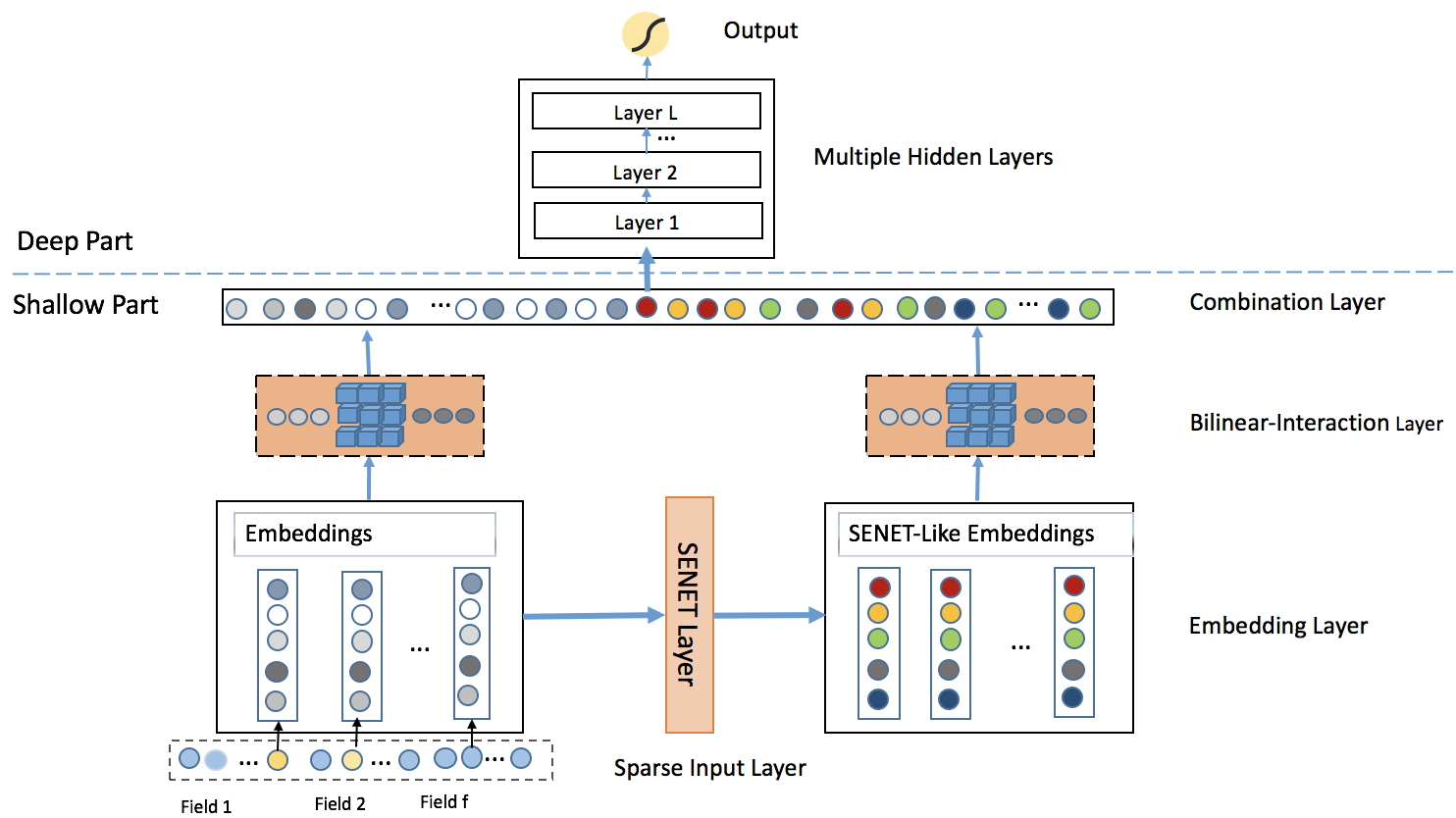
1、二阶特征交叉
针对 Wide & Deep 模型中人工特征工程的局限性,特征交叉自动化成为了一个迫切需要解决的问题。在这一探索过程中,首先要攻克的是:如何自动、高效地捕捉所有成对(二阶)特征的交互,并将其与深度学习模型结合。 这里的挑战不仅在于"自动",更在于面对推荐场景下海量、高维、稀疏的数据时如何实现"高效"。直接暴力计算所有特征对的组合是不可行的,我们需要一种更巧妙的机制来参数化这些交互。同时,在解决了二阶交互的自动化表达后,如何将这些捕获到的低阶、显式交互信息,与能够 ...
