
深度学习推荐系统
深度学习推荐系统
来源:王喆《深度学习推荐系统 1.0》
第一章 宏观认知
- 互联网的核心需求是“增长”,而推荐系统正处在“增长引擎”的核心位置。
- 推荐系统要解决的“用户痛点”是用户如何在“信息过载”的情况下高效地获得感兴趣的信息。
- 信息:
- 物品信息
- 用户信息
- 场景信息
- 推荐系统处理问题的形式化定义:
对于用户 U (user), 在特定场景 C (context) 下,针对海量的物品信息,构建一个函数 f(U,I,C),预测用户对特定候选物品 I (item) 的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
第二章 传统推荐模型
- 发展脉络
- 协调过滤算法族CF:UserCF、ItemCF、MF
- 逻辑回归模型族LR:LR、LS-PLM、POLY2
- 因子分解机模型族FM:FM、FFM
- 组合模型:GBDT+LR
| 模型名称 | 基本原理 | 特点 | 局限性 |
|---|---|---|---|
| 协同过滤 | 根据用户的行为历史生成用户-物品共现矩阵,利用用户相似性和物品相似性进行推荐 | 原理简单、直接,应用广泛 | 泛化能力差,处理稀疏矩阵的能力差,推荐结果的头部效应较明显 |
| 矩阵分解 | 将协同过滤算法中的共现矩阵分解为用户矩阵和物品矩阵,利用用户隐向量和物品隐向量的内积进行排序并推荐 | 相较协同过滤,泛化能力有所加强,对稀疏矩阵的处理能力有所加强 | 除了用户历史行为数据,难以利用其他用户、物品特征及上下文特征 |
| 逻辑回归 | 将推荐问题转换成类似 CTR 预估的二分类问题,将用户、物品、上下文等不同特征转换成特征向量,输入逻辑回归模型得到 CTR,再按照预估 CTR 进行排序并推荐 | 能够融合多种类型的不同特征 | 模型不具备特征组合的能力,表达能力较差 |
| FM | 在逻辑回归的基础上,在模型中加入二阶特征交叉部分,为每一维特征训练得到相应特征隐向量,通过隐向量间的内积运算得到交叉特征权重 | 相比逻辑回归,具备了二阶特征交叉能力,模型的表达能力增强 | 由于组合爆炸问题的限制,模型不易扩展到三阶特征交叉阶段 |
| FFM | 在 FM 模型的基础上,加入“特征域”的概念,使每个特征在与不同域的特征交叉时采用不同的隐向量 | 相比 FM,进一步加强了特征交叉的能力 | 模型的训练开销达到了 O(n2) 的量级,训练开销较大 |
| GBDT+LR | 利用 GBDT 进行“自动化”的特征组合,将原始特征向量转换成离散型特征向量,并输入逻辑回归模型,进行最终的 CTR 预估 | 特征工程模型化,使模型具备了更高阶特征组合的能力 | GBDT 无法进行完全并行的训练,更新所需的训练时长较长 |
| LS-PLM | 首先对样本进行“分片”,在每个“分片”内部构建逻辑回归模型,将每个样本的各“分片”概率与逻辑回归的得分进行加权平均,得到最终的预估值 | 模型结构类似三层神经网络,具备了较强的表达能力 | 模型结构相比深度学习模型仍比较简单,有进一步提高的空间 |
1. 协同过滤——经典的推荐算法(2003)
- 利用现有数据的物品共现性,计算物品相似度矩阵,用户召回时取最近历史几个物品在矩阵中选出 top N 相似的物品作为结果即可。
- UserCF 具备更强的社交属性、发现热点跟踪热点, ItemCF 更适合兴趣变化较为稳定的。
- 优势:直观、可解释性强
- 局限:泛化能力弱, 头部效应明显, 处理稀疏向量的能力弱, 无法加入更多用户物品上下文信息特征。
2. 矩阵分解算法——协同过滤的进化(2006)
- 在共现矩阵的基础上,加入隐向量概念,强化处理稀疏矩阵的能力。用户和物品的隐向量通过分解协同过滤生成的共现矩阵得到。
- 矩阵分解有三种方法:特征值分解(需要方阵放弃)、奇异值分解(要求矩阵稠密且时间复杂度高放弃)、梯度下降(拟合现有样本对,最小化得分损失,加入正则化约束权重波动越小越好)
- 梯度下降做法:确定目标函数、对目标函数求各参数的偏导、各参数沿梯度反方向更新。
- 推荐时:利用用户隐向量和物品隐向量进行逐一内积运算得到用户对所有物品的评分预测,排序推荐即可。
- 优势:泛化能力强,空间复杂度低,扩展性和灵活性更好。
- 局限性:无法加入更多用户物品上下文信息特征,且在缺乏用户交互历史行为时,无法进行有效推荐(用户冷启动差)。
3. 逻辑回归——融合多种特征
- 推荐问题看成分类问题(点击预估问题,CTR),通过预测正样本的概率,再对概率排序进行推荐。
- 所有特征处理成数值型特征向量 x,将特征向量 作为模型的输入,赋予相应权重 加权求和得到 ,再输入 $sigmoid(z) = \frac{1}{1+e^{-z}} $ 函数使之映射为 0-1 的区间即为点击率。
- 训练方法:梯度下降、牛顿法、拟牛顿法。
- 优势:可以融合较为全面的特征,有数学含义支撑(因变量y符合伯努利分布),可解释性强(计算逻辑符合直观认知)。
- 局限:表达能力有限,无法进行特征交叉、特征筛选等高级操作,不可避免地会损失信息。
