
LLM 常见手撕代码
LLM 常见手撕代码
来源参考: LLM 面试手撕代码大全
以 PyTorch 实现
此外,对于 transformer 的理解建议参考: Transformer模型详解(图解最完整版)
零、张量变换与重塑
0.1 教程说明
操作
作用
是否复制内存
常见用途
view()
重塑形状
否
分头、展平
reshape()
重塑形状
必要时是
安全重塑
transpose()
交换两维
否
注意力计算
permute()
重排所有维
否
复杂维度重排
contiguous()
内存连续化
必要时是
view前确保连续
unsqueeze()
插入维度
否
广播准备
squeeze()
删除维度
否
去除冗余维
expand()
扩展维度
否
只读广播
repeat()
复制扩展
是
需要独立副本
cat()
拼接
视情况
合并张量
stack()
堆叠
视情况
增维合并
split()
按大小分割
否
分离特征
chunk()
按份数分割
否
均分张量
where()
条件选择
视情况
掩码、索引
优先使用 ...

HOT100 一句话题解
HOT100 一句话题解
2026/04/01@Sean
来源:力扣 HOT100
01. 两数之和
哈希表, 一边查差值, 一边插入
02. 字母异位词分组
哈希表, 键用正序的字符串, 值是字符串数组
03. 最长连续序列
插入哈希表, 从表全部查一遍num, num 有前序 num-1 则放弃, 无前序则计算长度, 更新答案
04. 移动零
i 从头扫描, p记录当前已排好的下一个位置, 最后把 p 之后的填0即可
05. 盛最多水的容器
下标 L,R 从两头开始, 每次计算更新答案, 移动是看 h[L], h[R] 谁低移动谁
06. 三数之和
先排序, 再用下面的两重循环:
123for(i=0~n) for(j=i+1, k=n-1; j<k; j++) while(j<k && nums[i+j+k] > 0) k--;
注意:jk刚好拼接成一重循环的。
注意:使用 if(i != 0 && nums[i-1] == nums[i]) continue; 去除重复。
07. 接雨水
下标 li, ...

深度学习推荐系统
深度学习推荐系统
来源:王喆《深度学习推荐系统 1.0》
第一章 宏观认知
互联网的核心需求是“增长”,而推荐系统正处在“增长引擎”的核心位置。
推荐系统要解决的“用户痛点”是用户如何在“信息过载”的情况下高效地获得感兴趣的信息。
信息:
物品信息
用户信息
场景信息
推荐系统处理问题的形式化定义:
对于用户 U (user), 在特定场景 C (context) 下,针对海量的物品信息,构建一个函数 f(U,I,C),预测用户对特定候选物品 I (item) 的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
第二章 传统推荐模型
发展脉络
协调过滤算法族CF:UserCF、ItemCF、MF
逻辑回归模型族LR:LR、LS-PLM、POLY2
因子分解机模型族FM:FM、FFM
组合模型:GBDT+LR
模型名称
基本原理
特点
局限性
协同过滤
根据用户的行为历史生成用户-物品共现矩阵,利用用户相似性和物品相似性进行推荐
原理简单、直接,应用广泛
泛化能力差,处理稀疏矩阵的能力差,推荐结果的头部效应较明显
矩阵分解
将 ...

transformers 库基础组件
transformers 库基础组件
参考来源:B站-手把手带你实战HuggingFace Transformers-入门篇
官方文档:HuggingFace-transformers
pipeline
查看支持任务
123456from transformers.pipelines import SUPPORTED_TASKSfor k, v in SUPPORTED_TASKS.items(): print(k, v)pipe = pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")pipe("我觉得不太行!")
背后实现
123456789101112131415def my_pipeline(): tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese" ...

HLLM
HLLM (Hierarchical Large Language Model)
HLLM是一种分层大规模语言模型架构,主要用于处理具有层次结构的数据(如用户-物品交互、文档-段落、对话历史等)。
1234567891011121314HLLM Architecture:┌─────────────────────────────────────┐│ Task-specific Layer │├─────────────────────────────────────┤│ Cross-Level Attention │├─────────────────────────────────────┤│ Level 3: 全局语义表示层 │├─────────────────────────────────────┤│ Level 2: 会话/序列建模层 │├─────────────────────────────────────┤│ Level 1: 基础元素编码层 ...
多目标建模 ESSM、MMOE
多目标建模 ESSM、MMOE
场景:精排多任务学习
模型:ESSM、MMOE
数据:Ali-CCP数据集
ESSM 算法原理
MMOE 算法原理
代码实现
直接调包
ESSM
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859#使用pandas加载数据import pandas as pddata_path = '../examples/ranking/data/ali-ccp' #数据存放文件夹df_train = pd.read_csv(data_path + '/ali_ccp_train_sample.csv') #加载训练集df_val = pd.read_csv(data_path + '/ali_ccp_val_sample.csv') #加载验证集df_test = pd.read_csv(data_path + '/ali_cc ...