精排(一)记忆与泛化
参考
精排(一)记忆与泛化
在构建推荐模型时,我们常常追求两个看似矛盾的目标:记忆(Memorization)与泛化(Generalization)。
记忆能力,指的是模型能够学习并记住那些在历史数据中频繁共同出现的特征组合。例如,模型记住“买了A的用户,通常也会买B”。这种能力可以精准地捕捉显性、高频的关联,为用户提供与他们历史行为高度相关的推荐。
泛化能力,指的是模型能够发掘特征之间更深层次的关联,探索那些在数据中从未或很少出现过的全新特征组合。例如,模型通过学习发现“物品A和物品C都属于某个抽象类别,而用户喜欢该类别的物品”,从而向喜欢A的用户推荐了他们从未见过的C。这种能力有助于提升推荐的多样性和新颖性。
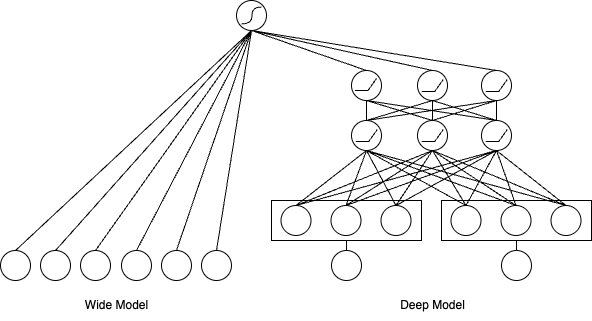
如何在一个模型中平衡并兼具这两种能力,是推荐系统领域的一个核心挑战。于2016年提出的Wide & Deep模型 ,为此提供了一个影响深远的经典架构。它并非简单的模型集成,而是通过一种巧妙的 联合训练(Joint Training) 机制,将两种能力无缝融合。
这个架构的核心思想是将模型结构拆分为两个部分,分别承担不同的职责,如下图所示:
记忆的捷 ...
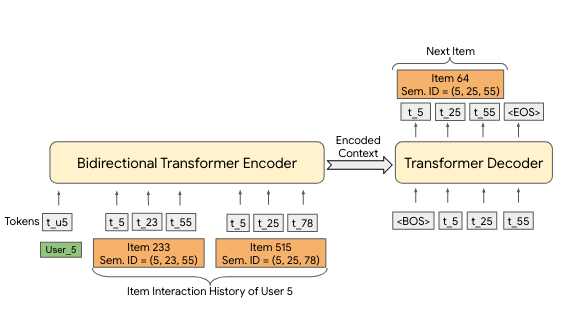
召回(三)序列召回
参考
召回(三)序列召回
在前面的章节中,我们学习了协同过滤和向量召回的方法。这些方法通常将用户的历史行为汇总成一个静态的表示(比如一个向量),然后基于这个表示进行推荐。但是,用户的行为其实是有时间顺序的,而且这个顺序往往包含了重要的信息。
比如,一个用户先浏览了跑鞋,然后看了运动服,接着又看了健身器材,这个顺序告诉我们这个用户可能对健身运动感兴趣。如果我们只是简单地把这些行为加起来或者平均,就丢失了这种时间顺序的信息。
序列召回就是要利用用户行为的时间顺序信息来进行推荐。它的基本想法是:用户的当前兴趣不仅取决于他过去喜欢什么,还取决于他最近在做什么,以及这些行为的顺序。
序列召回就是要利用用户行为的时间顺序信息来进行推荐。它的基本想法是:用户的当前兴趣不仅取决于他过去喜欢什么,还取决于他最近在做什么,以及这些行为的顺序。
相比传统的静态表示方法,序列召回能够对用户的兴趣理解的更加的准确及全面。它可以理解行为间的因果关系,如用户买手机后通常会买手机壳;能够捕捉兴趣的演化过程,如从数码产品转向户外运动;还能更好地处理多元化兴趣,在不同时段识别用户对电影、运动等领域的偏好变化。
在序 ...