辛普森悖论:在分组后的各组比较中都优势的,在不分组总评中反而劣势
4. 从 FM 到 FFM ——自动特征交叉(2010)
- POLY2 模型:暴力组合特征,对所有特征都二维交叉赋权重。(缺陷:向量更加稀疏;参数量上升,计算复杂)
- FM 模型:隐向量特征交叉,为每个特征学习一个隐权重向量,特征交叉时用其内积作为交叉特征的权重(思想与矩阵分解MF异曲同工)。复杂度由 降为 。相比POLY2,虽然丢失了某些精确记忆能力,但泛化能力提高。
- FFM 模型:引入特征域感知,隐向量由原来的 变为 ,每个特征不是唯一一个隐向量,而是一组隐向量。两个特征交叉时,选出特征的域对应的隐向量进行交叉。(同一个独热编码为一个域,需要学习 n 个特征在 f 个域上的 k 维隐向量,参数量 ,计算量 很大)
- 优势:引入了二阶特征交叉,信息丰富。
- 劣势:更高高阶特征交叉会带来计算量爆炸,无法进行高阶特征交叉。
5. GBDT+LR —— 特征工程模型化(2014)
- 利用 GBDT 自动进行特征筛选和组合生成新的离散特征向量,再把该向量当做 LR 模型输入。(GBDT构建特征工程,LR预估CTR,两步独立训练,不存在LR梯度回传GBDT的问题)
- GBDT的基本结构是决策树组成的森林,学习方式为梯度提升,预测方式是把所有子树的结果加起来。后一棵树以前面的树林的结果与真实结果的残差为拟合目标。每棵树生成的过程是一颗标准的回归树生成过程,每一个节点的分裂是一个自然的特征选择过程,而多层节点的结构刚好对应特征的有效组合。这刚好解决了棘手的特征选择和组合问题。
- GBDT 转换特征:训练样本在每个子树都会落入一个叶子节点,落入叶子1其他叶子0,连起来就是一个特征向量,把所有子树特征向量拼接就是最终生成的新离散型特征向量(其实同时也丢失了一部分信息)。
- 树的深度决定了特征交叉阶数(深度N就是分裂N-1次,为N-1阶交叉)。
- 广义上讲,后续深度学习通过各类网络或Embedding层实现特征工程自动化,都是GBDT+LR开启的特征工程模型化的延续。
6. LS-PLM —— 阿里巴巴曾经的主流(2012)
- 大规模分段线性模型 Large Scale Piece-wise Linear Model。也称为 MLR 混合逻辑回归。为了对不同群体不同场景有针对性,先对全量样本进行聚类,再对每个分类使用逻辑回归进行CTR预估。
- 首先使用聚类函数 (softmax) 对样本进行分类,再用 LR 模型计算样本在分片中具体的CTR,然后将两者相乘后求和。
- 分片数 m 在阿里巴巴的经验值为 12。
第三章 深度学习时代
- 演化关系:均以 多层感知机 MLP 为核心,通过改变神经网络的结构。
- 改变神经网络的复杂程度:增加层数/结构。AutoRec, DeepCrossing。
- 改变特征交叉方式:用户向量物品向量互操作方式、多种交叉操作。NeuralCF、PNN。
- 组合模型:组合两种不同特点、优势互补的深度学习网络。Wide&Deep、Deep&Cross、DeepFM。
- FM模型的深度学习演化:提升交叉能力、添加注意力机制、添加初始化。NFM、AFM、FNN。
- 注意力机制结合:应用注意力机制。AFM、DIN。
- 序列模型结合:使用序列模型模拟用户行为或兴趣的演化趋势。DIEN。
- 强化学习结合:应用强化学习,强调在线学习和实时更新。DRN。
| 模型名称 | 基本原理 | 特点 | 局限性 |
|---|---|---|---|
| AutoRec | 基于自编码器,对用户或者物品进行编码,利用自编码器的泛化能力进行推荐 | 单隐层神经网络结构简单,可实现快速训练和部署 | 表达能力较差 |
| Deep Crossing | 利用“Embedding 层+多隐层+输出层”的经典深度学习框架,预完成特征的自动深度交叉 | 经典的深度学习推荐模型框架 | 利用全连接隐层进行特征交叉,针对性不强 |
| NeuralCF | 将传统的矩阵分解中用户向量和物品向量的点积操作,换成由神经网络代替的互操作 | 表达能力加强版的矩阵分解模型 | 只使用了用户和物品的 id 特征,没有加入更多其他特征 |
| PNN | 针对不同特征域之间的交叉操作,定义“内积”“外积”等多种积操作 | 在经典深度学习框架上提高模型特征交叉能力 | “外积”操作进行了近似化,一定程度上影响了其表达能力 |
| Wide&Deep | 利用 Wide 部分加强模型的“记忆能力”,利用 Deep 部分加强模型的“泛化能力” | 开创了组合模型的构造方法,对深度学习推荐模型的后续发展产生重大影响 | Wide 部分需要人工进行特征组合的筛选 |
| Deep&Cross | 用 Cross 网络替代 Wide&Deep 模型中的 Wide 部分 | 解决了 Wide&Deep 模型人工组合特征的问题 | Cross 网络的复杂度较高 |
| FNN | 利用 FM 的参数来初始化深度神经网络的 Embedding 层参数 | 利用 FM 初始化参数,加快整个网络的收敛速度 | 模型的主结构比较简单,没有针对性的特征交叉层 |