召回 DSSM、YouTubeDNN
召回 DSSM、YouTubeDNN
场景:召回
模型:DSSM、YouTubeDNN
数据:MovieLens-1M
DSSM 算法原理
DSSM(Deep Structured Semantic Models,深度结构化语义模型)是微软研究院提出的一种非常经典的深度语义匹配模型。它最早主要用于解决搜索中查询(Query)和文档(Document)的匹配问题,后来也被广泛用于推荐系统、广告投放等场景。
DSSM的核心目标是:将高维的、稀疏的文本特征(如Query和Doc)映射到一个低维的、稠密的语义空间中,并在该空间中用向量的余弦相似度来表示两者的语义相关性。
DSSM是一个典型的双塔模型架构。它有两个结构相同(或相似)但参数独立的DNN塔,分别用来处理Query和Document。
1. 输入层:Term Vector+ Word Hashing
问题:输入通常是高维的one-hot向量(词袋模型),维度等于词典的大小(可能是几十万甚至百万),直接输入网络会导致参数过多且无法捕捉词之间的相似性。
解决方法:Word Hashing(这是DSSM的一个关键亮点,基于词的字母 ...
DIN
DIN
场景:精排CTR预测
数据:Amazon-Electronics
DIN(Deep Interest Network)模型,是阿里提出的经典推荐模型,核心解决了传统 CTR 模型(如 DeepFM)无法捕捉用户动态兴趣的问题。
DeepFM:把用户的所有历史行为(比如点击过的商品)当成 “静态特征”(拼接成固定长度的向量),无法区分哪些历史行为和当前推荐商品相关
DIN:针对 “用户兴趣多样性” 问题,提出注意力机制,对用户历史行为做 “加权聚合”—— 和当前商品相关的历史行为权重高,无关的权重低,从而精准捕捉用户的即时兴趣。
123用户历史行为:点击过 “篮球鞋”、“连衣裙”、“篮球”、“口红”;当前推荐商品:“篮球”→ DIN 会给 “篮球鞋”、“篮球” 高权重,给 “连衣裙”、“口红” 低权重;当前推荐商品:“口红”→ DIN 会给 “连衣裙”、“口红” 高权重,给 “篮球鞋”、“篮球” 低权重。
这就是 DIN 的核心:基于注意力的兴趣激活(Interest Activation)。
1234567输入特征 → 嵌入层 → 分模块处理: ...
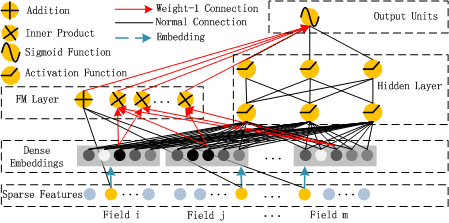
DeepFM
DeepFM
场景:精排CTR预测
数据:Criteo广告数据集
DeepFM 是为了解决 CTR 预估问题而生的,它的全称是Deep Factorization Machine(深度因子分解机),本质是将FM 层(因子分解机)和DNN 层(深度神经网络) 结合,同时学习特征的低阶交互和高阶交互,最终输出用户点击的概率(预估 CTR)。
传统 LR(逻辑回归)只能学习线性特征。
纯 FM 只能学习二阶特征交互(两个特征的组合)。
纯 DNN 虽然能学高阶交互,但对低阶交互的学习效率低,且需要大量数据。
1234输入特征 → 嵌入层(Embedding Layer) → 分两路: ├─ FM层:学习二阶特征交互 → 输出FM得分 └─ DNN层:学习高阶特征交互 → 输出DNN得分→ 拼接FM得分 + DNN得分 → 输出层(Sigmoid)→ 预估CTR(0~1的概率)
算法原理
1. 输入特征与嵌入层
输入特征:
离散特征:若这个离散特征是高维稀疏的,则需要先用一个嵌入层映射到低维稠密。
连续特征:可以直接归一化后输入;也可以做离散化 ...

性能指标
性能指标全解
AUC
AUC 是 Area Under the Curve 的缩写,中文翻译为曲线下面积,具体指的是ROC 曲线(受试者工作特征曲线) 下方的面积。
ROC 曲线:以 “假正例率(FPR)” 为横轴,“真正例率(TPR)” 为纵轴绘制的曲线,反映模型在不同阈值下的分类能力;
AUC 值:ROC 曲线与坐标轴围成的面积,取值范围是 [0, 1],AUC 越接近 1,说明模型的排序 / 分类能力越强。
CTR 预估本质是二分类任务(用户 “点击” 为正例,标签 = 1;“不点击” 为负例,标签 = 0),先明确 4 个核心统计量:
\
预测为正例(点击)
预测为负例(不点击)
正例(1)
TP(真阳性)
FN(假阴性)
负例(0)
FP(假阳性)
TN(真阴性)
基于这 4 个指标,推导 ROC 曲线的横纵轴:
真正例率(TPR):TPR=TPTP+FNTPR=\frac{TP}{TP+FN}TPR=TP+FNTP → 所有真实点击的样本中,被模型正确预测为点击的比例(“找对正例” 的能力);
假正例率(FPR):FPR=FPFP ...