召回(二)向量召回
参考
召回(二)向量召回
然而,矩阵分解仍然面临一些局限:它是一个相对简单的线性模型,通过用户向量和物品向量的内积来预测评分,表达能力有限;它主要依赖用户-物品交互矩阵,难以融入更多的特征信息(如用户画像、物品属性、上下文信息等);在面对数亿用户和数千万商品的工业级规模时,完整交互矩阵的处理和冷启动问题仍然是挑战。
在向量空间中,推荐问题得到了根本性的简化。原本需要遍历巨大交互矩阵的召回过程,转变为在高维向量空间中根据一个“查询”向量快速搜索出距离最近的K个物品向量。这种转变不仅大幅提升了计算效率,还通过向量的表示能力捕捉到了更深层次的语义相似性。
向量召回技术主要沿着两条路径发展。I2I(Item-to-Item)召回专注于计算物品与物品之间的相似性。U2I(User-to-Item)召回则直接匹配用户与物品。
1、I2I召回
在推荐系统中,I2I(Item-to-Item)召回是一个核心任务:给定一个物品,如何快速找出与之相似的其他物品?这个看似简单的问题,实际上蕴含着深刻的洞察——“相似性”并非仅仅由物品的内在属性决定,而是与用户的行为所共同定义的。如果两个商品经常被同 ...

召回(一)协同过滤
参考
召回(一)协同过滤
核心思想基于一个朴素的假设:相似的用户会喜欢相似的物品。
1、基于物品的协同过滤
ItemCF的思路建立在一个简单的假设上:用户的兴趣具有一定的连贯性,喜欢某个物品的用户往往也会对相似的物品感兴趣。它关注的是“和你喜欢的物品相似的还有什么”这一问题。
1.1 ItemCF 算法
流程
实现流程主要包含以下两个步骤:
第一步:物品相似度计算
wij=C[i][j]∣N(i)∣⋅∣N(j)∣这里∣N(i)∣表示与物品i有交互的用户总数,C[i][j]是两个物品的共现次数。w_{ij} = \frac{C[i][j]}{\sqrt{|N(i)| \cdot |N(j)|}} \\
这里|N(i)|表示与物品i有交互的用户总数,C[i][j]是两个物品的共现次数。
wij=∣N(i)∣⋅∣N(j)∣C[i][j]这里∣N(i)∣表示与物品i有交互的用户总数,C[i][j]是两个物品的共现次数。
第二步:候选物品推荐
首先,系统会选取用户最近交互的物品作为兴趣种子(通常是几百个),然后为每个种子物品找到最相似的若干个候选物品(如Top-10) ...

推荐系统概述
FunRec推荐系统
Start: 2025.12.15
End: 2025.
Check:
章节
(一)
(二)
(三)
(四)
(五)
(六)
1、系统概述
12.15
\
\
\
\
\
2、召回模型
12.15
12.16
12.17
\
\
\
3、精排模型
12.17
12.18
12.18
12.18
12.18
\
4、重排模型
12.18
12.18
\
\
\
\
5、难点热点
12.18
12.18
12.18
\
\
\
6、项目实践
12.19
12.19
12.20
12.21
12.21
12.21
7、面试经验
01.12
01.12
01.12
01.12
01.12
\
12.22
完全跑通搞懂 项目实践 思考提升,询问提升方案;
看完剩下的 面试经验,打印纸质版。
12.23
寻找并跑通1个创新的 召回/排序 项目;
更新简历。
12.24 投简历,找实习!
复习 面试经验 纸质;
重温 力扣HOT100 全书;
刷 热门题机刷 一遍。
岗位:推荐算法岗位
企业:小红书、美团、阿 ...