| DeepFM | 在 Wide&Deep 模型的基础上,用 FM 替代原来的线性 Wide 部分 | 加强了 Wide 部分的特征交叉能力 | 与经典的 Wide&Deep 模型相比,结构差别不明显 |
| NFM | 用神经网络代替 FM 中二阶隐向量交叉的操作 | 相比 FM,NFM 的表达能力和特征交叉能力更强 | 与 PNN 模型的结构非常相似 |
| AFM | 在 FM 的基础上,在二阶隐向量交叉的基础上对每个交叉结果加入了注意力得分,并使用注意力网络学习注意力得分 | 不同交叉特征的重要性不同 | 注意力网络的训练过程比较复杂 |
| DIN | 在传统深度学习推荐模型的基础上引入注意力机制,并利用用户行为历史物品和目标广告物品的相关性计算注意力得分 | 根据目标广告物品的不同,进行更有针对性的推荐 | 并没有充分利用除“历史行为”以外的其他特征 |
| DIEN | 将序列模型与深度学习推荐模型结合,使用序列模型模拟用户的兴趣进化过程 | 序列模型增强了系统对用户兴趣变迁的表达能力,使推荐系统开始考虑时间相关的行为序列中包含的有价值信息 | 序列模型的训练复杂,线上服务的延迟较长,需要进行工程上的优化 |
| DRN | 将强化学习的思路应用于推荐系统,进行推荐模型的线上实时学习和更新 | 模型对数据实时性的利用能力大大加强 | 线上部分较复杂,工程实现难度较大 |
1. AutoRec —— 单隐层神经网络(2015)
- 利用协同过滤中的共现矩阵,完成物品向量或用户向量的自编码。再利用自编码的结果得到用户对物品的预估评分,进而进行推荐排序。
- 自编码器:将向量 r 作为输入,通过自编码器后,得到的输出向量接近本身。相当于重建函数存储了所有数据向量的精华。一般来说,重建函数的参数数量远小于输入向量的维度数量,因此自编码器相当于完成了数据压缩和降维的工作。
- 很标准的三层神经网络(输入层、隐层、输出层),直接使用梯度反向传播即可。
- 有两种:输入向量是物品的所有评分向量,则是 I-AutoRec;输入向量是用户的评分向量,则是 U-AutoRec。(对比之下,U-AutoRec优点是输入一次目标用户的用户向量就可以重建用户对所有物品的评分,而I-AutoRec需要所有物品都输入完毕后都取出对应用户u的评分。但是,同时用户向量的稀疏性可能会影响模型效果。)
- 局限:结构简单表达能力不足。
- 模型结构上与后面的 Word2Vec 完全一致,但是用户目标和训练方法有所不同。
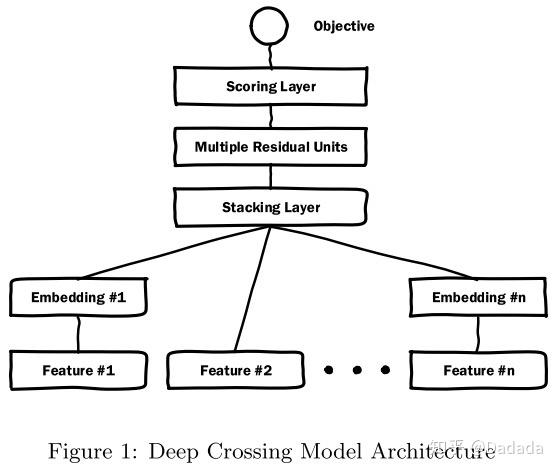
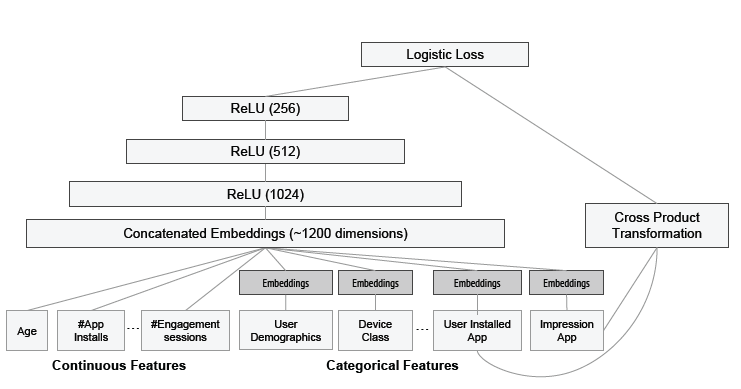
2. DeepCrossing —— 经典深度学习(2016)
- 特征:类别型特征(通过one-hot或 multi-hot 编码)、数值型特征(直接拼接进特征向量)。
- 网络结构:
Embedding层:将稀疏的类别型特征转换成稠密的 Embedding 向量(这里的实现是用经典的全连接层,但Embedding技术本身已经衍生出很多方法);数值型特征可以直接进入下一层,不用经过 Embedding层。Stacking层:堆叠层作用就是把不同的特征 Embedding 和 数值型特征拼接起来。Multiple Residual Units层:多层感知机,采用了多层残差网络。Scoring层:输出层,拟合优化目标,一般是LR逻辑回归模型采用 sigmoid(若是其他领域多分类问题则会是 softmax 模型)
- 训练方式:梯度反向传播即可。
- 注:从此开始,原始特征没有任何人工特征工程,直接交给深度学习embedding层处理,是革命意义的。这就是 DeepCrossing 的命名由来。
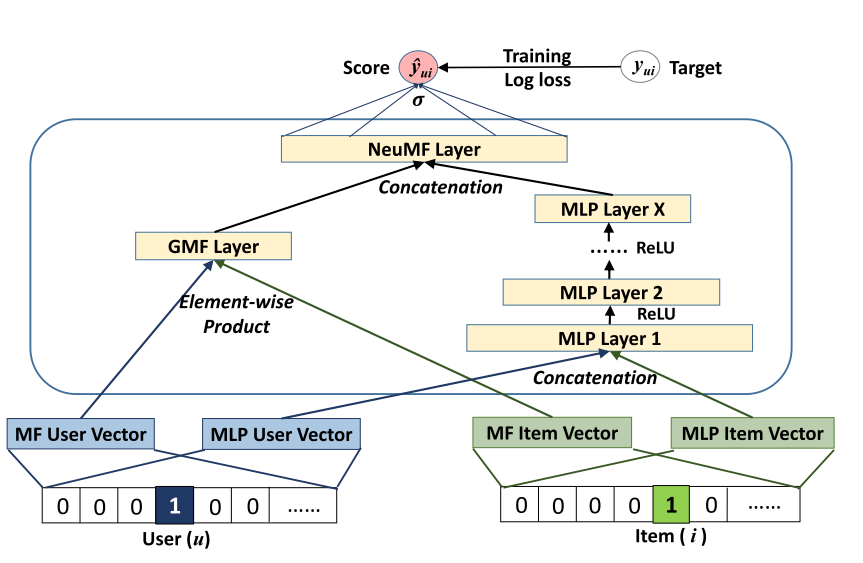
3. NeuralCF —— CF 结合深度学习(2017)
- 从深度学习角度看矩阵分解模型,矩阵分解的用户隐向量和物品隐向量相当于是 Embedding 方法,最终的 Scoring 层就是将两个隐向量进行内积后得到的相似度值。
- 但是内积还是太简单,无法有效拟合,可以用“MLP+输出层”替换内积操作,可以更充分交叉,也引入更多非线性表达能力强。
- 关于互操作,还可以有更多种,可以把不同互操作网络得到的特征向量拼接起来,交由输出层进行目标拟合,这就是 NeuralCF 混合模型。
- 优势:利用神经网络理论上可以拟合任何函数,灵活组合特征,按需增减复杂度。
- 局限:这是基于协同过滤思想构造的,没有引入更多其他特征信息,同时互操作也没有明确探究,需要进一步探索。
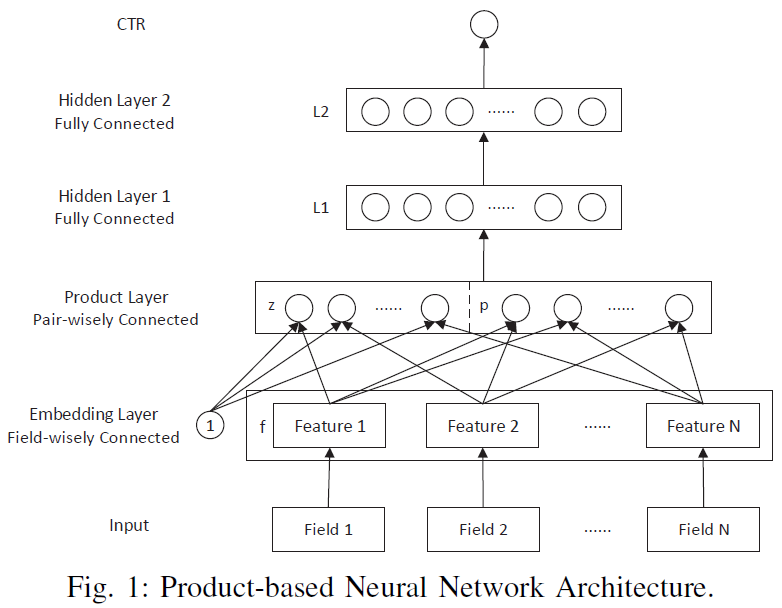
4. PNN —— 加强特征交叉能力(2016)
Product-based Neural Network- NeuralCF 模型只提到用户向量和物品向量两组特征向量,若加入多组特征向量如何设计特征交互?
- PNN 把不同形式不同来源的特征通过 Embedding 层编码成同样长度的稠密特征向量。
- 再把原来的
Stacking层改为Product乘积层,不再是简单拼接,而是特征两两交叉后连接(其实是有直接拼接和乘积拼接两部分,其中乘积特征交叉部分有内积操作、外积操作,分为IPNN和OPNN)。 - 优势:强调了特征交叉方式的多样性,更容易捕捉特征交叉信息。
- 局限:对特征进行无差别交叉在一定程度上是忽略了原始特征信息的有价值部分。如何综合原始信息与交叉信息更加高效,是后面的议题。
5. Wide&Deep —— 记忆能力与泛化能力的综合(2016)
“记忆能力”可以理解为模型直接学习并利用历史数据中的物品或特征的“共现频率”的能力。比如,历史数据中用户已经安装应用A在看到应用B时,应用B的是否安装结果总是“安装”,二者共现频率是 10%(而全部平均安装率只有1%),因此希望模型记住一旦发现有这个特征就会推荐应用B。
这种信号反而是逻辑回归这种简单模型容易记住,而MLP在多层处理交叉后,对这种强特征的记忆反而没有简单模型那么好。
“泛化能力”可以理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。
- 由单层的 wide 部分和多层的 Deep 部分组成的混合模型,wide部分让模型具有“记忆能力”,Deep部分让模型具有“泛化能力”,兼具逻辑回归和深度神经网络的优点——记忆大量历史行为特征并具有强大的表达能力。
- 单层的wide 部分善于处理大量稀疏的id类特征;Deep 部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘藏在特征背后的数据模式。最终利用逻辑回归模型,输出层将 wide 部分和 deep 部分组合起来,形成统一的模型。
- 在具体设计中,需要理解哪些特征作为 wide部分,哪些作为deep部分。
- Deep 部分的输入是全量的特征向量;