CS336(1):Basics
CS336(1): Basics
资料来源:斯坦福CS336: Language Modeling from Scratch
国内视频:B站 - (中英字幕完结)斯坦福CS336:从头开始构建大模型 | 2025年
本章包含课程:第 1、2 课
1. Tokenization
Tokenizer: strings <-> tokens (indexes)
基于字符、基于字节、基于单词的标记化非常次优。
BPE是一个有效的启发式查看语料库统计。
标记化是一种必要的弊端,也许有一天我们会从字节来做…
1.1 Character-based tokenization
直接按照 Unicode 字符编码分词即可。
问题1:这是一个非常大的词汇表。大约有150K个Unicode字符。
问题2:许多字符非常罕见(例如🌍),这是对词汇表的低效使用。
1234567891011121314151617181920class CharacterTokenizer(Tokenizer): """Represent a string as a ...
Transformer 开山之作
Transformer 开山之作
论文链接:https://arxiv.org/abs/1706.03762v7
视频讲解:Transformer论文逐段精读【论文精读】
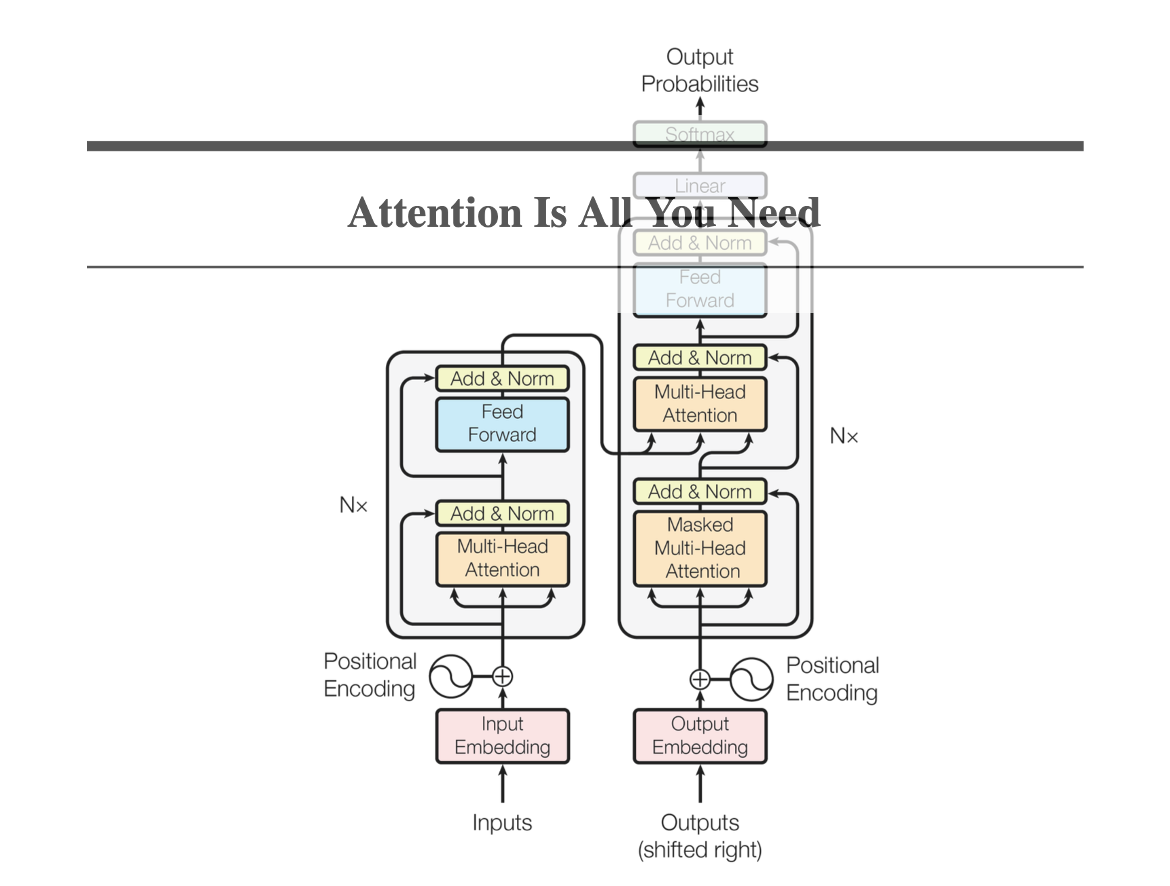
模型架构
Encoder
编码器(左)Encoder:(可以有N个)
Multi-Head Attention 层
Feed Forward 层(本质上就是MLP)
上述两者在输出后都残差连接Residual Connection 和层归一化Layer Normalization。
即 LayerNorm(x+Sublayer(x))LayerNorm(x+ Sublayer(x))LayerNorm(x+Sublayer(x))
固定输出维度 dmodel=512d_{model} = 512dmodel=512
Decoder
解码器(右)Decoder:(可以有N个)
Masked Multi-Head Attention 层
Multi-Head Attention 层
Feed Forward 层
第一个注意力层需要 Masked,是为了模拟预测的状态,不会提前知道后续词。
第二个注意 ...