- Wide 部分的输入仅仅只有已安装应用和曝光应用两类特征(已安装代表用户历史行为,曝光应用代表当前待推荐应用)。组合特征的函数是交叉积变换函数
- 后续有越来越多工作开始改进 wide 部分和 deep 部分。比较经典的是 Deep & Cross (DCN),主要就是用 Cross 网络代替原来的 wide 部分。设计Cross网络的目的是增加特征之间的交互力度。假设第l层交叉层的输出向量为 ,那么第 l+1 层的输出向量: 每一层仅增加了一个 n 维的权重向量 且在每一层均保留了输入向量,因此输入和输出之间的变化不会特别明显,而且 Cross 网络自动特征交叉,避免了人工特征组合。
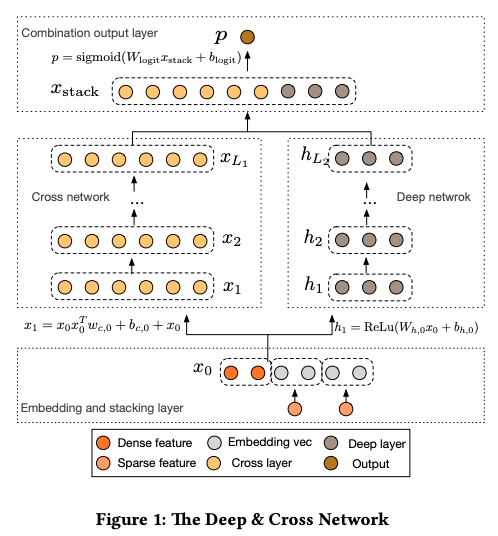
6. FM 与 深度学习(2016)
- 优点:在经典MLP上加入有针对性的特征交叉操作,让模型具备更强的非线性能力。
- 局限:大量的特征互操作尝试在此几乎走到尽头,进一步提升的空间很小了,后续需要更多结构上的探索。
6.1 FNN —— FM 隐向量初始化 Embedding 层
- Embedding 层收敛速度缓慢(参数量巨大且输入向量稀疏导致)
- FNN 使用 FM 模型训练好的各特征隐向量初始化 Embedding 层的参数,相当于初始化神经网络参数时就已经引入了有价值的先验信息。训练的起点就更接近目标最优点,自然加速了整个神经网络的收敛过程。
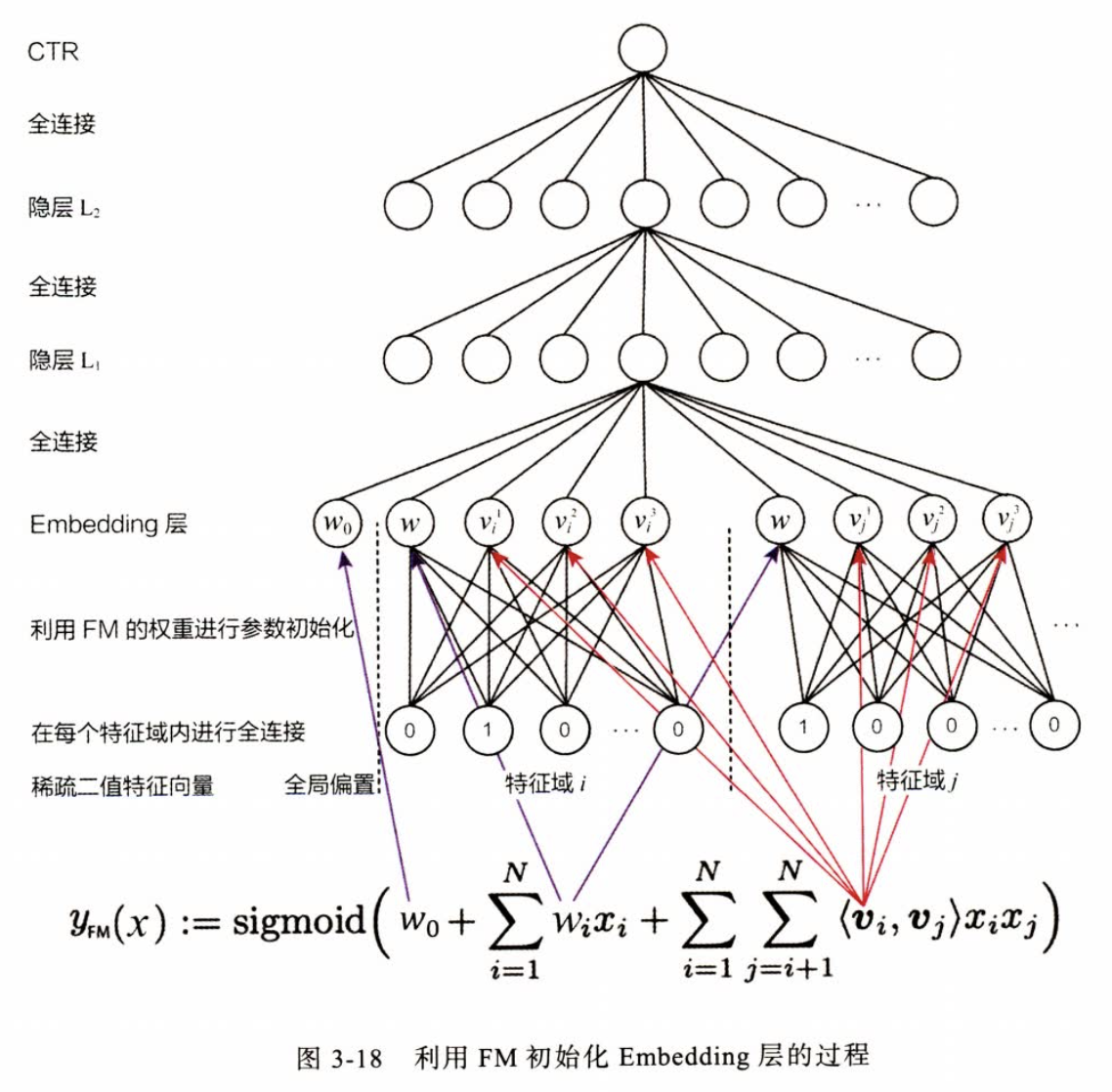
6.2 DeepFM —— FM 代替 Wide 部分
- 改进 Wide&Deep 模型,用FM 替换原来的 Wide 部分,加强浅层网络部分特征组合的能力,改进了原模型wide不具备自动特征组合的能力。
- 这与 Deep&Cross模型利用多层Cross网络进行特征组合思想类似。
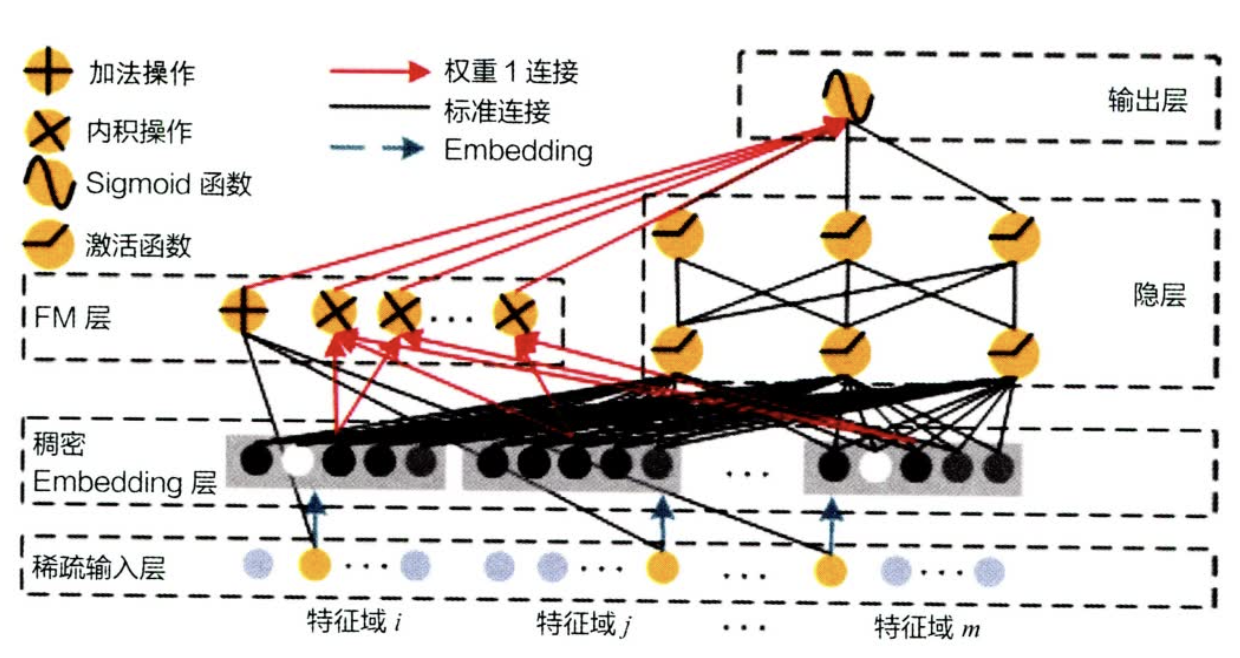
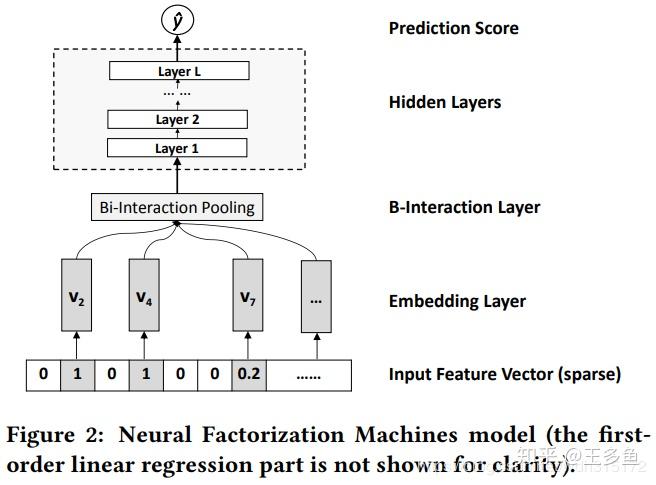
6.3 NFM —— FM 的神经网络化尝试
- 无论是 FM 还是 FFM,归根结底都是二阶特征交叉的模型,都会受到特征组合爆炸的问题,FM几乎不可能扩展到三阶以上,限制了FM模型的表达能力。
- 经典FM的数学形式如下,而NFM的主要思路是用一个表达能力更强的函数代替原FM中二阶隐向量内积的部分。
-
而这个 就是设计一个深度学习网络,结构是:在 Embedding 层和多层神经网络之间加入特征交叉池化层。
-
假设 是所有特征域的 Embedding 集合,那么特征交叉池化层的具体操作是:
- 进行两两 Embedding 向量的元素积操作后,对交叉特征向量取和,得到池化层的输出向量。再交由上层的多层全连接神经网络,进一步交叉。
7. 注意力机制应用(2017)
- 优势:将过去的平均操作或加和操作,换成了加权和或加权平均的操作,贴合用户真实思考过程。
7.1 AFM —— 引入注意力机制的 FM
- 将注意力机制和NFM进行结合。AFM引入注意力机制是在特征交叉层和最终的输出层之间加入注意力网络。作用是为每一个交叉特征提供权重,也就是注意力得分。
- 特征交叉过程是采用元素积操作,加入注意力得分后进行池化:
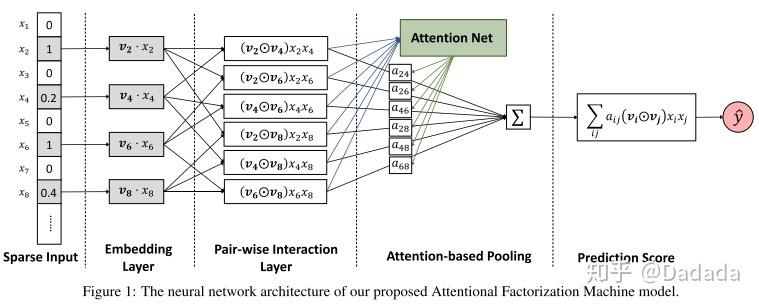
- 其中注意力网络的实现是一个简单的单全连接层加 softmax 输出层的结构(要学习的参数就是 h、W、b):
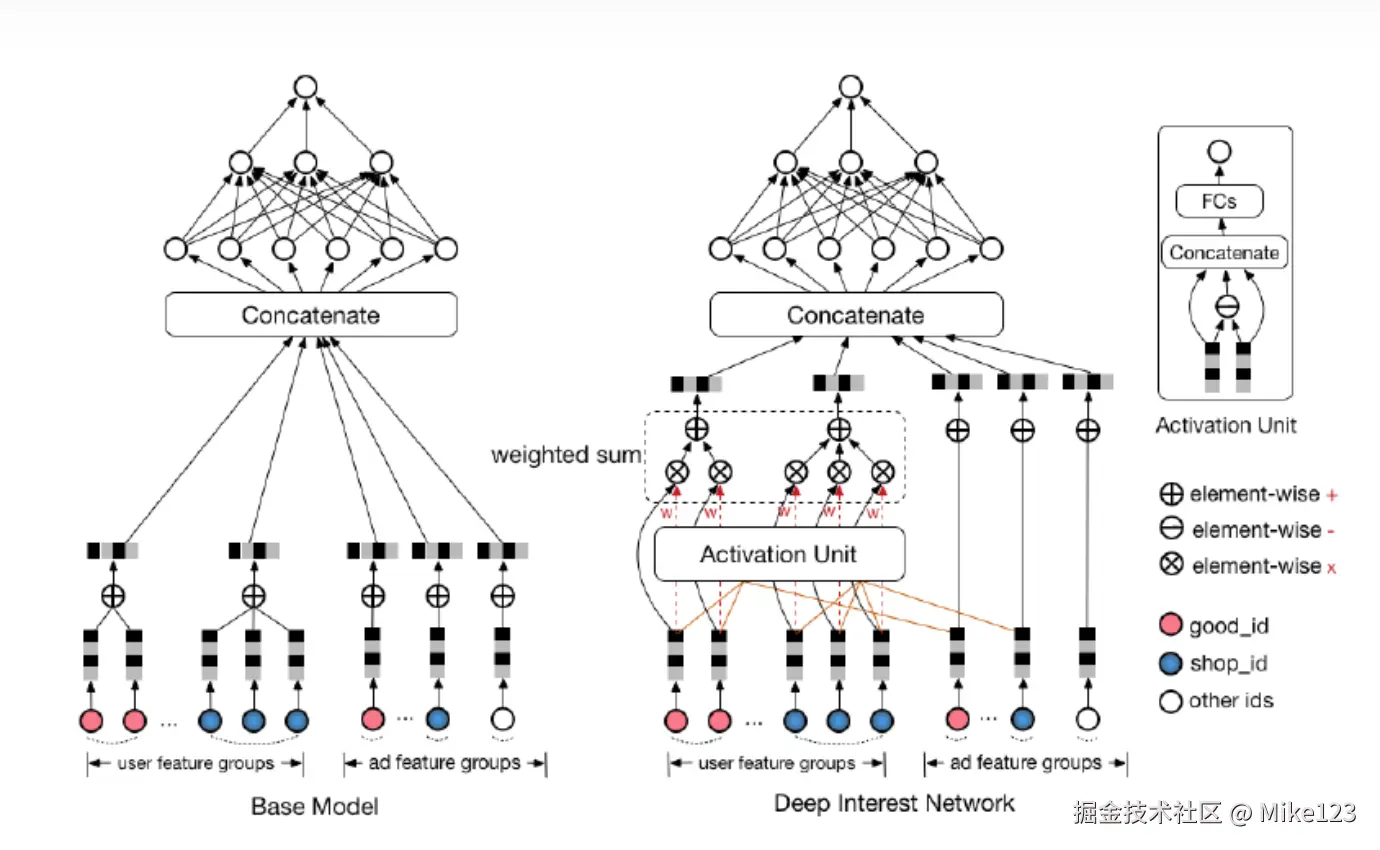
7.2 DIN —— 引入注意力机制的深度学习网络
- 利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就是注意力强弱,加入注意力权重的深度学习网络就是 DIN 模型。
- 注意力部分的形式化表达如下, 从过去的 的加和变成了 的加权和, 权重 就由 与 的关系决定,即注意力得分 :
8. DIEN —— 序列模型结合(2019)