大模型推荐系统 (应用)
阅读书籍: 《大模型推荐系统 | 算法原理、代码实战与案例分析》刘强
数据集来源:
MIND 新闻数据集对应论文MIND: A Large-scale Dataset for News Recommendation
Amazon 电商数据集
注:大型文件包工具git-lfs、强化学习训练工具trl
大模型在电商推荐中的应用
1、冷启动
1.1 数据准备
由于涉及冷启动商品生成模拟的用户行为,因此需要确定哪些是冷启动商品。
将用户行为数据按照时间排序,前 70%作为训练样本,后 30%作为测试样本。
只在测试数据中出现但不在训练数据中出现的商品就被认为是冷启动商品。
代码cold_start/utils/utils.py
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394 ...
大模型推荐系统(4)直接推荐范式
阅读书籍: 《大模型推荐系统 | 算法原理、代码实战与案例分析》刘强
数据集来源:
MIND 新闻数据集对应论文MIND: A Large-scale Dataset for News Recommendation
Amazon 电商数据集
注:大型文件包工具git-lfs、强化学习训练工具trl
直接推荐范式
利用大模型的上下文学习进行推荐
1、上下文学习推荐基本原理
当模型参数规模足够大时,大模型本身就具备非常强的泛化能力。基本能够直接使用这类大模型进行个性化推荐。
只需要使用特定提示词激发大模型的推荐能力就可以将其用于下游推荐任务,而无需进行任何微调,这种能力就叫做上下文学习,分为 zero-shot 和 few-shot 的。
另外,可以分解任务,逐步解决,叫做思维链能力。
注意,在经典的召回->排序推荐范式下,直接推荐范式其实是利用大模型进行排序,即对召回的候选物品进行排序。召回阶段使用其他推荐算法。
2、案例
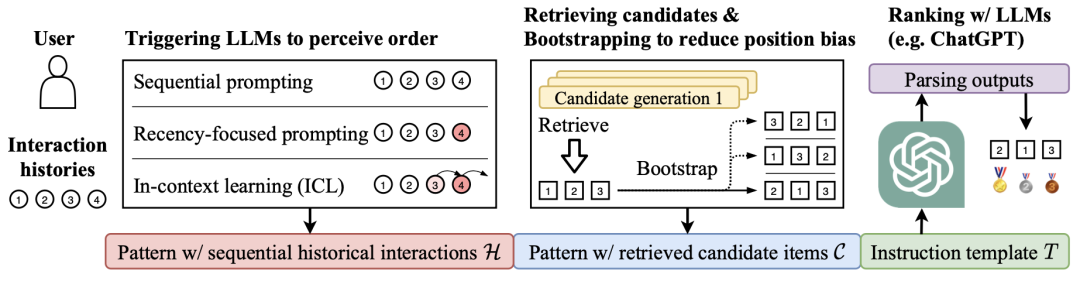
2.1 LLMRank 实现
构造用户历史交互序列(方法:顺序提示词、关注最近行为的提示词、上下文学习提示词)
构造抽取候选集(方法:多路召回后 ...