- 前面的所有模型,即便引入了注意力,也仅是对不同行为的重要性进行打分,得分始终是时间无关的,是序列无关的。对于一个综合电商来说,用户兴趣的迁移其实很快,上周的行为序列会集中在篮球鞋,购买完成后本周的购物兴趣可能变成一个机械键盘。若放弃序列信息,则模型学习时间和趋势的能力不强,始终是基于用户所有购买历史的综合推荐,而不是针对下一次购买推荐。
- 序列信息重要性:1. 加强了最近行为对下一次行为预测的影响;2. 序列模型能够学习到购买趋势的信息。
- 如何构建兴趣进化网络(三层):
- 行为序列层:把原始的id类行为序列转换成 Embedding 行为序列。
- 兴趣抽取层:模拟用户兴趣迁移过程,抽取用户兴趣。
- 兴趣进化层:在兴趣抽取层加入注意力机制,模拟与当前目标广告相关的兴趣进化过程。
- 行为序列层就与普通的 Embedding 层一致。
- 兴趣抽取层采用GRU(Gated Recurrent Unit 门循环单元,与RNN相比解决了梯度消失,与LSTM相比参数量更少)。
- 兴趣进化层加入注意力机制,生成得分过程与DIN一致。通过AUGRU (GRU with Attentional Update gate)实现。
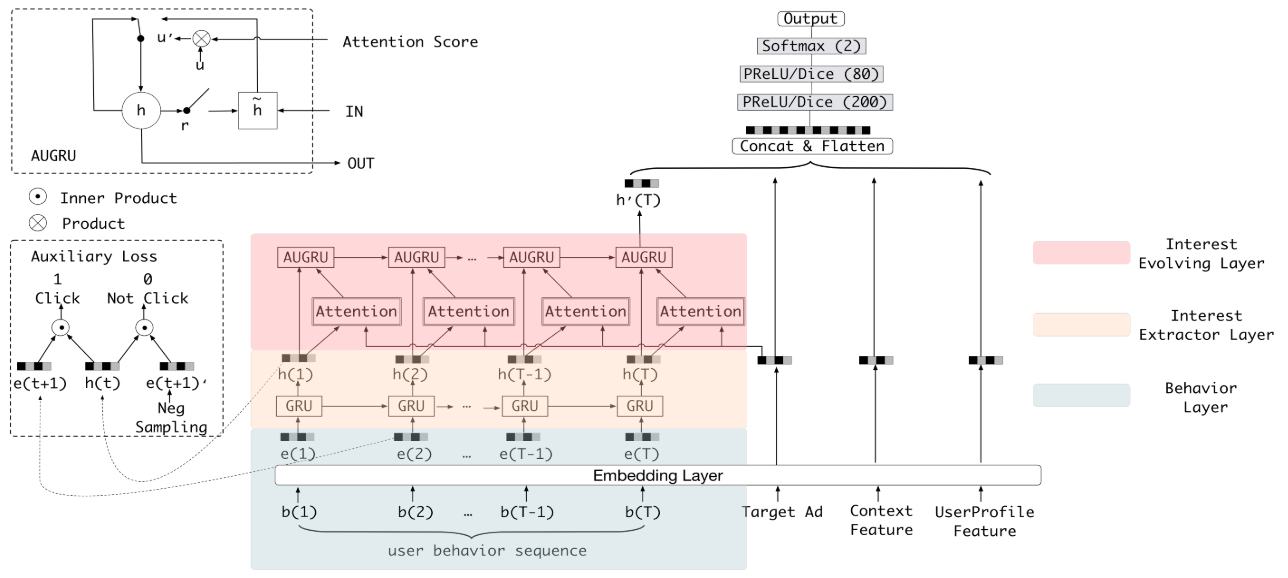
- 优势:加入序列时间信息
- 局限:序列模型复杂度更高,串行推断,延迟更大,需要工程优化。
9. DRN —— 强化学习结合(2018)
- 框架
- 智能体:推荐系统本身
- 环境:由新闻网站或APP、用户组成的整个推荐系统外部环境。用户接收推荐的结果并做出反馈。
- 行动:进行新闻排序后推荐给用户的动作。
- 反馈:用户收到推荐结果后进行的正向或负向的反馈。
- 状态:对环境及自身当前所处具体情况的刻画。
- 在DRN 中,Deep Q-Network (DQN)是大脑,用户特征和环境特征归为状态向量,因为与具体的行为无关;用户-新闻交叉特征和新闻特征归为行动向量,因为与推荐这一行动相关。
- 状态向量在左侧拟合生成价值得分 ;状态向量和行动向量在右侧生成优势得分 ;最后两部分得分综合得到最终的质量得分 。
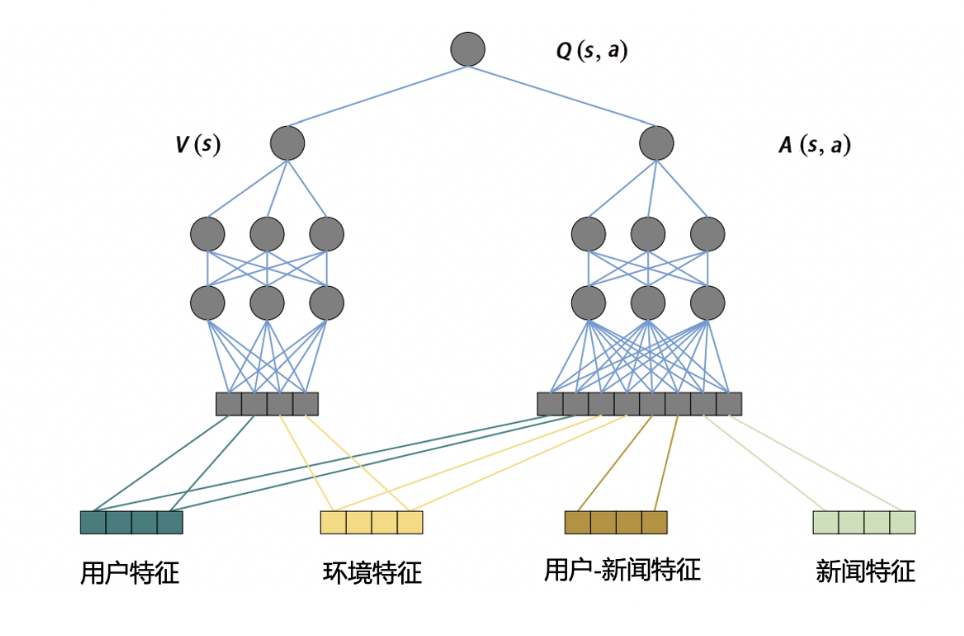
- DRN 学习过程:
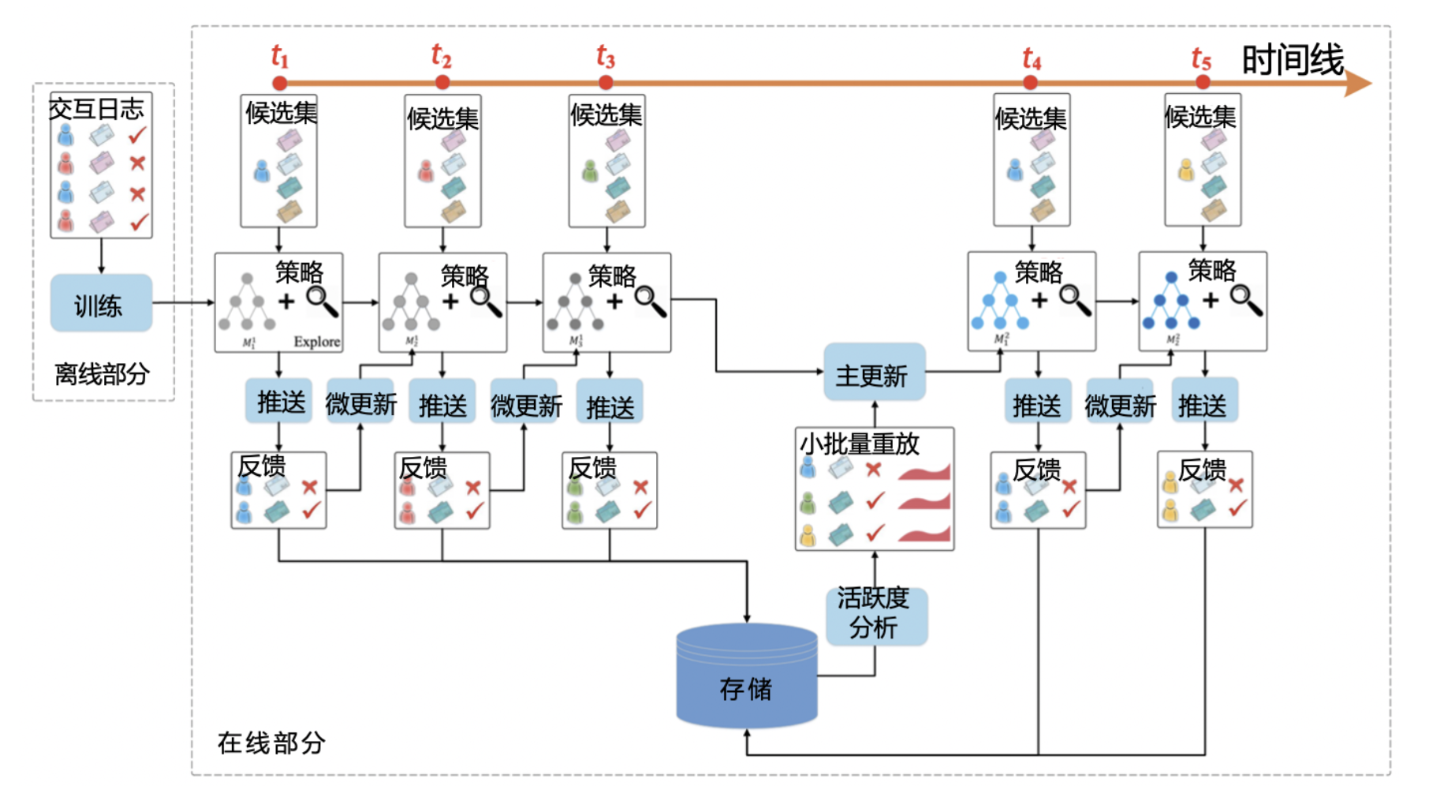
- DRN 的在线学习方法:竞争梯度下降算法。
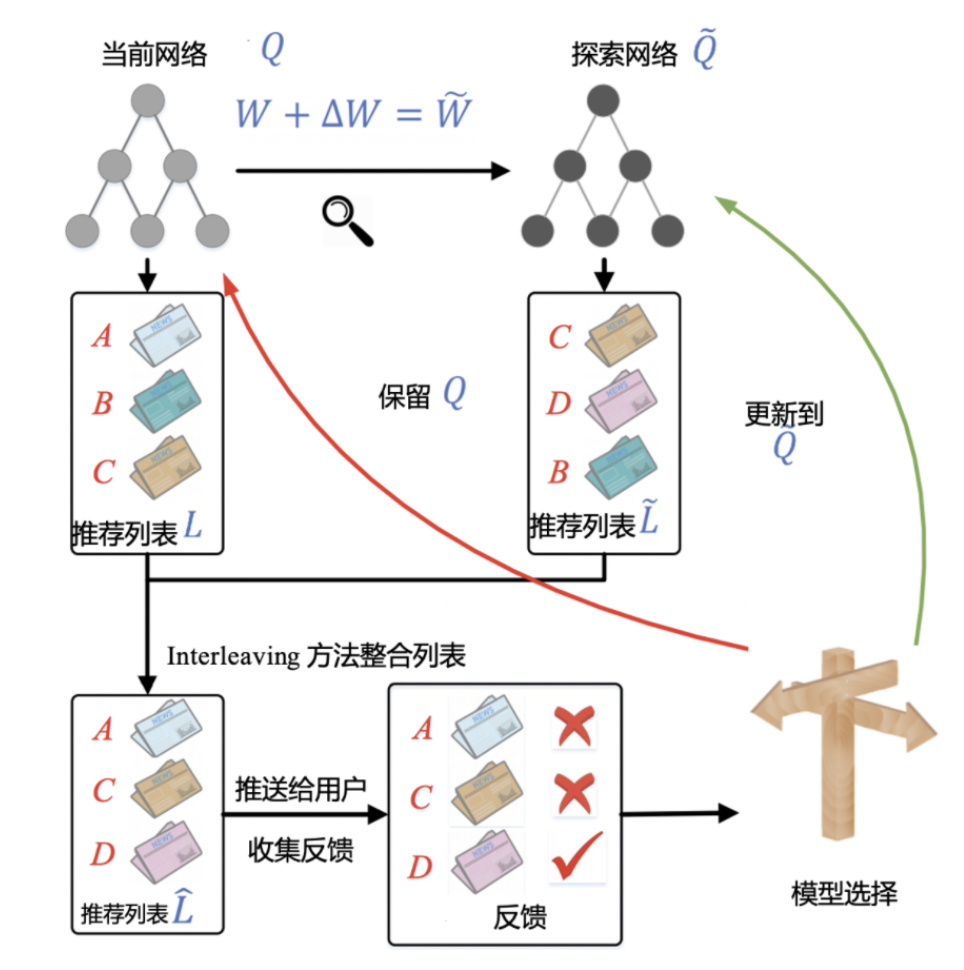
- 优势:变静态为动态,时空性提到一个空前重要的位置。
- 局限:训练延迟大、重量级
第四章 Embedding 技术
- 推荐系统大量使用 one-hot 编码对类别、id型特征进行编码,导致特征向量稀疏,不利于深度学习网络处理,需要 Embedding 层负责将高维稀疏特征向量转为低维稠密特征向量。
1. Word2Vec —— 经典的 Embedding 方法
- 主要原理:CBOW模式是输入周围词,预测中心测;Skip-Gram是输入中心词,预测周围词。后者效果更好。
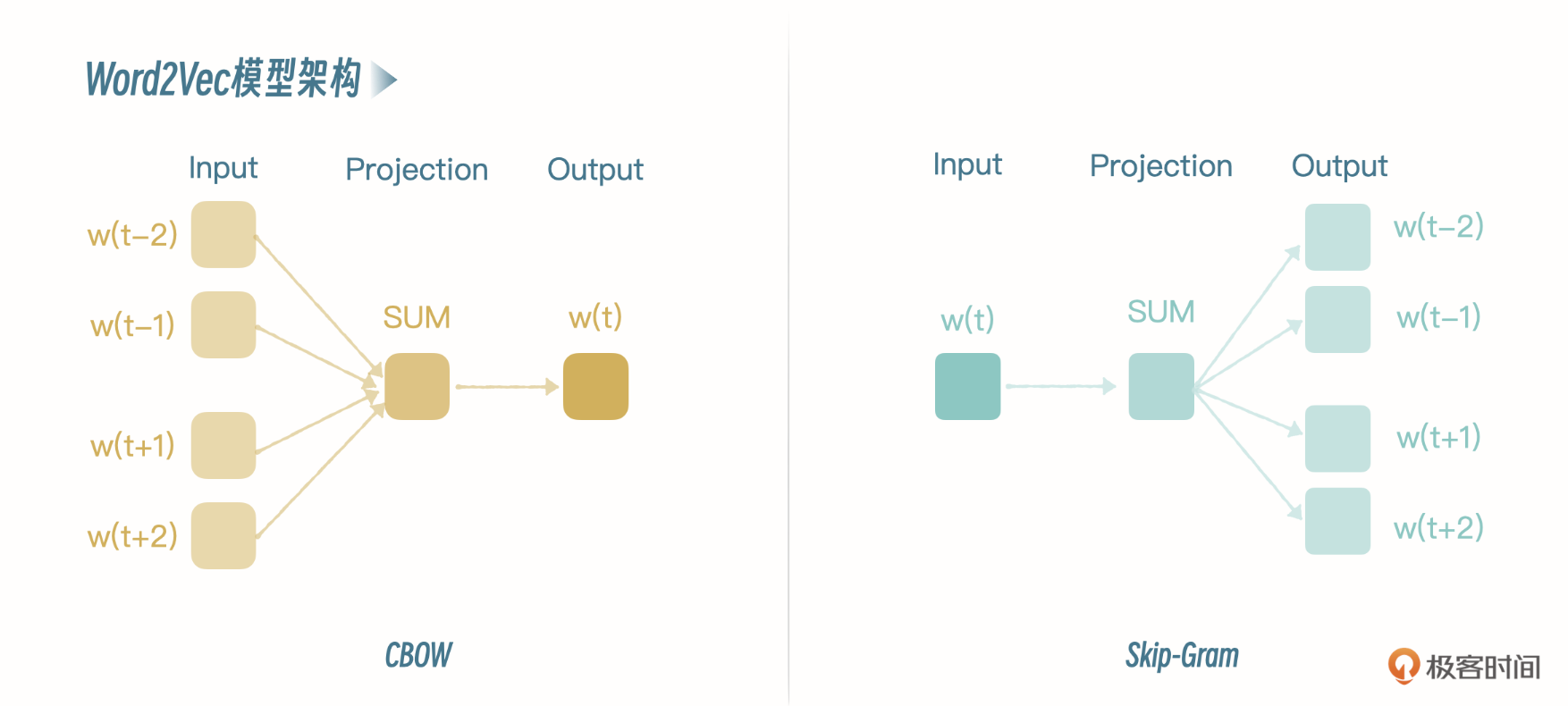
- 训练样本:定义窗口大小 (前后各 c 个词),抽取一个句子,窗口滑动,窗口词组就是一个训练样本。
- 优化目标:极大似然估计,希望所有样本的条件概率 之积最大(使用对数概率)。
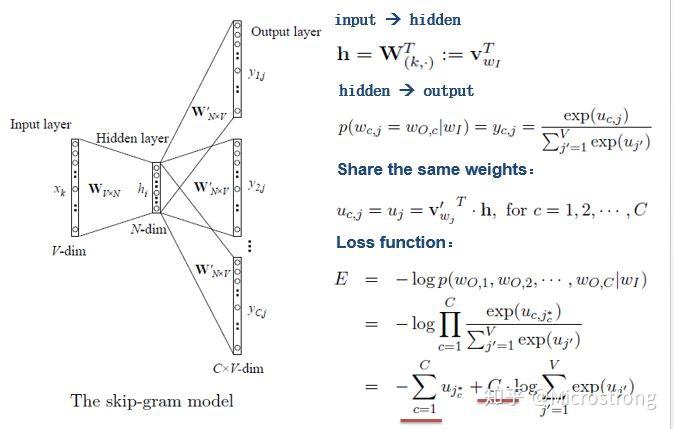
- 如何定义 p?多分类问题,最直接方式是 softmax 函数:
- 负采样训练方法:全量词表太大,采用负采样,多分类退化成近似二分类。
2. Node2Vec —— 图嵌入技术
- 在图结构上随机游走,生成序列样本后,利用 Word2Vec 思想建模。
3. ESGM —— 综合不同信息 embedding 加权融合
- 融合多种补充信息,解决 Embedding 冷启动问题。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 isSeymour!
 微信支付
微信支付 支付宝
支付宝
评论